
标题:重新审视用于跨领域少样本学习的原型网络
研究背景:
- 问题背景:原型网络是一种流行的小样本学习方法, 其网络简单而直观,对于小样本学习问题有着较好的表现,尤其是在图像分类等领域。
- 存在问题:然而,当推广到跨领域的少样本分类任务时,其性能出现了大幅度下降,这严重限制了原型网络的实用性。
- 研究动机:由研究表明,神经网络倾向于锁定简单的特征(颜色,形状等),而忽略了复杂的特征(语义)。故作者认为原型网络泛化能力差是由于简单性偏差引起的。
研究方法:
- 理论基础:基于响应的知识蒸馏
- 技术路线;作者设计了一个局部-全局蒸馏网络原型网络(LDP-net),该网络采用双分支结构,如下图。

- 全局分支基本和标准的原型网络一样,用于预测查询集的类别。
- 局部分支使用另外一个特征提取器,用于提取经过随机裁切后的查询集图像特征,并使用改特征和全局分支的原型计算相似度,进行同样的分类预测。
- 基础原型网络:
- 1、原型计算公式如下,对于支持集中的k个图像,计算抽取后的平均特征
- 2、对于查询集中的每个图像,计算特征,如何使用该特征与原型计算分类预测。
- 3、分类损失计算如下:
- LDP-net
- 局部分支:局部分支有和全局分支类似的结构,其中原型采用和全局分支同一个,但输入改为查询集的随机裁切,以求获取局部特征。
- 局部-全局知识蒸馏:
- 鼓励全局图像从局部裁切中获取更丰富的语义信息,为了实现这个目标,在全局预测和局部预测之间施加一致性约束如下,即计算局部分类结果和全局分类结果之间计算交叉熵。
- 为了减少类内的语义变化,对于同一类的图像的预测结果,施加一致性约束,因为强行对所以查询集施加一致性约束会导致模型学习琐碎的解决方案,所以只随机选取同一类查询集中的一张,计算它的局部预测结果,并使用该结果和全局分支结果计算交叉熵。
- 跨任务知识蒸馏:
- 元训练过程中,使用EMA来更新局部分支的特征提取器参数,以求更好的学习跨任务知识,提高泛化能力。(局部分支和全局分支的特征提取器结构是相同的)
- 元训练:
- 总损失函数,预测损失+图像自蒸馏损失+跨图像蒸馏损失
- 算法:
- 在评估阶段,只使用全局分支,使用评估阶段的训练集训练分类器,而特征提取层参数不变。

实验结果:
- 实验设置;使用mini-ImageNet完成元训练阶段,在八个数据集上(CUB, Cars,Places, Plantae, ChestX, ISIC, EuroSAT and CropDisease),进行评估。使用Resnet-10作为特征提取器。目标领域位N-way,1 or 5-shot ,任务,使用欧几里得距离。
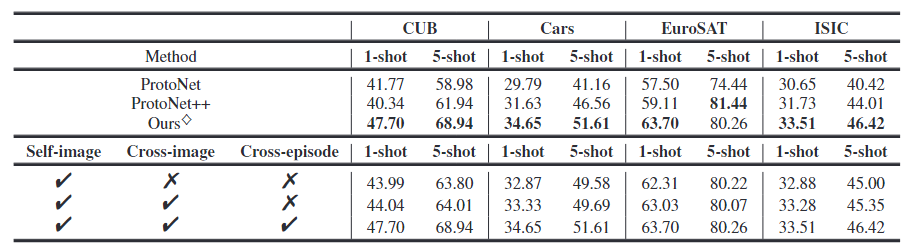
- 1、与原型网络的基线对比:
- 2、CAM图对比:
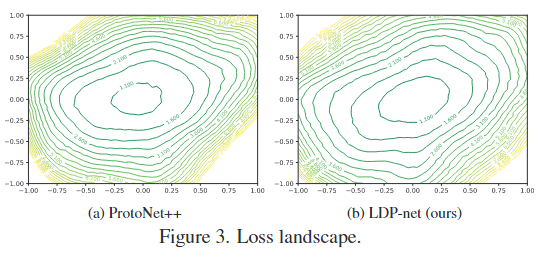
- 3、损失景观:
- 结论,该网络能缓解原型网络中的简单性偏差,实现更好的泛化。
- 与最先进的办法对比:
- 消融研究
- 存在问题:在有明显领域偏移的任务中,结果依然不如人意,可能的解决方法是扩充元训练的领域。
posted @
2023-11-22 16:07
katzzy
阅读(
585)
评论()
编辑
收藏
举报
点击右上角即可分享




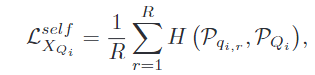
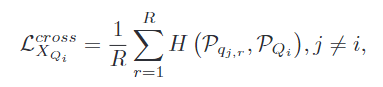





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!