MyBatis随手笔记
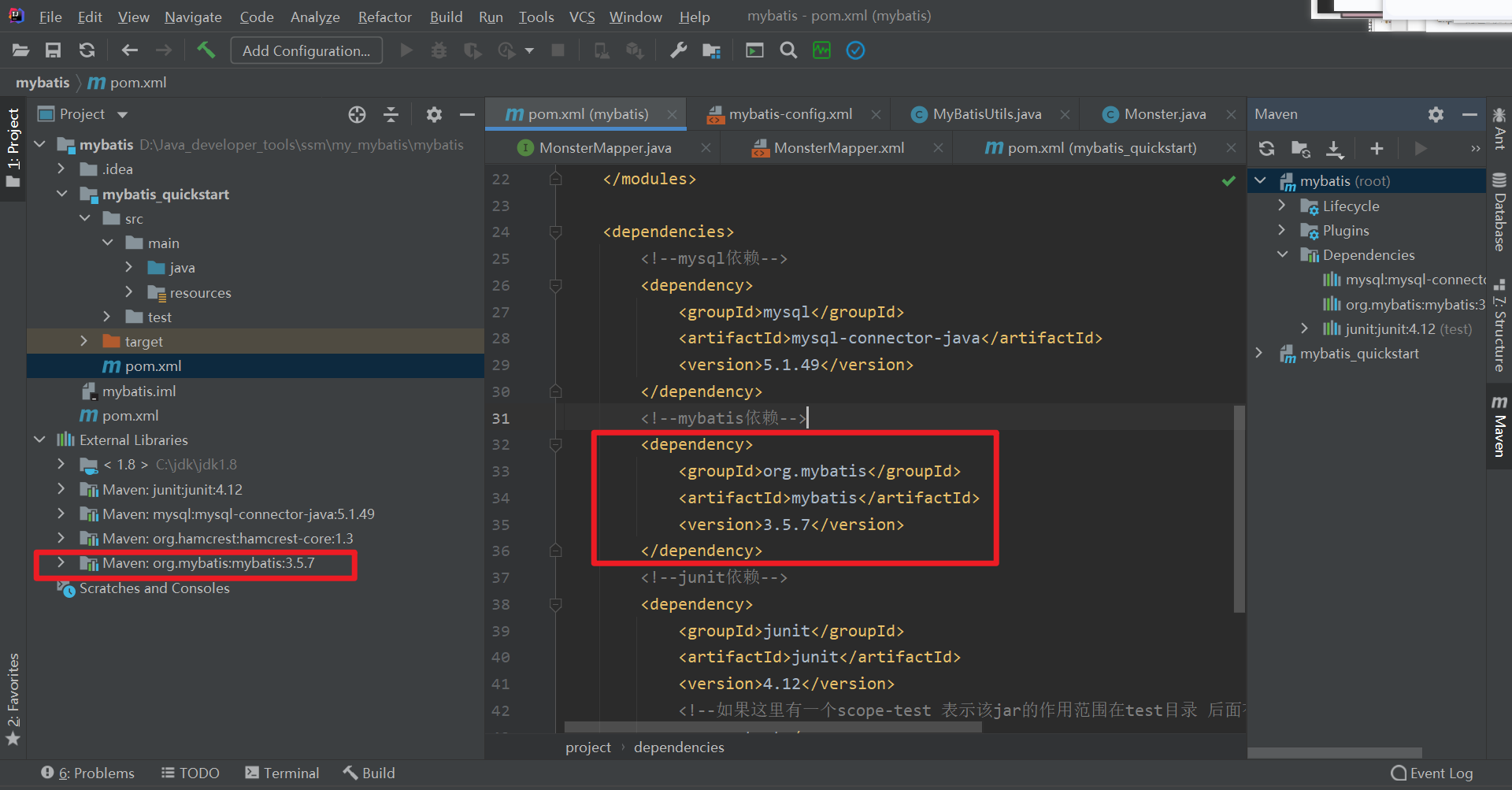
重新刷一下右侧的Maven刷新按钮 需要保证左侧的External Libraries出现
Maven:org.mybatis:mybatis:3.5.7
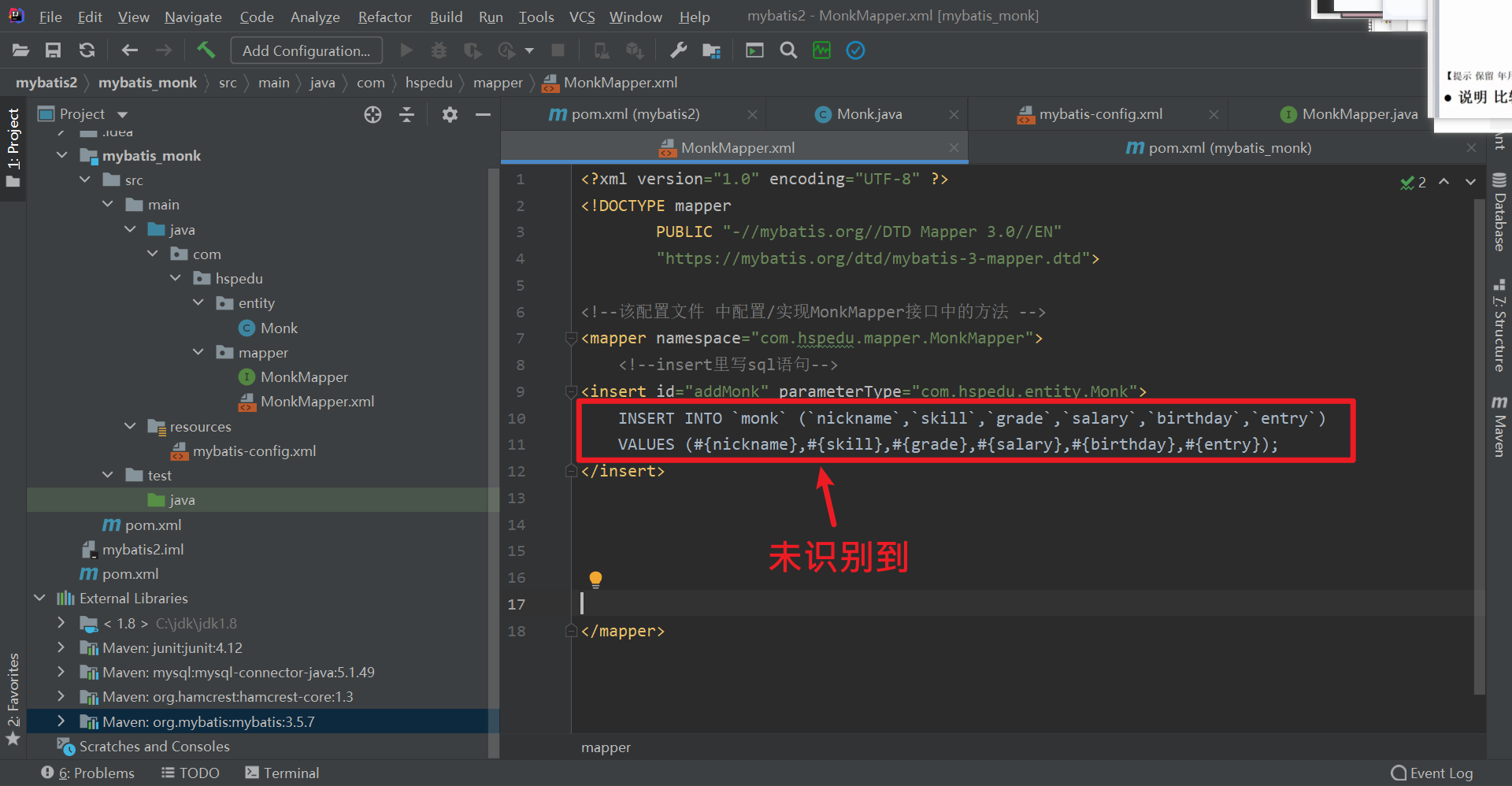
2 MyBatis Mapper.xml中识别不到insert语句
解决方法:
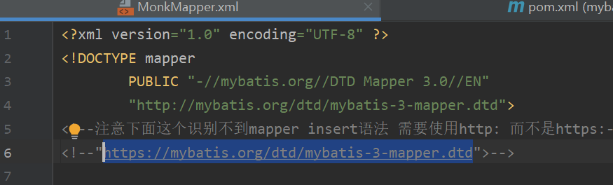
文件头中使用 "http://mybatis.org/dtd/mybatis-3-mapper.dtd"
mybatis-config.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--注意点:mybatis官方文档https://mybatis.org/mybatis-3/zh/getting-started.html中 使用的是
https://mybatis.org/dtd/mybatis-3-config.dtd和https://mybatis.org/dtd/mybatis-3-mapper.dtd
但是在自己写的项目中 不好使
需要按照老韩使用的http协议的才好使
http://mybatis.org/dtd/mybatis-3-config.dtd和http://mybatis.org/dtd/mybatis-3-mapper.dtd
其中mybatis-config.xml 中使用https://mybatis.org/dtd/mybatis-3-config.dtd 也可以
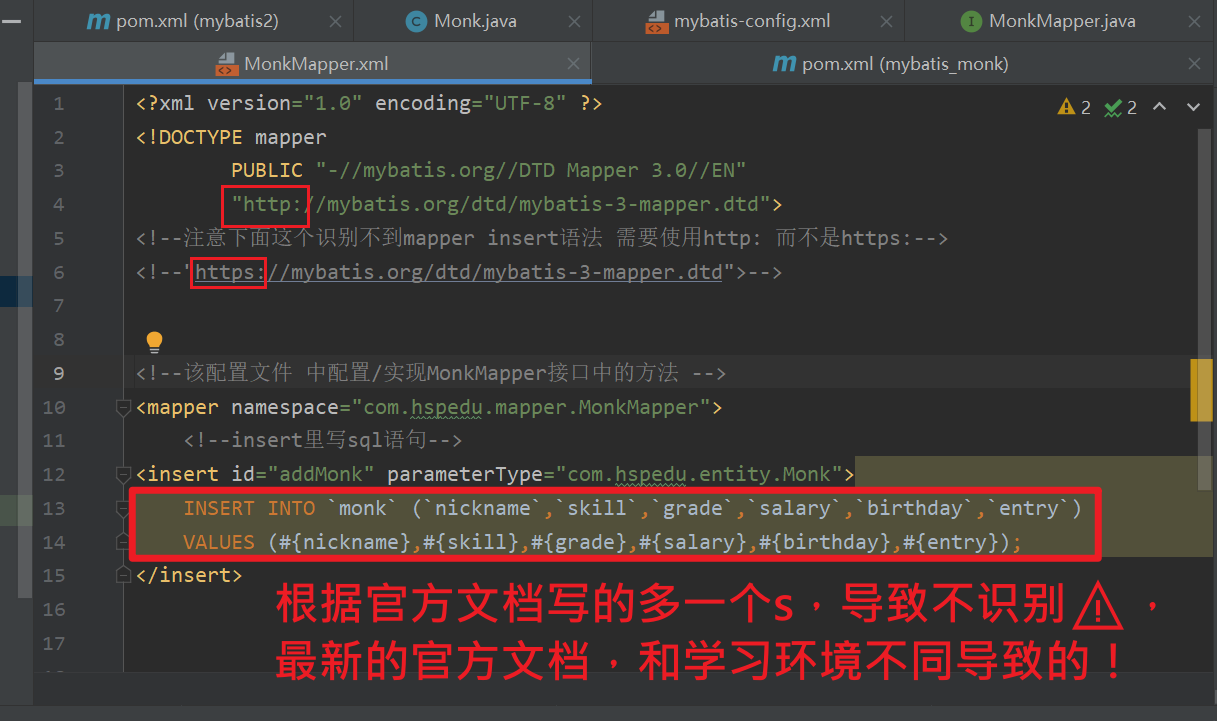
但是Mapper.xml中使用https://mybatis.org/dtd/mybatis-3-mapper.dtd 不好使!!
