前端SEO处理
TDK设置
title
-
基础描述
-
内容分隔符一般有
-,_和空格-
_对百度比较友好 -
-对谷歌比较友好 -
空格英文站点可以使用,中文较少使用
-
-
内容长度上,一般pc端大概30个中文,移动端大概20个,超过则会截断为省略号
-
-
参考格式
-
首页:网站名称 或者 网站名称_提供服务介绍or产品介绍
-
频道页:频道名称_网站名称
-
文章页:文章title_频道名称_网站名称
-
-
示例代码
<title>SEO优化实战 - 腾讯Web前端</title>
description
-
基础描述
-
不影响网页权重值,只用做搜索结果摘要的一个选择目标
-
长度pc端大概为78个中文,移动端为50个,超过则会截断为省略号
-
-
示例代码
<meta name="description" content="Web前端 腾讯IMWeb 团队社区">
keywords
-
基础描述
- 因为以前被seo人员过度使用,所以现在对这个进行优化对搜索引擎是没用的。
-
示例代码
<meta name="keywords" content="前端,javascript,html,css, lego.imweb.io">
网站内容
结构布局
-
控制首页链接数,控制在100个以内
-
扁平化网站结构,三层目录结构
- 从首页跳转,最多两次跳转就能够到达任意页面
-
应用面包屑导航
页面编码
-
标签使用
-
<img>设置alt说明 -
<a>设置title链接描述 -
用H1~H5标签做内容标题
-
用
<em>,<strong>突出强调,表达重要内容 -
使用
<table>时,用<caption>定义表格标题 -
使用html5语义化标签(
header,footer,section,aside,nav,article) -
尽少使用
<iframe> -
不乱用
<br>
-
-
编码注意
-
每个页面都设置唯一h1标题
-
重要内容不要用JS输出
-
重要的HTML内容代码放在最前面
-
谨慎使用
display:none,爬虫会过滤掉这一部分 -
对不需要跟踪爬行的链接,
<a>标签设置nofollow -
精简代码,切记用过于复杂的代码
-
robots
robots文件
-
robots.txt放在站点根目录
-
搜索引擎蜘蛛访问网站时,会第一个访问robots.txt文件
-
用于指导搜索引擎蜘蛛,禁止抓取网站某些内容或只允许抓取哪些内容
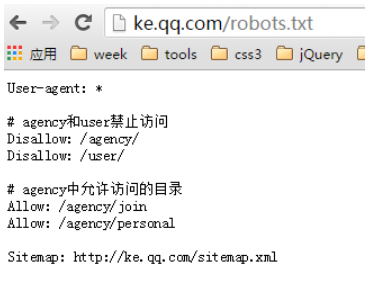
robots规则
-
#表示注释 -
User-agent 表示以下规则适用哪个蜘蛛,*表示所有
-
Disallow 表示禁止抓取的文件或目录,必须每个一行,分开写
-
Allow 表示允许抓取的文件或目录,必须每个一行,分开写
-
Sitemap 表示站点XML地图,注意S大写
示例代码
// 禁止所有搜索引擎蜘蛛抓取任何内容
User-agent: *
Disallow: /
// 允许所有搜索引擎蜘蛛抓取任何内容
User-agent: *
Disallow:
参考案例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号