结对编程作业
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 北航 2022 春季敏捷软件工程 |
| 这个作业的要求在哪里 | https://bbs.csdn.net/topics/605443466 |
| 我在这个课程的目标是 | 尝试结对编程,使用单元测试工具开发高鲁棒应用程序 |
| 这个作业在哪个具体方面帮助我实现目标 | 构建一款计算单词链的程序,在实践中成长 |
1. 在文章开头给出教学班级和可克隆的 Github 项目地址(例子如下)。
- 教学班级:周五班
- 项目地址:https://github.com/Chenrt-ggx/WordListProject
2. 在开始实现程序之前,在下述 PSP 表格记录下你估计将在程序的 各个模块的开发上耗费的时间。(0.5')
见后方
3. 看教科书和其它资料中关于 Information Hiding,Interface Design,Loose Coupling 的章节,说明你们在结对编程中是如何利用这些方法对接口进行设计的。(5')
Information Hiding:我们的程序分为了CLI和CORE两部分,其中CORE中有许多私有数据,如建的图,图的状态等等,这些数据并不开放给调用者查看。另外,我们还封装了Node类与Chain类,采用面向对象的方式将内部状态封装,向外提供合适的接口。
Interface Design:接口设计上为了与题目配合,仅实现了指导书上描述的四个函数,其中,这些方法中的*words[]参数的内存均由调用者负责释放,*result[]的每一个指针指向的内存由被调用者负责释放。这样的设计不容易导致调用者误操作造成内存泄露。函数报错时,为了不同语言的可互换性,不能使用抛出异常,我们采用了返回负值代表错误的方式。
Loose Coupling:使用面向对象的方法包装了Node和Chain,Node类提供了对单词的包装(内容,长度,首尾,还有DFS的状态属性),Chain类用于管理一个单词链(可以在结尾加上或减去一个Node,并O(1)管理链的字母数长度)通过如上的包装,我们实现了寻找最长单词数链和寻找最长单词字母链的统一处理。另外,对每一个函数都是根据题目性质实现的效率较高的算法。
4. 计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(7')
- build_graph: 把传入的单词用Node节点包装起来,存到一个二维数组里面,并将重边(如abc,abbc)按照长度排序后去重。排序的作用是求最长字母链时,可以只遍历第一个没用过的边。
- check_cycle:使用标准的DFS判环算法,时间复杂度O(1+E),用于在没有允许隐含单词环且输入中存在单词环时报错。【单词环存在的一个充分必要条件是:单词图中存在不是自环的环,或者存在某个字母上有两个以上的自环】
- abstract_gen_chain:同时处理最长单词链和最长单词字母链的函数,由于有单词环时是NPC问题,所以没有做算法上的优化,采用了DFS算法。做了两个简单的优化一个是有多条重边时只遍历最长的那一条,另一个是自环会在第一次到达字母节点时全部加入单词链(显然更长)
- gen_chain_word_unique:由于这个操作不允许存在单词环,故可以使用无需标记的DFS算法【(在不允许单词环存在的条件下)单词链中的每一个单词的首字母不能相同的一个充分必要条件是:仅这个单词链的最后一个单词可以为自环(如aba)链中其他单词不能为自环】
- gen_chains_all:由于这个操作不允许存在单词环,故可以使用无需标记的DFS算法。在每个字母上最多只有一个自环,所以遍历就分为走这个自环和不走这个自环。
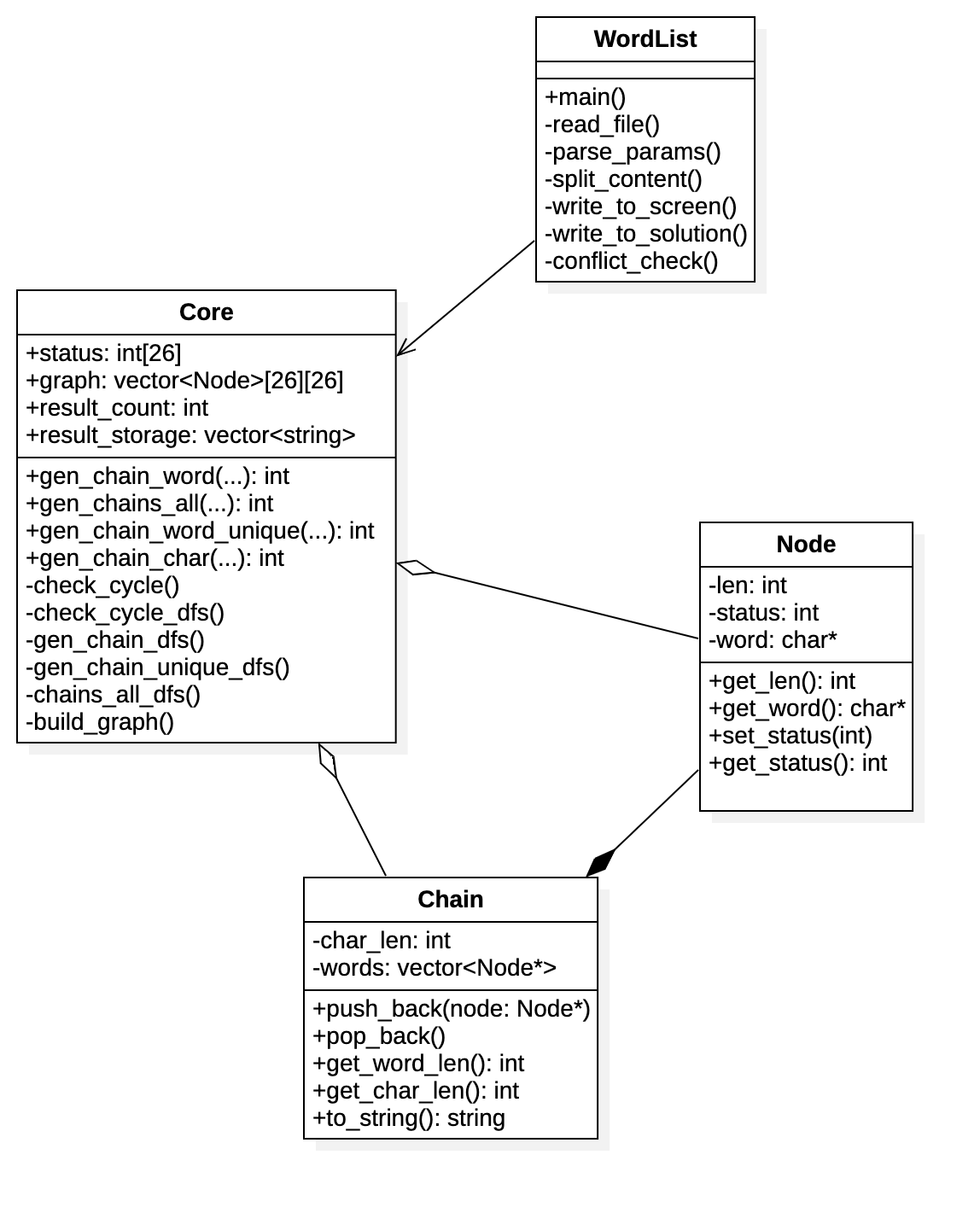
5. 阅读有关 UML 的内容,画出 UML 图显示计算模块部分各个实体之间的关系(画一个图即可)。(2’)
6. 计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019的性能分析工具自动生成),并展示你程序中消耗最大的函数。(3')
我们在设计阶段考虑了以下性能优化:
- 使用
fread读入数据,减少系统调用次数已优化性能。 - 使用邻接矩阵存图,以加速查询。
- 缓存/维护包括单词长度,单词链单词数,单词链字母数等的信息,以加速查询。
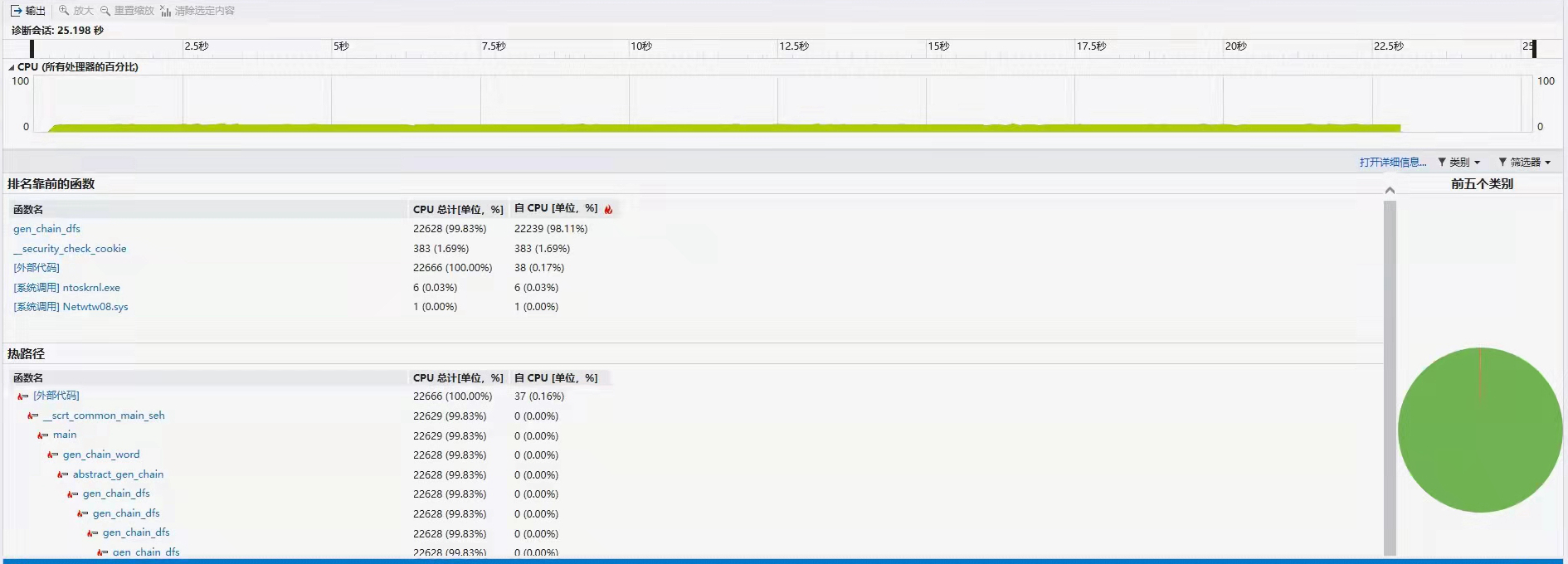
此外,在测试过程中,我们发现我们的程序面对存在较多自环的数据性能较差,例如对于以下数据:
aa axa aya aza ab axb ac axc ba bxa bb bxb byb bzb bc bxc ca cxa cb cxb cc cxc cyc czc
使用VS 2019的性能分析工具分析如下,可以发现大量时间被用于gen_chain_dfs:
添加“合并自环优化”后,使用VS 2019的性能分析工具分析如下:

这个过程包括调试在内花费了大约120分钟时间。
然而,在存在-r的情况下,最长单词链问题实质上是NPC的有向图最长路问题,我们总可以构造数据将算法卡出指数复杂度,例如使用以下数据:
aa ab ac ad ae af ba bb bc bd be bf ca cb cc cd ce cf da db dc dd de df ea eb ec ed ee ef
使用VS 2019的性能分析工具分析如下,可以发现大量时间仍然被用于gen_chain_dfs:

7. 看 Design by Contract,Code Contract 的内容,并描述这些做法的优缺点,说明你是如何把它们融入结对作业中的。(5')
- http://en.wikipedia.org/wiki/Design_by_contract
- http://msdn.microsoft.com/en-us/devlabs/dd491992.aspx
契约式设计在北航OO课程中已经有所学习,那时是对于Java语言使用JML对方法进行形式化描述,作业是通过阅读契约完成对方法的编写。当时就有同学表示对这个JML的使用意愿不高,因为编写JML过于繁琐,并且也是很容易出现错误,另外,即便编写了JML也不能自动为我测试程序,十分的鸡肋。
我对契约化设计的理解表述如下:
人相较于目前计算机人工智能而言,是一个高级的学习器,如果说计算机是图灵完备的,我想应该说人的智能应该是高于图灵完备的另一层,比如称其为通用智能,如果人类成功研发了实现通用人工智能,那就说明通用智能是完备的,否则如果人类永远也没能实现通用人工智能,就说明通用智能是不完备的,制造通用智能是上帝的事情,人类的智能只是上帝的玩具。有些有信仰的人相信后者,认为通用人工智能不可能实现,不过我没信仰,我觉得人类很有可能在未来几十年内实现通用智能然后让其自行迭代升级并帮助人类发展科学。