mapper标签中检测不到insert语法
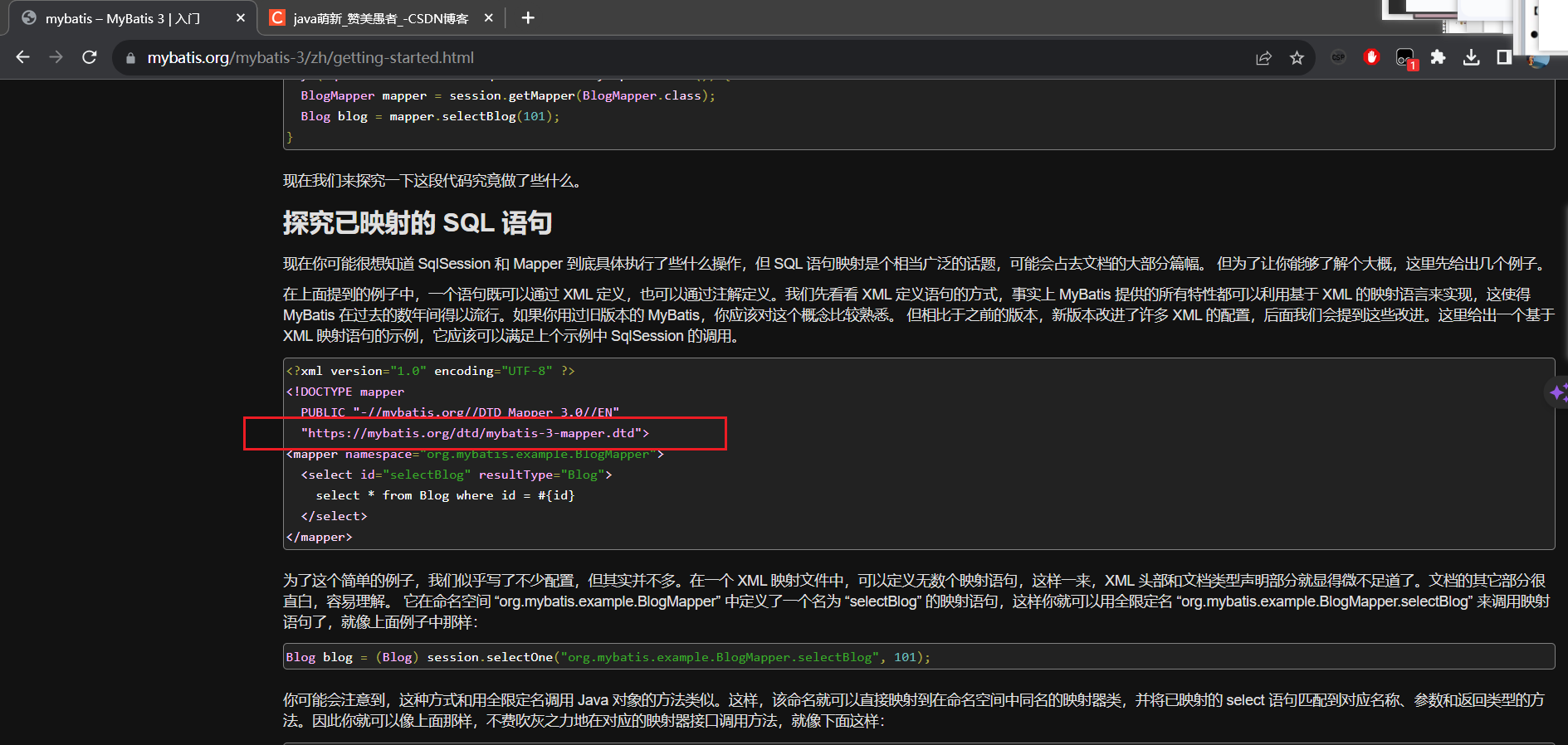
3 saxReader 获取元素属性值的方式有两种
try {
// 得到hspspringmvc1.xml文件的文档对象
Document document = saxReader.read(resourceAsStream);
// 获取根元素
Element rootElement = document.getRootElement();
// 通过根节点获取 子元素
Element element = rootElement.element("component-scan");
// 获取元素的base-package属性
Attribute attribute = element.attribute("base-package");
//String attributeValue = element.attributeValue("base-package");
// 获取属性的值 方式一:
String pack = attribute.getText();
System.out.println("通过 attribute.getText() 获取到的属性的值pack= " + pack);
//通过 attribute.getText() 获取到的属性的值pack= com.hspedu1.controller,com.hspedu1.service
// 获取属性的值 方式二:
// 下面这种方式也可以获取到属性的值 是一样的
//String pack2 = element.attributeValue("base-package");
//System.out.println("通过 element.attributeValue(\"base-package\");" +
// " 获取到的属性的值pack2= " + pack2);
//通过 element.attributeValue("base-package"); 获取到的属性的值pack2= com.hspedu1.controller,com.hspedu1.service
return pack;
} catch (Exception e) {
e.printStackTrace();
}
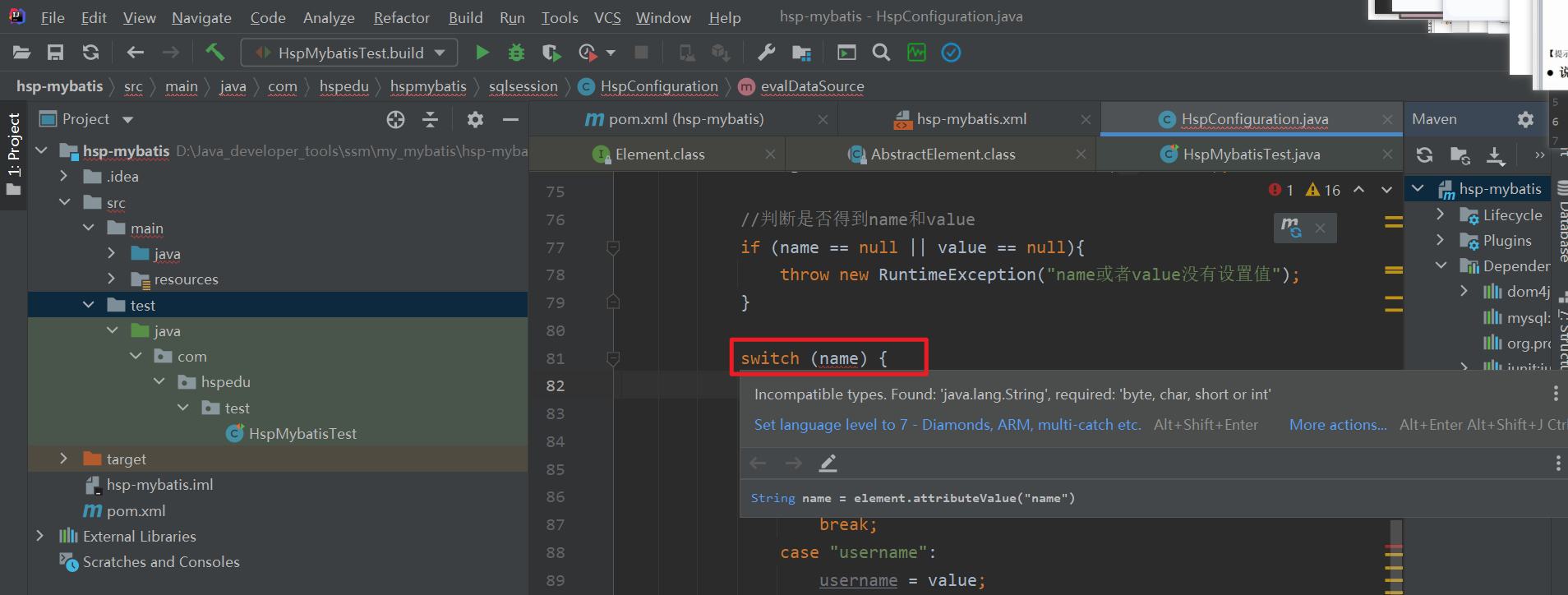
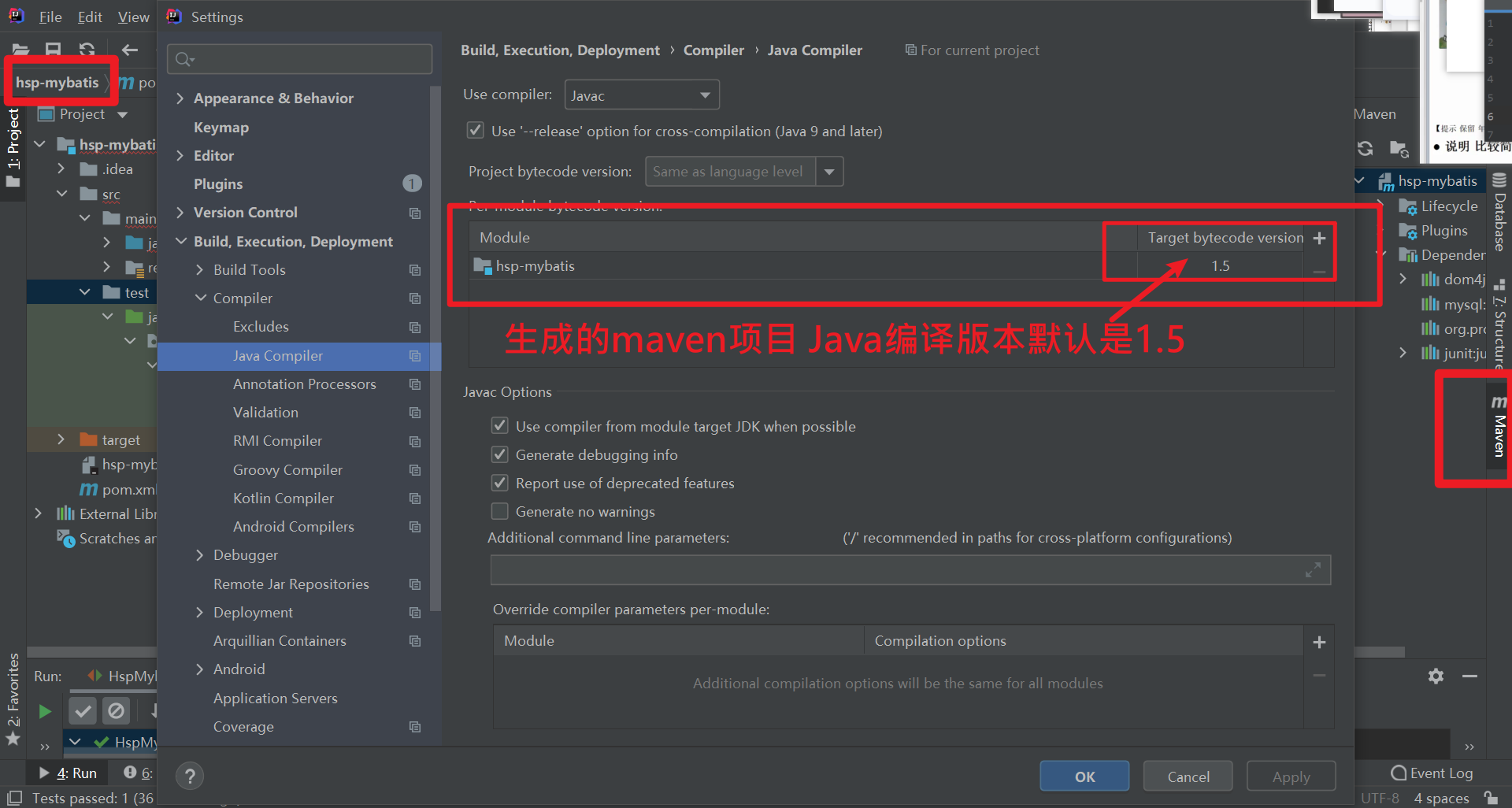
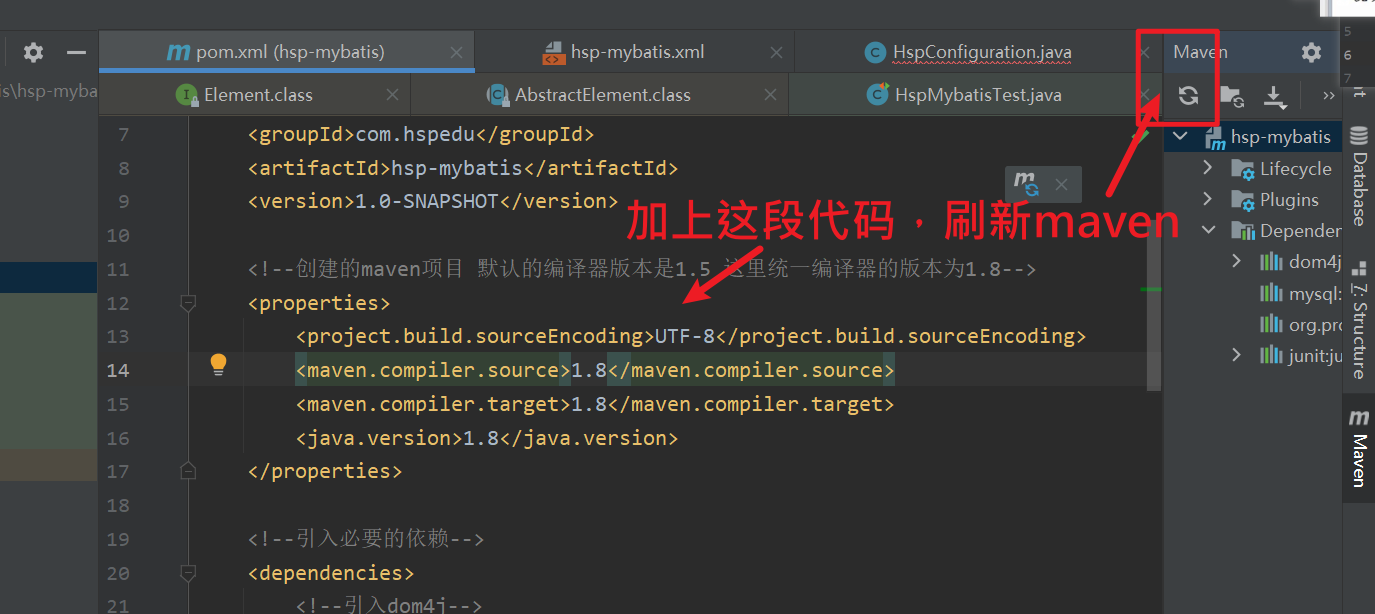
4 创建的maven项目 默认的编译器版本是1.5 在pom.xml文件中加入一段代码 统一编译器的版本为1.8
