springcloud随手笔记
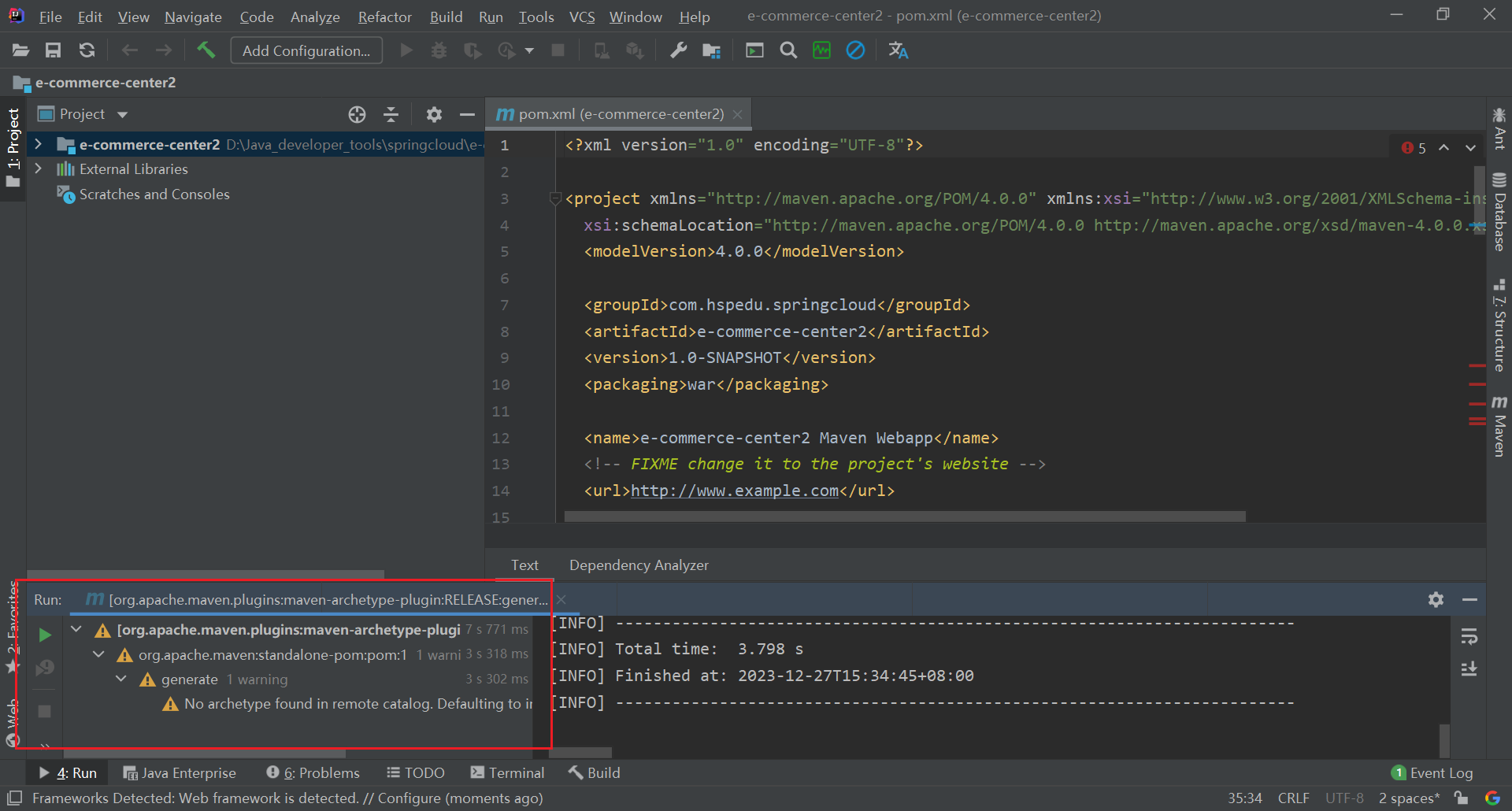
1 创建Maven项目报错 [WARNING] No archetype found in remote catalog. Defaulting to internal catalog(已解决)
问题描述:当创建maven-archetype-webapp时出现警告提示
[WARNING] No archetype found in remote catalog. Defaulting to internal catalog
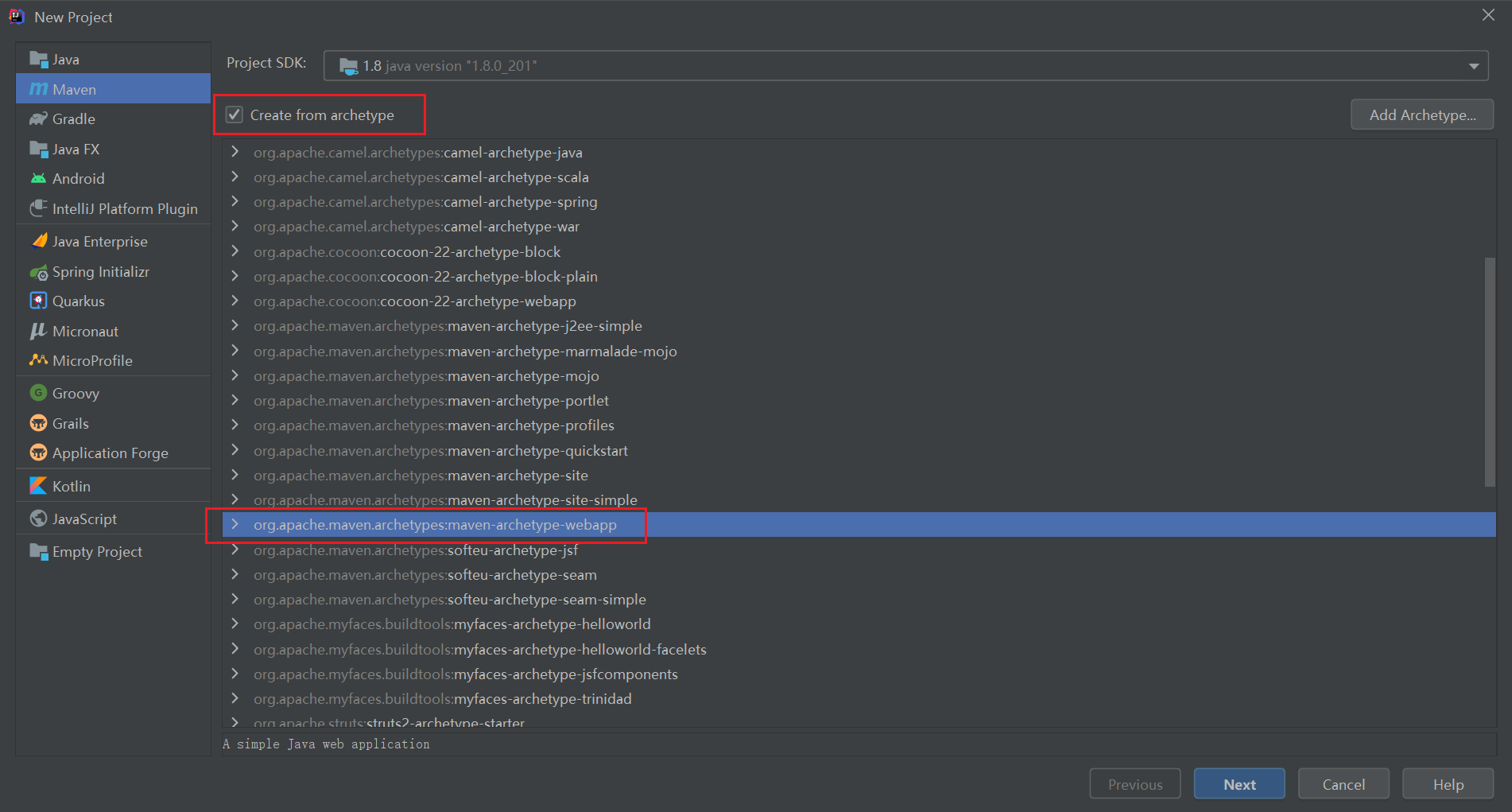
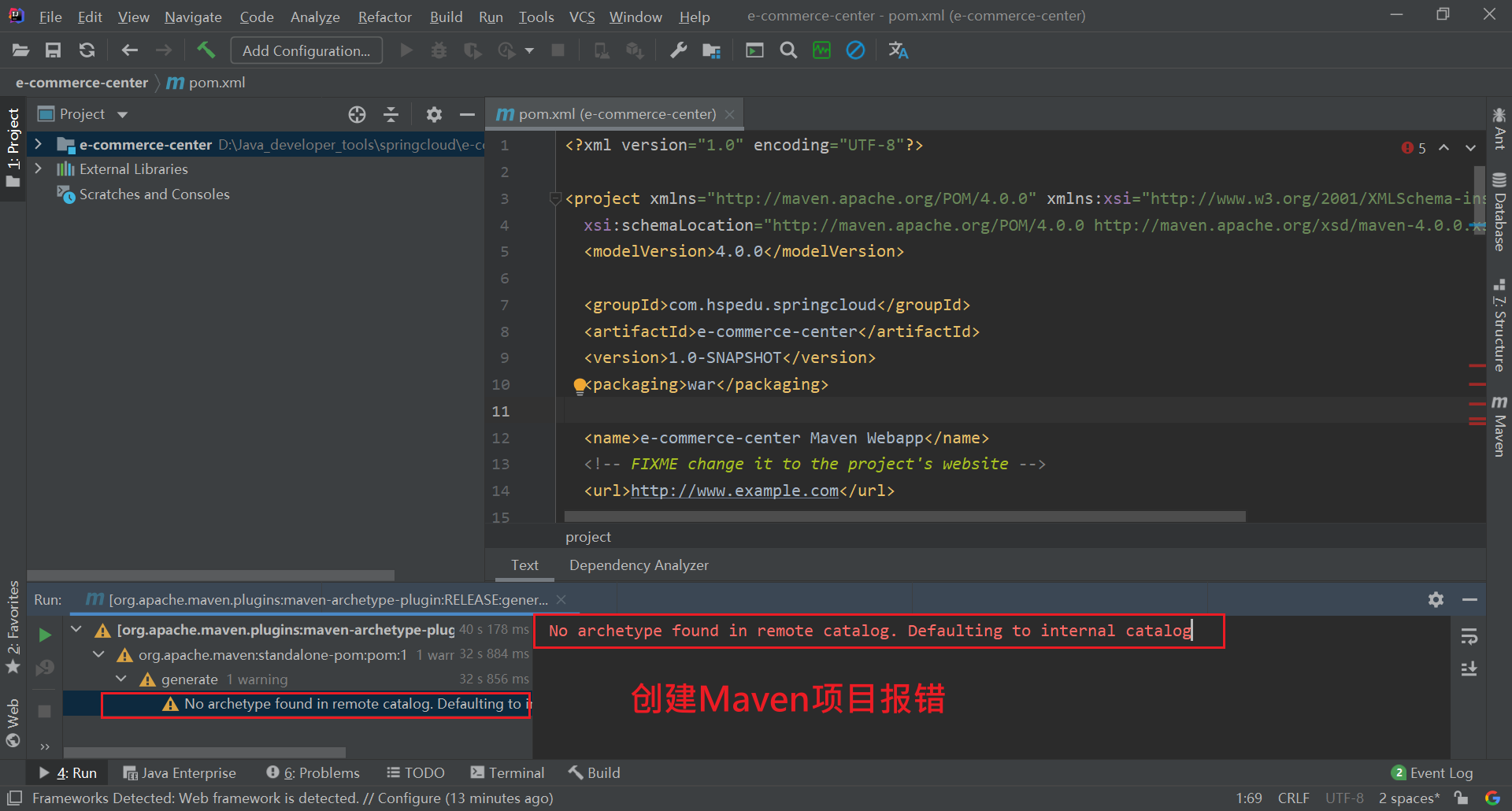
解决方法参考链接https://blog.csdn.net/gao_zhennan/article/details/123247536
该博客文章讨论了在使用 Maven 生成项目模板时遇到的一个常见警告:“No archetype found in remote catalog. Defaulting to internal catalog”,并提供了解决方案。问题发生在使用 Maven 命令 mvn archetype:generate 时,这通常是由于 Maven 配置的镜像仓库中不包含 archetype-catalog.xml 文件导致的。作者在调试过程中发现从配置的阿里云镜像仓库中无法找到该文件。
解决方案分为以下几步:
-
在运行
mvn archetype:generate时(这里改为在idea创建Maven项目时),暂时不使用任何镜像仓库,即使用 Maven 默认的中央仓库。 -
创建项目模板后,再配置镜像仓库以获取依赖和插件。
此外,作者还提到,这个警告并不会影响 Maven 命令创建项目的功能。对于希望从中央仓库获取更多项目模板的用户,可以直接访问 https://repo1.maven.org/maven2/archetype-catalog.xml 并将该文件保存到 Maven 用户目录(通常是 ~/.m2/)中。这样做可以让用户访问上千个项目模板。尽管这样做可能仍会出现警告,但对正常使用 Maven 没有影响。
解决步骤:
-
修改Maven配置文件
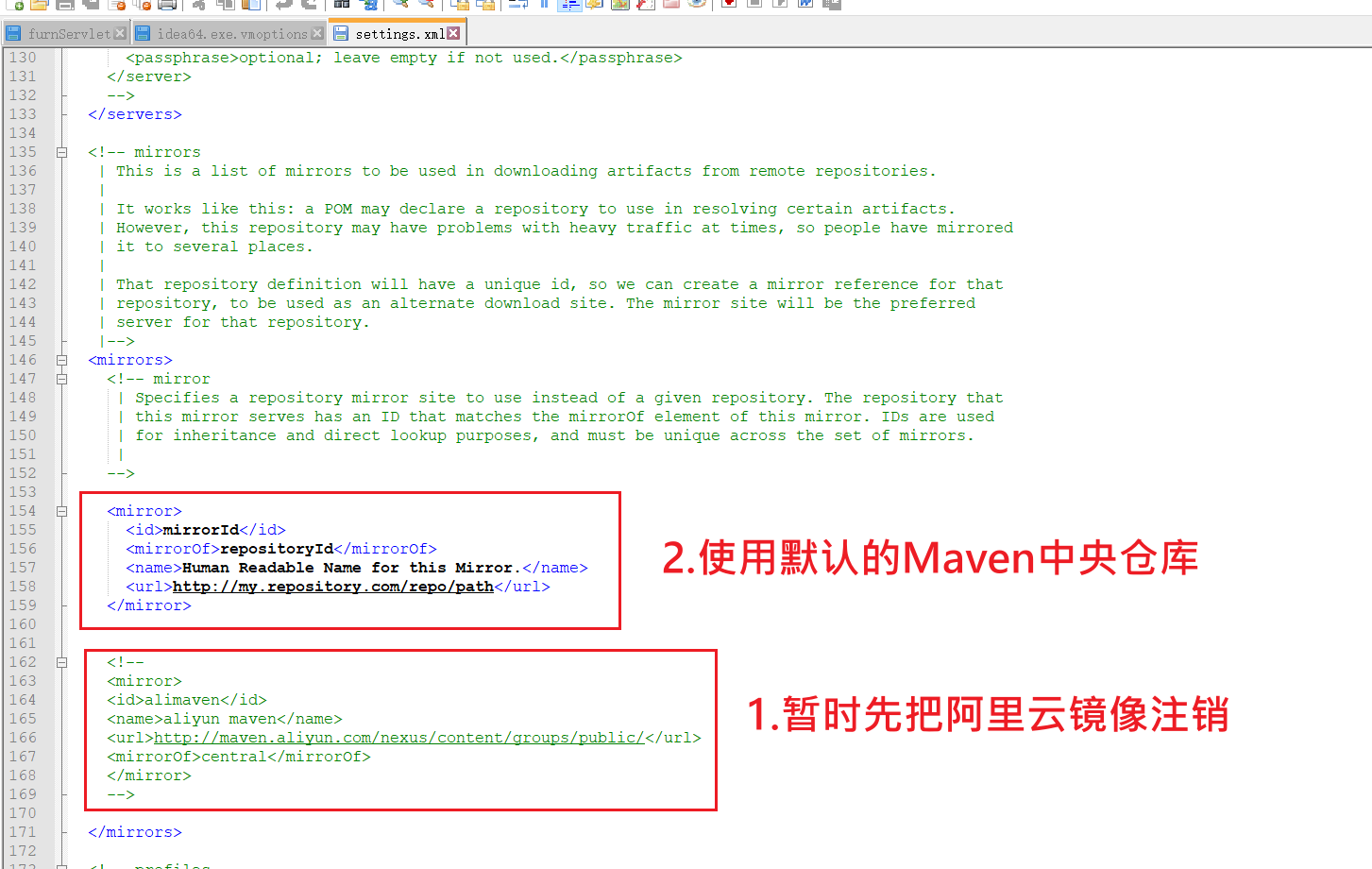
-
重新创建 maven-archetype-webapp 项目,注意此时需要使用外网,需要将***的TUN模式打开!!否则还是会出错
-
创建成功
![image-20231227150403326]()
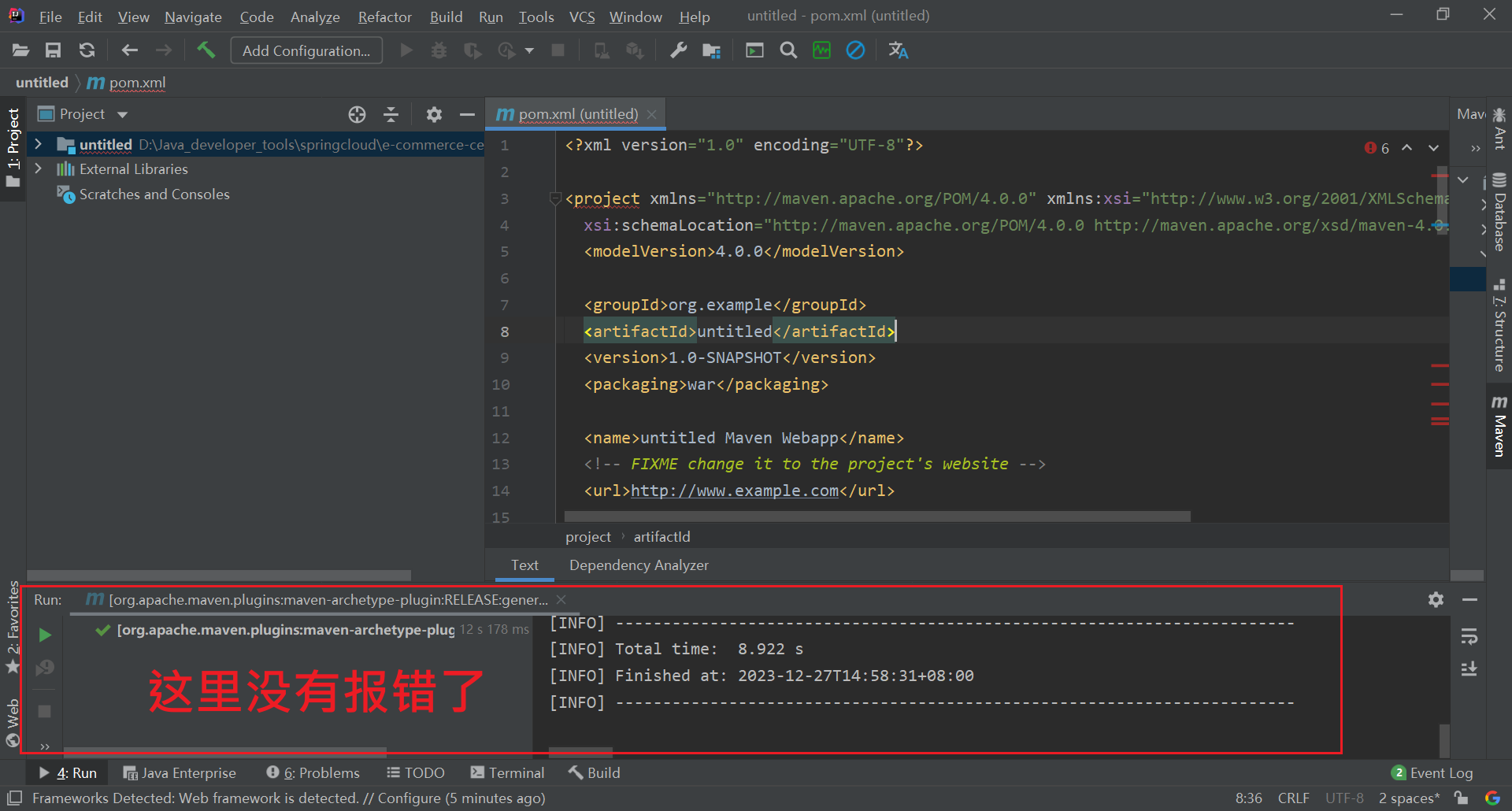
因为这个警告不影响使用 可以仍然使用阿里镜像创建的项目 e-commerce-center2
警告:No archetype found in remote catalog. Defaulting to internal catalog
知识点随笔记录