但就目前而言,通用人工智能还没有实现,编写代码是不是图灵机可以做的事情,至少也应该是用了神经网络的弱人工智能才能做得事情(DeepMind AlphaCode)。于是我做出如下推论:人类编写代码时定义契约表述不得不使用自然语言。不可能完备地定义一种语言来快速准确地定义一个程序的行为,并易于人类理解(比如JML肯定就不行)
综上所述,我不愿使用基于DSL的契约化编程工具(如JML和Code Contracts for .NET)
接下来,就看看我们的题目对于接口的定义是否有契约精神呢?
- 首先就是函数签名,参数的类型都写错了(Markdown排版出错,都没人复查吗?),在提醒下才修改正确。
- 然后是函数参数,根本没有任何自然语言表述它的意义,只能全靠猜。
- 然后是函数参数的类型,words和result的类型都是
char *[],words的意思比较好猜,就是一个指针列表,每个指针指向一个C字符串,存着一个单词。result的含义就不太好猜了,既可以表示【由调用者传入一个指针的指针,被调用者修改指针指向一个已经将单词用\n拼接好的整个字符串】也可以表示【由调用者传入一个指针列表,被调用者修改其中的每个指针指向一个单词(或-n中的单词链)】,配合上最开始的函数签名类型错误,再配合上其他信息,直接就让我误解为是前者。后来经过多次询问才知道了原来是后者,并且老师补上了总长度不超过20000的约定。 - 再考虑考虑怎么抛异常,老师说是自己设计。好家伙,后面不是有一道题说让互换DLL文件看看能不能成功,这让我们自己设计抛异常的方式不就完全破坏了契约吗?到时候我们设计出来的接口抛异常方法千奇斗艳,拿头来保证互换兼容性。最后我们也是发现了兼容性的问题采用了返回负值代表报错的传统C语言模式。
- 我对这种希望训练契约化编程精神,却不提供明确的契约的做法表示不理解。
- 另外就是内存释放问题,CLI和Core都会生产内存,究竟由谁释放也没有说清楚。一问也说自己设计,拿头互换保证兼容性。假如让我写前端,我团队中的后端这么给接口,我就自己去写后端了。
至于说我们怎么把契约化编程融入结对中的,那就是我们在群里轮番询问老师对指导书和测试方法的越来越精确的定义,直至我们可以去实现。
8. 计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。要求总体覆盖率到 90% 以上,否则单元测试部分视作无效。(6')
我们设置了测试点32个,如下:
TEST_METHOD(AllChainNormal) { core_test_at(1); }
TEST_METHOD(AllChainEmpty) { core_test_at(7); }
TEST_METHOD(AllChainCycle) { core_test_at(13); }
TEST_METHOD(AllChainAddition) { core_test_at(29); }
TEST_METHOD(AllChainExceed) { core_test_at(30); }
TEST_METHOD(ByWordNormal) { core_test_at(2); }
TEST_METHOD(ByWordEmpty) { core_test_at(8); }
TEST_METHOD(ByWordCycle) { core_test_at(14); }
TEST_METHOD(ByWordSetHead) { core_test_at(17); }
TEST_METHOD(ByWordSetTail) { core_test_at(18); }
TEST_METHOD(ByWordSetBoth) { core_test_at(19); }
TEST_METHOD(UniqueChainNormal) { core_test_at(3); }
TEST_METHOD(UniqueChainEmpty) { core_test_at(9); }
TEST_METHOD(UniqueChainCycle) { core_test_at(15); }
TEST_METHOD(UniqueChainAddition) { core_test_at(31); }
TEST_METHOD(TestPerformance) { core_test_at(32); }
TEST_METHOD(ByCharNormal) { core_test_at(4); }
TEST_METHOD(ByCharEmpty) { core_test_at(10); }
TEST_METHOD(ByCharCycle) { core_test_at(16); }
TEST_METHOD(ByCharSetHead) { core_test_at(20); }
TEST_METHOD(ByCharSetTail) { core_test_at(21); }
TEST_METHOD(ByCharSetBoth) { core_test_at(22); }
TEST_METHOD(ByWordAllowRNormal) { core_test_at(5); }
TEST_METHOD(ByWordAllowREmpty) { core_test_at(11); }
TEST_METHOD(ByWordAllowRSetHead) { core_test_at(23); }
TEST_METHOD(ByWordAllowRSetTail) { core_test_at(24); }
TEST_METHOD(ByWordAllowRSetBoth) { core_test_at(25); }
TEST_METHOD(ByCharAllowRNormal) { core_test_at(6); }
TEST_METHOD(ByCharAllowREmpty) { core_test_at(12); }
TEST_METHOD(ByCharAllowRSetHead) { core_test_at(26); }
TEST_METHOD(ByCharAllowRSetTail) { core_test_at(27); }
TEST_METHOD(ByCharAllowRSetBoth) { core_test_at(28); }
这些测试点均为手工构造,构造思路即为测试点名称,可望文生义,故不再赘述,输入和评测方式存储在文件中(.in和.config格式),由core_test_at函数读取和使用:
void core_test_at(const int index)
{
static char* result[20000];