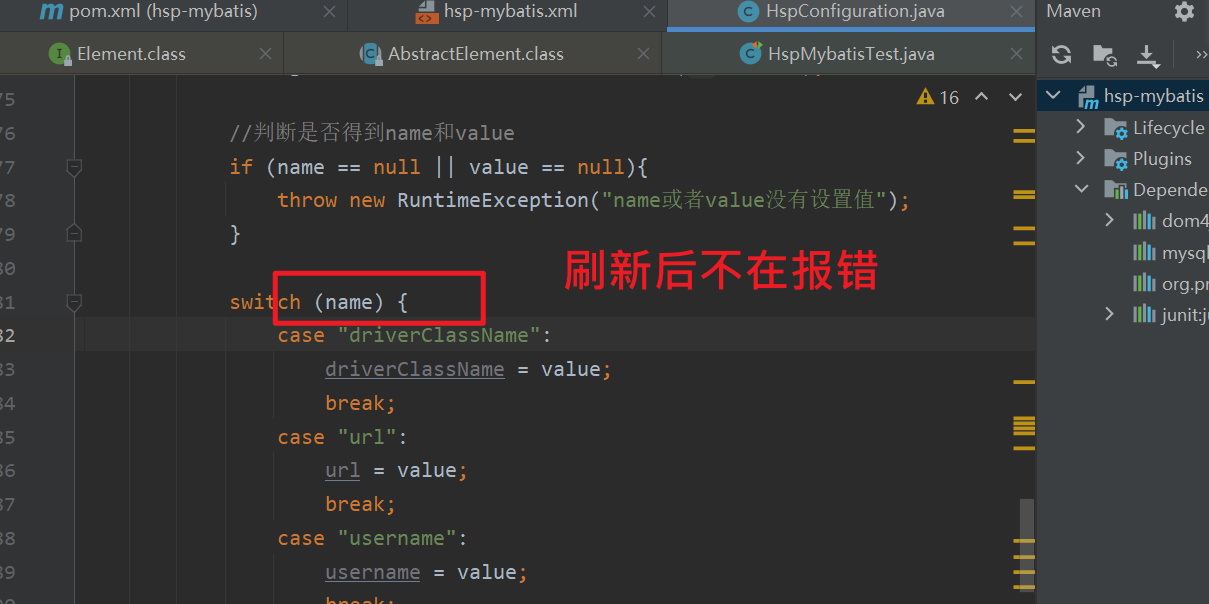
Java1.5 的编译器 switch case 语句中 switch() 中 不能使用 String类型
需要改成1.8的
switch结构中的表达式,只能是如下的6种数据类型之一: byte 、short、char、int、枚举类型(JDK5.0新增)、String类型(JDK7.0新增)
Incompatible types. Found: 'java.lang.String', required: 'byte, char, short or int'
<!--创建的maven项目 默认的编译器版本是1.5 这里统一编译器的版本为1.8-->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
</properties>
解决方法:
5 IDEA Lombok无法获取get、set方法
今天尝试在IDEA中使用Lombok,但是在编译时,提示找不到set()和get()方法,我明明在javabean中使用了@Data注解,但是编译器就是找不到。于是从网上查询了很多的方法去解决,最后终于解决了。接下来我就将过程分享一下,希望能够帮助需要的人:
Idea下安装lombok(需要二步)
第一步: pom.xml中加入lombok依赖包
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.20</version>
<scope>provided</scope>
</dependency>
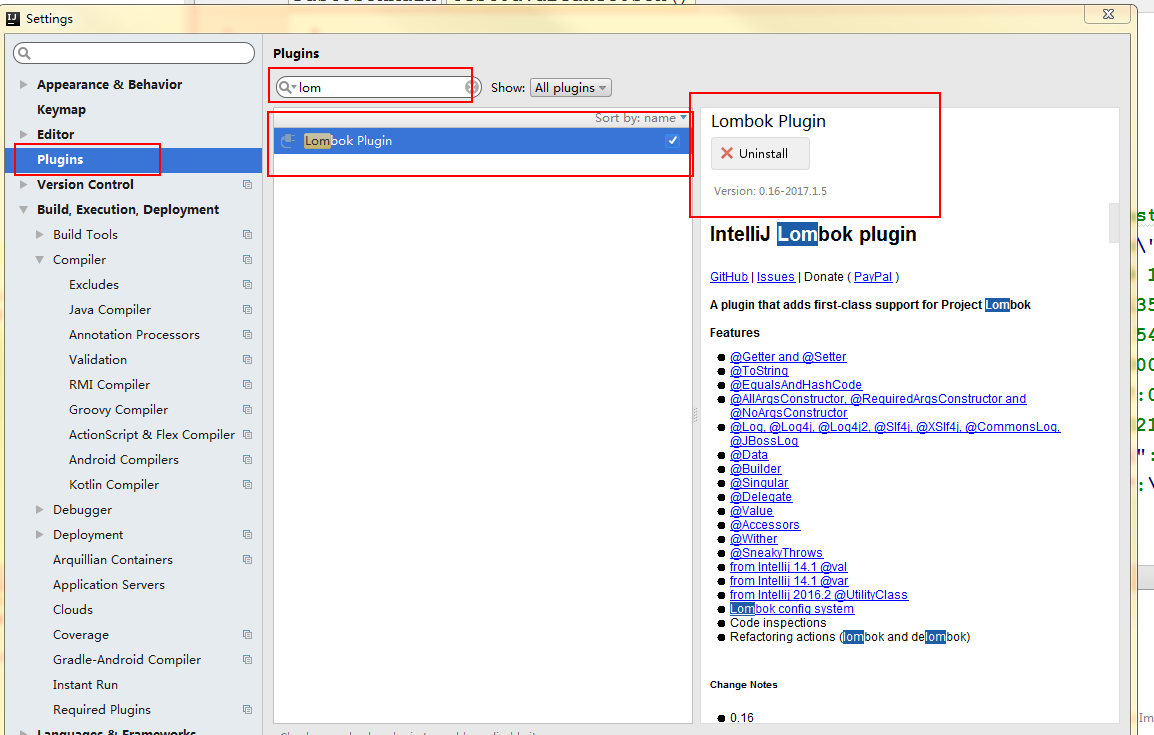
第二步:加入lombok插件
步骤:File ——》Settings——》Plugins. 搜索lombok,点击安装install。然后会提示重启,重启。
解决编译时无法找到set和get 的问题:
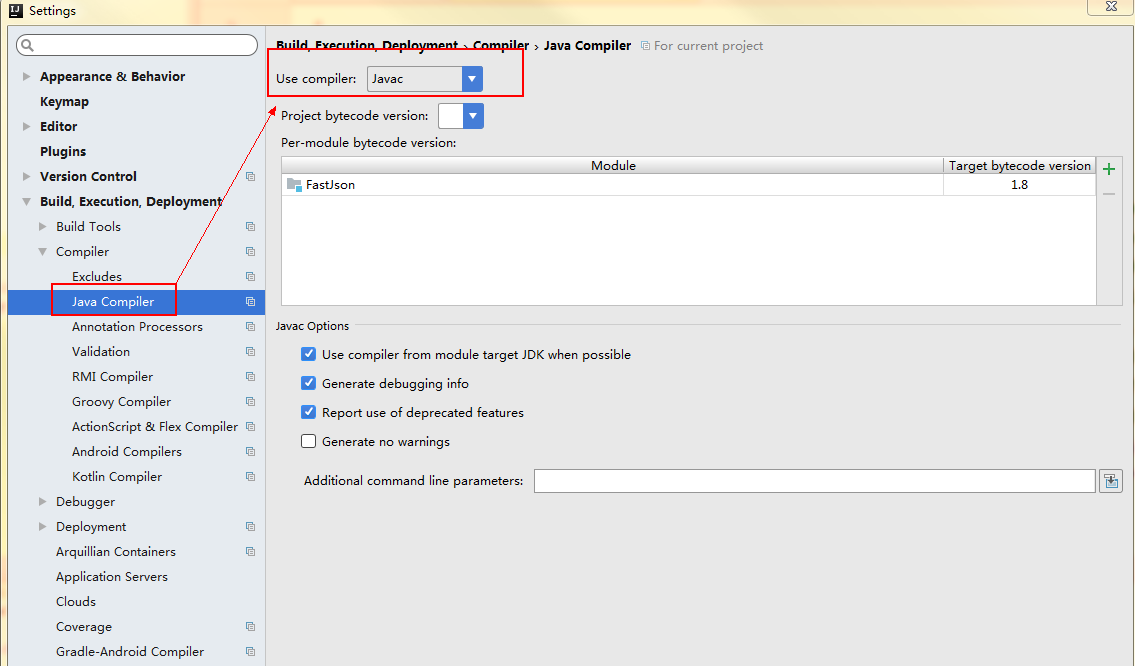
可能一:IDEA的编译方式选项错误,应该是javac,而不是eclipse。因为eclipse是不支持lombok的编译方式的,javac支持lombok的编译方式。
可能二:没有打开注解生成器Enable annotation processing。
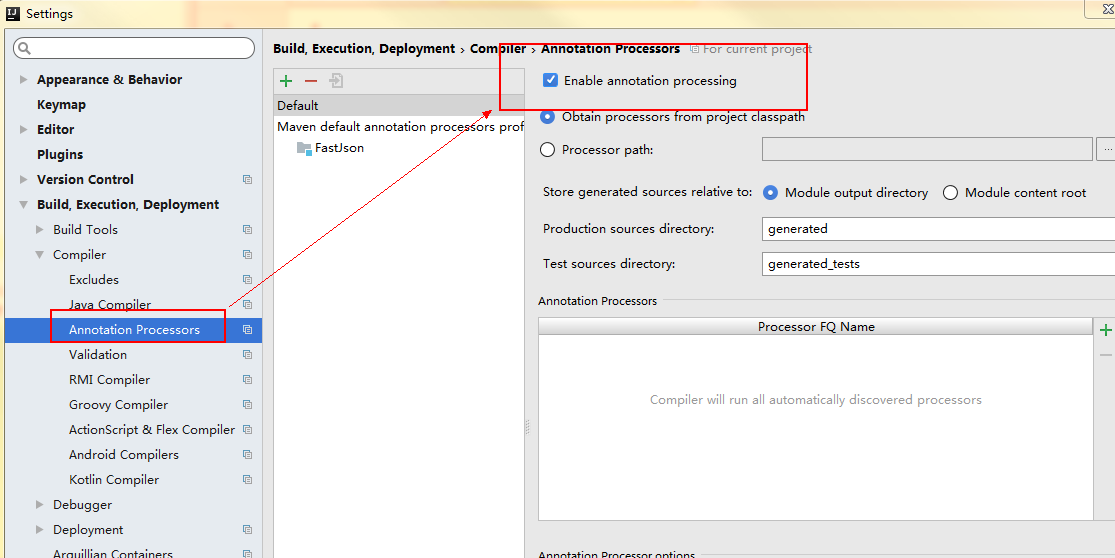
可能三(我遇到的就是这个问题):pom.xml中加入的lombok依赖包版本和自动安装的plugin中的lombok依赖包版本不一致。
因为我们添加的lombok插件plugin,点击insall时是自动安装的最新版本的lombok。但是我在pom.xml中的依赖包是maven中的低版本的一个依赖包,版本不一致,造成了无法找到set和get.