1.通过 pom + import 解决 maven 单继承机制
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId> <version>2.2.2.RELEASE</version>
<!-- 老师解读:
1. type: pom 和 scope import 配合使用
2. 表示父项目的子模块,在引入 springboot 相关依赖时锁定版本为2.2.2.RELEASE
3. 通过 pom + import 解决 maven 单继承机制
-->
<type>pom</type>
<scope>import</scope>
</dependency>
如何理解pom + import的作用?
GPT
在 Maven 中,pom 和 import 的组合使用是一个高级功能,主要用于依赖管理。这个组合在 <dependencyManagement> 部分中使用,以控制项目的依赖版本,而不是在 <dependencies> 中直接声明依赖。下面是对您提供的代码片段的解释和 pom + import 作用的理解:
-
类型为
pom: 在 Maven 中,依赖的<type>元素默认是jar,表示依赖是一个 JAR 文件。当<type>被设置为pom时,表示这个依赖实际上是一个 Maven 项目的 POM 文件。在这种情况下,Maven 将处理这个 POM 文件中定义的依赖和配置,而不是引入一个实际的代码库。 -
作用域为
import:<scope>元素通常用来定义依赖的范围(如compile,runtime,test,provided)。当<scope>设置为import时,这意味着当前 POM 文件将导入另一个 POM 文件中的<dependencyManagement>部分。这是一种特殊的作用域,仅在<dependencyManagement>部分中有效。 -
合作机制: 当
<type>为pom并且<scope>为import时,Maven 将导入指定的 POM 文件中的<dependencyManagement>部分。这样做的结果是,当前项目可以使用被导入的 POM 文件中指定的依赖版本,而不需要在每个子模块中重复这些信息。这样可以确保项目中的所有模块都使用相同的依赖版本,这对于保持大型项目的一致性非常重要。 -
解决 Maven 单继承机制的限制: Maven 项目支持从单个父 POM 继承,这称为单继承机制。通过使用
<type>pom</type>和<scope>import</scope>,可以实现类似于多继承的效果。这意味着你可以导入多个 POM 文件的依赖管理信息,从而绕过单继承的限制。
在你的示例中,spring-boot-dependencies 是 Spring Boot 的一个特殊 POM,它包含了所有 Spring Boot 所需依赖的推荐版本。通过导入这个 POM,你的项目将自动使用 Spring Boot 推荐的依赖版本,这样可以避免版本冲突并简化依赖管理。