check_testcase(index, "coretest");
string base = "../../cases/coretest/testcase" + to_string(index);
read_by_line(base + ".in", in_content, in_len);
read_by_line(base + ".config", config_content, config_len);
parse_config(config_content, config_len, config);
switch (config.process_method)
{
case ALL:
result_len = gen_chains_all(in_content, in_len, result);
break;
case UNIQUE:
result_len = gen_chain_word_unique(in_content, in_len, result);
break;
case BY_WORD:
result_len = gen_chain_word(in_content, in_len, result, config.head, config.tail, false);
break;
case BY_WORD_ALLOW_R:
result_len = gen_chain_word(in_content, in_len, result, config.head, config.tail, true);
break;
case BY_CHAR:
result_len = gen_chain_char(in_content, in_len, result, config.head, config.tail, false);
break;
case BY_CHAR_ALLOW_R:
result_len = gen_chain_char(in_content, in_len, result, config.head, config.tail, true);
break;
}
if (result_len < 0)
{
error_code_check(result_len, config);
}
else if (config.check_method == BY_STRING)
{
string_check(result, result_len, in_content, in_len, config);
}
else if (config.check_method == BY_UNIQUE)
{
unique_check(result, result_len, in_content, in_len, config);
}
else if (config.check_method == BY_WORD_LEN)
{
array_check_word(result, result_len, in_content, in_len, config);
}
else if (config.check_method == BY_CHAR_LEN)
{
array_check_char(result, result_len, in_content, in_len, config);
}
free_content(in_content, in_len);
free_content(config_content, config_len);
delete in_content;
delete config_content;
}
对于gen_chains_all输出顺序任意,对于其它接口,存在多个满足条件的单词链时可以返回任意一个,因此我们没有固定全部结果,而是只固定了接口的返回值,result中的内容则通过SPJ的方式验证。
我们设置了以下五种针对Core的评测逻辑,均可望文生义:
void array_check_word(char* result[], const int result_len, char* input[], const int input_len, const Config& config)void array_check_char(char* result[], const int result_len, char* input[], const int input_len, const Config& config)void unique_check(char* result[], const int result_len, char* input[], const int input_len, const Config& config)void string_check(char* result[], const int result_len, char* input[], const int input_len, const Config& config)void error_code_check(const int result_len, const Config& config)
我们的SPJ支持以下评测模式:
void array_unique_check(char* data[], const int data_len)对数组形式的单词链,检查单词是否没有重复。void string_unique_check(char data[], const int data_len)对字符串形式的单词链,检查单词是否没有重复。void head_unique_check(char* data[], const int data_len)对数组形式的单词链,检查首字母是否没有重复。void head_tail_check(char* result[], const int result_len, const Config& config)对数组形式的单词链,检查首尾字母是否满足-h和-t的约束。void array_list_check(char* data[], const int data_len)对数组形式的单词链,检查每个元素是否是单词(长度大于1),连在一起是否是单词链。void string_list_check(char* data, const int data_len)对字符串形式的单词链,检查每个元素是否是单词(长度大于1),连在一起是否是单词链。void array_in_input_check(char* data[], const int data_len, char* input[], const int input_len)对数组形式的单词链,检查每个元素是否在输入中。void string_in_input_check(char* data, const int data_len, unordered_set<string>& input)对字符串形式的单词链,检查每个元素是否在输入中。