6 MySQL 字符串类型用数字可以查出来 MySQL字符串类型会转换成数字 MySQL隐式类型转换
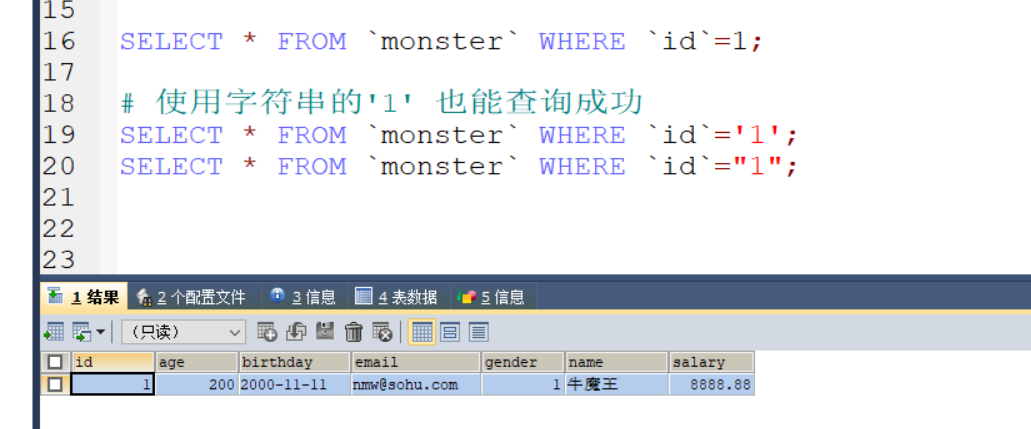
1、原因: 当MySQL字段类型和传入条件数据类型不一致时,会进行隐形的数据类型转换(MySQL Implicit conversion)
2、若字符串是以数字开头,且全部都是数字,则转换为数字结果是整个字符串;部分是数字,则转换为数字结果是截止到第一个不是数字的字符为止。 理解: varchar str = "123dafa",转换为数字是123 。 SELECT '123dafa'+1 ; --- 124 。
3、若字符串不是以数字开头,则转换为数字结果是 0 。 varchar str = "aabb33" ; 转换为数字是 0 。 SELECT 'aabb33'+100 ; --- 100 。
4、更多隐式转换规则摘录:
两个参数至少有一个是 NULL 时,比较的结果也是 NULL,例外是使用 <=> 对两个 NULL 做比较时会返回 1,这两种情况都不需要做类型转换 两个参数都是字符串,会按照字符串来比较,不做类型转换 两个参数都是整数,按照整数来比较,不做类型转换 十六进制的值和非数字做比较时,会被当做二进制串 有一个参数是 TIMESTAMP 或 DATETIME,并且另外一个参数是常量,常量会被转换为 timestamp 有一个参数是 decimal 类型,如果另外一个参数是 decimal 或者整数,会将整数转换为 decimal 后进行比较,如果另外一个参数是浮点数,则会把 decimal 转换为浮点数进行比较
3.1、SELECT 'a10'+10 ; -- 10
SHOW WARNINGS ; -- WARNINGS: Truncated incorrect DOUBLE value: 'a10'
查看warnings可以看到隐式转化把字符串转为了double类型。但是因为字符串是非数字型的,所以就会被转换为0,因此最终计算的是0+10=10 .
3.2、SELECT '10a'+10 ; -- 20
SHOW WARNINGS ; -- WARNINGS: Truncated incorrect DOUBLE value: '10a'
3.3、SELECT 'a'=0 ; -- 1 , 相当于 true
SHOW WARNINGS ; -- WARNINGS: Truncated incorrect DOUBLE value: 'a'
3.4、SELECT 'a23423' = 0 ; -- 1 , 相当于 true
SHOW WARNINGS ; -- WARNINGS:Truncated incorrect DOUBLE value: 'a23423'
3.5、SELECT '11dafdfwwe'=11; -- 1, 相当于 true
SHOW WARNINGS ; -- WARNINGS:Truncated incorrect DOUBLE value: '11dafdfwwe'
3.6、SELECT 11= 11 ; -- 1, 相当于 true
SHOW WARNINGS ; -- 无
3.7、SELECT 'abc'='abc' ; -- 1, 相当于 true
SHOW WARNINGS ; -- 无
3.8、SELECT 'abc'='abc232322' ; -- 0 , 数据类型一样,不会进行转换
SHOW WARNINGS ; -- 无
3.9、SELECT 'a'+'b'; -- 0 , 都转换为0了, 0+0=0 。
SHOW WARNINGS ; -- WARNINGS: Truncated incorrect DOUBLE value: 'a' , Truncated incorrect DOUBLE value: 'b'
3.10、SELECT 'a'+'b'='c' ; -- 1 ,等价于 0+0=0 --> 0=0=1。
SHOW WARNINGS ; -- WARNINGS: Truncated incorrect DOUBLE value: 'a' , Truncated incorrect DOUBLE value: 'b' , Truncated incorrect DOUBLE value: 'c'
7 快速复制全类名
<?xml version="1.0" encoding="UTF-8" ?>
<!--这里的全类名 可以使用【右键菜单】-【Copy】-【Copy Reference】-->
<mapper nameSpace="com.hspedu.mapper.MonsterMapper">
<select id="getMonsterById" resultType="com.hspedu.entity.Monster">
</select>
</mapper>
8 快速复制 Path From Source Root
<!--说明
1. 这里我们配置需要关联的Mapper.xml
2. 这里可以通过 [菜单]-[Copy]-[Path From Source Root]
点击生成下面需要的格式:全路径点换成斜杠加上文件后缀
-->
<mappers>
<mapper resource="com/hspedu/mapper/MonsterMapper.xml"/>
</mappers>
9 泛型方法 public <T> T getMapper(Class<T> clazz){} ,泛型指定的时机
//编写方法 返回代理对象 Class<T> 这里传入时 指定了T的类型!!!
public <T> T getMapper(Class<T> clazz){
return (T)Proxy.newProxyInstance(clazz.getClassLoader(), new Class[]{clazz},
new HspMapperProxy(hspConfiguration,this,clazz));
}
@Test
public void openSession(){
HspSqlSession hspSqlSession = HspSessionFactory.openSession();
// 这里 alt+enter 自动补全的返回 MonsterMapper 类型 因为