2Maven 在 dependencyManagement 中导入配置报错Dependency 'org.mybatis.spring.boot:mybatis-spring-boot-starter:2.2.0' not found
问题发生的原因:
在刷新 Maven 时,这通常是由于 Maven 配置的镜像仓库/中央仓库中不包含
org.mybatis.spring.boot:mybatis-spring-boot-starter:2.2.0文件导致的。在调试过程中发现从配置的阿里云镜像仓库中无法找到该文件。
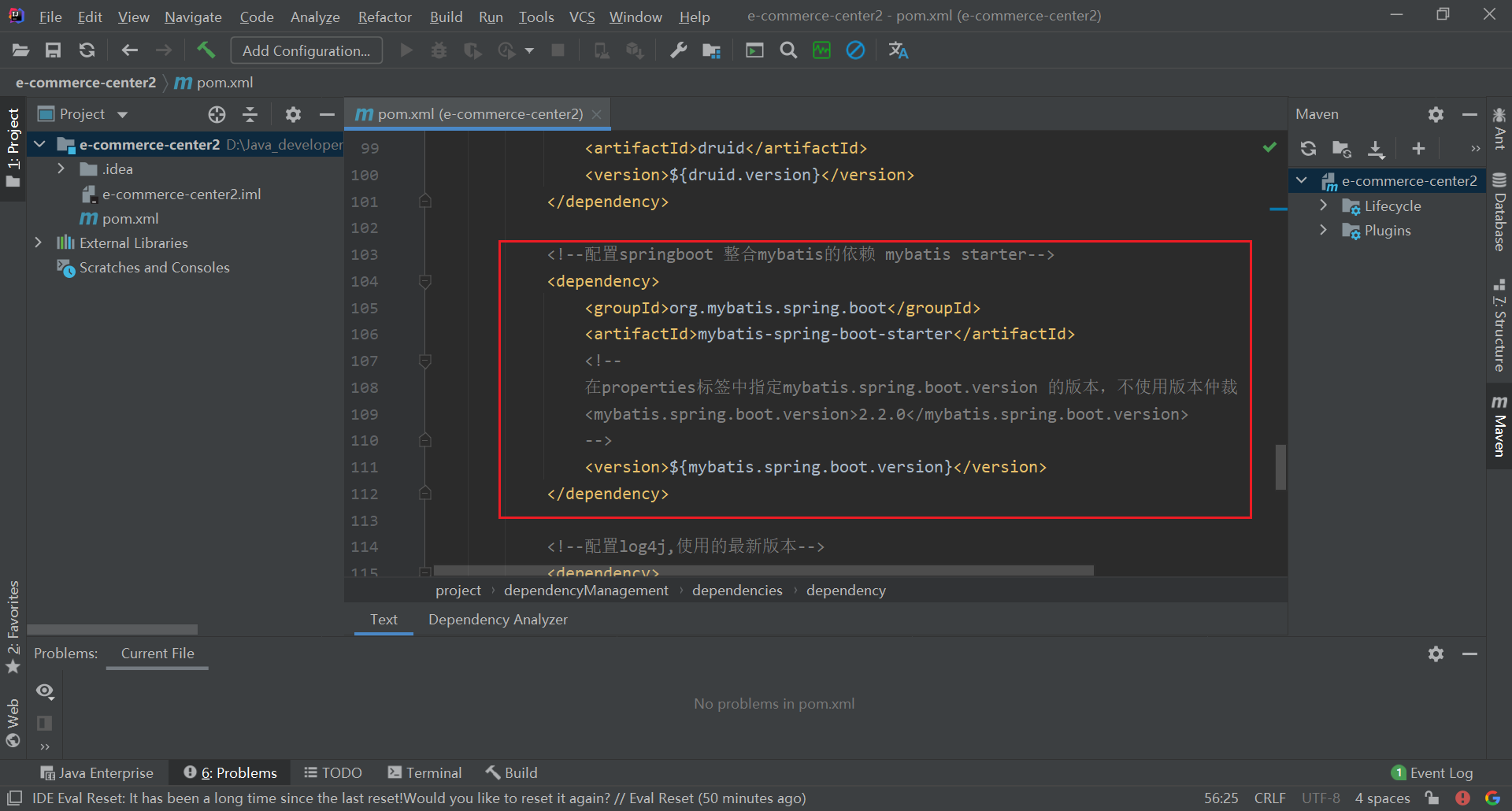
<dependencyManagement>
<dependencies>
<!--配置springboot 整合mybatis的依赖 mybatis starter-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<!--在这里指定mysql、mybatis.spring.boot.version的版本,不使用版本仲裁
<properties>
<mybatis.spring.boot.version>2.2.0</mybatis.spring.boot.version>
</properties>
-->
<version>${mybatis.spring.boot.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
创建springcloud项目时,在<dependencyManagement>标签中锁定版本时报错如下:
刷新Maven还是报错
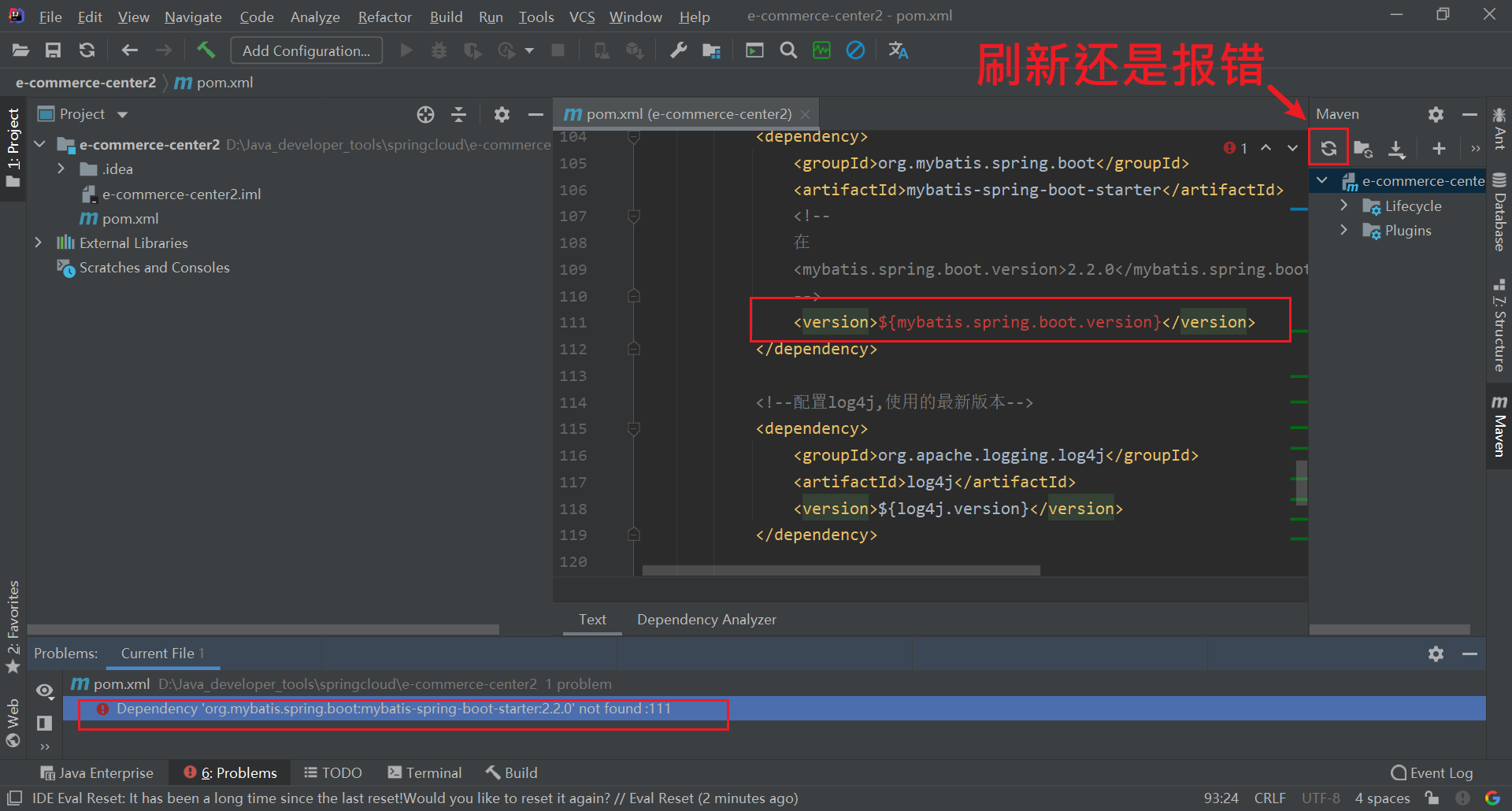
因为这时的maven配置的是Maven中央仓库
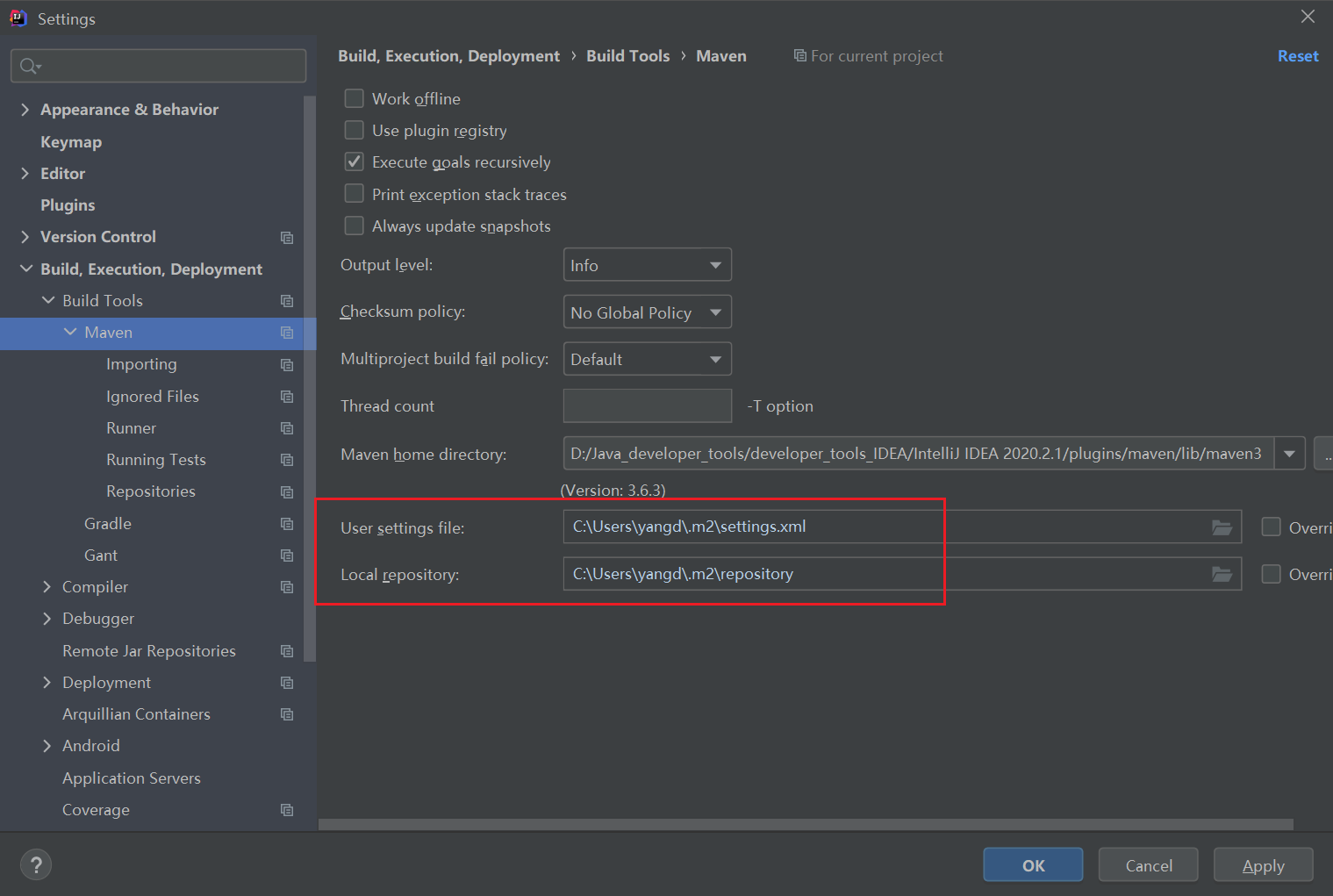
C:\Users\yangd.m2\settings.xml中的配置如下:
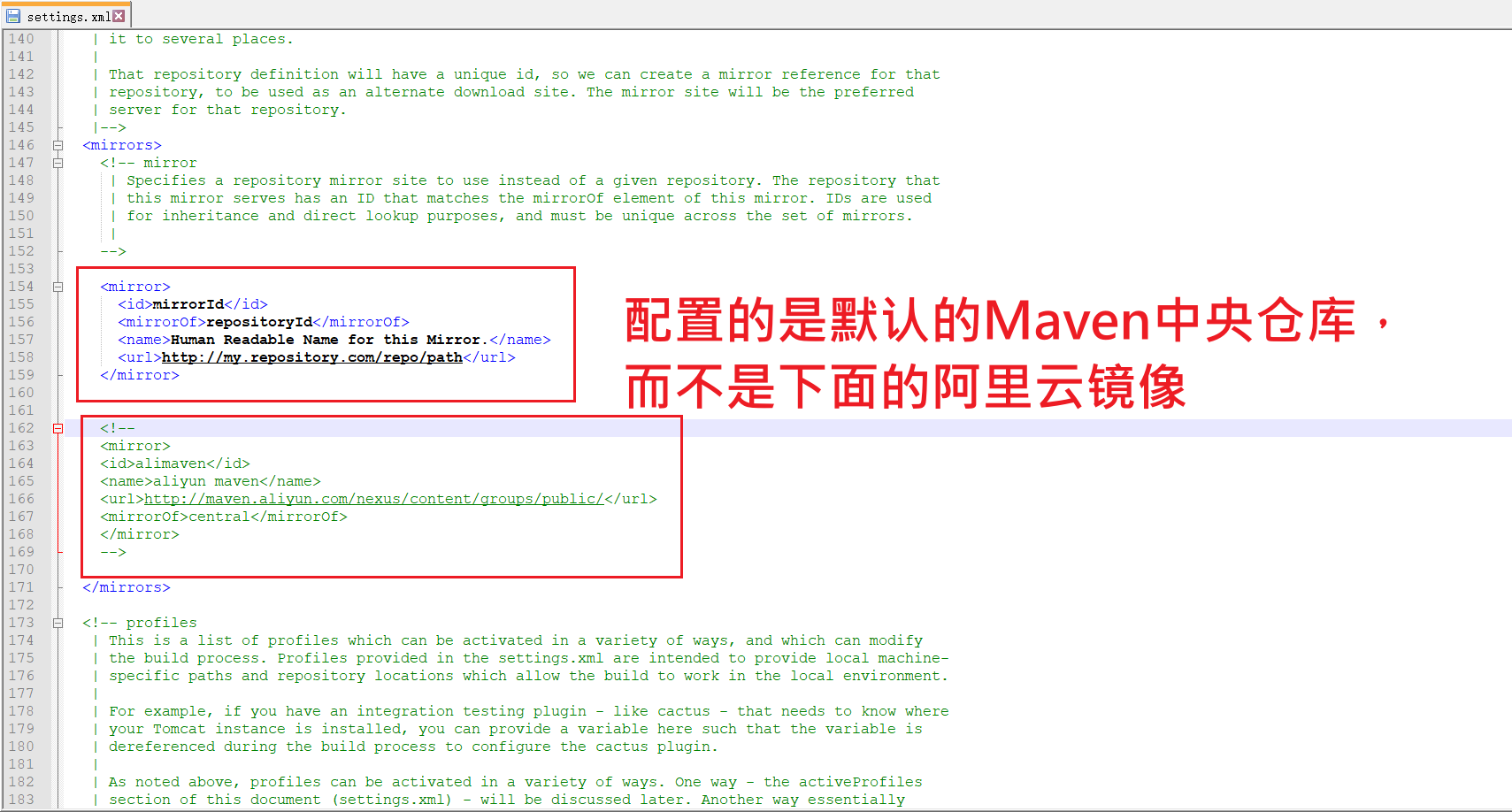
配置在Maven设置文件中默认的url地址:http://my.repository.com/repo/path
查看maven中央仓库文档https://mvnrepository.com/ 是否有版本为2.2.0的mybatis-spring-boot-starter依赖 发现有2.0.0这个版本
从中央仓库下载依赖的地址是 https://repo.maven.apache.org/maven2
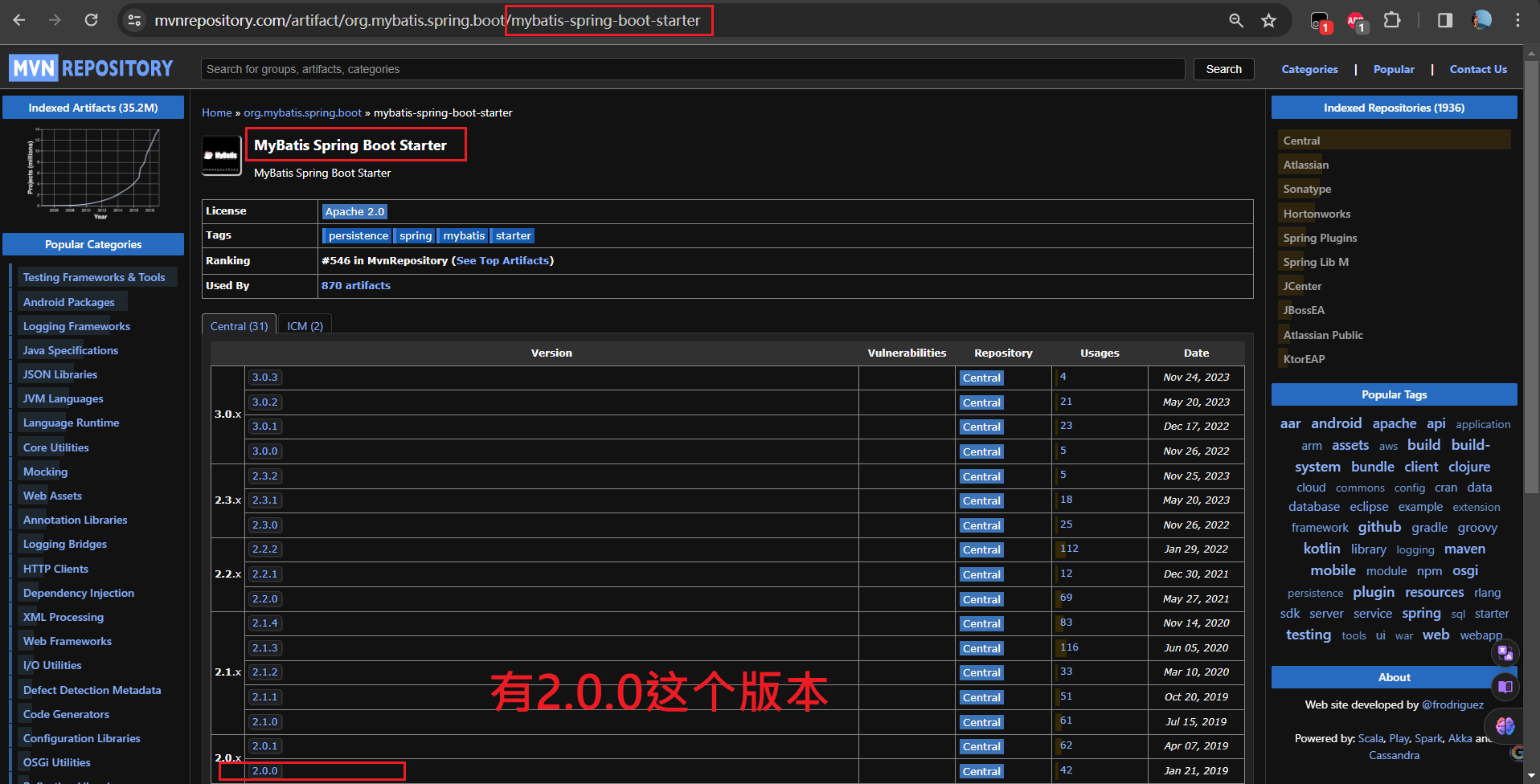
解决方法,新建一个Maven项目 真正的导入一下这个jar
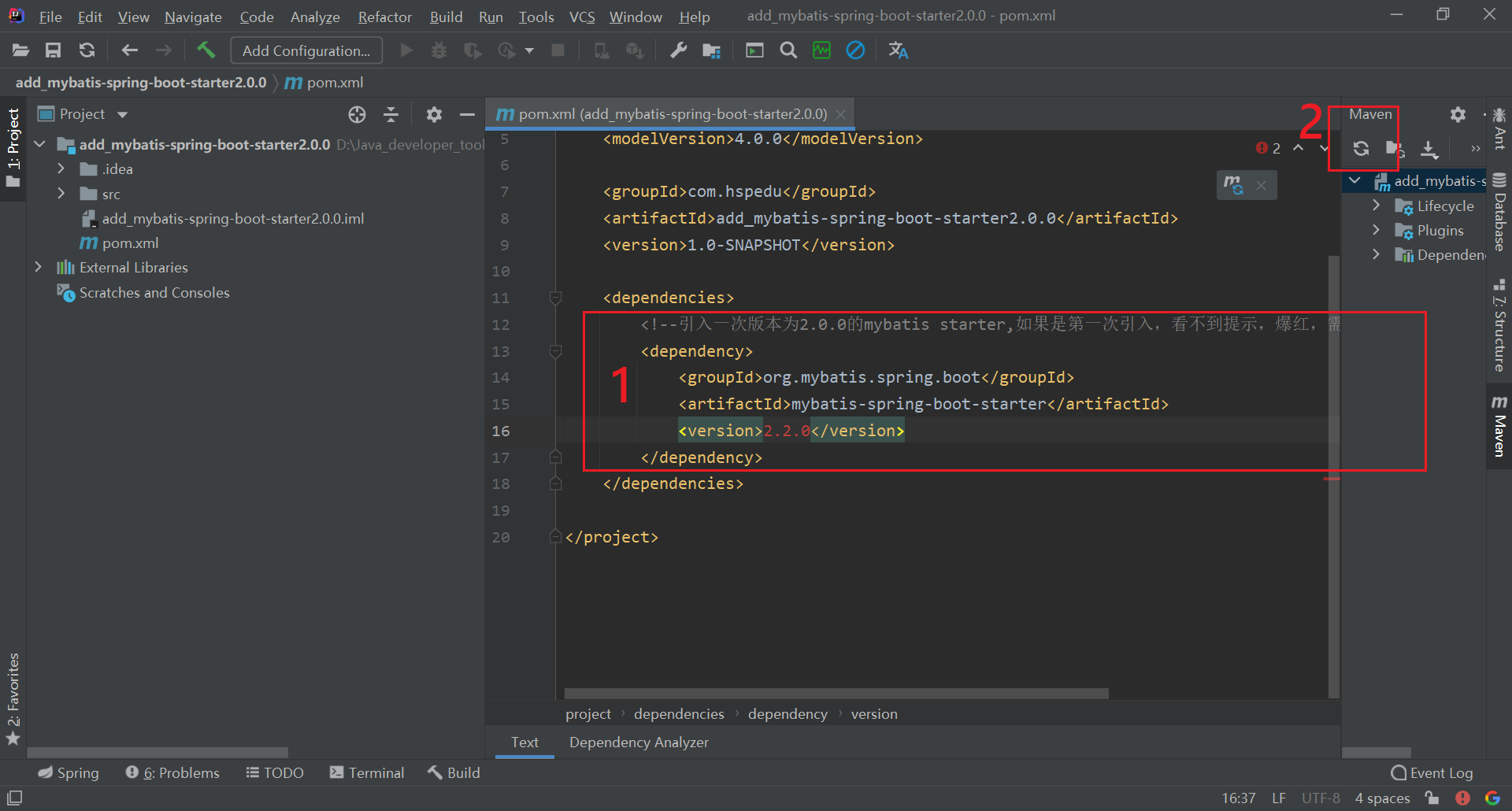
刷新Maven
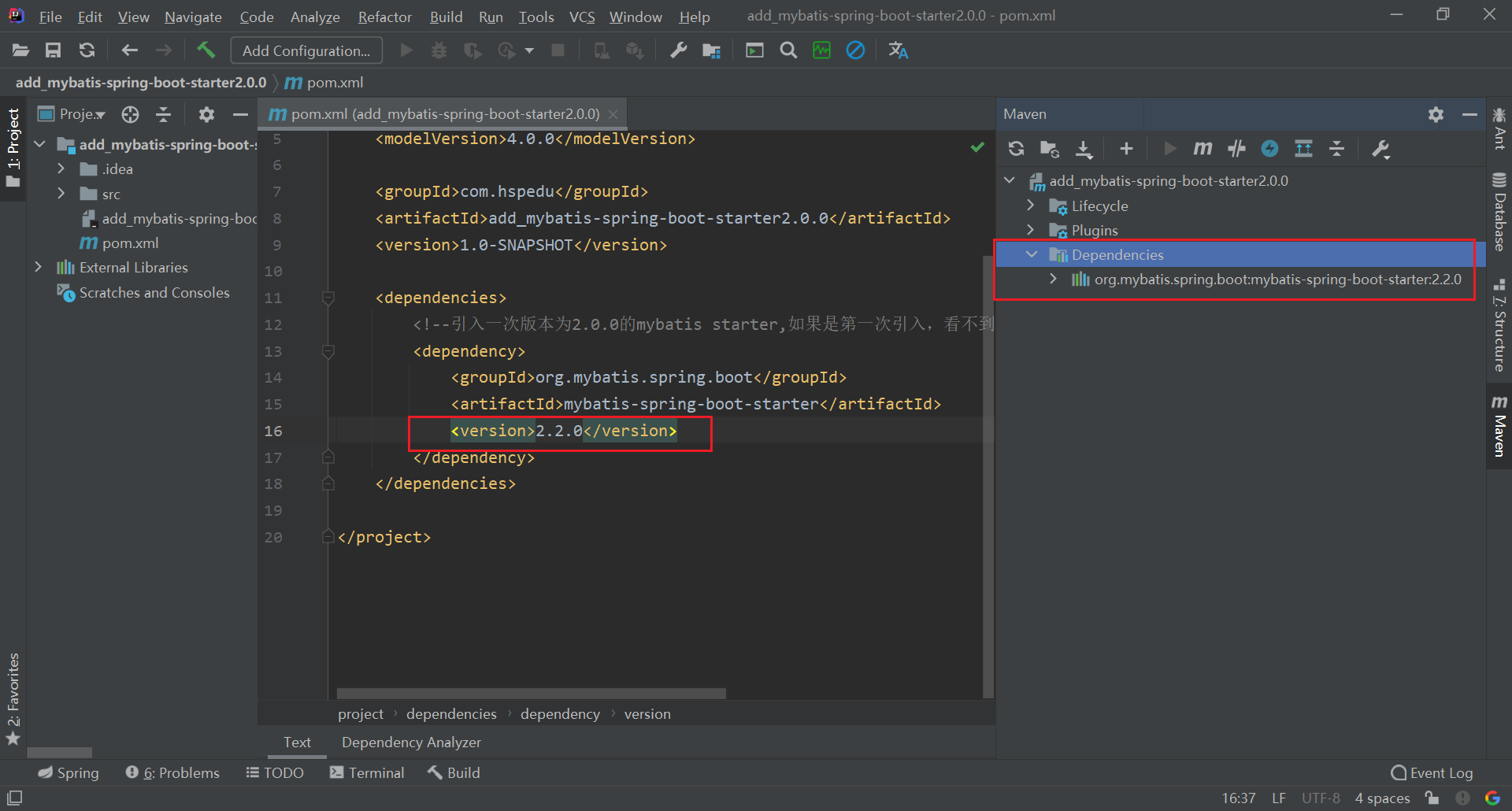
当新建的项目导入成功后,创建的springcloud项目 e-commerce-center2的pom.xml中的
