
为什么不推荐select * from
为什么不推荐select * from
1. 不必要的磁盘I/O
对于无用的大字段,如 varchar、blob、text,会增加 io 操作,准确来说,长度超过 728 字节的时候,会先把超出的数据序列化到另外一个地方,因此读取这条记录会增加一次 io 操作。(MySQL InnoDB)
2. 不需要的列会增加数据传输时间和网络开销
保不住真的有人用*把TEXT、MEDIUMTEXT或者BLOB类型的字段也查出来了,总数据量大了,这就直接导致网络传输的次数变多了。
3. 无法使用覆盖索引
为了说明这个问题,我们需要建一个表
CREATE TABLE `user_innodb` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`gender` tinyint(1) DEFAULT NULL,
`phone` varchar(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `IDX_NAME_PHONE` (`name`,`phone`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
我们创建了一个存储引擎为InnoDB的表user_innodb,并设置id为主键,另外为name和phone创建了联合索引,最后向表中随机初始化了500W+条数据。
InnoDB会自动为主键id创建一棵名为主键索引(又叫做聚簇索引)的B+树,这个B+树的最重要的特点就是叶子节点包含了完整的用户记录,大概长这个样子。
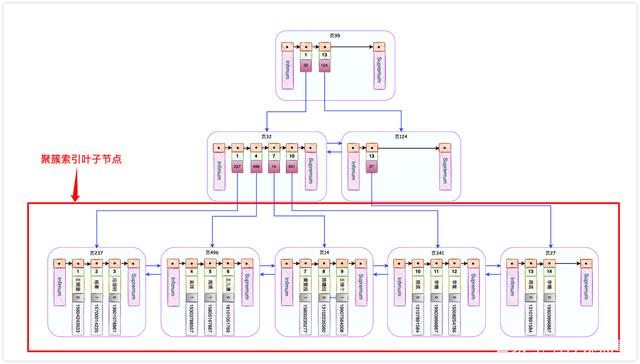
如果我们执行这个语句
SELECT * FROM user_innodb WHERE name = '蝉沐风';
使用EXPLAIN查看一下语句的,发现这个SQL语句会使用到IDX_NAME_PHONE索引,

这是一个二级索引。二级索引的叶子节点长这个样子:
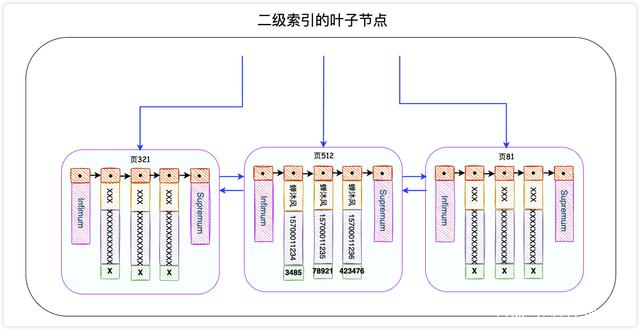
InnoDB存储引擎会根据搜索条件在该二级索引的叶子节点中找到name为蝉沐风的记录,但是二级索引中只记录了name、phone和主键id字段(谁让我们用的是SELECT *呢),因此InnoDB需要拿着主键id去主键索引中查找这一条完整的记录,这个过程叫做回表。
想一下,如果二级索引的叶子节点上有我们想要的所有数据,是不是就不需要回表了呢?是的,这就是覆盖索引。
举个例子,我们恰好只想搜索name、phone以及主键字段。
SELECT name, phone FROM user_innodb WHERE name = "蝉沐风";
会显示Using index,表示我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是使用了覆盖索引,能够直接摒弃回表操作,大幅度提高查询效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号