//public <T> T getMapper(Class<T> clazz){} 返回代理对象
// Class<T> 这里传入时 指定了T的类型!!!
//
MonsterMapper mapper = hspSqlSession.getMapper(MonsterMapper.class);
// 测试 确实是 在getMapper(Class<T> clazz) 传入时 指定了T的类型!!!
// 返回类型也按照 T 类型进行返回的
//Goods goods = hspSqlSession.getMapper(Goods.class);
// 这里自动补全的就是Monster类型 是因为在接口中声明的返回类型就是Monster
Monster monster = mapper.getMonsterById(1);
System.out.println("monster====== " + monster);
}
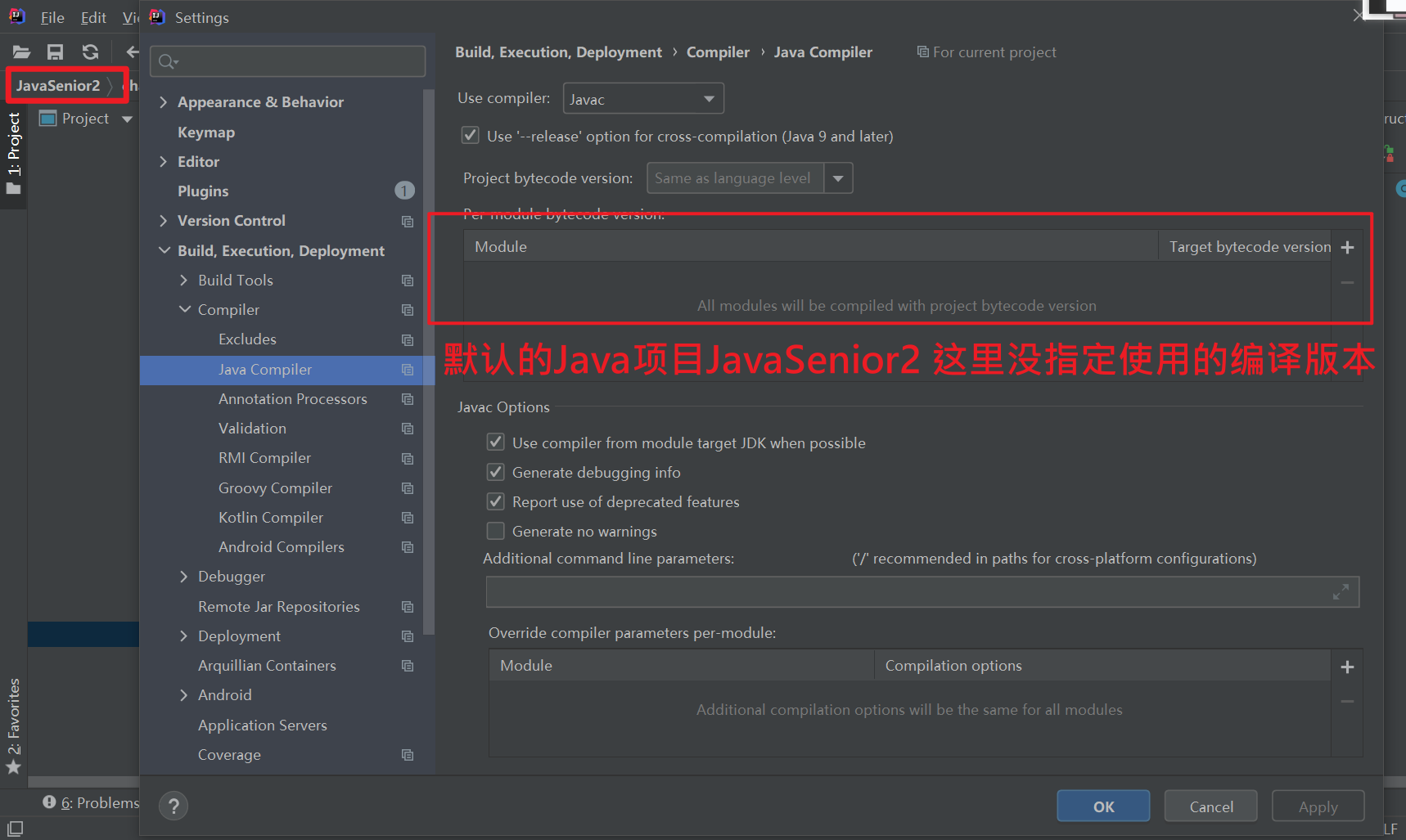
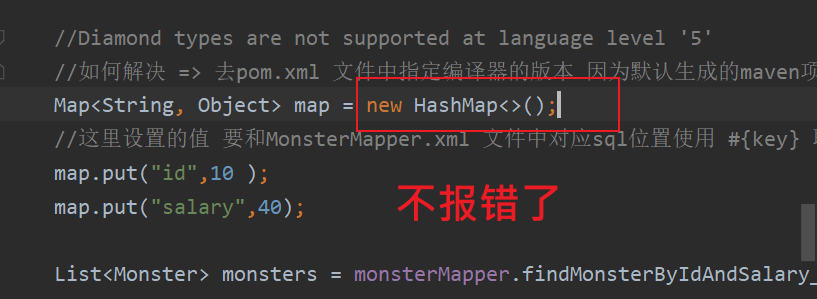
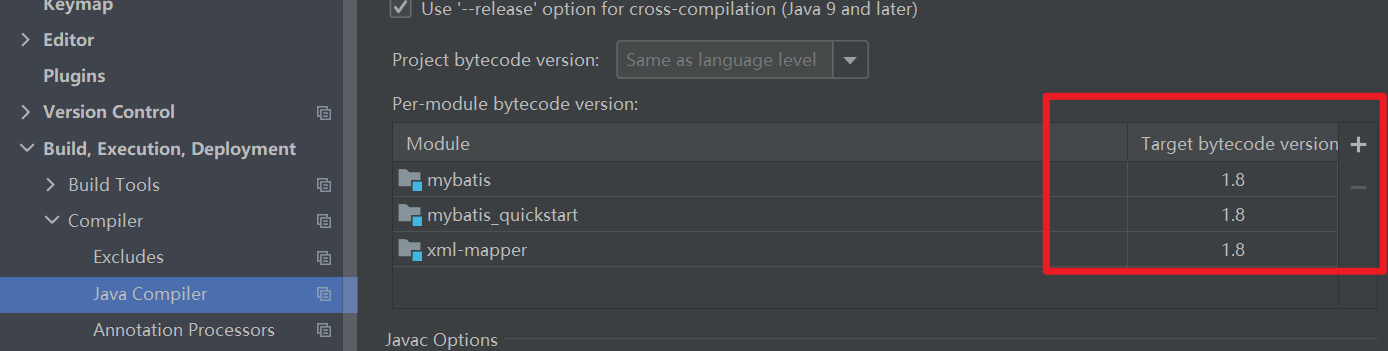
10 解决maven项目 默认编译器版本1.5问题
1.5 不可以使用钻石<>符号 会报错
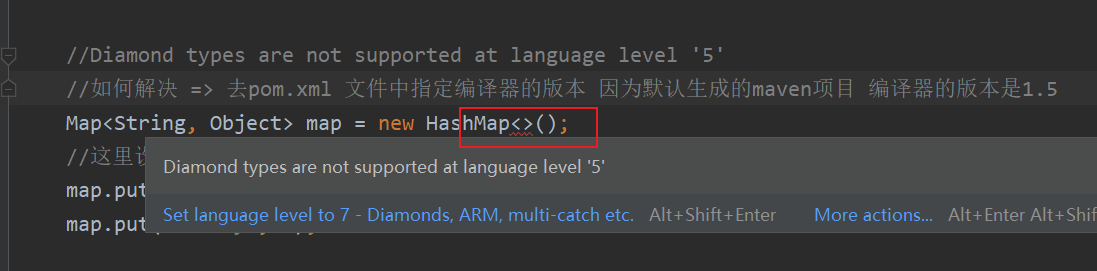
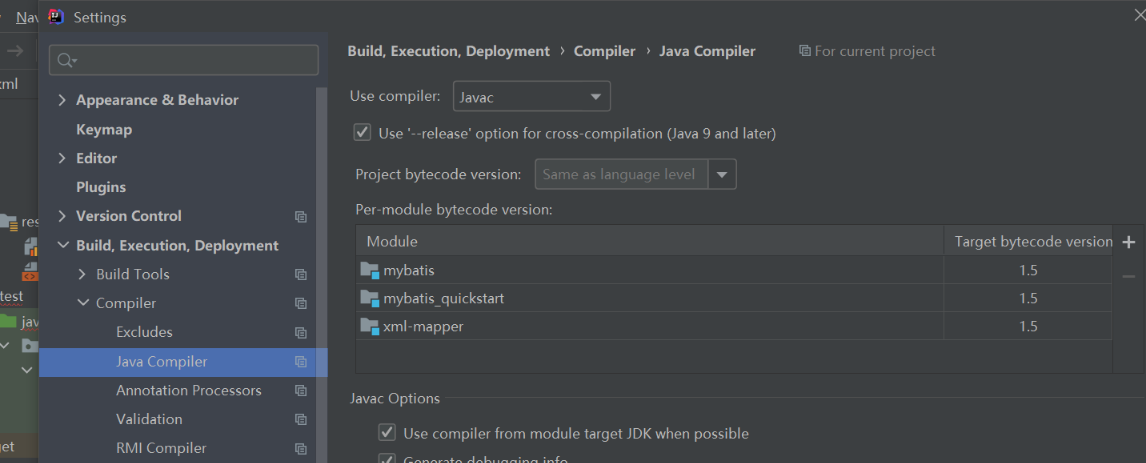
解决方法:
1 . 在父项目 的pom.xml 文件中指定
<!--Settings-Build,...-Compiler-Java Compiler- Target bytecode version 默认是1.5-->
<!--这里指定maven编译器 和 jdk的版本 /source/target/java的版本为1.8 -->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
</properties>
2 . 刷新Maven
11 mybatis mapper.xml文件中注释说明
在mapper.xml 文件中的 <select> 等语句块中 可以使用的注释 如下:
<!---->
<!--注意 最好不要在 下面的select 语句中写注释 杠杠 和 /**/ 的注释会导致报错 但是下面那种注释没事
会被当成sql的一部分 导致查询失败 报错-->
<select id="getPersonById" parameterType="Integer" resultMap="personResultMap">
SELECT * FROM `person`,`idencard`
WHERE `person`.`id` = #{id} AND `person`.`id` = `idencard`.`id`;
<!-- SELECT `person`.`id`,`person`.`NAME`,`person`.`card_id`,`idencard`.`card_sn` FROM `person`,`idencard`-->
<!-- WHERE `person`.`id` = #{id} AND `person`.`id` = `idencard`.`id`;-->
</select>
12 resultMap 细节
<resultMap id="resultWifeMap" type="Wife">
<!--这里如果 没有指定 就按照默认的规则进行匹配
即 javabean属性名和表的字段名要保持一致,否则匹配不上,封装的Javabean对象该属性值为null-->
<!--<result property="id" column="id"/>-->
<result property="name" column="wife_name"/>
</resultMap>
<select id="getWifeById" parameterType="Integer" resultMap="resultWifeMap">
SELECT * FROM `wife` WHERE `id` = #{id};
</select>
“ofType” 属性。这个属性非常重要,它用来将 JavaBean(或字段)属性的类型和集合存储的类型区分开来。 所以你可以按照下面这样来阅读映射:
<collection property="posts" javaType="ArrayList" column="id" ofType="Post" select="selectPostsForBlog"/>
读作: “posts 是一个存储 Post 的 ArrayList 集合”
在一般情况下,MyBatis 可以推断 javaType 属性,因此并不需要填写。所以很多时候你可以简略成:
<collection property="posts" column="id" ofType="Post" select="selectPostsForBlog"/>
在UserMapper.xml 的 resultMap 中使用 collection 标签 如果没有指定 集合的javaType // mybatis底层会 进行类型推断 默认封装为'class java.util.ArrayList'
// 会出现栈溢出 StackOverflowError
// 原因:
// 在UserMapper.xml 的 resultMap 中使用 collection 标签 如果没有指定 集合的javaType
// mybatis底层会 进行类型推断 默认封装为'class java.util.ArrayList'
// ArrayList 直接输出 也会调用集合中元素的toString 方法
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
// 下面打印pets时 会调用pet.toString
// 通过输出pets的运行类型 可以发现声明为List类型的属性
// mybatis底层会 进行类型推断 封装为'class java.util.ArrayList'
// 因为ArrayList 重写了 toString方法 因此