dependencyManagement标签中指定的版本也不再报错了
需要注意的是:dependencyManagement标签主要用于锁定版本,本身并不引入依赖jar,即刷新Maven时看不到依赖的引入dependencies
总结:
-
Maven下载下来的依赖会保存在本地磁盘C:\Users\yangd.m2\repository文件中
-
Maven会去哪里下载依赖的文件会根据Maven配置在C:\Users\yangd.m2\settings.xml文件中的<mirror>标签的url路径下载文件
-
如果Maven刷新失败,可以切换配置在C:\Users\yangd.m2\settings.xml文件中的<mirror>标签的url路径下载文件的url,比如使用阿里镜像
-
如果使用默认的Maven中央仓库注意需要外网,打开TUN模式
以下是Maven相关设置文件,本地仓库路径的位置
3 Maven报错Failed to read artifact descriptor for org.springframework.boot:spring-boot-starter-web:jar:2.2.2.RELEASE多次导入失败解决经验
如果在idea中网络使用的是*** TUN 模式 ,同时指定的是从中央仓库下载maven的jar包
,按理说所有的流量都走代理,不应该会下载失败,通过检查本地Maven仓库对应的存放依赖的位置
,如在导入spring-boot-starter-web-2.2.2.RELEASE 时,反复刷新Maven仓库,导入失败如下:
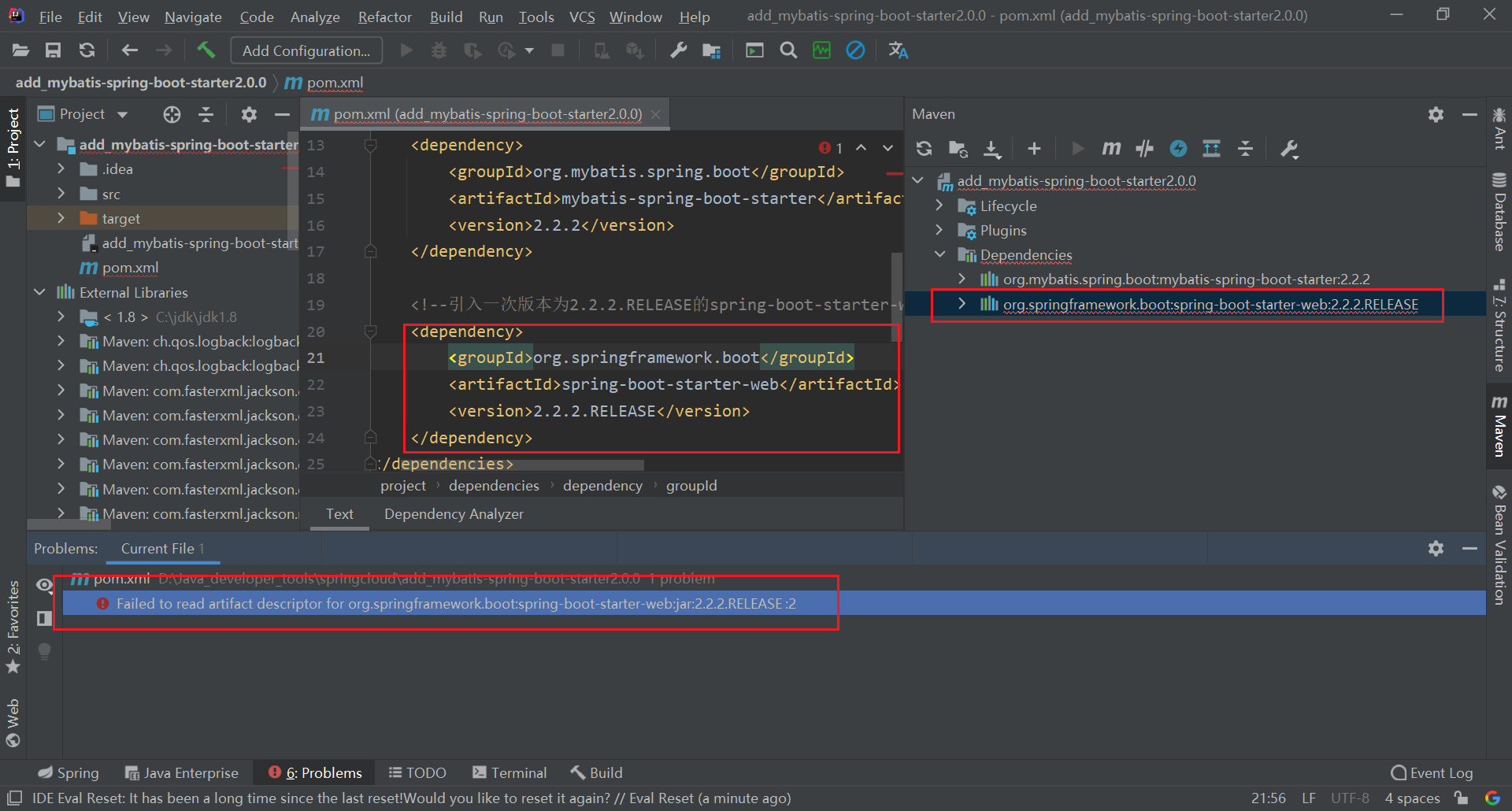
打开本地的Maven仓库 文件夹C:\Users\yangd\.m2\repository\org\springframework\boot\spring-boot-starter-web\2.2.2.RELEASE\,发现该文件夹下只含有一个名为spring-boot-starter-web-2.2.2.RELEASE.pom.lastUpdated的文件如下:
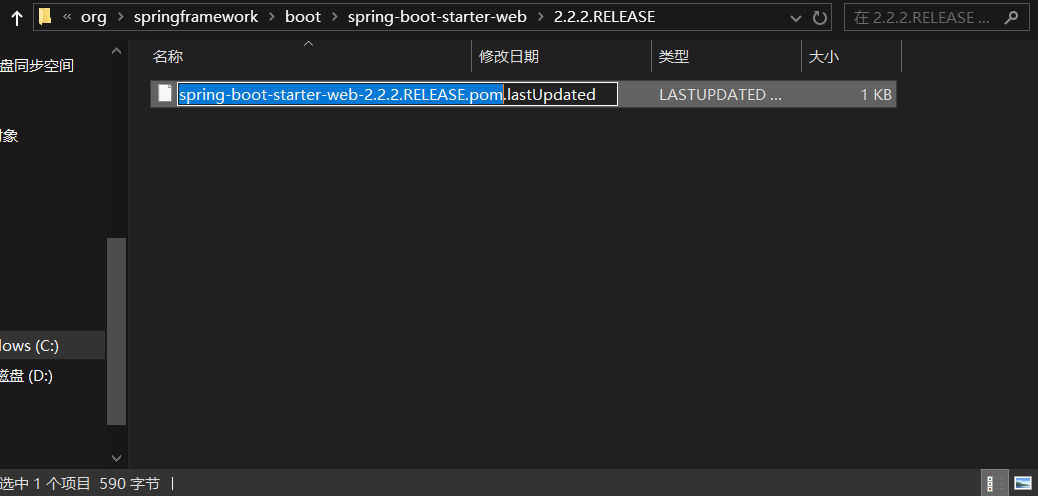
猜测,因为存在这个文件,导致maven刷新时,不再去Maven仓库下载对应的依赖资源了,在对应的存放maven依赖的文件夹下,将这个spring-boot-starter-web-2.2.2.RELEASE.pom.lastUpdated文件删除,在删除后重新刷新Maven,发现此时
maven已经重新开始下载对应的依赖文件spring-boot-starter-web-2.2.2.RELEASE了,问题解决!!
spring-boot-starter-web-2.2.2.RELEASE.pom.lastUpdated文件中的内容如下:
#NOTE: This is a Maven Resolver internal implementation file, its format can be changed without prior notice.
