
Ubuntu 20.04 安装ClickHouse集群
Ubuntu 20.04 安装ClickHouse集群
-
引言
因为笔者最近一直想实现一个自己的APM服务端,但是看了很多APM服务端系统没有使用.Net Core来写的,都是采用Java或者Go,笔者是写C#的,但是笔者认为.Net Core的性能在现在对比Go和Java很有优势,所以笔者才有想法使用.Net Core来实现一个APM的服务端;最近在研究SkyWalking APM服务端的实现,在研究下来SkyWalking存储使用的是MySql、PgSql、ES用来存储数据,笔者本想使用MySql来进行存储但是看了很多文章都不推荐使用,原因是因为MySql吞吐量太低,对于大量数据提交并无法支撑,但是笔者不想是用ES,众所周知ES的配置相当麻烦而且也很吃内存,笔者配置了几次但是因为服务器是自己家里的机器,有时候会存在关机的情况,就会导致莫名其妙的无法启动ES,所以笔者在研究了一些其他类型的数据库,笔者经过对比MongDB、ClickHouse 最终选择了ClickHouse;在笔者看来放弃MongoDB的原因也是因为他的吞吐量太低,因为MongDB并不是适合APM数据存储,MongoDB本身是一个适用于存储非结构化数据和半结构化数据。ClickHouse是一种列式数据库,适用于存储和分析大量结构化数据,而且他的写入速度快,适合APM这种级别的写入效率。实现APM服务端的话那么它必然需要高性能的写入,所以笔者选择了ClickHouse。
-
ClickHouse简介
ClickHouse是一种高性能、开源、列式数据库管理系统(DBMS),被设计用于在线分析处理(OLAP)环境下的大规模数据仓库。以下是ClickHouse的优势和缺点:
-
优势:
- 支持高并发:ClickHouse 使用并行处理机制来处理查询请求,可以支持高并发场景。
- 数据压缩空间大:ClickHouse 采用数据压缩技术,可以减少数据的存储空间,同时也减少了 I/O 传输。
- 索引是类似跳表结构:ClickHouse 的索引是类似跳表结构,不需要满足最左原则,非常适合聚合计算。
- 写入速度快:ClickHouse 的写入速度非常快,特别适合写本地表而不是 All 表。
- 采用了并行处理机制:ClickHouse 使用并行处理机制来处理查询请求,可以充分利用服务器的计算资源。
- 支持多种数据类型:ClickHouse 支持多种数据类型,包括数字、字符串、日期、时间、二进制等。
- 支持多种编程语言:ClickHouse 支持多种编程语言,包括 SQL、Python、R 等。
- 易于管理和维护:ClickHouse 采用面向对象的设计思想,使得管理和维护变得更加容易。
-
缺点:
- 不支持事务:ClickHouse是一种面向分析的数据库,不支持像MySQL或PostgreSQL这样的事务。
- 不支持更新和删除操作:ClickHouse是一种列式数据库,不支持行级别的更新和删除操作。
- 存储格式限制:ClickHouse只支持列式存储,不支持行式存储。
- 操作复杂:ClickHouse相对于其他数据库系统可能需要更长的学习和调试时间,因为它有许多不同的特性和配置选项。
-
结论
总的来说,ClickHouse是一种专门为大规模数据分析而设计的高性能数据库,可以处理海量数据且速度非常快。但是,它不支持事务和行级别的更新和删除操作,并且需要更复杂的配置和调试,因此需要更多的学习和使用时间。
-
-
1、安装ClickHouse
官网安装clickhouse命令:https://clickhouse.com/docs/zh/getting-started/install