// 又会调用ArrayList集合中元素的toString方法 即调用pet.toString
// 而pet.toString 中 直接输出了user对象 就又会调用user.toString...
// 因此造成了栈溢出
", pets=" + pets + ", pets.getClass='" + pets.getClass() + '\'' +
'}';
}
12.1 MyBatis和MyBatisPlus中 <resultMap>映射机制的详细解释
在 MyBatis 中,JavaBean 属性名和数据库字段名的映射非常关键,正确设置这一映射是保证数据正确封装到 JavaBean 中的前提。以下是 MyBatis 映射机制的详细解释:
1. 默认映射行为
如果在 MyBatis 的 <resultMap> 中没有明确指定映射关系,MyBatis 默认采用属性名与字段名相同的规则来自动匹配。这意味着,JavaBean 的属性名必须与数据库表的字段名完全一致(包括字母的大小写),否则这些字段将无法被正确封装,其对应的属性值会是 null。
例如,如果数据库中的字段名为 wife_name,而 JavaBean 中的属性名为 wifeName,不使用 <result> 指定映射关系的话,wifeName 属性将会得到 null 值。
2. 指定映射关系
为了解决字段名与属性名不一致的问题,可以在 <resultMap> 中使用 <result> 标签明确指定映射关系。例如:
<resultMap id="resultWifeMap" type="Wife">
<result property="wifeName" column="wife_name"/>
</resultMap>
这样配置后,wife_name 字段的值就会正确地映射到 wifeName 属性上。
3. MyBatis Plus 的自动映射扩展
MyBatis Plus 是 MyBatis 的一个扩展框架,它提供了更加强大的映射功能,包括自动的驼峰命名转换(即自动将数据库中的下划线分隔命名转换为 JavaBean 中的驼峰式命名)。这意味着,在 MyBatis Plus 中,即便不通过 <resultMap> 明确指定映射关系,wife_name 也能自动映射到 wifeName 属性。
4. 总结
-
MyBatis: 需要属性名和字段名完全一致,或者通过
<resultMap>明确指定映射关系。 -
MyBatis Plus: 提供自动的驼峰命名转换,更加灵活。
在实际开发中,建议根据具体需求选择合适的工具和配置。如果是在使用标准的 MyBatis,确保你的 <resultMap> 配置正确,或者调整数据库字段名和 JavaBean 属性名使其一致。如果希望有更自动化的映射支持,可以考虑使用 MyBatis Plus。
12.2 MyBatis 和 MyBatis Plus 时,对于表名(tablename)的处理也存在一些差异,尤其是在映射和使用便捷性方面。
在使用 MyBatis 和 MyBatis Plus 时,对于表名(tablename)的处理也存在一些差异,尤其是在映射和使用便捷性方面。让我们一起看看这两个框架是如何处理表名映射的:
MyBatis 关于表名的映射
在 MyBatis 中,表名通常是硬编码在 XML 映射文件或者注解中的。MyBatis 本身不提供表名的自动映射功能,开发者需要在每个 SQL 映射中明确指定使用的表名。
例如,使用 XML 配置时,你需要在 <select>、<insert>、<update> 或 <delete> 标签的 SQL 语句中直接引用表名:
<select id="selectWife" resultType="Wife">
SELECT * FROM wife WHERE id = #{id}
</select>
在这种情况下,如果表名变更,你需要手动更新所有引用了该表名的 SQL 映射。
MyBatis Plus 关于表名的映射
MyBatis Plus 提供了更高级的映射机制,包括对表名的自动映射。这是通过在实体类上使用 @TableName 注解来实现的。这样,你可以在一个地方定义表名,MyBatis Plus 会在执行任何 CRUD 操作时自动使用正确的表名。
@TableName("wife")
public class Wife {
private Integer id;
private String name;
// getter and setter
}
使用 MyBatis Plus 的好处是,如果表名发生变化,你只需要更新 @TableName 注解中的值即可,无需修改每个 SQL 映射。此外,MyBatis Plus 还支持动态表名,通过实现 ITableNameHandler 接口可以在运行时动态改变表名,这对于多租户系统等场景非常有用。
总结
-
MyBatis: 需要在每个 SQL 映射中手动指定表名,没有内置的自动映射功能。
-
MyBatis Plus: 通过
@TableName注解提供表名的自动映射,支持动态表名,增加了开发的便利性和灵活性。
根据项目的具体需求选择使用 MyBatis 或 MyBatis Plus。如果项目中表名经常变化,或者需要支持动态表名(如多租户场景),MyBatis Plus 是一个更好的选择。如果项目比较简单,表结构变化不频繁,使用 MyBatis 就已经足够。
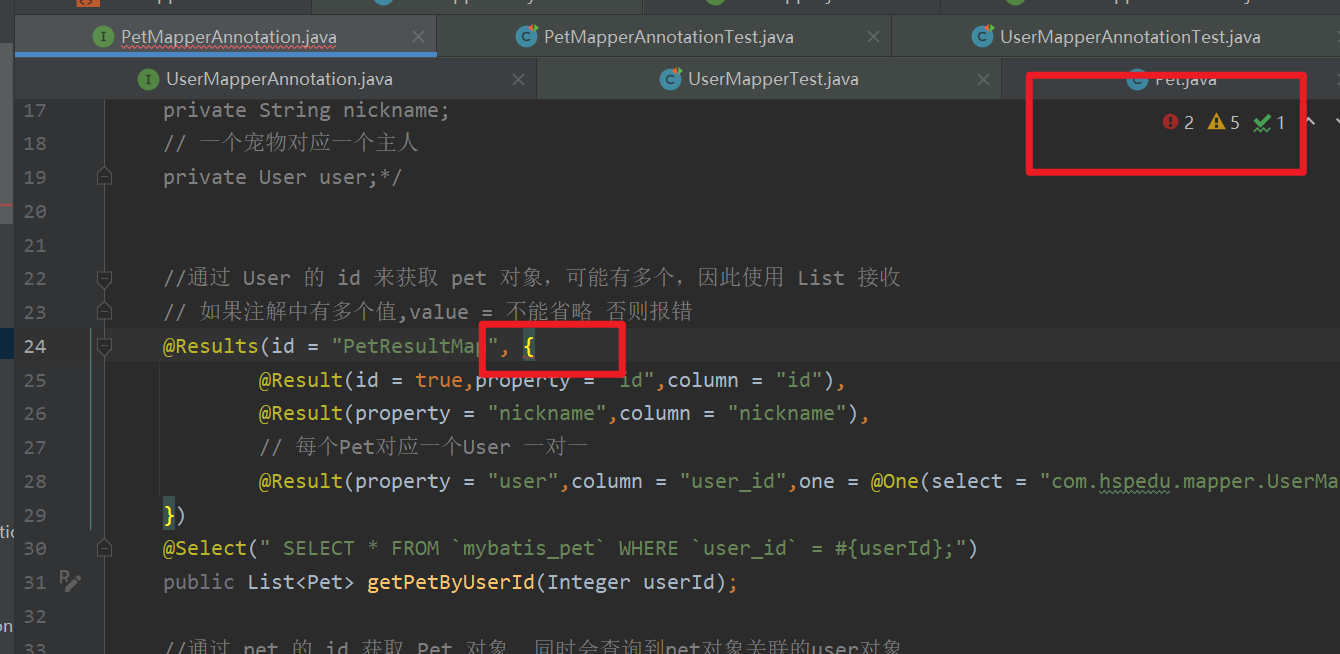
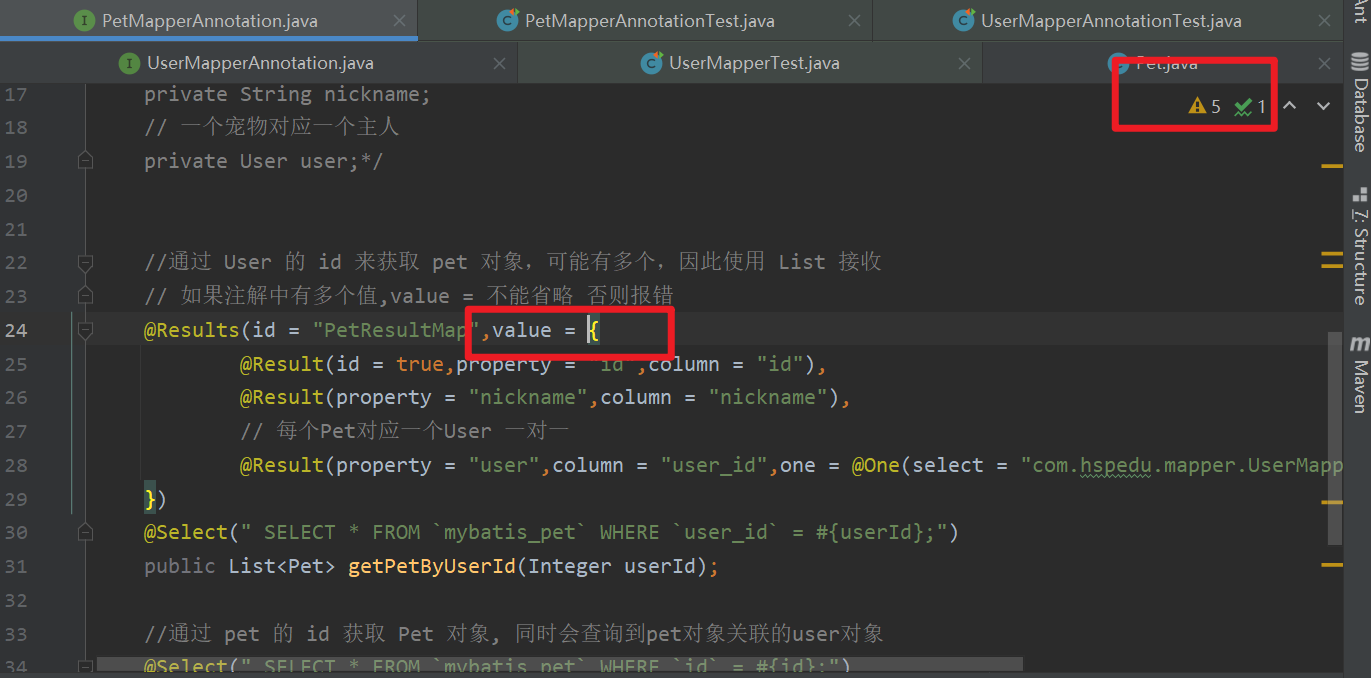
13 如果注解中有多个值,value = 不能省略 否则报错
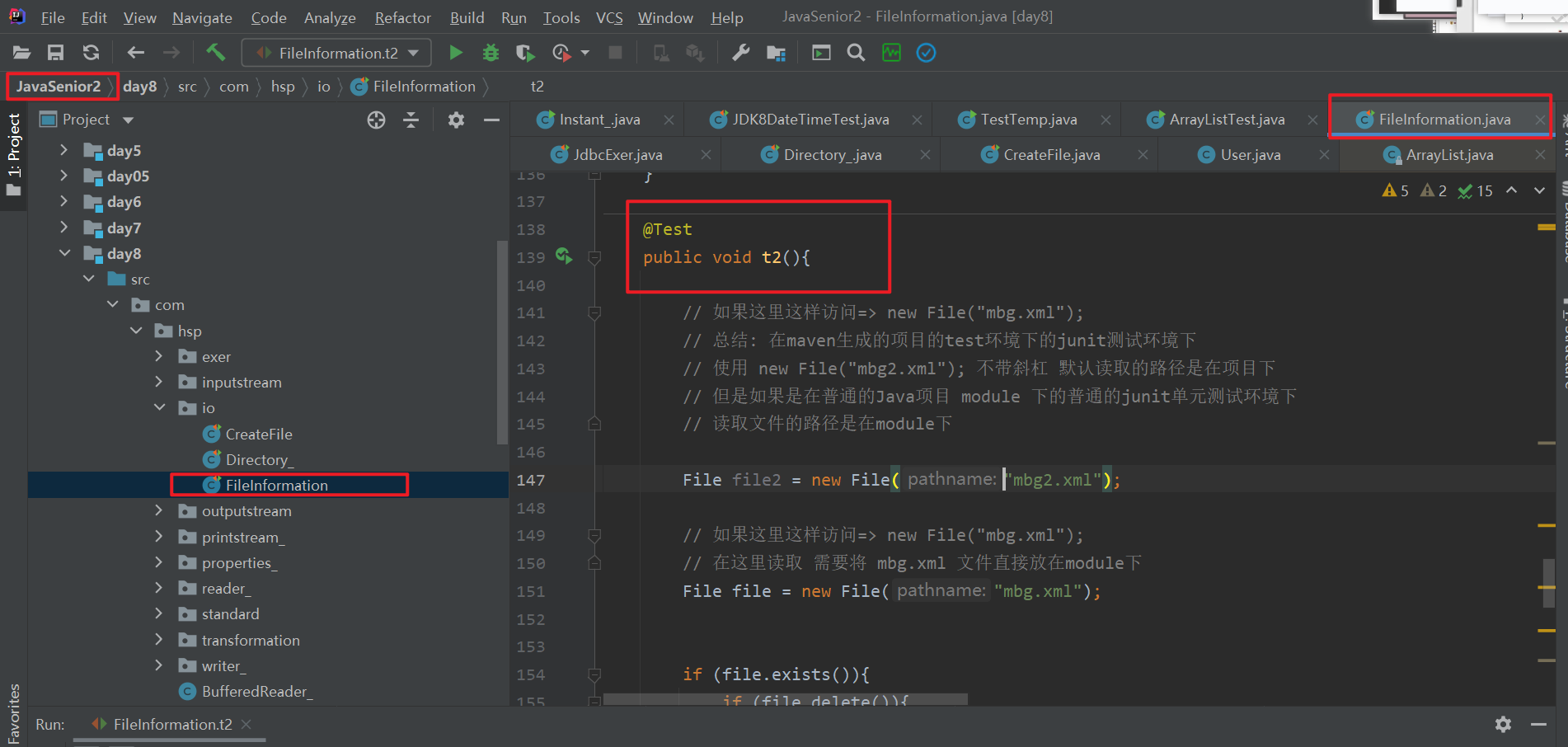
14 new File("mbg2.xml"); 在不同环境下 读取文件的路径不同
// 总结: 在maven生成的项目的test环境下的junit测试环境下
// 使用 new File("mbg2.xml"); 不带斜杠 默认读取的路径是在项目下
// 但是如果是在普通的Java项目 module 下的普通的junit单元测试环境下
// 读取文件的路径是在module下
注意不要使用核心文件mbg.xml文件进行测试!!