#Thu Dec 28 16:44:33 CST 2023
@default-central-https\://repo.maven.apache.org/maven2/.lastUpdated=1703753073751
https\://repo.maven.apache.org/maven2/.error=Could not transfer artifact org.springframework.boot\:spring-boot-starter-web\:pom\:2.2.2.RELEASE from/to central (https\://repo.maven.apache.org/maven2)\: Transfer failed for https\://repo.maven.apache.org/maven2/org/springframework/boot/spring-boot-starter-web/2.2.2.RELEASE/spring-boot-starter-web-2.2.2.RELEASE.pom
出现该问题的原因可能是之前导入依赖失败过,比如,之前使用的是阿里云镜像网站下载该依赖资源,但是在镜像网站没有该依赖资源,最后生成了这样一个损坏的文件留在本地仓库中,导致后面将下载文件的位置设置到默认的maven中央仓库后,再重新下载该文件时已经不去中央仓库下载了,只需要把这个损坏的文件spring-boot-starter-web-2.2.2.RELEASE.pom.lastUpdated删除,重新刷新Maven再导入一次即可
删除后本地仓库中的依赖文件如下:
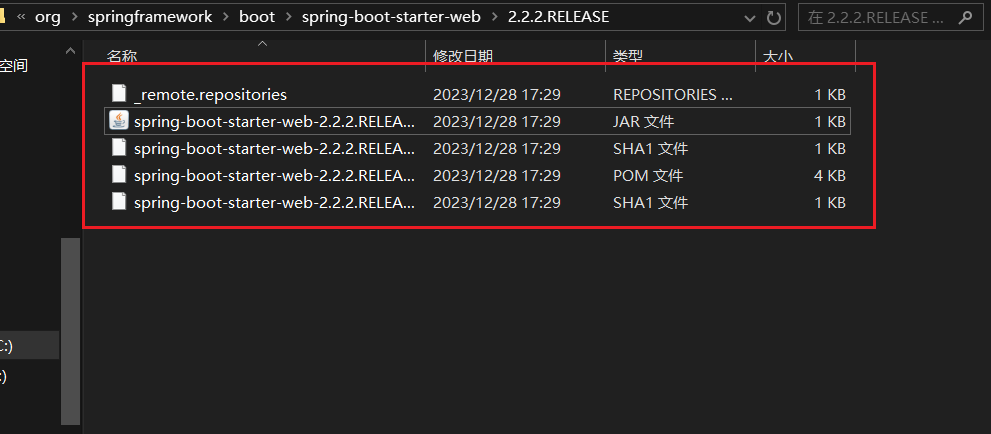
此时idea右侧Maven选项框中还是爆红
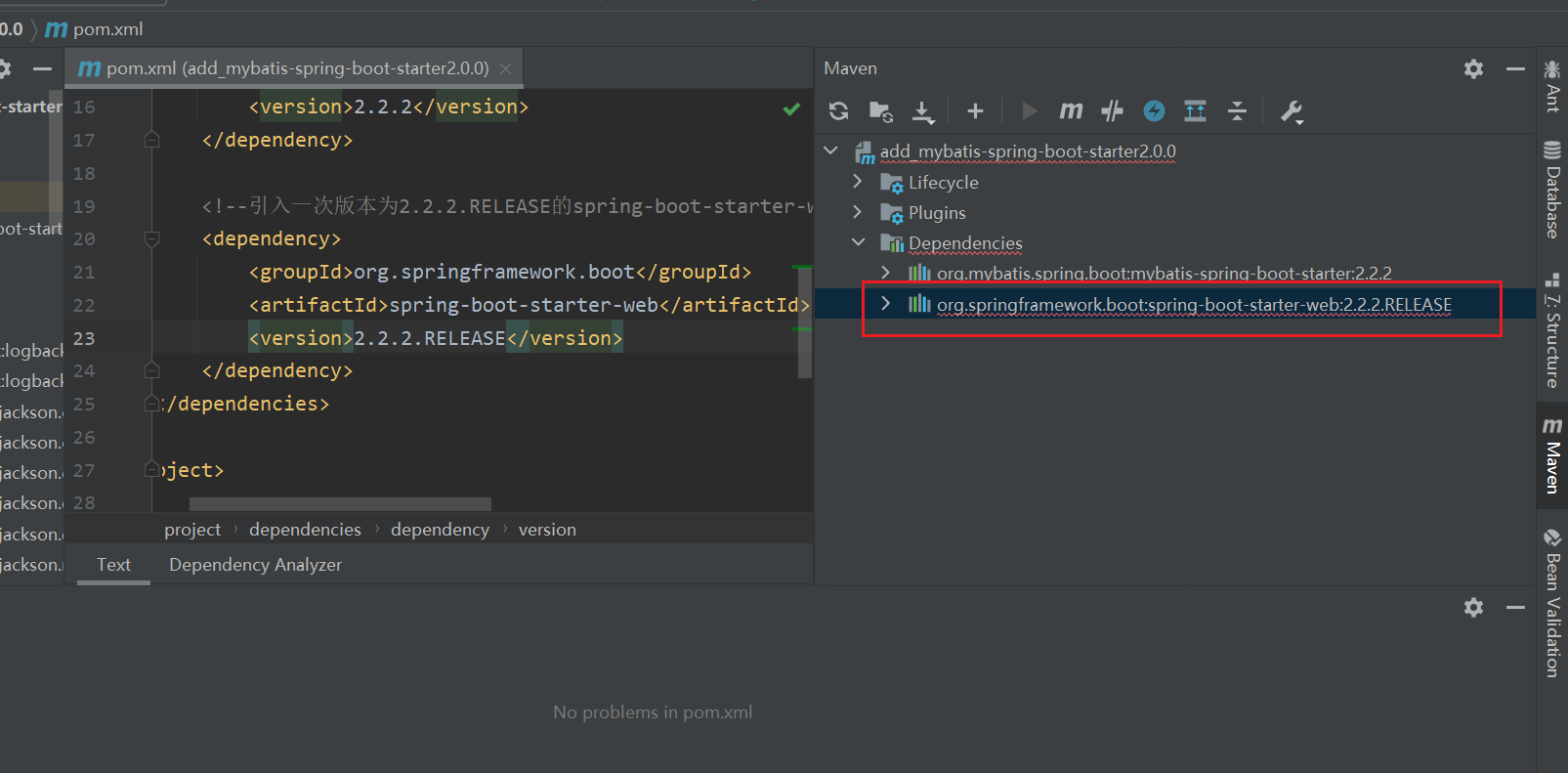
只需要重启idea即可
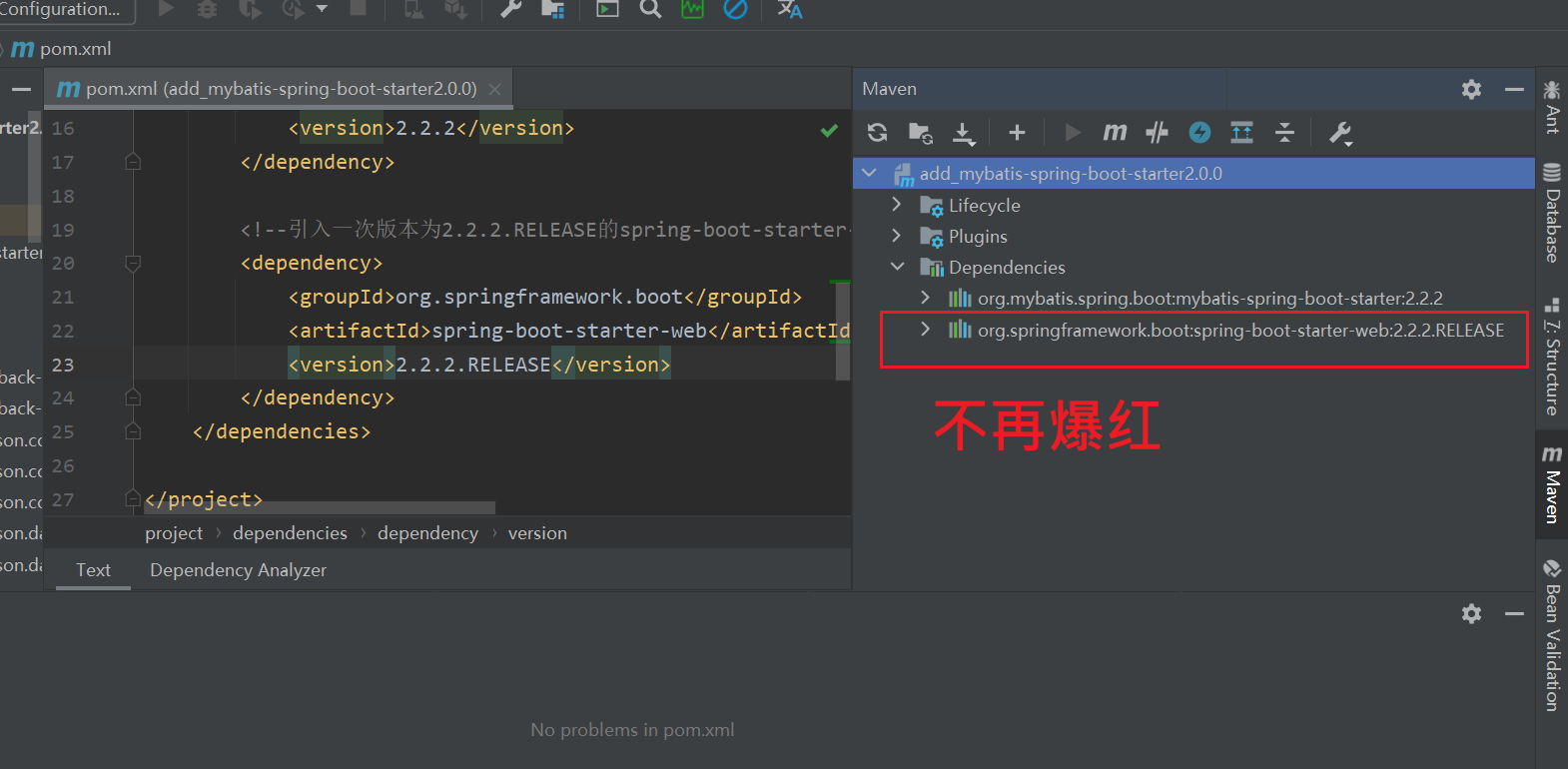
4 在中央仓库中找不到依赖的报错Could not find artifact com.alibaba:druid-spring-boot-starter:jar:unknown in central (https://repo.maven.apache.org/maven2)
这里没有指定版本,父项目中和本项目中都没有指定版本,导致的报错
解决方法:指定版本即可
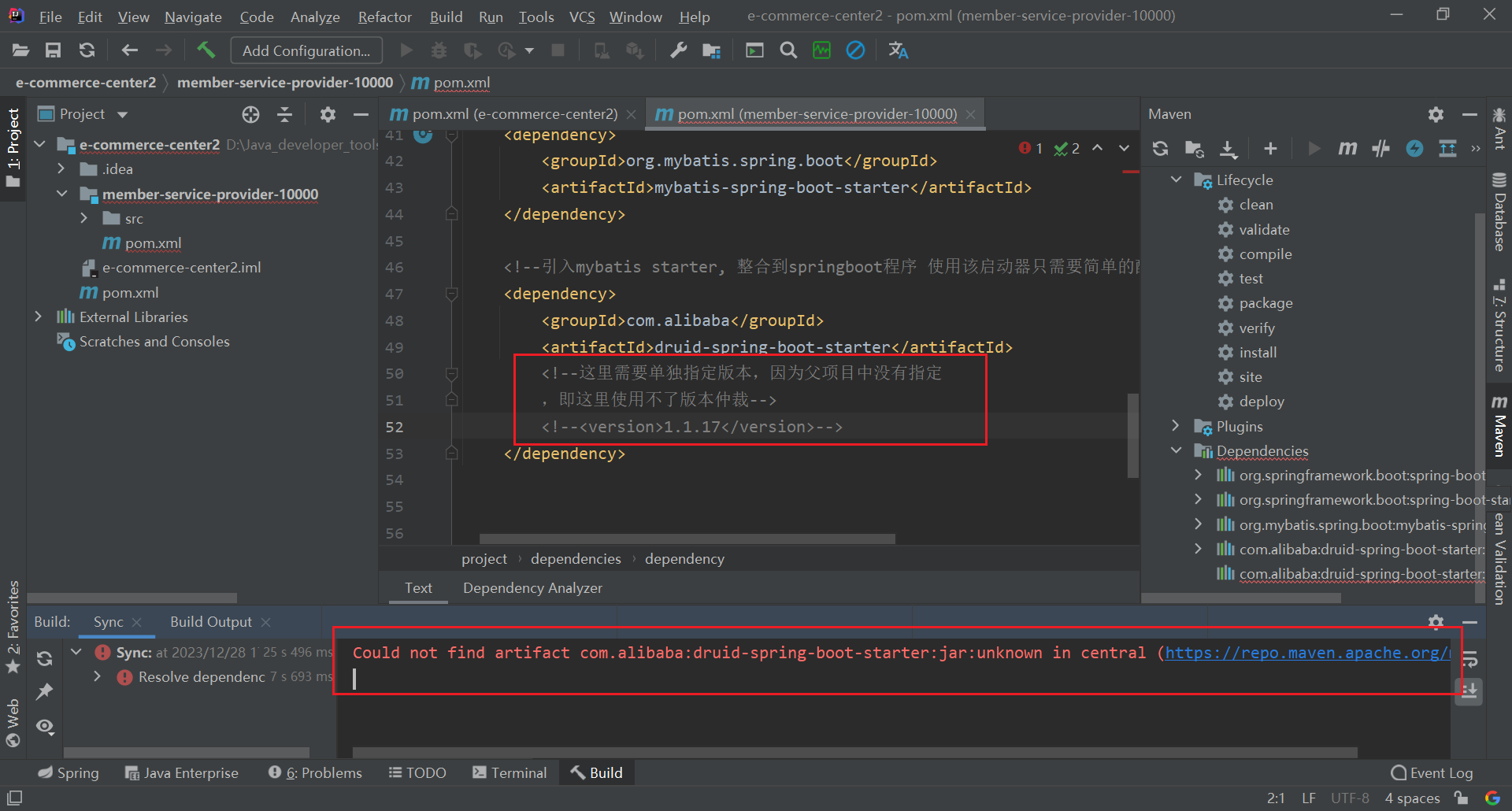
指定版本
5 @SpringBootTest进行测试引的是import org.junit.jupiter.api.Test;
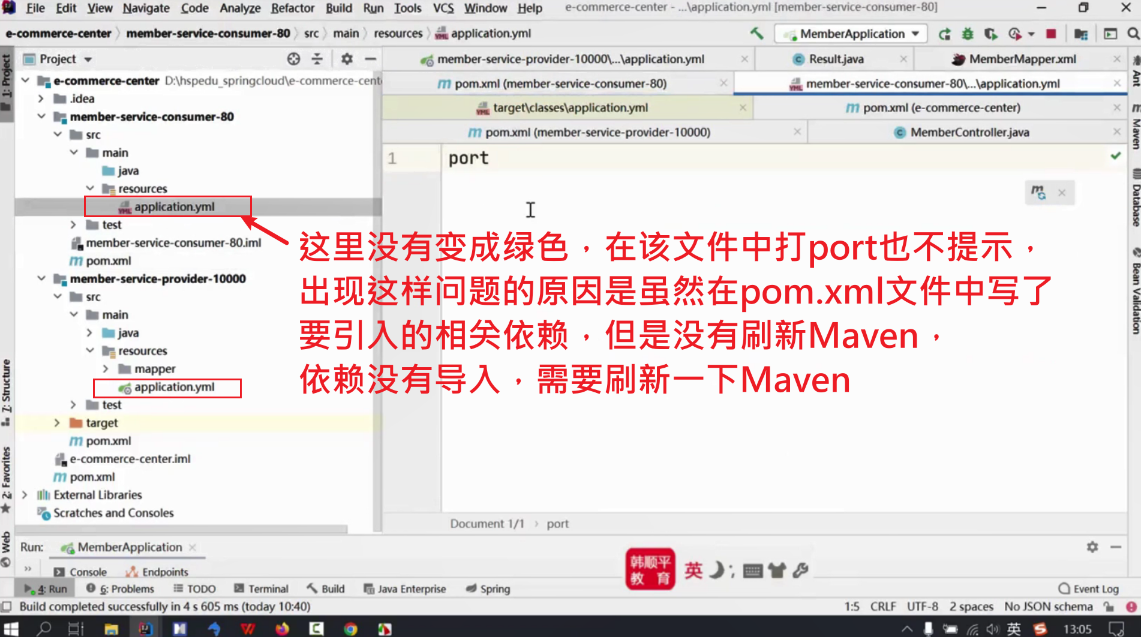
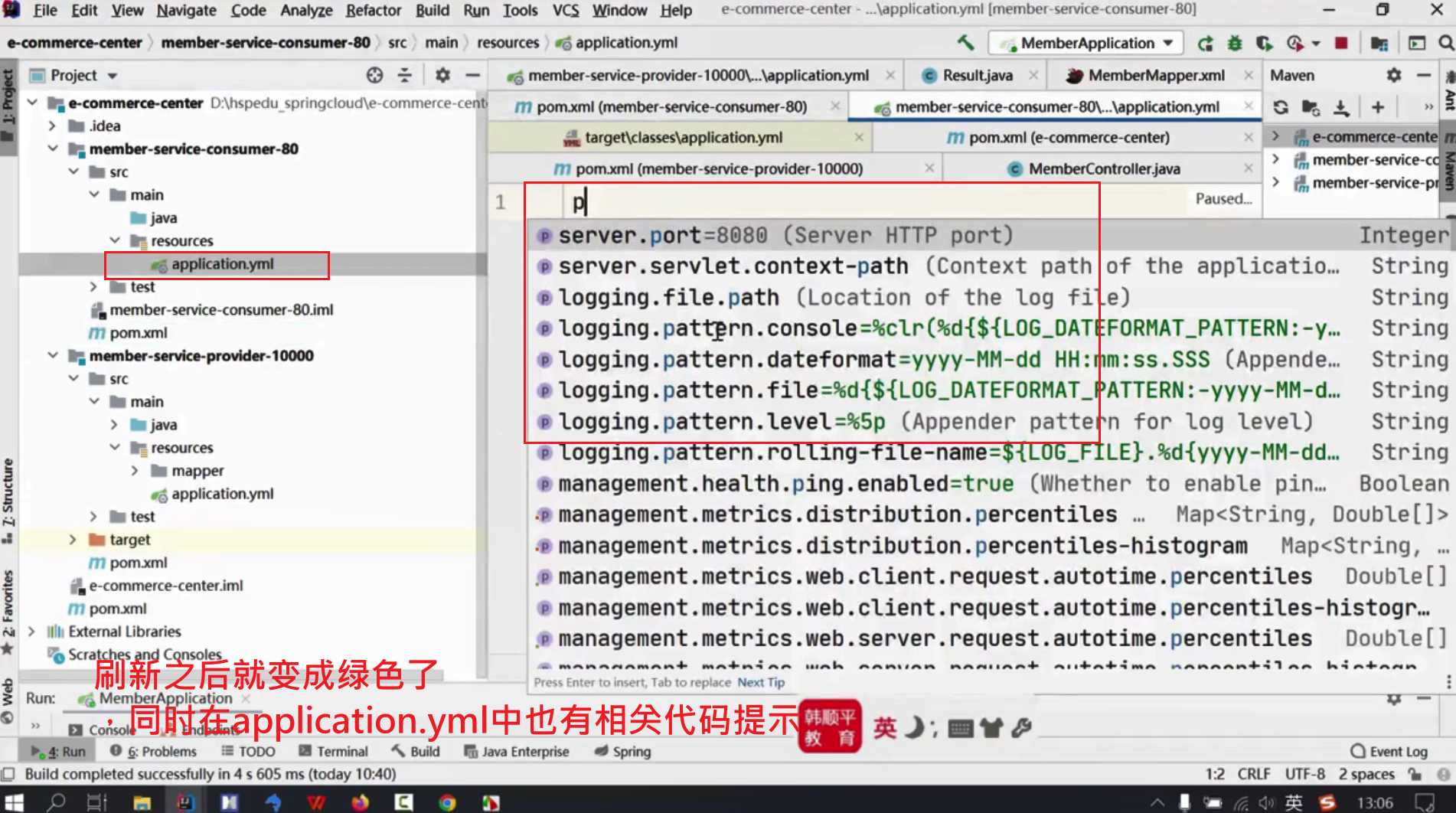
6 application.yml没有变成绿色,写port不提示,是因为没有刷新Maven
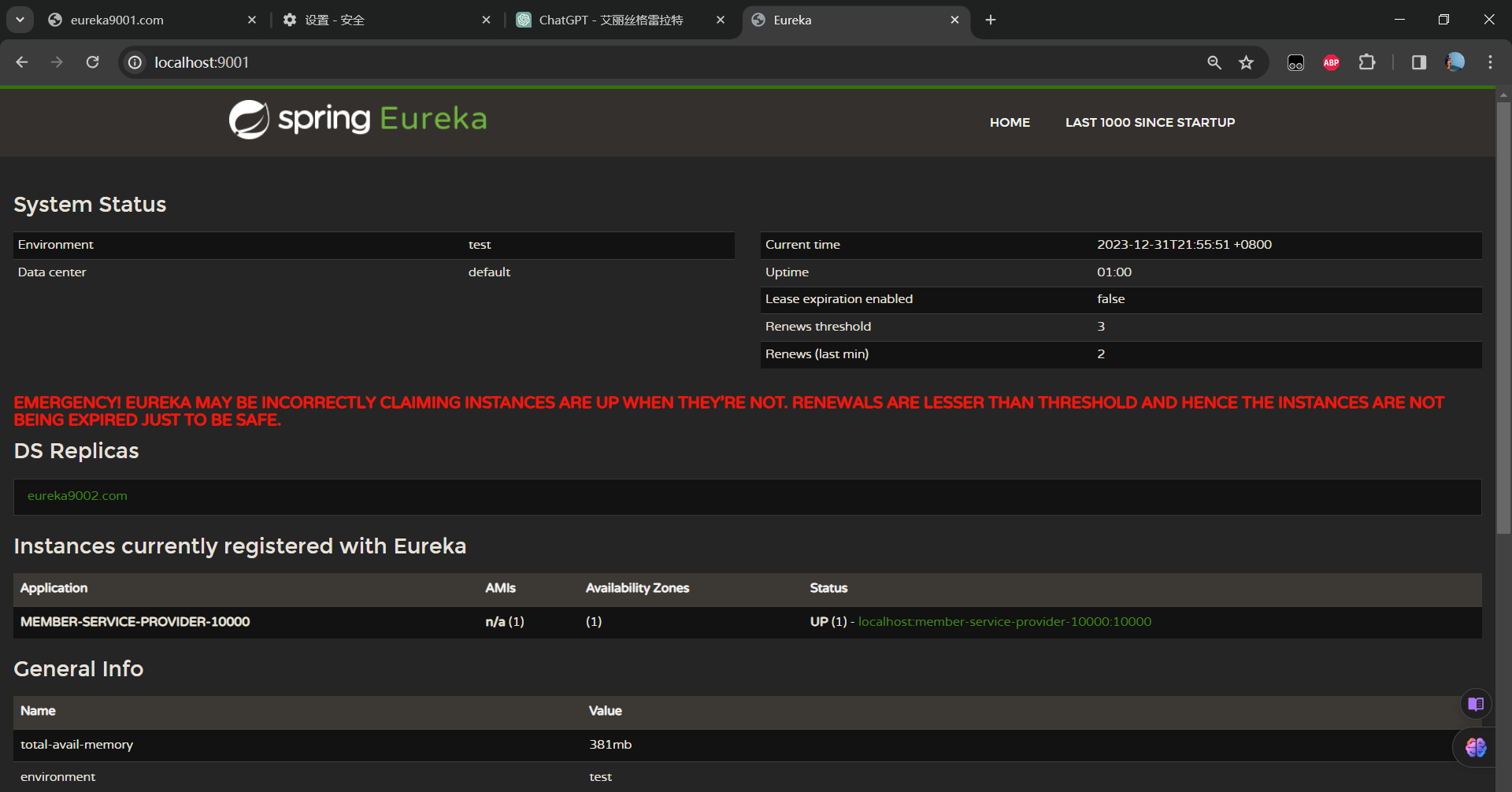
7 Eureka 访问http://eureka9001.com:9001/ 时,火狐浏览器总是跳转https://eureka9001.com:9001/
#当访问http://eureka9001.com:9001/ 时,火狐浏览器总是跳转https://eureka9001.com:9001/