sudo apt-get install -y apt-transport-https ca-certificates dirmngr sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 8919F6BD2B48D754 echo "deb https://packages.clickhouse.com/deb stable main" | sudo tee \ /etc/apt/sources.list.d/clickhouse.list sudo apt-get update # 安装命令 sudo apt-get install -y clickhouse-server clickhouse-client # 启动服务端 sudo systemctl start clickhouse-server # 查看状态 sudo systemctl status clickhouse-server # 停止服务 sudo systemctl stop clickhouse-server # 重新启动服务端 sudo systemctl restart clickhouse-server # 连接服务端 clickhouse-client # or "clickhouse-client --password" if you've set up a password. -
2、ClickHouse添加自定义用户名
-
2.1、通过配置 sudo nano /etc/clickhouse-server/users.xml文件配置账号密码
推荐使用这种方式<!-- Users and ACL. --> <users> <kawhi> <!--<password></password>--> <password_sha256_hex>896f566e6b8731559d49b0744bdbdb3274ed3eaed2ed494f44da6f8957a6590d</password_sha256_hex> <networks> <ip>::/0</ip> </networks> <!-- Settings profile for user. --> <profile>default</profile> <!-- Quota for user. --> <quota>default</quota> <!-- User can create other users and grant rights to them. --> <!-- <access_management>1</access_management> --> </kawhi> </users> -
2.2、进入ClickHouse-server以后创建自己的用户
clickhouse-client --password create user kawhi identified with sha256_password by 'abcdefg' host any; GRANT ALL ON *.* TO kawhi WITH GRANT OPTION; show grants for kawhi
-
-
3、修改默认配置
-
3.1、修改默认数据存储目录
建议在所有安装完成以后直接先修改目录,这样我们还没有任何数据进来,避免遗漏或者丢失数据
# 创建目录 mkdir /clickhouse sudo chown clickhouse:clickhouse -R 你的目录 # 打开配置文件 sudo nano /etc/clickhouse-server/config.xml # 找到<path>/var/lib/clickhouse/<path> 修改成以下 <path>你的目录<path> # 例如: <path>/home/kawhi/clickhouse/</path> -
3.2、打开远程访问
红框内的那段代码默认是被注释掉的,将其取消注释。
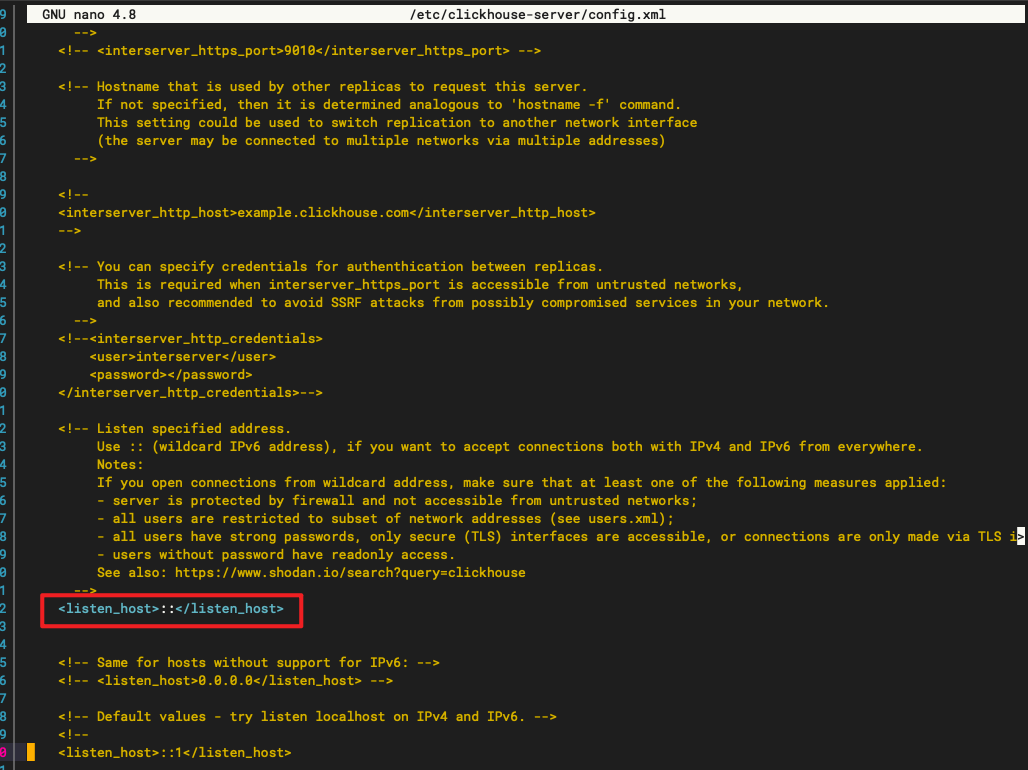
# 重新启动服务端 sudo systemctl restart clickhouse-server
-
-
4、clickhouse配置集群
-
4.1、在你所有的clickhouse机器上重复以上步骤
-
4.2、添加集群配置
在/etc/clickhouse-server/config.xml的配置文件中添加集群配置