测试代码如下 可以将下面的这段代码 拿到不同的环境中进行测试
如
-
普通的Java工程 junit @Test 环境
![image-20231108202903187]()
-
maven 创建的 web项目 furn_ssm 项目下 的 项目专门的test环境 下 使用 junit @Test junit @Test 进行测试
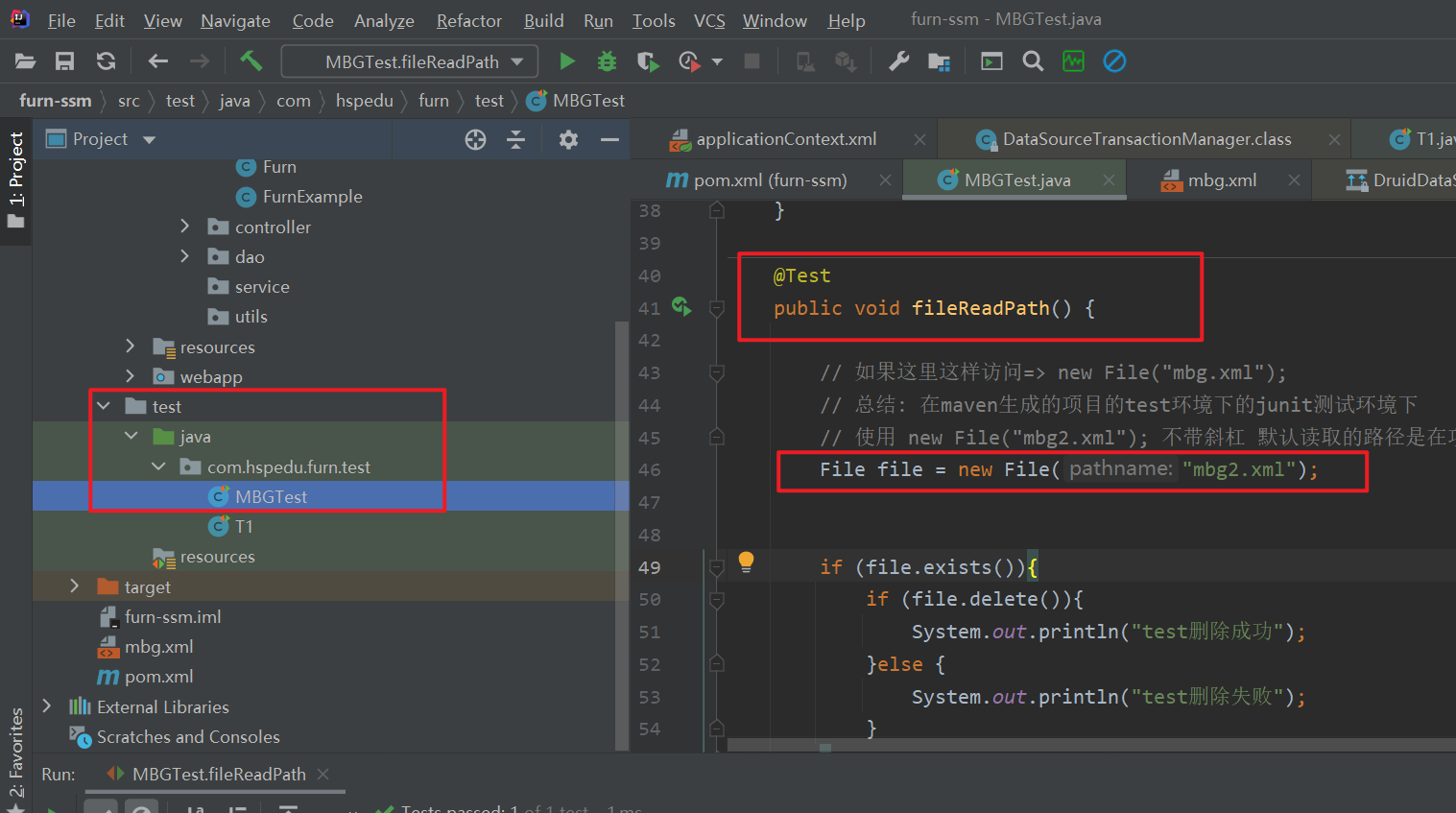
@Test
public void t2(){
// 如果这里这样访问=> new File("mbg.xml");
// 总结: 在maven生成的项目的test环境下的junit测试环境下
// 使用 new File("mbg2.xml"); 不带斜杠 默认读取的路径是在项目下
// 但是如果是在普通的Java项目 module 下的普通的junit单元测试环境下
// 读取文件的路径是在module下
File file2 = new File("mbg2.xml");
// 如果这里这样访问=> new File("mbg.xml");
// 在这里读取 需要将 mbg.xml 文件直接放在module下
// File file = new File("mbg.xml");
if (file.exists()){
if (file.delete()){
System.out.println("test删除成功");
}else {
System.out.println("test删除失败");
}
}else {
System.out.println("test该文件不存在");
try {
file.createNewFile();
System.out.println("test文件绝对路径:" + file.getAbsolutePath());
//文件绝对路径:D:\testFile
System.out.println("test文件创建成功");
} catch (IOException e) {
e.printStackTrace();
}
}
//调用相应的方法,得到对应的信息
System.out.println("文件名:" + file.getName()); // 文件名:news1.txt
System.out.println("文件绝对路径:" + file.getAbsolutePath());
System.out.println("文件父级目录:" + file.getParent());
System.out.println("文件大小(字节):" + file.length());
System.out.println("文件是否存在:" + file.exists());
System.out.println("是否为文件:" + file.isFile());
System.out.println("是否是一个目录:" + file.isDirectory());//文件夹
}
15 导入了druid-starter但是如果没有进行配置,使用的数据源的类型为?
答:是默认的HikariDataSource数据源,即如果要使用Druid数据源不仅需要引入依赖,还需要进行配置
16 数据源的配置方式两种
1.使用注入bean的方式配置Druid数据源
package com.hspedu.springboot.mybatis.config;
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.sql.SQLException;
/**
* @author yangda
* @create 2023-12-16-20:45
* @description: DruidDataSourceConfig: 是一个配置类 该配置类的作用:切换数据源为 druid
* 最好先把这个类创建好,再把需要的代码拷贝过来,因为有时文件的编码不同/引入的包不同,
* 会出问题,这样也知道是为什么写这个类,只把需要的代码拿过来,这样是最安全的
* 如果复制多了,不需要的代码,有可能会出现新的问题
*/
@Configuration
public class DruidDataSourceConfig {
//老韩还有说明一下为什么我们注入自己的DataSource , 默认的HiKariDatasource失效?
//1. 默认的数据源是如配置? 在数据源自动配置类 DataSourceAutoConfiguration.java中进行的自动配置
// 这个类中频繁的使用到注解 @ConditionalOnMissingBean({ DataSource.class, XADataSource.class })
// 解读通过@ConditionalOnMissingBean({ DataSource.class}) 判断如果容器有DataSource Bean 就不注入默认的HiKariDatasource
//2. debug源码.
//3. 测试/证明 可以将本类全部注销,此时debug,查看主程序Application.java 的main方法中的ioc容器中
// 是否自动注入了"dataSource"=HikariDataSource , 再将本类打开后debug,注入的为"dataSource"=DruidDataSource
// 因此可以证明如果配置了其他的数据源(ioc中会注入DruidDataSource数据源)
// , HikariDataSource数据源就不注入了,ioc中会注入DruidDataSource数据源
//编写方法,注入DruidDataSource
//注意返回的是 package javax.sql; 包下的DataSource,不要引错了
/**
* 如果使用 DruidDataSource 必须标注
*
* @ConfigurationProperties("spring.datasource") 否则不好使
* 加了该注解后就会到application.yml文件中读取,配置好的参数信息
* 读取到后就会设置到DruidDataSource的父类DruidAbstractDataSource.java 中的相关的属性上
* 通过setUrl(),setUsername()...等方法,这是Druid就可以正常连接到数据库了
*/
@ConfigurationProperties("spring.datasource")
@Bean
public DataSource dataSource() throws SQLException {
/**
* DruidDataSource 实现了javax.sql.DataSource接口
* 所以可以按照接口的形式返回一个对象
*
* 1.配置了@ConfigurationProperties("spring.datasource")
* 就可以读取到application.yml的配置
* 2.就不需要调用DruidDataSource对象的setXxx()方法,一个一个的进行设置了
* 当然也可以进行设置但没必要
* ,因为配置了@ConfigurationProperties("spring.datasource")
* 后在底层会自动的进行关联
*/
DruidDataSource druidDataSource = new DruidDataSource();
// druidDataSource.setUrl();
// druidDataSource.setUsername();
// druidDataSource.setPassword();
// stat:统计
// wall:墙
// 加入sql监控功能,
// wall 加入sql防火墙监控,如果什么都没有配置,所有的sql语句都允许执行 可以配置黑名单白名单
// druidDataSource.setFilters("stat,wall");
return druidDataSource;
}
}
2.使用application.yml配置的方式切换到Druid数据源
#application.yml如下
server:
port: 10000
spring:
application:
name: member-service-provider-10000 #配置应用的名称,这里可以根据需求自定义,这就设置为和子项目的名字保持一致
datasource:
type: com.alibaba.druid.pool.DruidDataSource #因为在pom.xml文件中我们已经引入了druid-starter,就不要用默认的了,
#,所以我们这里就指定数据源的类型为DruidDataSource
#导入了druid-starter但是如果没有进行配置,使用的数据源的类型为?
#答:是默认的HikariDataSource数据源
17 关于 MyBatis 和 MyBatis Plus 以及特定代码片段 SFunction<Furn, Object> sf = Furn::getName; lambdaQueryWrapper.like(sf, search); 的概念和区别的整理
当然可以。以下是关于 MyBatis 和 MyBatis Plus 以及特定代码片段 SFunction<Furn, Object> sf = Furn::getName; lambdaQueryWrapper.like(sf, search); 的概念和区别的整理:
MyBatis vs MyBatis Plus
MyBatis
-
基本概念: MyBatis 是一个基于 Java 的持久层框架,使用 XML 或注解来配置和映射原生信息,将对象与数据库中的记录关联起来。
-
映射方式: 通常使用 XML 文件或注解来定义 SQL 语句和结果映射。例如,通过
<mapper>XML 文件中的<resultMap>来实现 Java 对象属性和数据库表字段之间的映射。 -
操作方式: 编写 SQL 语句进行数据操作,需要手动编写大量的 SQL 代码和映射配置。
MyBatis Plus
-
基本概念: MyBatis Plus 是 MyBatis 的一个增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而设计。
-
映射方式: 支持使用注解如
@TableName和@TableField来定义实体类与数据库表及字段之间的映射关系。如果遵循默认命名策略(如驼峰命名转换为下划线命名),甚至可以省略这些注解。 -
操作方式: 提供了大量的 CRUD 方法,支持 Lambda 表达式和链式调用,大大减少了重复的 SQL 代码和映射配置的需要。
LambdaQueryWrapper 与 SFunction
-
LambdaQueryWrapper: 是 MyBatis Plus 中用于构建 Lambda 表达式查询的类。它允许开发者使用 Java 8 的 Lambda 表达式来构建类型安全的查询条件,而无需直接编写数据库字段字符串,减少了错误的可能性。
-
SFunction: 在
SFunction<Furn, Object> sf = Furn::getName;中,SFunction是 MyBatis Plus 中的一个函数式接口,用于在LambdaQueryWrapper中引用实体类的属性。Furn::getName是一个方法引用,它被 MyBatis Plus 解析为对应的数据库字段名。 -
混淆点: 在传统 MyBatis 中,不存在类似
LambdaQueryWrapper或SFunction的概念。这些都是 MyBatis Plus 特有的功能,目的是为了提高代码的类型安全性和减少编写 SQL 字符串的错误。 -
代码示例解释:
-
在 MyBatis Plus 中使用
lambdaQueryWrapper.like(sf, search);其中sf通过Furn::getName引用,这意味着创建一个条件,使得Furn表中的name字段应当模糊匹配search参数。这种方式依赖于 MyBatis Plus 的自动映射,不需要在 XML 文件中定义映射关系。
-
希望这个整理能帮助你更清楚地理解 MyBatis 和 MyBatis Plus 之间的区别,以及特定的 Lambda 表达式在 MyBatis Plus 中如何使用。
18 动态sql语句,关于 #{} 的使用场景
是的,这里的 #{age} 是用来取得方法的形参 findMonsterByAge(@Param("age") Integer age) 上传入的值。在这种情况下,使用 @Param("age") 注解,age 就成为了 MyBatis SQL 映射文件中可用的一个参数名。这意味着当 findMonsterByAge 方法被调用时,传给该方法的实参将被 MyBatis 用来替换 SQL 语句中的 #{age} 占位符。
关于 #{} 的使用场景:
#{} 在 MyBatis 中用于预编译 SQL 语句中的参数,这有几个重要的使用场景和好处:
-
防止 SQL 注入:通过使用
#{},MyBatis 为每个参数生成一个预处理语句(PreparedStatement),这意味着参数值是绑定的而不是直接拼接到 SQL 语句中的,这可以有效防止 SQL 注入攻击。 -
类型匹配:MyBatis 根据参数的 Java 类型自动匹配数据库中对应的类型,确保数据的类型安全。
-
简化 SQL 编写:使用
#{}可以让 SQL 映射文件更加简洁,因为你不需要手动拼接字符串来构造 SQL 语句。 -
支持复杂类型:
#{}不仅可以引用简单类型的参数,还可以引用 Java Beans 或 Map 类型参数的属性。例如,如果你有一个名为user的 JavaBean 参数,那么你可以在 SQL 中使用#{user.name}来引用它的name属性。 -
动态 SQL:在使用 MyBatis 动态 SQL 功能时(如
<if>、<choose>、<foreach>等),#{}参数占位符用于在满足特定条件时动态插入参数值。
示例:
如果你有一个 Monster 类的实例 monster 并希望在 MyBatis 映射文件中引用它的属性,你的方法签名应该像这样:
public Monster findMonsterByName(Monster monster);
在这种情况下,因为你没有使用 @Param 注解,整个 Monster 对象作为一个单一的参数传递给方法。在 MyBatis 的 XML 映射文件中,你可以直接使用 #{属性名} 来访问 Monster 实例的属性。例如,如果 Monster 类有一个名为 name 的属性,你可以在 SQL 映射中这样使用它:
<!-- 假设传入的参数是一个 Monster 对象 -->
<select id="findMonsterByName" resultType="Monster">
SELECT * FROM `monster` WHERE name = #{name}
</select>
这里,#{name} 会被 MyBatis 替换为方法参数 monster 实例的 name 属性的值。当你调用 findMonsterByName(monster) 方法时,你提供的 Monster 实例中的 name 属性将用于查询。
注意,这种用法是基于假设方法参数是一个含有相应属性(例如,name)的 Monster 对象。如果 Monster 对象确实有这样的属性,那么 MyBatis 将能够正确解析和使用它。