#使用Edge浏览器和Chrome浏览器,同时关闭***代理,开着代理会导致访问失败!!!报502
#这时可以暂时使用 localhost 访问 因为在hosts文件中配置的域名 eureka9001.com 映射的地址就是本地#主机的ip地址127.0.0.1 即等同于http://localhost:9001/
8 什么是子域名?
子域名是域名系统(DNS)层次结构中的一个概念,它是在主域名(例如 example.com)下进一步细分的域名。理解子域名的概念,可以将其看作是主域名的一个“子部分”,用于组织和导航到网站的不同部分或服务。以下是一些关键点来帮助您理解子域名:
-
层次结构:在一个完整的域名中,如
subdomain.example.com,subdomain是子域名,example是主域名,而.com是顶级域名。子域名在主域名的前面,并且通过点(.)与之分隔。 -
用途:子域名常用于将大型网站分割成不同的部分,每个部分负责不同的功能。例如,一个大学可能会使用
admissions.university.com来处理招生信息,而使用research.university.com来展示研究成果。 -
独立性:尽管子域名是主域名的一部分,但它们通常可以被视为独立的网站来管理和运行。它们可以有自己的独特内容,甚至拥有不同的服务器和托管服务。
-
DNS解析:在DNS中,子域名有自己的DNS记录,可以解析到与主域名不同的IP地址。
-
无限制的创建:理论上,主域名下可以创建无限多的子域名。
-
示例:举例来说,
blog.example.com和shop.example.com是example.com的子域名,分别可能用于博客和网上商店。
9 调整默认的访问优先级IPV6大于IPV4为IPV4>IPV6
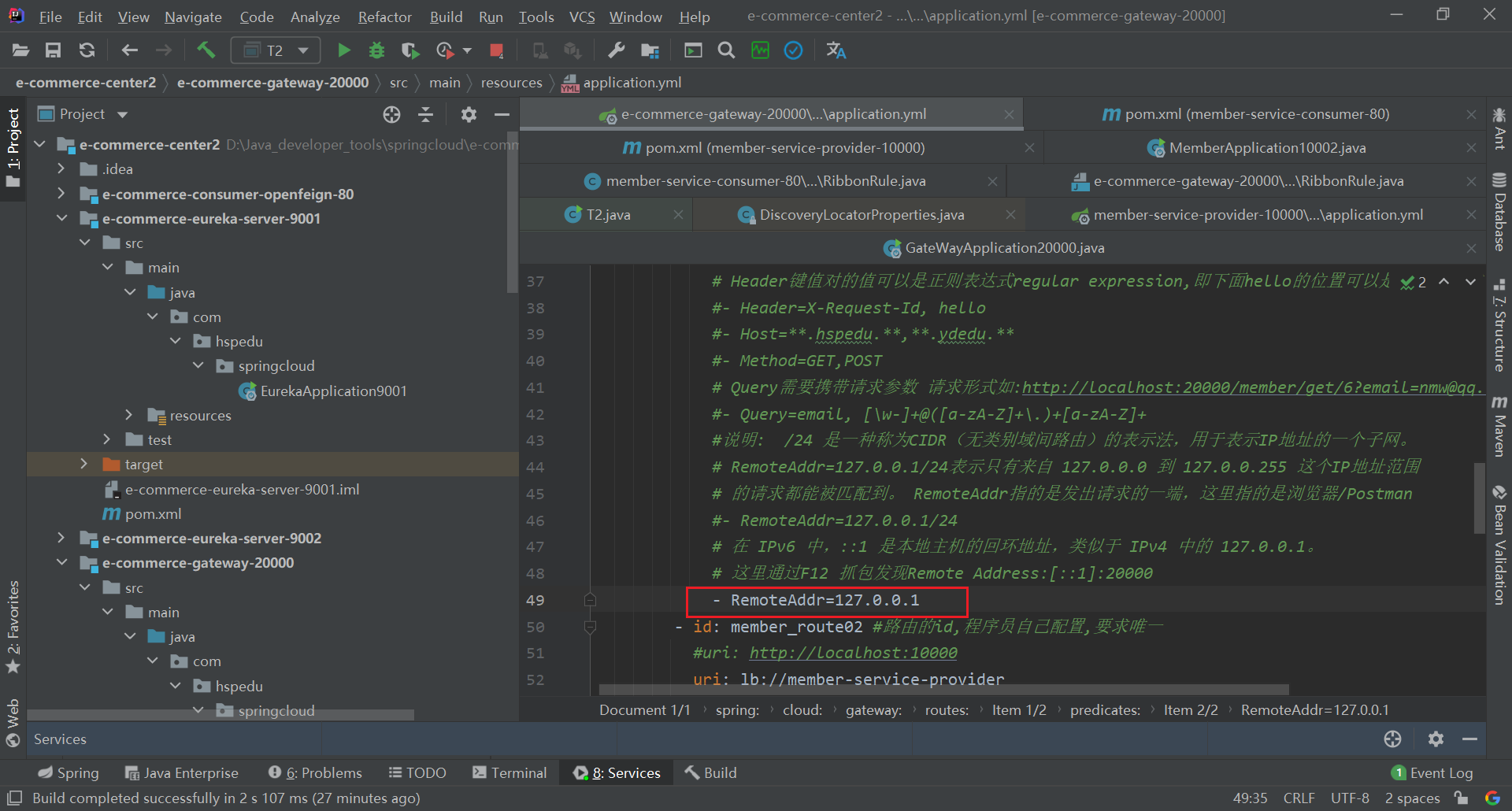
出现的问题 网关配置的允许127.0.0.1进行访问,但是在浏览器地址栏使用http://localhost:20000/member/get/5 进行访问时,却出现访问不了的情况,通过抓包发现,在浏览器要访问地址localhost这里是要被访问的地址,而不是发出请求的地址,在网关配置的 - RemoteAddr=127.0.0.1 指的是发出请求的一端的地址,这里指的是浏览器所在的主机地址,但是这里被优先解析成了IPV6地址 ::1

通过ping localhost来检测优先使用的是哪种协议
C:\Users\yangd>ping localhost
正在 Ping F2 [::1] 具有 32 字节的数据:
来自 ::1 的回复: 时间<1ms
来自 ::1 的回复: 时间<1ms
来自 ::1 的回复: 时间<1ms
来自 ::1 的回复: 时间<1ms
::1 的 Ping 统计信息:
数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),
往返行程的估计时间(以毫秒为单位):
最短 = 0ms,最长 = 0ms,平均 = 0ms
首先查看网络前缀访问优先级 我们先看下Windows10/11 中各个访问 IPv4/IPv6的优先级,可以看到 IPv6(::/0)比 IPv4(::ffff:0:0/96) 的优先级高,会被优先访问。
第一列优先循序越大优先级越高,会优先访问。
C:\WINDOWS\system32>netsh interface ipv6 show prefixpolicies
查询活动状态...