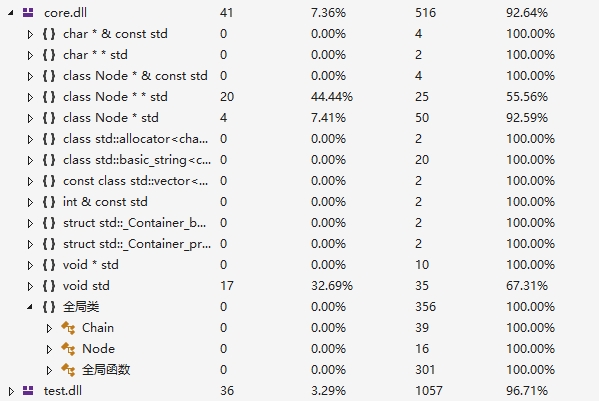
单元测试覆盖率如下:
功能测试
这并不是作业里面要求的问题,但我们认为有必要对其进行说明。(\(0'\))
我们认为,仅靠手工构造的测试用例进行单元测试并不能很好的保证程序的正确性,为此我们开发了测试数据生成器,并实现了对拍机,见代码仓库utils目录下。
测试数据生成器的接口如下:
def generate(length, no_same, self_cycle_max, no_cycle, confuse):
"""
:param length: 输入长度
:param no_same: 不允许完全一样的单词
:param self_cycle_max: 自环的数量上限
:param no_cycle: 不允许输入单词环
:param confuse: 混淆输出
:return:
"""
基于上述接口,我们采用多种不同的规则生成测试数据:
-
长度方面,我们考虑了以下情况:
- 长度为1的数据,测试边界值。
- 长度为5的数据,测试小数据。
- 长度为100的数据,测试中等数据。
- 长度为1000的数据,测试较大数据。(不存在
-r时)
-
环路方面,我们考虑了以下情况:
- 一个字母上至多存在1,2,4,5个自环。
- 除自环外,存在/不存在环路。
我们最终选择生成七类数据,每一类生成100个测试点:
for i in range(100):
count += 1
with open(f"data_no_cycle_{count}.txt", "w") as f:
f.write(generate(length=1, no_same=False, self_cycle_max=1, no_cycle=True, confuse=False))
for i in range(100):
count += 1
with open(f"data_no_cycle_{count}.txt", "w") as f:
f.write(generate(length=i // 5 + 1, no_same=False, self_cycle_max=1, no_cycle=True, confuse=False))
for i in range(100):
count += 1
with open(f"data_no_cycle_{count}.txt", "w") as f:
f.write(generate(length=100, no_same=False, self_cycle_max=1, no_cycle=True, confuse=False))
for i in range(100):
count += 1
with open(f"data_no_cycle_{count}.txt", "w") as f:
f.write(generate(length=1000, no_same=False, self_cycle_max=1, no_cycle=True, confuse=False))
count = 0
for i in range(100):
count += 1
with open(f"data_cycle_{count}.txt", "w") as f:
f.write(generate(length=1, no_same=False, self_cycle_max=2, no_cycle=False, confuse=False))
for i in range(100):
count += 1
with open(f"data_cycle_{count}.txt", "w") as f:
f.write(generate(length=i // 5 + 1, no_same=False, self_cycle_max=4, no_cycle=False, confuse=False))
for i in range(100):
count += 1
with open(f"data_cycle_{count}.txt", "w") as f:
f.write(generate(length=100, no_same=False, self_cycle_max=5, no_cycle=False, confuse=False))
在测试过程中,我们发现了自身的Bug和参与对拍组的Bug,需要说明的是,参与对拍的双方均已经过单元测试。
9. 计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(5')
我们设置了十二种异常,其中内核异常一种,CLI异常十一种:
| 异常码 | 异常类型 | 异常说明 |
|---|---|---|
0x80000001 |
内核异常 | 输入中存在单词环 |
0x80000002 |
CLI异常 | 输入了未定义的Flag |
0x80000003 |
CLI异常 | 输入的Flag冲突 |
0x80000004 |
CLI异常 | 必需的Flag不存在 |
0x80000005 |
CLI异常 | Flag参数格式错误 |
0x80000006 |
CLI异常 | 必需的Flag参数不存在 |
0x80000007 |
CLI异常 | 文件名不存在 |
0x80000008 |
CLI异常 | 文件名存在多个 |
0x80000009 |
CLI异常 | 文件不存在 |
0x800000010 |
CLI异常 | 文件无法打开 |
0x800000011 |
CLI异常 | 文件在读入时被修改 |
0x800000012 |
CLI异常 | 内存申请失败 |
-
0x80000001测试样例
- 命令行参数:
-n testcase.txt。 - 文件系统:当前目录存在名为
testcase.txt的文件,此文件可读。 - 文件内容:
ab bc cd da。 - 错误说明:输入内容存在单词环。
- 命令行参数:
-
0x80000002测试样例
- 命令行参数:
-w -x testcase.txt。 - 文件系统:不关注文件系统。
- 文件内容:不关注输入内容。
- 错误说明:
-x未定义。
- 命令行参数:
-
0x80000003测试样例
- 命令行参数:
-n -w testcase.txt。 - 文件系统:不关注文件系统。
- 文件内容:不关注输入内容。
- 错误说明:
-n和-w冲突。
- 命令行参数:
-
0x80000004测试样例
- 命令行参数:
-r testcase.txt。 - 文件系统:不关注文件系统。
- 文件内容:不关注输入内容。
- 错误说明:
-n、-w、-m、-c之一必须存在。
- 命令行参数:
-
0x80000005测试样例
- 命令行参数:
-w -h % testcase.txt。 - 文件系统:不关注文件系统。
- 文件内容:不关注输入内容。
- 错误说明:
-h的参数必须是一个字母。
- 命令行参数:
-
0x80000006测试样例
- 命令行参数:
testcase.txt -w -h。 - 文件系统:不关注文件系统。
- 文件内容:不关注输入内容。
- 错误说明:
-h的参数不存在。
- 命令行参数:
-
0x80000007测试样例
- 命令行参数:
-n。 - 文件系统:不关注文件系统。
- 文件内容:不关注输入内容。
- 错误说明:文件名不存在。
- 命令行参数:
-
0x80000008测试样例
- 命令行参数:
-n testcase.txt testcase.txt。 - 文件系统:不关注文件系统。
- 文件内容:不关注输入内容。
- 错误说明:文件名存在多个。
- 命令行参数:
-
0x80000009测试样例
- 命令行参数:
-n testcase.txt。 - 文件系统:当前目录不存在名为
testcase.txt的文件。 - 文件内容:不关注输入内容。
- 错误说明:文件不存在。
- 命令行参数:
-
0x800000010测试样例
- 命令行参数:
-n testcase.txt。 - 文件系统:当前目录存在名为
testcase.txt的文件夹,或当前目录存在名为testcase.txt的文件,但此文件被因被操作系统写有保护等原因不可读取。 - 文件内容:不关注输入内容。
- 错误说明:文件无法打开。
- 命令行参数:
-
0x800000011测试样例
- 命令行参数:
-n testcase.txt。 - 文件系统:在获取文件大小后文件读取完成前修改文件,使文件大小变化。
- 文件内容:不关注输入内容。
- 错误说明:文件在读入时被修改。
- 命令行参数:
-
0x800000012测试样例
- 命令行参数:
-n testcase.txt。 - 文件系统:当前目录存在名为
testcase.txt的文件,此文件可读。 - 文件内容:超过内存大小的若干字符。
- 错误说明:内存申请失败。
- 命令行参数:
这部分需要比较琐碎,为此我们手工构造了74个测试用例,构造思路即为测试点名称,可望文生义:
TEST_METHOD(FlagNotExistA) { cli_test_at(1); }
TEST_METHOD(FlagNotExistB) { cli_test_at(2); }
TEST_METHOD(FlagNotExistC) { cli_test_at(3); }
TEST_METHOD(FlagNotExistD) { cli_test_at(4); }
TEST_METHOD(FlagNotExistE) { cli_test_at(5); }
TEST_METHOD(FlagNotExistF) { cli_test_at(6); }
TEST_METHOD(FilenameNotExistA) { cli_test_at(7); }
TEST_METHOD(FilenameNotExistB) { cli_test_at(8); }
TEST_METHOD(FilenameNotExistC) { cli_test_at(9); }
TEST_METHOD(FilenameNotExistD) { cli_test_at(10); }
TEST_METHOD(FilenameNotExistE) { cli_test_at(11); }
TEST_METHOD(FilenameNotExistF) { cli_test_at(12); }
TEST_METHOD(FilenameDuplicateA) { cli_test_at(13); }
TEST_METHOD(FilenameDuplicateB) { cli_test_at(14); }
TEST_METHOD(FilenameDuplicateC) { cli_test_at(15); }
TEST_METHOD(FilenameDuplicateD) { cli_test_at(16); }
TEST_METHOD(FilenameDuplicateE) { cli_test_at(17); }
TEST_METHOD(FilenameDuplicateF) { cli_test_at(18); }
TEST_METHOD(FlagUndefinedA) { cli_test_at(19); }
TEST_METHOD(FlagUndefinedB) { cli_test_at(20); }
TEST_METHOD(FlagUndefinedC) { cli_test_at(21); }
TEST_METHOD(FlagUndefinedD) { cli_test_at(22); }
TEST_METHOD(FlagUndefinedE) { cli_test_at(23); }
TEST_METHOD(FlagUndefinedF) { cli_test_at(37); }
TEST_METHOD(FlagUndefinedG) { cli_test_at(38); }
TEST_METHOD(FlagUndefinedH) { cli_test_at(39); }
TEST_METHOD(ParamFormatErrorA) { cli_test_at(24); }
TEST_METHOD(ParamFormatErrorB) { cli_test_at(25); }
TEST_METHOD(ParamFormatErrorC) { cli_test_at(26); }
TEST_METHOD(ParamFormatErrorD) { cli_test_at(27); }
TEST_METHOD(ParamFormatErrorE) { cli_test_at(28); }
TEST_METHOD(ParamFormatErrorF) { cli_test_at(29); }
TEST_METHOD(ParamFormatErrorG) { cli_test_at(30); }
TEST_METHOD(ParamFormatErrorH) { cli_test_at(31); }
TEST_METHOD(ParamFormatErrorI) { cli_test_at(32); }
TEST_METHOD(ParamNotExistA) { cli_test_at(33); }
