

DataTable 转换为Tree 树状结构
一个数据库表的结构如下:
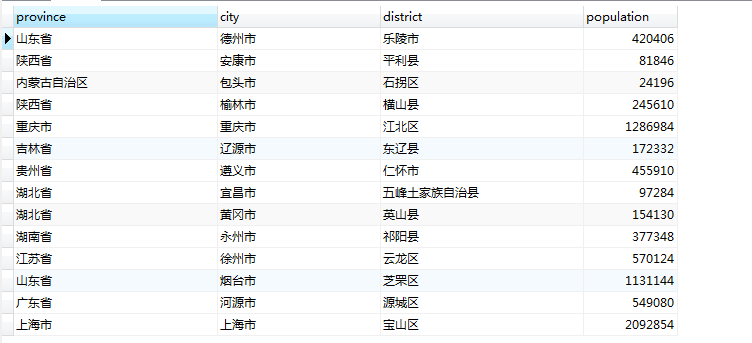
可以看到 province/city/district 这三个字段是逻辑上的主从结构,在展示的时候,有时候会以列表的形式展示,这种方式展示时
不需要做什么特殊处理,如果是以树状图展示时,则需要进行特殊处理。如下图

首先需要有一个类表示树结构。
package cn.kanyun; import java.util.List; /** * 树节点类 * @author KANYUN * */ public class TreeData { private String name; private Long value; private String path; private List<TreeData> children; public String getName() { return name; } public void setName(String name) { this.name = name; } public Long getValue() { return value; } public void setValue(Long value) { this.value = value; } public List<TreeData> getChildren() { return children; } public void setChildren(List<TreeData> children) { this.children = children; } public String getPath() { return path; } public void setPath(String path) { this.path = path; } }
有了树的节点类之后,接下来我们就需要将数据库中的表的记录查出来,然后将结果集放到该节点类对象中。
接下来查看测试类
package cn.kanyun; import cn.hutool.db.Db; import cn.hutool.db.Entity; import java.sql.SQLException; import java.util.*; import com.google.gson.Gson; public class MainTest { public static void main(String[] args) { // TODO Auto-generated method stub try { List<Entity> result = Db.use() .query("SELECT\r\n" + " province,\r\n" + " city,\r\n" + " district ,\r\n" + " SUM(population) AS population\r\n" + "FROM\r\n" + " area \r\n" + "WHERE\r\n" + " province = '河南省' or province = '浙江省'\r\n" + "GROUP BY\r\n" + " province,\r\n" + " city,\r\n" + " district "); // 构建树形的字段,必须出现在查询的SQL中,也就是说你想用哪几个字段来构造父子关系,同时也说明了,可以使用任意字段构造树形结构(是否有意义则另说) // 其add()的顺序也表示了每个字段的父子关系 List<String> dimensions = new ArrayList<String>(); dimensions.add("province"); dimensions.add("city"); dimensions.add("district"); TreeHandler treeHandler = new TreeHandler(); System.out.println("总数量:" + result.size()); List<TreeData> treeDataList = new ArrayList<>(); // root节点集合 Set<String> set = new HashSet<>(); // 所有节点集合 Set<String> paths = new HashSet<>(); // 遍历结果集 for (Entity stringObjectMap : result) { // 找到root节点的值 String key = String.valueOf(stringObjectMap.get(dimensions.get(0))); TreeData treeData = null; // 判断root节点是否被添加过 if (!set.contains(key)) { treeData = new TreeData(); treeData.setName(key); treeData.setPath(key); set.add(key); treeDataList.add(treeData); } else { // 如果当前root节点被添加过,则找过那个节点 for (TreeData node : treeDataList) { if (node.getName().equals(key)) { treeData = node; break; } } } // 待计数的字段名(也需要出现的查询SQL中) String v_key = "population"; // 处理树形结构 treeHandler.tree(paths, treeData, (Map<String, Object>) stringObjectMap, dimensions, v_key); } CountHandler countHandler = new CountHandler(); // 进行计数 countHandler.count(treeDataList); Gson gson = new Gson(); String vaString = gson.toJson(treeDataList); System.out.println(vaString); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