如果调用的方法如下:
public Monster findMonsterByName(@Param("monster") Monster monster);
那么你需要在 SQL 中这样引用它的属性:
<select id="findMonsterByName" resultType="Monster">
SELECT * FROM `monster` WHERE name = #{monster.name}
</select>
在这里,#{monster.name} 引用的是传给 findMonsterByName 方法的 monster 对象的 name 属性。
19 在 MyBatis 中,使用 #{xxx} 参数的传递和在 SQL 映射文件中的引用可以根据参数的类型和上下文有不同的表现。
在 MyBatis 中,参数的传递和在 SQL 映射文件中的引用可以根据参数的类型和上下文有不同的表现。这里我们分类总结,并提供示例及解释:
1. 传入单一的简单类型或包装类型参数:
举例: Java 方法:
public List<Monster> findMonsterByAge(@Param("age") Integer age);
MyBatis 映射文件:
<select id="findMonsterByAge" resultType="Monster">
SELECT * FROM monster WHERE age = #{age}
</select>
解释: 这里 age 是一个简单类型的包装类 Integer。在 SQL 映射文件中,你使用 #{age} 来直接取值。使用 @Param("age") 注解是为了在 SQL 映射文件中清晰地引用方法参数,尤其是当只有一个参数且为简单类型时。
2. 传入 POJO(Plain Old Java Object)类型:
举例: Java 方法:
public List<Monster> findMonsterByDetails(Monster monster);
MyBatis 映射文件:
<select id="findMonsterByDetails" resultType="Monster">
SELECT * FROM monster
<where>
<if test="name != null and name != ''">
AND name = #{name}
</if>
<if test="age != null and age >= 0">
AND age = #{age}
</if>
</where>
</select>
解释: 在这里,monster 是一个对象,但在 MyBatis 的 <if> 测试表达式中,你直接使用属性名(如 name, age),因为 MyBatis 通过反射自动匹配对象的属性。在 SQL 中,你同样使用 #{name} 和 #{age} 来取值。
3. 传入 Map 类型:
举例: Java 方法:
public List<Monster> findMonsterByMap(@Param("params") Map<String, Object> params);
MyBatis 映射文件:
<select id="findMonsterByMap" resultType="Monster">
SELECT * FROM monster
<where>
<if test="params.name != null and params.name != ''">
AND name = #{params.name}
</if>
<if test="params.age != null and params.age >= 0">
AND age = #{params.age}
</if>
</where>
</select>
解释: 当使用 Map 作为参数传递时,你需要在 <if> 测试表达式中使用 params.key 的形式来引用 Map 中的元素,这里的 params 是 Map 参数的注解名称,而 key 是 Map 中的键。在 SQL 中,使用 #{params.key} 来取值。
4. 传入 List 类型(通常结合 <foreach> 标签使用):
举例: Java 方法:
public List<Monster> findMonsterByIds(@Param("idList") List<Integer> idList);
MyBatis 映射文件:
<select id="findMonsterByIds" resultType="Monster">
SELECT * FROM monster WHERE id IN
<foreach item="id" collection="idList" open="(" separator="," close=")">
#{id}
</foreach>
</select>
解释: 当传入一个 List 类型的参数时,在 SQL 映射文件中通常结合 <foreach> 标签来遍历每一个元素。在这里,idList 是传入的 List 类型的参数名称,id 是在 <foreach> 中迭代时使用的单个元素的别名,在 SQL 中,使用 #{id} 来取值。
总结:MyBatis 提供了灵活的参数传递方式,确保在动态 SQL 中正确引用参数对提高代码的可读性和维护性非常关键。在 <if> 测试表达式中直接使用属性或键名称来建立条件,而在 SQL 取值时使用 #{} 来引用具体的值或属性。
20 在 MyBatis 的动态生成Sql语句, <foreach> 标签中,collection 属性的含义会根据传入参数的类型而改变
1. 如果传入的值是 List 类型:
当你直接传入一个 List 类型的参数(不是封装在 Map 里的),并且在 MyBatis 映射方法中没有使用 @Param 注解来命名这个 List,你通常会在 MyBatis 的配置中使用 collection="list"(或者在较新版本的 MyBatis 中,这可能不是必须的,因为它可以自动推断出来):
Java 方法示例:
public List<Monster> findMonsterByIdList(List<Integer> ids);
MyBatis 映射文件示例:
<select id="findMonsterByIdList" resultType="Monster">
SELECT * FROM monster
<where>
<if test="ids != null">
`id` IN
<foreach collection="ids" item="id" open="(" separator="," close=")">
#{id}
</foreach>
</if>
</where>
</select>
在这个例子中,由于传入的参数是 List 类型,所以在 <foreach> 中直接使用 collection="ids" 来遍历这个 List。这里的 "ids" 对应的是方法参数的名称(如果你用的是 MyBatis 3.0 以上版本,在单参数传递时不需要 @Param 注解也可以直接使用参数名)。
2. 如果传入的值是 Map 类型:
当你传入一个 Map 类型的参数时,collection 应该是这个 Map 中的一个键名,该键对应的值是需要被遍历的集合。这时,collection 表示的确实是 Map 的某个 key 的值,这个值应该是一个 List 或 Array。
Java 方法示例:
public List<Monster> findMonsterByIdsMap(@Param("params") Map<String, Object> params);
MyBatis 映射文件示例:
<select id="findMonsterByIdsMap" parameterType="map" resultType="Monster">
SELECT * FROM monster
<where>
<if test="params.ids != null">
`id` IN
<foreach collection="params.ids" item="id" open="(" separator="," close=")">
#{id}
</foreach>
</if>
</where>
</select>
在这个例子中,collection="params.ids" 表示从 Map 参数 params 中取出键名为 "ids" 的 List 或 Array 来遍历。
总的来说,collection 的值取决于传入参数的类型和结构,它可以是直接的列表(如 List 类型参数),也可以是 Map 中的一个键(键的值为 List 或 Array)。
21 两个条件的批量删除
# 这些条件用 OR 组合在一个 DELETE 语句中,是在告诉数据库:
# “检查每一条记录,如果它符合这些条件组中的任何一个,那么删除它。
<delete id="deleteBatchRelation">
DELETE FROM `commodity_attr_attrgroup_relation` WHERE
<foreach collection="entities" item="item" separator="OR">
(`attr_id`=#{item.attrId} AND `attr_group_id`=#{item.attrGroupId})
</foreach>
</delete>
确实,之前我们讨论了在 SQL 中使用 OR 条件来组合多个条件,特别是在 DELETE 语句中,这种做法是用来指示:如果记录符合任何一个条件组合,则应该被删除。这是 SQL 语法和逻辑的标准用法,并且完全正确。
在之前的上下文中,这是在讨论 OR 的逻辑用法 —— 如果有多个条件,且你想从数据库中删除匹配任何一个条件的记录,你确实会使用 OR。
然而,回到你最初的 MyBatis <foreach> 示例中,使用 OR 的场景是特定的,我们讨论的是批量删除多个特定条件的情况。在这种场景下:
-
如果你有多个特定的关系对,每对
attr_id和attr_group_id都标识一个独立的关系,你想删除满足任何一对条件的记录,则使用OR是正确的。 -
但是,这种用法在实际的数据库操作中比较少见,因为通常当我们说“批量删除”,意思往往是指定一个条件列表(如 IDs 列表),然后删除所有匹配这个列表中任一 ID 的记录,这通常通过
IN操作符实现。
所以,如果你的意图是删除所有符合列表中任一特定 attr_id 和 attr_group_id 对的记录,那么,在 <foreach> 中使用 OR 条件是正确的:
<delete id="deleteBatchRelation">
DELETE FROM `commodity_attr_attrgroup_relation` WHERE
<foreach collection="entities" item="item" separator="OR">
(`attr_id`=#{item.attrId} AND `attr_group_id`=#{item.attrGroupId})
</foreach>
</delete>
在这种情况下,确实,每个条件之间用 OR 分隔表示“删除数据库中任何匹配这些条件组中任一组合的记录”。
我向你道歉如果之前的解释导致了任何混淆。希望这次解释能够更清晰地说明何时以及如何使用 OR 条件。如果有任何进一步的问题或疑问,请继续提问。
普通的批量删除一个条件的情况下使用IN 更多一些对吗?但是我这里需要满足两个条件,并且只要包含这些条件中的任何一组就将其删除
对,你完全正确。在普通的批量删除操作中,尤其是当只有一个条件(如一组 ID)时,使用 IN 是更常见和直观的方法。这样做可以简化 SQL 语句并提高执行效率,因为它允许数据库一次性检查并删除所有匹配给定列表中任一项的记录。
例如,如果你想删除多个特定 ID 的记录,你可能会写成这样:
<delete id="deleteByIds">
DELETE FROM `table_name` WHERE `id` IN
<foreach collection="idList" item="id" open="(" separator="," close=")">
#{id}
</foreach>
</delete>
在上述情况中,所有匹配列表中任一 ID 的记录都将被删除。
但是,根据你的需求,如果需要同时满足两个条件,并且你希望删除符合这些条件中任何一组的记录,那么你的方法是正确的。这种情况下,使用 OR 来连接每组 attr_id 和 attr_group_id 的条件是合适的,因为你希望删除所有符合任何一对条件的记录。
<delete id="deleteBatchRelation">
DELETE FROM `commodity_attr_attrgroup_relation` WHERE
<foreach collection="entities" item="item" separator="OR">
(`attr_id`=#{item.attrId} AND `attr_group_id`=#{item.attrGroupId})
</foreach>
</delete>
在这种特定情况下,使用 OR 正确地反映了你的需求——即检查每条记录是否符合列出的任何一组条件,并删除所有匹配的记录。尽管在批量删除中这种情况比较少见,但如果这符合你的业务逻辑,那么这是完全合适的。
22 mybatis默认不支持驼峰法映射,但是mybatis-plus默认是支持驼峰法映射的
MyBatis 和 MyBatis-Plus 在处理属性和数据库列映射的默认行为上有所不同,这确实影响了是否需要额外配置 resultMap。
MyBatis 的默认行为
-
非自动映射:MyBatis 默认并不自动进行驼峰命名(camelCase)到下划线(underscore)的转换。如果数据库的列名是下划线风格,而Java实体属性是驼峰风格,开发者通常需要手动配置映射关系,或者在 MyBatis 的配置文件中设置
mapUnderscoreToCamelCase为true来启用自动映射。
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
这个设置告诉 MyBatis 在执行 SQL 映射到 Java 实体时,自动把数据库中的下划线命名转换成Java实体的驼峰命名。
MyBatis-Plus 的默认行为
-
自动映射:MyBatis-Plus 默认支持驼峰到下划线的自动转换。这意味着在大多数常见场景下,你不需要手动写
resultMap来处理基本的属性映射。此外,MyBatis-Plus 提供了许多方便的功能,如自动的 CRUD 操作和更简单的查询构造,这些都是基于约定优于配置的原则。
因此,如果你在使用 MyBatis-Plus,并且你的数据模型与数据库列直接对应(遵循驼峰和下划线自动映射规则),你可能不需要频繁使用 resultMap。但如之前所述,对于复杂的SQL操作,如多表联合、非标准列映射、复杂的聚合或特定的优化需求,自定义 resultMap 仍然是有用的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号