TEST_METHOD(ParamNotExistB) { cli_test_at(34); }
TEST_METHOD(ParamNotExistC) { cli_test_at(35); }
TEST_METHOD(ParamNotExistD) { cli_test_at(36); }
TEST_METHOD(FlagConflictA) { cli_test_at(40); }
TEST_METHOD(FlagConflictB) { cli_test_at(41); }
TEST_METHOD(FlagConflictC) { cli_test_at(42); }
TEST_METHOD(FlagConflictD) { cli_test_at(43); }
TEST_METHOD(FlagConflictE) { cli_test_at(44); }
TEST_METHOD(FlagConflictF) { cli_test_at(45); }
TEST_METHOD(FlagConflictG) { cli_test_at(46); }
TEST_METHOD(FlagConflictH) { cli_test_at(47); }
TEST_METHOD(FlagConflictI) { cli_test_at(48); }
TEST_METHOD(FlagConflictJ) { cli_test_at(49); }
TEST_METHOD(FlagConflictSameA) { cli_test_at(50); }
TEST_METHOD(FlagConflictSameB) { cli_test_at(51); }
TEST_METHOD(FlagConflictSameC) { cli_test_at(52); }
TEST_METHOD(FlagConflictSameE) { cli_test_at(53); }
TEST_METHOD(FlagConflictSameF) { cli_test_at(54); }
TEST_METHOD(FileNotExist) { cli_test_at(55); }
TEST_METHOD(FileUnableOpen) { cli_test_at(56); }
TEST_METHOD(CorrectA) { cli_test_at(57); }
TEST_METHOD(CorrectB) { cli_test_at(58); }
TEST_METHOD(CorrectC) { cli_test_at(59); }
TEST_METHOD(CorrectD) { cli_test_at(60); }
TEST_METHOD(CorrectE) { cli_test_at(61); }
TEST_METHOD(CorrectF) { cli_test_at(62); }
TEST_METHOD(CorrectG) { cli_test_at(63); }
TEST_METHOD(CorrectH) { cli_test_at(64); }
TEST_METHOD(CorrectI) { cli_test_at(65); }
TEST_METHOD(CorrectJ) { cli_test_at(66); }
TEST_METHOD(CorrectK) { cli_test_at(67); }
TEST_METHOD(CorrectL) { cli_test_at(68); }
TEST_METHOD(RingA) { cli_test_at(69, true); }
TEST_METHOD(RingB) { cli_test_at(70, true); }
TEST_METHOD(RingC) { cli_test_at(71, true); }
TEST_METHOD(RingD) { cli_test_at(72, true); }
TEST_METHOD(RingE) { cli_test_at(73, true); }
TEST_METHOD(RingF) { cli_test_at(74, true); }
与上文类似的,输入和评测方式存储在文件中,由cli_test_at函数调用:
void cli_test_at(const int index, bool has_ring = false)
{
static char* result[20000];
static char* ring[] = { "Ab", "bc", "cD", "DA" };
static char* chain[] = { "Ab", "bc", "cD", "DE" };
filename = nullptr;
param_h = param_t = '\0';
flag_n = flag_w = flag_m = flag_c = flag_h = flag_t = flag_r = false;
check_testcase(index, "clitest");
string base = "../../cases/clitest/testcase" + to_string(index);
read_by_line(base + ".in", in_content, in_len);
read_by_line(base + ".config", config_content, config_len);
create_temp_file("testcase.txt", has_ring ? ring : chain, sizeof(has_ring ? ring : chain) / sizeof(char*));
cli_parse_check(main(in_len, in_content), config_content, config_len);
remove_temp_file("testcase.txt");
free_content(in_content, in_len);
free_content(config_content, config_len);
delete in_content;
delete config_content;
}
10. 界面模块的详细设计过程。在博客中详细介绍界面模块是如何设计的,并写一些必要的代码说明解释实现过程。(5')
CLI:
命令行的界面模块分为四个子过程:解析命令行参数,解析文件,调用函数与输出
在最初设计的时候我们就同意应当将界面分成这四个部分分别开发。于是我们首先写了参数解析部分,并且用了很多样例来测试程序是否正确的解析了参数、是否正确的检测出错误等,我们还发现了一个特殊的样例
Wordlist.exe -w -c