集群配置添加完成后确认集群在任意一台机器上执行下面的命令登录数据库,确认集群配置;<remote_servers> <!--集群名称《可自行修改》--> <luck_click_house_cluster> <!-- shard定义分片的副本数量,这里只配置了三个 --> <shard> <!--weight表示每个分片的写入权重值--> <weight>1</weight> <!--internal_replication表示是否启用内部复制--> <internal_replication>true</internal_replication> <!-- replica定义分片的副本数量,这里只配置了一个,如果需要配置多个,追加replica即可,但是IP不可以相同,不然在创建数据库时会报错 --> <replica> <host>192.168.31.20</host> <port>9000</port> <user>default</user> <password>wzw0126..</password> </replica> </shard> <!-- shard定义分片的副本数量,这里只配置了三个 --> <shard> <!--weight表示每个分片的写入权重值--> <weight>1</weight> <!--internal_replication表示是否启用内部复制--> <internal_replication>true</internal_replication> <!-- replica定义分片的副本数量,这里只配置了一个,如果需要配置多个,追加replica即可,但是IP不可以相同,不然在创建数据库时会报错 --> <replica> <host>192.168.31.21</host> <port>9000</port> <user>default</user> <password>wzw0126..</password> </replica> </shard> <!-- shard定义分片的副本数量,这里只配置了三个 --> <shard> <!--weight表示每个分片的写入权重值--> <weight>1</weight> <!--internal_replication表示是否启用内部复制--> <internal_replication>true</internal_replication> <!-- replica定义分片的副本数量,这里只配置了一个,如果需要配置多个,追加replica即可,但是IP不可以相同,不然在创建数据库时会报错 --> <replica> <host>192.168.31.22</host> <port>9000</port> <user>default</user> <password>wzw0126..</password> </replica> </shard> </luck_click_house_cluster> </remote_servers>

# 登录clickhouse服务端 clickhouse-client -u 你的用户名 # 查询集群命令 select * from system.clusters;
-
-
5.3、结语
在配置ClickHouse时遇到了很多问题,例如不知道集群如何设置,所以花费了将近一天的时间,但是如果你们公司有专门的DBA这件事情完全不用你操心,或者可以选择云服务商的ClickHouse,笔者纯粹是想学习以下ClickHouse的集群配置,所以会花费一些时间来进行研究,但是重点仍然是APM服务端的实现。在看过SkyWalking的表设计之后,笔者是被震惊到了,他有287张表,甚是惊讶。毕竟SkyWalking已经是一个成熟的APM项目,所以还是有很多值得学习的。本篇只讲了如何配置ClickHouse集群,但是笔者在创建分布式数据库和表时发现ClickHouse想使用分布式的数据库或者表还需要Zookeeper,所以ClickHouse会出至少两篇文章,下一篇将记录ClickHouse如何使用Zookeeper集群来建立分布式数据库或者表。ClickHouse系列是APM系统的打头。
▼-----------------------------------------▼-----------------------------------------▼