测试类中,除了数据库查询操作外(数据库查询使用了HuTool工具库),还有两个比较重要的类 TreeHandler/CountHandler
其中TreeHandler主要用来处理树形结构
package cn.kanyun; import java.util.ArrayList; import java.util.Collection; import java.util.HashSet; import java.util.List; import java.util.Map; import java.util.Set; import cn.hutool.db.sql.Condition; /** * 树形处理类 * @author KANYUN * */ public class TreeHandler { /** * 构造树的方法 * @param paths * @param treeData * @param rowData * @param dimensions * @param v_key */ public void tree(Set<String> paths, TreeData treeData, Map<String, Object> rowData, List<String> dimensions,String v_key) { // 最低等级 String lowLevel = dimensions.get(dimensions.size()-1); // 记录当前的path,path的作用是用来判断层级 String currentPath = ""; for (String dimension : dimensions) { String cellData = String.valueOf(rowData.get(dimension)); currentPath += cellData; if (paths.contains(currentPath)) { // 如果当前path包含在paths集合中,说明该path已经加入了树对象中,则继续循环 currentPath += "/"; continue; } System.out.println(currentPath); paths.add(currentPath); if (!dimension.equals(lowLevel)) { // 如果当前key不是最低等级,则执行addChildNode方法 addChildNode(treeData, cellData, currentPath); } else { // 如果当前key是最低等级,则执行addNode()方法 int measureValue = 0; try { measureValue = Integer.parseInt(String.valueOf(rowData.get(v_key))); }catch(Exception e) { System.out.println("============"); System.out.println(rowData); System.out.println(rowData.get(v_key)); throw e; } addNode(treeData, cellData, currentPath, measureValue); } currentPath += "/"; } } /** * @return void * @Description 添加叶子节点,即最低级的节点 * @Date 18:16 2020/8/31 * @Param [treeData, cellData, beforeName, measureValue] **/ private void addNode(TreeData treeData, String cellData, String currentPath, long measureValue) { if ((treeData.getPath() + "/" + cellData).equals(currentPath)) { // 还是先判断路径是否一致,一致说明待插入节点是当前节点的子节点 TreeData data = new TreeData(); data.setName(cellData); data.setValue(measureValue); data.setPath(currentPath); if (treeData.getChildren() == null) { List<TreeData> treeDataList = new ArrayList<>(); treeData.setChildren(treeDataList); } treeData.getChildren().add(data); } else { if (treeData.getChildren() == null) { // 判断当前节点是否为空,为空设置其value,然后直接返回 treeData.setValue(measureValue); return; } for (TreeData child : treeData.getChildren()) { // 继续递归 addNode(child, cellData, currentPath, measureValue); } } } /** * @return boolean * @Description 添加节点,递归调用 * @Date 10:42 2020/8/31 * @Param [treeData, name] **/ public void addChildNode(TreeData treeData, String cellData, String currentPath) { if (treeData.getPath().equals(currentPath)) { // 如果当前的节点路径,和传递过来的节点路径一致,则直接返回 return; } if ((treeData.getPath() + "/" + cellData).equals(currentPath)) { // 判断(当前的节点路径 + "/" + cellData) 与传递过来的带插入的路径是否一致,如果一致,说明待插入的节点是当前节点的子节点 // 构建待插入的节点对象 TreeData data = new TreeData(); data.setName(cellData); data.setPath(currentPath); if (treeData.getChildren() == null) { // 判断当前节点是否存在子节点list,存在则直接插入,不存在则先构造子节点list List<TreeData> treeDataList = new ArrayList<>(); treeData.setChildren(treeDataList); } treeData.getChildren().add(data); } // 走到这里说明没有发现能插入的节点 if (treeData.getChildren() != null) { for (TreeData tree : treeData.getChildren()) { // 继续遍历递归 addChildNode(tree, cellData, currentPath); } } } }
需要注意的是测试类中的每一行结果集,都会调用TreeHandler中的tree()方法,在tree()方法中,会遍历该结果集中的每一个字段。
先判断该字段的值是否被添加到了树状结构中,如果没有则继续添加,如果已经添加过,则进行下一个字段。需要注意的是如果判断一个节点是否是
另外一个节点的子节点。
这里使用的是TreeData类中的 path字段。通过组装path字段,来判断父子关系

如图,该行数据包含三个字段,也就是三个节点。
其中父节点的path 为 “山东省”
中间节点解的path 为 “山东省/德州市”
叶子节点的 path 为“山东省/德州市/乐陵市”
由于每次遍历时,就已经知道了当前节点 的path 和 value ,因此判断待插入节点是否与当前节点是父子关系是,就可以判断当前节点的
path + "/" + 待插入节点的 value 是否与 待插入节点的path一致,如果一致说明当前节点是待插入节点的父节点,如果不是则继续递归判断。
该类的主要方法为addNode()/addChildNode()方法。
其中CountHandler用来计数
package cn.kanyun; import java.util.List; /** * 计数处理类 * @author KANYUN * */ public class CountHandler { /** * 外部调用该方法 * @param treeDataList root节点下的数组 */ public void count(List<TreeData> treeDataList) { for (TreeData treeData : treeDataList) { if (treeData.getValue() == null) { groupCount(treeData); // 当上面方法执行完成,就说明当前节点下的所有子节点都已经有值了,因此直接将该节点进行计数 calc(treeData); } } } /** * 分组计数(递归方法) * @param treeData */ public void groupCount(TreeData treeData) { // 如果当前节点的value为空 if (treeData.getValue() == null) { // 则判断是否可以为该节点进行计数(其主要依据是看该节点的子节点的value是否都有值) if (!isCount(treeData)) { // 如果该节点不能被计数,则遍历该节点的所有子节点,进行递归 List<TreeData> treeDataList = treeData.getChildren(); if (treeDataList == null) return ; for (TreeData data : treeDataList) { // 递归方法 groupCount(data); } } else { // 如果该节点可以计数,则进行计数 calc(treeData); } } } /** * 统计计数,当isCount()方法返回true时执行 * @param treeNode */ public void calc(TreeData treeNode) { long i = 0; List<TreeData> treeDataList = treeNode.getChildren(); if (treeDataList == null) return ; for (TreeData treeData : treeDataList) { i += treeData.getValue(); } treeNode.setValue(i); } /** * 判断是否可以进行计数操作 * @param treeNode * @return */ public boolean isCount(TreeData treeNode) { List<TreeData> treeDataList = treeNode.getChildren(); if (treeDataList == null) return false; // 如果该方法的入参对象,其所有子节点的value都不为空,说明可以为当前入参对象进行计数了 for (TreeData treeData : treeDataList) { if (treeData.getValue() == null) { return false; } } return true; } }
从第一张图上我们看出,该表最后一个字段表示的是人口数,那么我们组装完tree之后,非叶子节点的 value将为空,因为我们取到的value都是叶子节点的value。

即我们现在知道“山东省/德州市/乐陵市”的人口数是420406 但是“山东省/德州市”的人口数是不知道的 “山东省”的也是不知道的,因此我们需要统计非叶子节点的值
在这里需要认清楚叶子节点是有值的,因此需要不断递归的给父节点算值。
具体步骤是。先判断一个节点是否有值,有值自然不需要管了,如果没有值,则遍历其所有子节点是否有值,如果所有子节点都有值,则可以为当前节点计算值,如果
当前节点的所有节点不全都有值,则继续递归当前节点的子节点,直至所有子节点都有值