这个样例具有两个正确的解读,一个是找出"-w"这个文件的最大单词字母链,另一个是找出"-c"这个文件的最大单词数链,产生了二义性。据此与老师进行反馈后增加了"打开的文件必须以.txt结尾"的特殊限制,解除了这个冲突,我们将首先判断某个参数是否以.txt结尾来决定其是否是文件,然后再判断参数。
解析文件设计为第一次遍历时处理大小写和特殊字符,第二次遍历找到符合单词定义的字符串,将字符串首地址存入result。
错误处理的设计经过了多次变动,最开始我们为了性能采用了返回负值的错误处理方法,不过发现我们会因此多些许多不必要的代码,于是后来改成了用throw抛出int类型错误码的方式,不过又发现这种方式对dll调用的通用性很差(异常不能抛到Python里接住)于是就仅在dll的调用接口处设计为返回负值,其他地方仍采用返回负值错误码来代表错误。
阶段一:
// 第一个函数parse_params将命令行参数解析并判断格式错误和重复错误
void parse_params(int argc, char* argv[]);
// 在确保参数在形式上正确后,conflict_check函数会对所有flag进行细致的存在性检查和冲突检查。
void conflict_check();
解析文件:
// read_file函数会在充分考虑到异常的情况下将一个文件读取到内存中
void read_file(const char* filename, char*& content, int& len);
// split_content会正确的将一个装有输入的字符数组的所有非英文字符转换为'\0',并将大写字母转换为小写字母,然后会找出所有符合“单词”定义的字符串,将它们的首地址指针放入result内。
int split_content(char* content, const int len, char* result[]);
调用函数:
int main(int argc, char* argv[])
{
int len;
char* content = nullptr;
static char* words[10005]; // 有约定称单词数最多不超过10000个
static char* result[20005]; // 有约定称结果最多不超过20000行
try
{
parse_params(argc, argv);
conflict_check();
read_file(filename, content, len);
int word_count = split_content(content, len, words);
if (flag_n)
{
int result_len = gen_chains_all(words, word_count, result);
if (result_len < 0) // 此处有接口转换,如果dll返回值是赋值,则表示有异常,改用throw方式与其他异常统一处理
{
throw result_len;
}
write_to_screen(result, result_len);
}
else if ...
}
catch (int eid)
{
const char* description[] =
{
"unexpected word cycle detected", // 1
"..."
};
int index = ((eid ^ 0x80000000) - 1) % (sizeof(description) / sizeof(char*));
printf("expection (id 0x%X) catched: %s\n", eid, description[index]);
}
}
输出:
// 将从core返回的结果打印到屏幕上
void write_to_screen(char* result[], const int len);
// 将从core返回的结果打印到文件solutions.txt里
void write_to_solution(char* result[], const int len);
GUI:
GUI的设计分为显示模块、接口包装模块、字符处理模块三部分。
对于这样一款简单的单页面应用,不必应用MVC设计模式,直接将V(iew)和C(ontrollor)融合在一起了。
有关于参数的解析,我们认为避免用户犯错要比让用户犯错之后再提醒更好,前端会自动将冲突的按钮禁用,自动保证首位字母的参数为小写字母,利用文件选取器保证用户一定选择了一个存在的并且可以打开的.txt文件。在解析时,会自动将用户输入的非ASCII码转换为替代字符.来告知用户输入虽然不合法,但是我们使用了替代的方案来进行执行。
接口包装模块是把ctypes调用dll接口的复杂方法转换为Python风格的写法
字符处理模块处理无害化输入和分词等较为复杂的字符串工作,因为Python很强大所以也没写几行。
文件的导入和导出与错误检测大部分都由PyQt代劳了,所以没有为此单独包装模块。
11. 界面模块与计算模块的对接。详细地描述 UI 模块的设计与两个模块的对接,并在博客中截图实现的功能。(4')
Core:
Core通过extern "C" _declspec(dllexport)将函数导出到动态链接库。
函数签名与作业题面中一致,words和result指针列表的内存分配由调用者负责,words内的指针指向的内存由调用者负责管理,result内的指针指向的内存由被调用者Core负责管理,Core被调用时在全局区域的一个vector<string> result_storage中存上结果并让result里的指针指向这一块内存区域,在第二次调用函数时首先会清空result_storage,回收之前的内存,这样可以保证多次调用内存不泄露。
调用参数words约定为已经处理好的转换为小写的字符串数组。
函数的返回值若为正值则与题面描述一致,若为负值则说明core报错,错误码在全局中定义。
CLI:
CLI通过extern "C" _declspec(dllimport)导入动态链接库中的函数。
CLI程序通过解析参数完成对以下字段的填充:
bool flag_n = false;
bool flag_w = false;
bool flag_m = false;
bool flag_c = false;
bool flag_h = false;
bool flag_t = false;
bool flag_r = false;
char param_h = '\0';
char param_t = '\0';
char* filename = nullptr;
之后会读入文件,将文件中的单词切分出来并转换为小写。
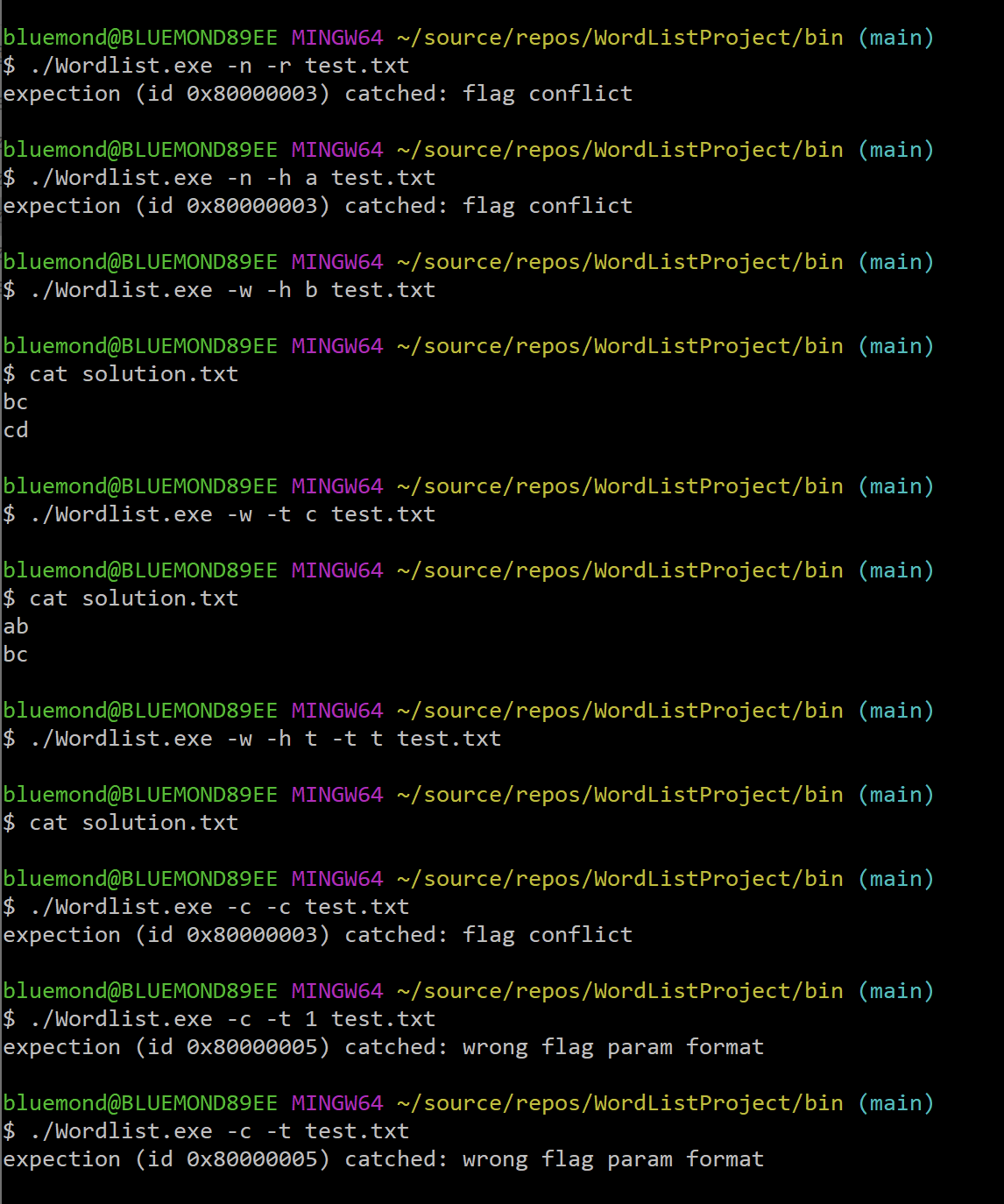