优先顺序 标签 前缀
---------- ----- --------------------------------
50 0 ::1/128
40 1 ::/0
35 2 ::ffff:0:0/96
30 3 2002::/16
1 6 ::/96
调整网络前缀优先级,让 IPv4 访问优先 从前面我们知道 IPv6(::/0)比 IPv4(::ffff:0:0/96) 的优先级高,我们通过 netsh interface ipv6 命令调整优先级。
Win + R 进入运行对话框,输入 cmd,选择 以管理员身份运行,执行调整命令,可以看到 IPv4(::ffff:0:0/96) 优先级最高。
C:\WINDOWS\system32>netsh interface ipv6 set prefixpolicy ::ffff:0:0/96 100 3
确定。
C:\WINDOWS\system32>netsh interface ipv6 show prefixpolicies
查询活动状态...
优先顺序 标签 前缀
---------- ----- --------------------------------
100 3 ::ffff:0:0/96
50 0 ::1/128
40 1 ::/0
30 3 2002::/16
1 6 ::/96
执行 ping 、curl 命令验证,确实默认 IPv4 访问优先。
这里我自己的已经成功了,实现了优先IPV4访问
C:\Users\yangd>ping localhost
正在 Ping F2 [127.0.0.1] 具有 32 字节的数据:
来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=128
来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=128
来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=128
来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=128
127.0.0.1 的 Ping 统计信息:
数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),
往返行程的估计时间(以毫秒为单位):
最短 = 0ms,最长 = 0ms,平均 = 0ms
但是在谷歌浏览器访问http://localhost:20000/member/get/3时还是访问不到
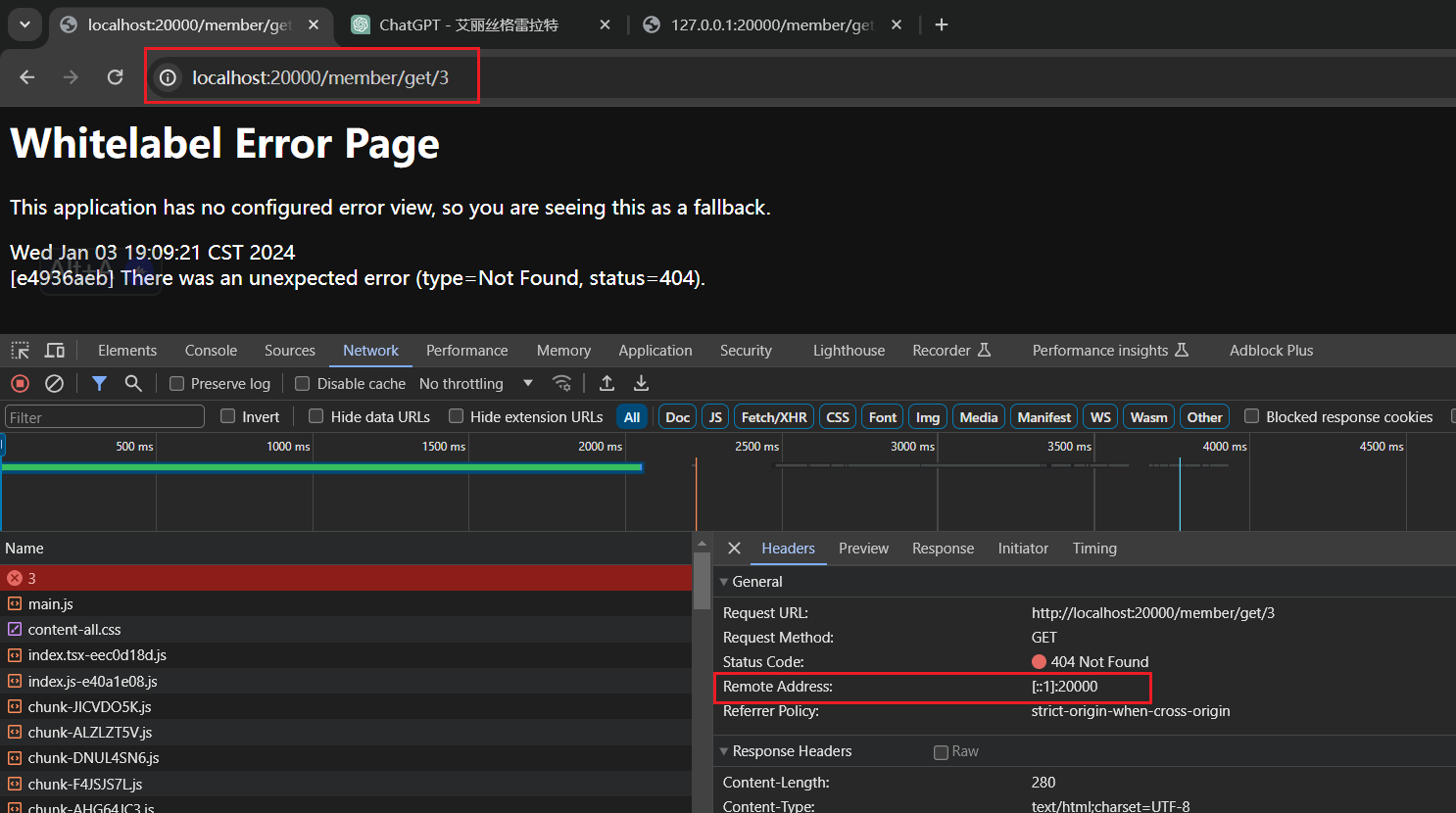
使用IPV4直接访问http://127.0.0.1:20000/member/get/5 访问到了
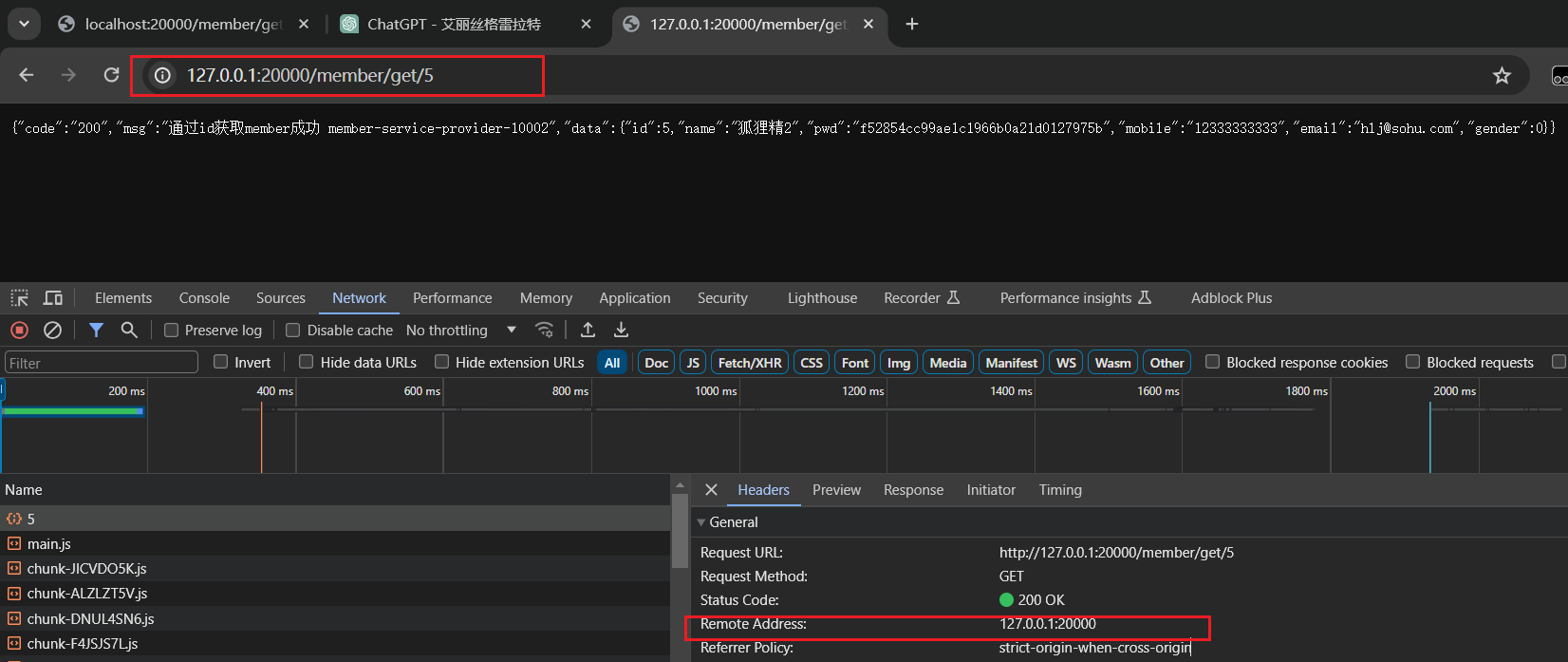
但是在火狐可以使用http://localhost:20000/member/get/3 访问成功 由此可见在火狐 RemoteAddr:127.0.0.1:20000
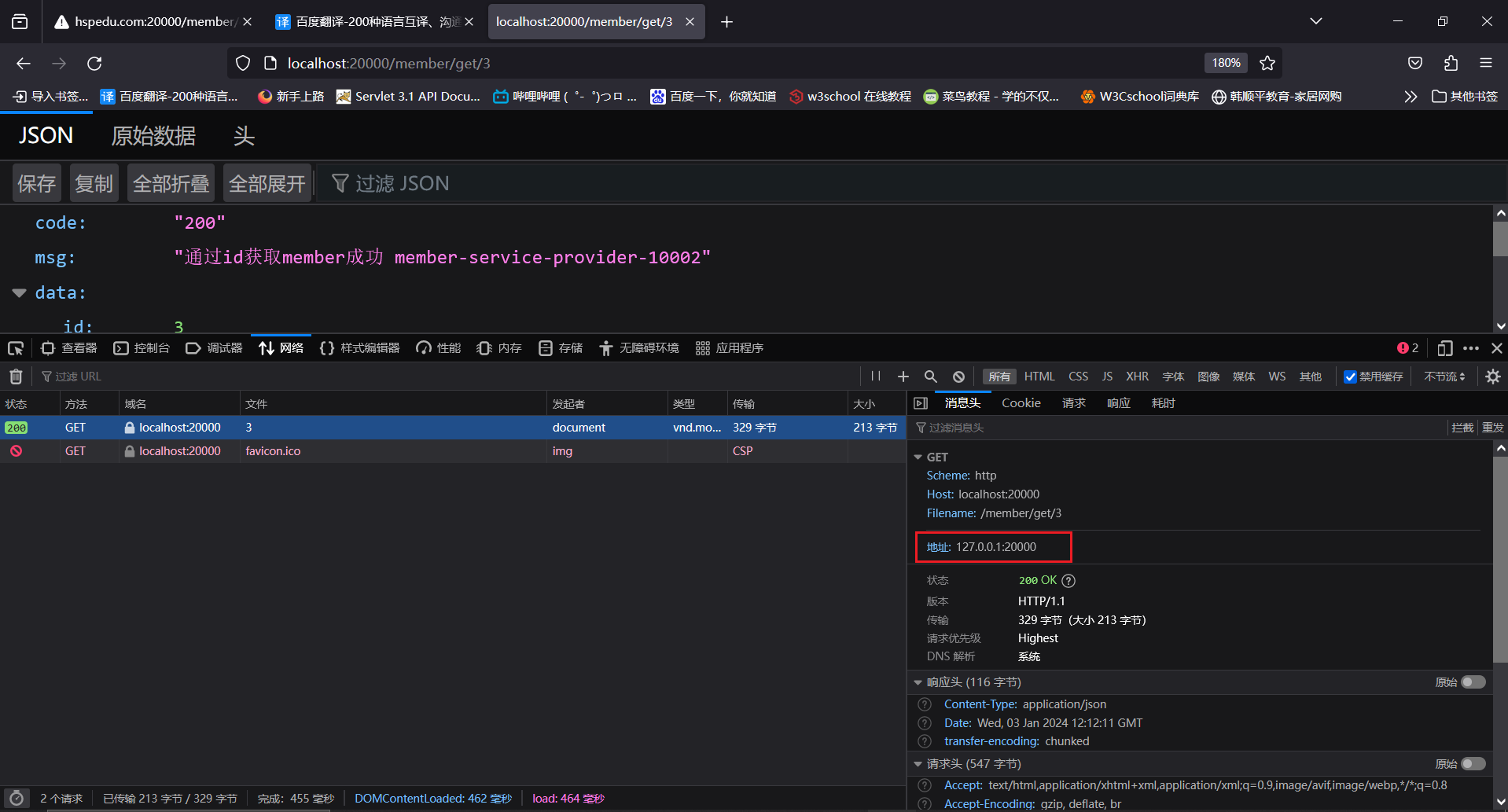
# 在网关配置文件application.yml中使用 `uri: http://www.baidu.com` + `- Path=/`
# 来测试 `- RemoteAddr=127.0.0.1` 指的是浏览器端的地址而不是提供服务端的地址
server:
port: 20000
spring:
application:
name: e-commerce-gateway
cloud:
gateway:
discovery:
locator:
# Flag that enables DiscoveryClient gateway integration.
# 启用DiscoveryClient 服务发现
enabled: true
routes: #配置路由,可以配置多个路由,List<RouteDefinition> routes
- id: member_route01 #路由的id,程序员自己配置,要求唯一
# gateway 最终访问的url 是 url=uri + Path
# 匹配后提供服务的路由地址:也可以是外网 http://www.baidu.com
# 比如 客户端/浏览器请求的url http://localhost:20000/member/get/1
# 如果根据Path匹配成功 最终访问的url/转发的url 就是http://localhost:10000/member/get/1
# 如果匹配失败,则有gateway返回404信息
# 疑惑:这里的uri这里暂时配置的是固定的,在当前的情况可以不是Eureka Server[服务发现]
# ,后面会使用灵活的方式配置,就会使用Eureka Server[服务发现]
#uri: http://localhost:10000
#解读:
# 1. lb :协议名, member-service-provider (注册到Eureka-Server的服务名[小写])
# 2. 默认情况下,负载均衡的算法是轮询
# uri: lb://member-service-provider
# 使用下面的`uri: http://www.baidu.com` + `- Path=/`
# 来测试 `- RemoteAddr=127.0.0.1` 指的是浏览器端的地址而不是提供服务端的地址
uri: http://www.baidu.com
predicates: #断言,可以有多种形式
- Path=/
# 在火狐可以使用http://localhost:20000/member/get/3 访问成功
# 由此可见在火狐 RemoteAddr:127.0.0.1:20000
- RemoteAddr=127.0.0.1
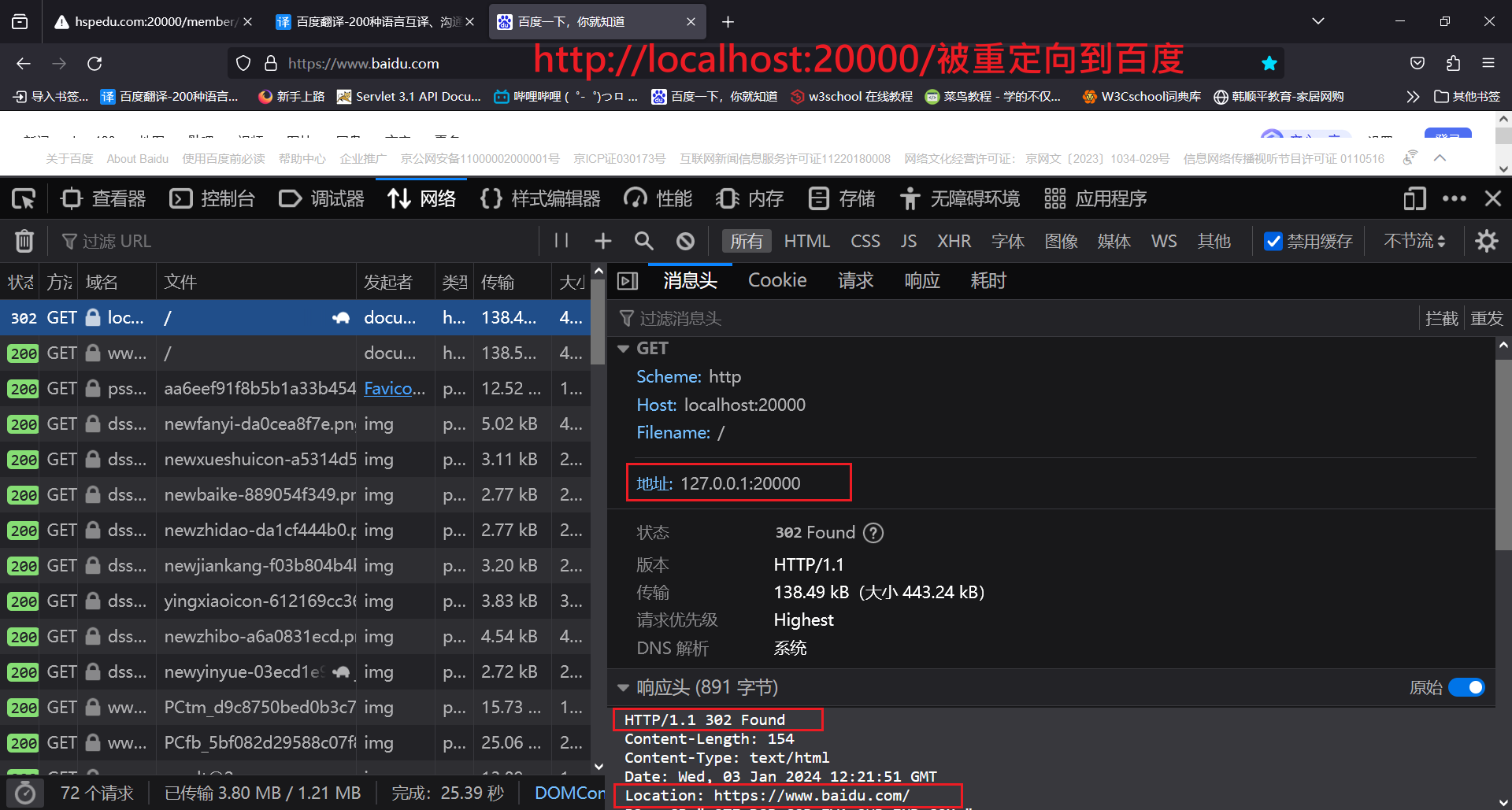
重启电脑后,发现还是 IPv6 访问优先。
查看网络前缀访问优先级,发现只剩下 IPv4 的,可能是因为这个原因导致没生效,加回 IPv6 的网络前缀,IPv4 访问优先,达到目的。
C:\Windows\system32>netsh interface ipv6 show prefixpolicies
查询活动状态...
优先顺序 标签 前缀
---------- ----- --------------------------------
100 4 ::ffff:0:0/96
C:\Windows\system32>netsh interface ipv6 add prefixpolicy ::/0 40 1
确定。
C:\Windows\system32>netsh interface ipv6 show prefixpolicies
查询活动状态...
优先顺序 标签 前缀
---------- ----- --------------------------------
100 4 ::ffff:0:0/96
40 1 ::/0
如何重新设置 IPv6访问优先 两种方式,直接重置
重置 IPv6 策略
C:\Windows\system32>netsh interface ipv6 reset
正在重置 分段转发,完成!
正在重置 分段,完成!
正在重置 控制协议,完成!
正在重置 回显顺序请求,完成!
正在重置 全局,完成!
正在重置 接口,完成!
正在重置 任意广播地址,完成!
正在重置 多播地址,完成!
正在重置 单播地址,完成!
重新启动计算机来完成此操作。
10 Sentinel 熔断降级规则中,"慢调用比例阈值","比例阈值"设置为0是什么意思?
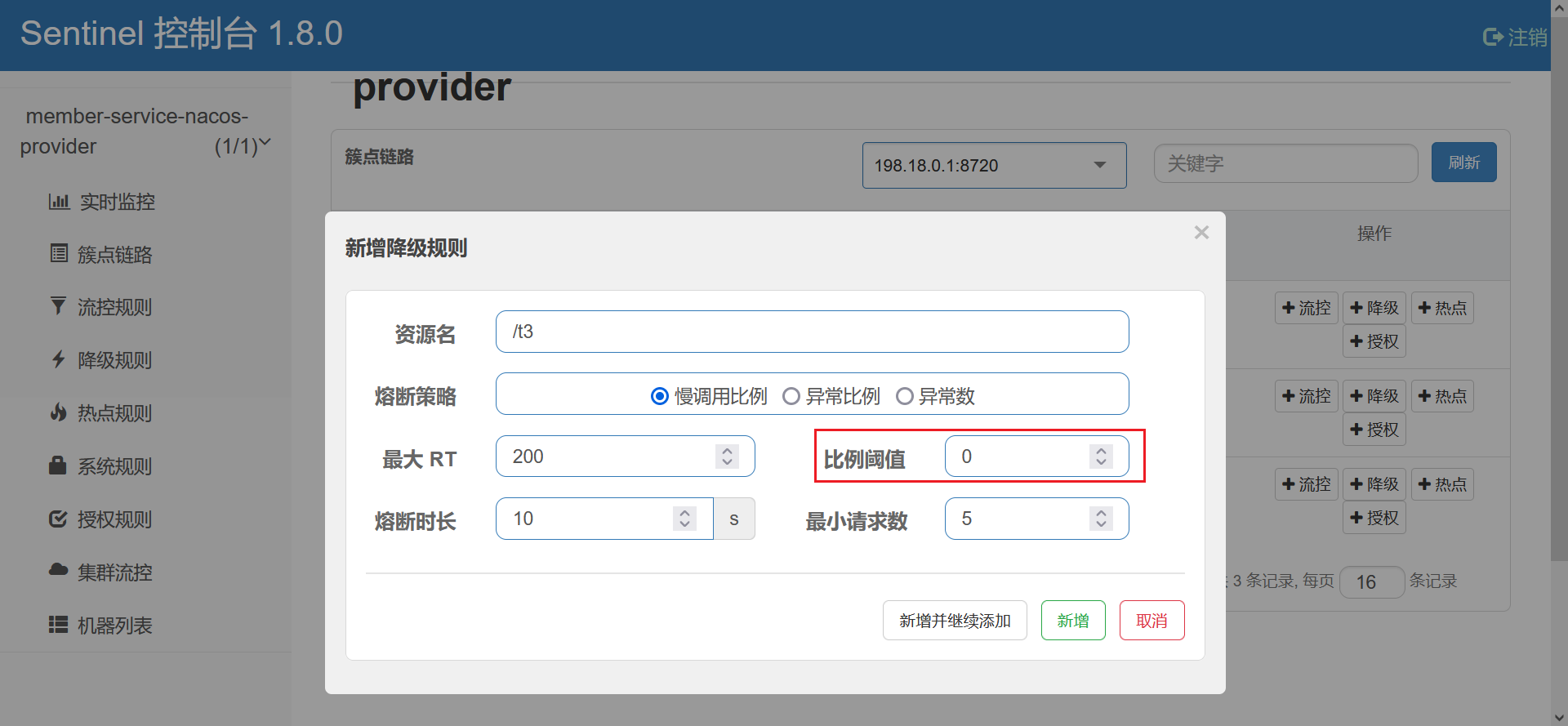
请参考https://sentinelguard.io/zh-cn/docs/circuit-breaking.html说明,截图中的比例阈值是什么意思?
[GPT]WebPilot
Talked to gpts.webpilot.ai
在 Sentinel 的熔断降级规则中,"慢调用比例阈值"(slowRatioThreshold)是指在慢调用比例(SLOW_REQUEST_RATIO)模式下生效的一个参数。这个阈值是用来定义何时触发熔断的条件。具体来说:
-
当请求的响应时间大于设定的慢调用响应时间(RT)时,该请求会被统计为慢调用。
-
如果在一个统计时间窗口内(由
statIntervalMs参数定义),请求总数超过了设定的最小请求量(由minRequestAmount参数定义),并且慢调用的比例超过了设定的慢调用比例阈值,则会触发熔断。 -
一旦熔断被触发,系统会在接下来的熔断时间窗口内(由
timeWindow参数定义)自动拒绝所有请求,以防止不稳定的服务导致系统资源耗尽。
例如,如果慢调用比例阈值设定为0.5(或者50%),那么在统计时间内,如果慢调用的请求超过了50%的请求总数,熔断器将会触发。
在您提供的截图中,"比例阈值"的输入框被设置为0,这个值在实际配置中需要根据实际情况进行调整,以便正确地触发熔断保护机制。
You
"比例阈值"设置为0是什么意思?
[GPT]WebPilot
在Sentinel的熔断规则中设置"比例阈值"为0意味着,只要有请求的响应时间超过了设定的慢调用响应时间(RT),不管这样的请求占比多少,即便是一个单一的请求,也会触发熔断机制。这是一个非常严格的配置,它设置了一个非常低的容错率,因为任何慢请求都会导致熔断。这种设置可能适用于对响应时间极其敏感的场景,但在大多数情况下,可能会由于过于敏感而导致不必要的熔断,因此通常需要根据具体的业务需求和性能指标来更合理地设置这个阈值。
当“比例阈值”设置为0时,在统计时间窗口内,只要有一个请求的响应时间超过了设定的慢调用响应时间(RT),并且总的请求数达到了最小请求数阈值(这里是5),那么即便是一个单独的慢请求也会触发熔断机制。
这意味着,在这个配置下,如果前五个请求的响应时间都是快速的,而第六个请求慢,就会触发熔断,因为此时已经满足了最小请求数的要求,而慢请求比例(1/6)超过了设置的比例阈值(0%)。这里的“0%”表示只要有慢请求出现(在达到最小请求数之后),不管这些慢请求的比例是多少,熔断都会被触发。
11 sentinel流控模式直接、关联、链路举例
Sentinel 是一个流行的 Java 流量控制组件,用于确保应用程序的稳定性和可靠性。它提供了几种流量控制模式,包括直接、关联和链路。下面分别介绍这三种模式并给出示例:
-
直接模式:
-
定义:当某个 API 的访问频率或并发数达到定义的阈值时,Sentinel 会直接对该 API 进行限流。
-
示例:设定一个 API 每秒最多只能被访问100次。当请求频率超过这个限制时,Sentinel 会阻止额外的请求。
-
-
关联模式:
-
定义:当某个关联资源(而非当前资源本身)达到阈值时,Sentinel 会对当前资源进行限流。这适用于两个资源之间有相关性的情况。
-
示例:假设有两个 API,API A 和 API B。我们可以设置当 API B 的访问频率超过每秒100次时,限制 API A 的访问。即使 API A 的访问频率没有达到限流条件,但由于 API B 的高频访问,API A 也会被限流。
-
-
链路模式:
-
定义:根据请求的入口或链路(来源)来限流。如果请求是通过特定的入口或路径到达的,并且这些请求达到了阈值,那么就会触发限流。
-
示例:如果我们有一个 API C,它既可以直接被外部服务调用,也可以作为另一个 API D 的子调用。我们可以仅在 API C 作为 API D 的子调用时才对其进行限流,比如当每秒从 API D 到 API C 的调用超过50次时限流,而直接对 API C 的其他调用则不限流。
-
12 sentinle+nacos持久化配置规则文档地址: https://sentinelguard.io/zh-cn/docs/basic-api-resource-rule.html
13 @Bean注解标注的方法是可以有参数的
在Spring框架中,@Bean注解的方法可以有参数,这些参数表示该Bean的依赖。Spring容器会自动地为这些参数寻找合适的实例来注入。这是Spring的依赖注入(Dependency Injection, DI)功能的一个关键方面。具体来说:
-
寻找合适的Bean进行注入:
-
当Spring容器创建一个由
@Bean注解的方法定义的Bean时,它会检查这个方法的参数。 -
对于每个参数,Spring容器会在其当前管理的Bean中寻找与参数类型相匹配的Bean。
-
如果找到了合适的Bean,Spring容器就会将这个Bean注入作为参数。
-
-
处理多个相同类型的Bean:
-
如果有多个相同类型的Bean可用,Spring容器需要额外的信息来确定使用哪一个。这可以通过指定Bean的名称或使用其他限定符(如
@Qualifier注解)来实现。
-
-
无法找到合适的Bean时的行为:
-
如果Spring容器无法找到匹配的Bean来注入,它通常会抛出异常,因为这通常表示配置错误或者所需的Bean尚未定义。
-
-
使用
@ConfigurationProperties进行细粒度控制:-
有时,您可能会看到与
@Bean一起使用@ConfigurationProperties注解。这用于将外部配置(如属性文件中的属性)绑定到Bean的属性上,进一步控制Bean的配置。
-
总的来说,@Bean

 浙公网安备 33010602011771号
浙公网安备 33010602011771号