验证参数无误后,将会调用Core导出的函数,如果发现有单词环的报错则打印出来,否则将答案按要求输出到文件solution.txt或控制台。

正常的功能实现
加入了特殊参数以及一些异常的抛出
GUI:
GUI采用PyQt编写,通过Python的ctypes包调用dll中的函数。
我们编写了一个接口转换模块,将C风格的接口转换为Python风格的接口,供其他Python模块调取。
Python写字符串处理是很爽的,两行搞定了C++二十几行的处理。
用户会在点击按钮后收集界面上所有的参数,传入内核获取结果后显示在前端UI上。
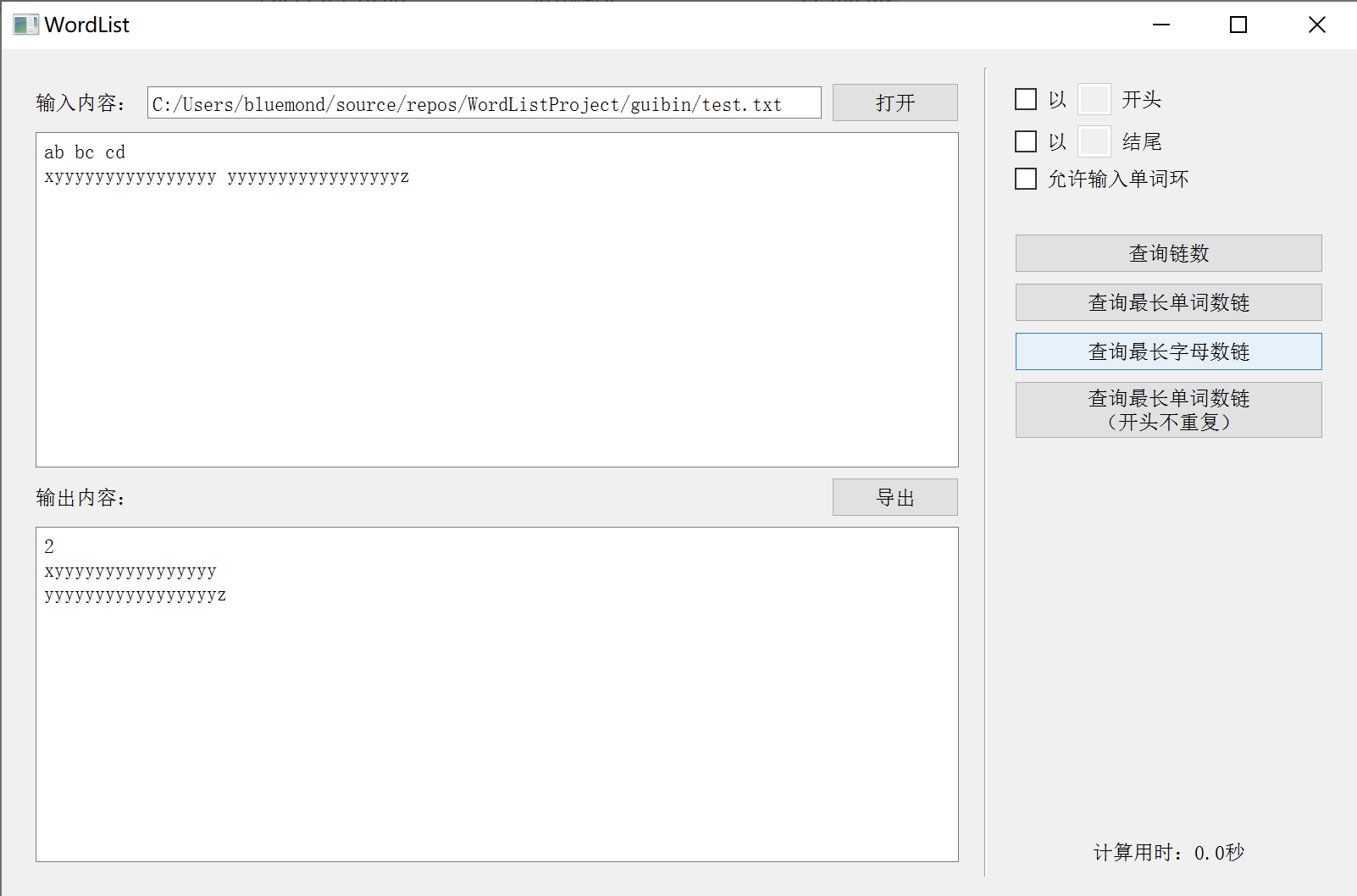
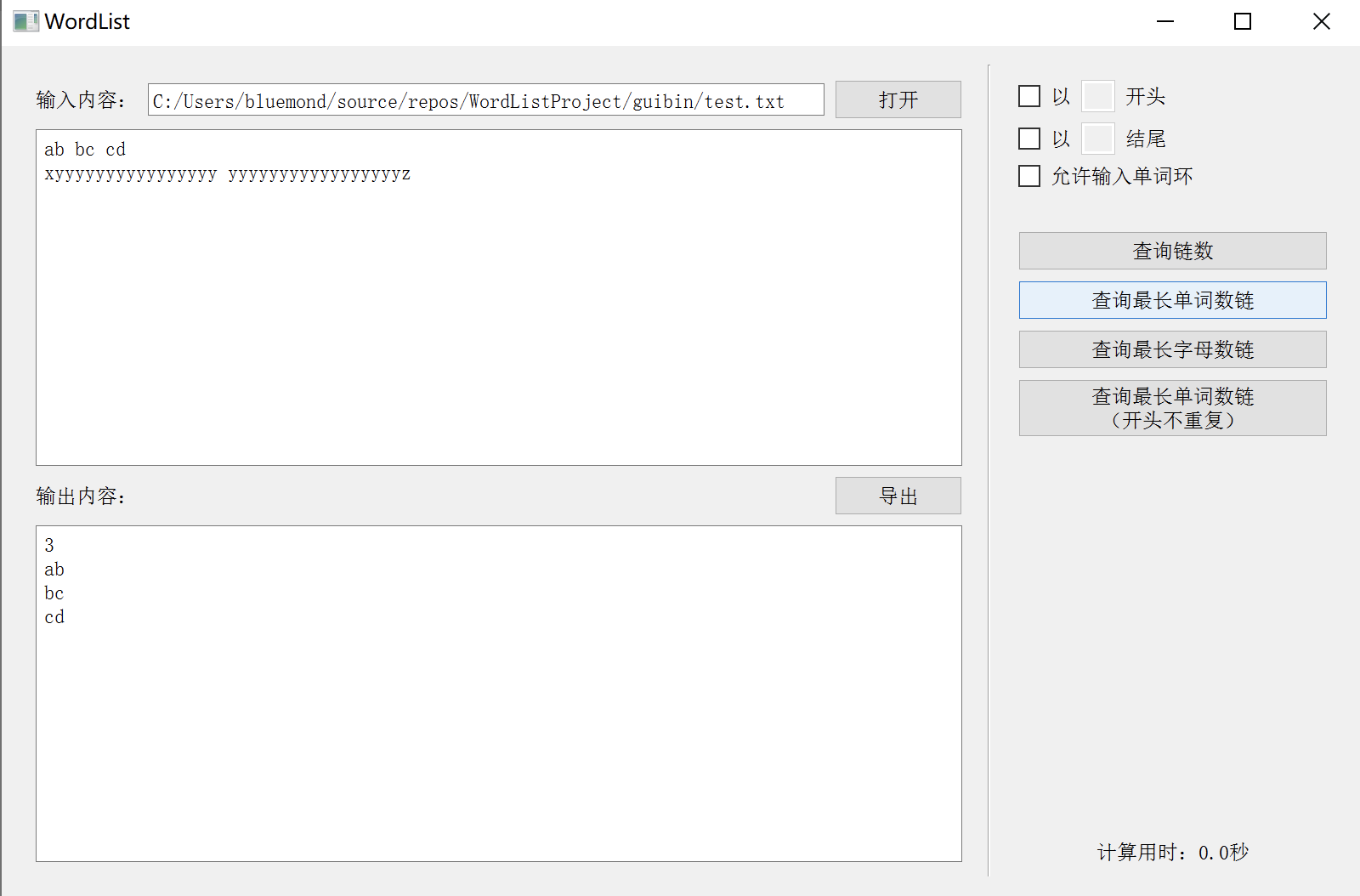

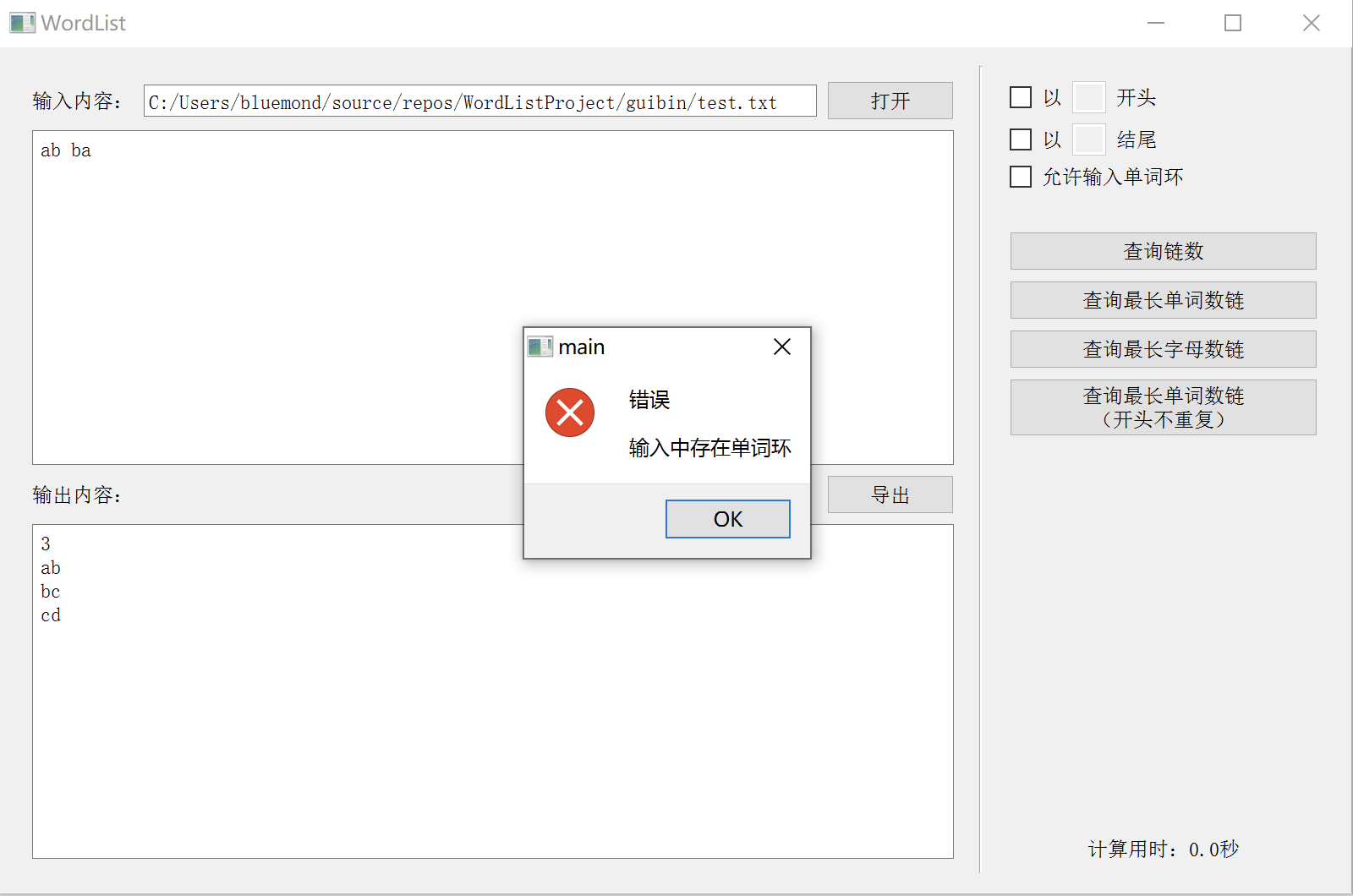
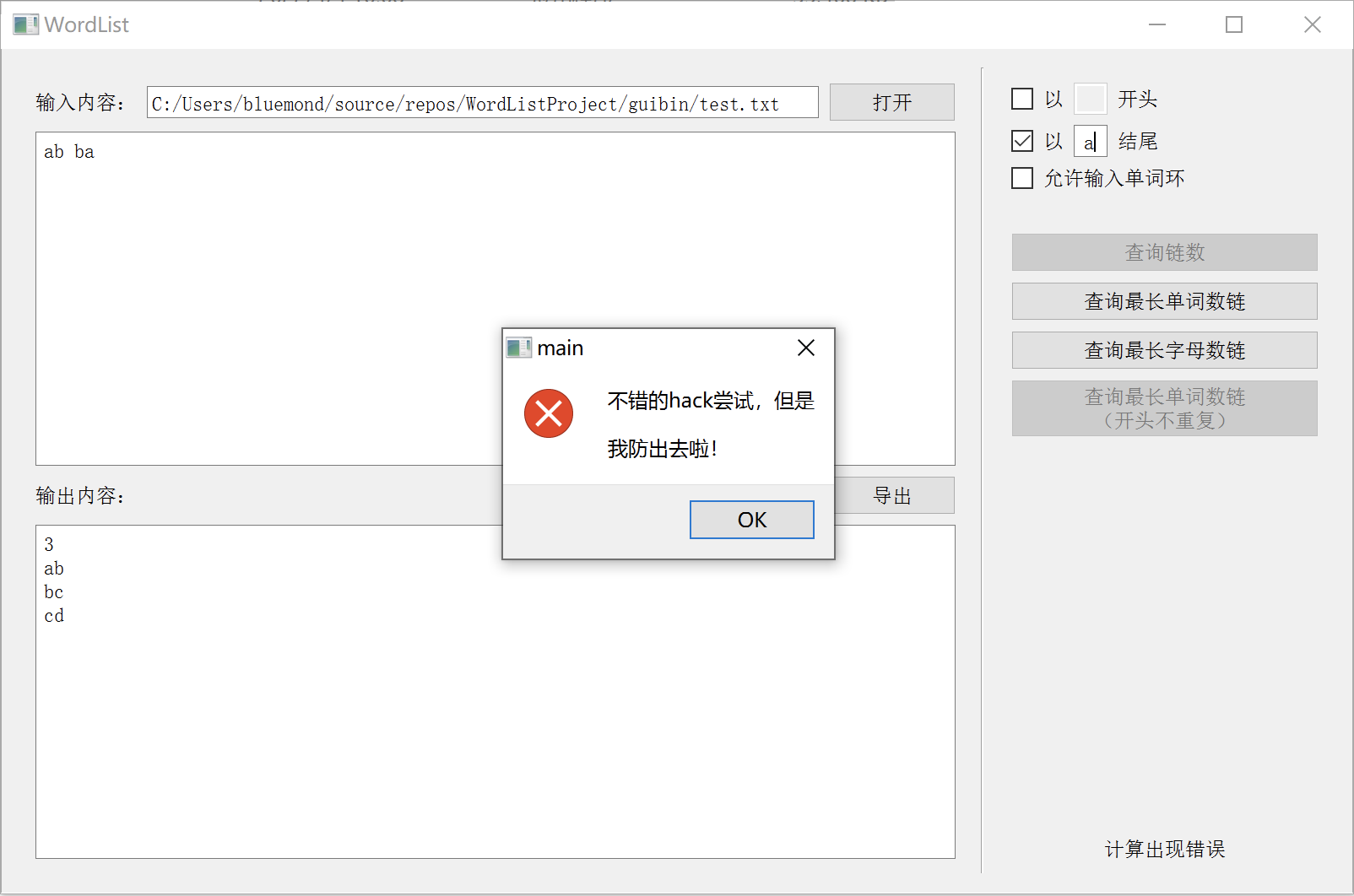
松耦合测试
在博客中指明合作小组两位同学的学号,分析两组不同的模块合并之后出现的问题,为何会出现这样的问题,以及是如何根据反馈改进自己模块的。(\(10'\))
合作小组两位同学的学号是:
- Roife:
19373189 - Yip Coekjan:
19373372
合作小组的模块使用\(C\#\)开发,为此我们需要额外安装以下内容:
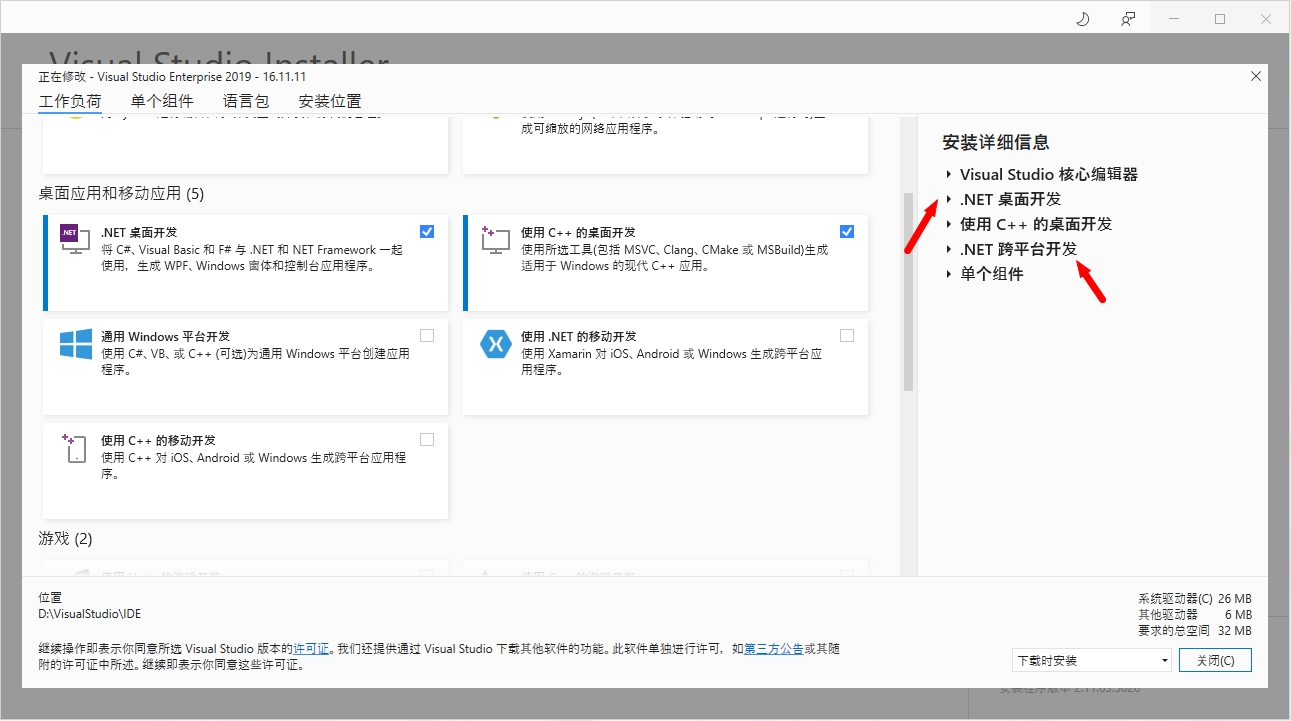
在C++中,我们可以通过使用下面的方式引入DLL:
#ifdef _DEBUG
#pragma comment(lib, "../x64/Debug/core.lib")
#else
#pragma comment(lib, "../x64/Release/core.lib")
#endif
但C#生成的DLL不附带.lib文件,为此需要修改引入DLL的方式,此外合作小组的接口放入了命名空间,因此需要套一层壳:

最后,需要进行以下两项设置和一处更改,即可跑通:
- 调整项目属性-配置属性-高级-公共语言运行时支持为公共语言运行时支持(/clr)。
- 调整项目属性-配置属性-C/C++-语言-符合模式为否(/permissive)。
- 更改内存分配方式,全部内存由调用者分配,既将result指针数组中所有的指针指向已分配的空间。
12. 描述结对的过程,提供两人在讨论的结对图像资料(比如 Live Share 的截图)。关于如何远程进行结对参见作业最后的注意事项。(1')
我们全程采用了线下结对编程方式,两个人约好在每天晚上6点到新主楼的长椅子上并排坐,每隔约一小时领航员提醒换一次人。

13. 看教科书和其它参考书,网站中关于结对编程的章节,例如:http://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html ,说明结对编程的优点和缺点。同时描述结对的每一个人的优点和缺点在哪里(要列出至少三个优点和一个缺点)。(5')
杰对编程的优缺点
我和我的同伴都是属于可以独立写出正确的程序的人,我们都比较擅长写测试用例和自动化测试,而且我们也比较擅长在脑海中对程序的正确性进行形式化证明。这时候两人一起协作会发生什么呢?
- 在设计时可以交流互补:两个人同时仔细阅读了作业题面,在设计程序整体架构和每个函数的算法和实现时可以极大程度上覆盖到题面中不易察觉的细节。对“某个实现能否解决问题”的问题经过了两个大脑的思考,可以及时发现缺陷并改正,这是我认为结对编程最大的优点。
- 在实现时可以交流经验:我们并排坐在新主楼每隔40分钟换人编程。由于我们对C++都不是完备的熟练运用,在进行到某些实现时可以提醒对方用一个对方不熟悉的C++语法,用简单地代码解决问题。因此可以说这份代码的技术细节是两个人的并集。
- 代码被充分审查:两个理解代码的人通过白盒测试找bug,效率极高。
- 非重要功能可以按特长分别开发:比如这次作业我开发GUI,我的同伴开发单元测试。对这种不需要严格审核的代码分别开发以提升效率
- 能学到新的知识:我曾经构造数据的时候虽然对数据异质性有考虑,但是有时过于随意地通过极端化的整数生成器随机生成感觉上异质的数据。在向 @Chenrt 佬学习后发现其实构造数据应当将数据的特征参数化,然后再有特征的基础上进行随机生成,显然会让数据的覆盖面更广,特征更明显。我感觉受益匪浅。
- (缺点)编写代码有点急躁:平时自己写代码都会想好久然后写一点,再想一会再写一点,后来才逐渐提速写的快起来。结对编程时我尽量控制着自己的path保持足够的思考,但还是由于无形的压力来增加写代码的速度,这使得刚开始时程序的架构设计的不是太好。
我的优缺点
- OO狼人出身,略懂构造数据和制造评测机
- 曾经写过PyQt的GUI,有相关经验
- 对代码质量要求比较高
- (缺点)脑子慢,写C++代码比较肉,看起来效率比较低
- (缺点)中度非Windows用户,操作Windows和VS十分苦手。
队友的优缺点
- OO金刚狼出身,CO DataMaker,善于构造极强数据,也擅长制作自动评测
- 敲代码快速熟练
- CTFer,擅长挑出指导书的bug,也擅长挑出程序里的bug
- 对代码质量要求比较高
- (缺点)Jetbrain全家桶用户,没用过VS。
14. 在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块上实际花费的时间。(0.5')
见后方
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 6 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 6 |
| Development | 开发 | 1250 | 1745 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 165 |
| · Design Spec | · 生成设计文档 | 120 | 10 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 60 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 480 | 960 |
| · Code Review | · 代码复审 | 120 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | 420 |
| Reporting | 报告 | 80 | 80 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1360 | 1831 |
致谢
感谢 @Chenrt 佬带我杰对编程

