从官方文档中探索MySQL分页的几种方式及分页优化
概览
相比于Oracle,SQL Server 等数据库,MySQL分页的方式简单得多了,官方自带了分页语法 limit 语句:
select * from test_t LIMIT {[offset,] row_count | row_count OFFSET offset}
例如:要获取第12行到第21行的记录可以这样写:
select * from test_t limit 11,10;
或者
select * from test_t limit 10 offset 11;
当然简单的用法可以这样使用,但是如果遇到数据量比较大的情况下和分页在中间或后面部分的话,这样使用会有性能问题。等会再看一下优化后的另外一种分页方式。
从官网中探索
想着
limit语句既然是官方语言,那样官方文档中一定会有的介绍MySQL分页的方式和优化的相关的建议吧,后面我看了一下其实与想象中的有挺大差别的,官方文档不是很全面🤐
关于MySQL 分页方式的官方文档解读
先来看看官网文档中是怎么样描述 limit语句的 :
The LIMIT clause can be used to constrain the number of rows returned by the SELECT statement. LIMIT takes one or two numeric arguments, which must both be nonnegative integer constants, with these exceptions:
Within prepared statements, LIMIT parameters can be specified using ? placeholder markers.
Within stored programs, LIMIT parameters can be specified using integer-valued routine parameters or local variables.
来自:https://dev.mysql.com/doc/refman/5.6/en/limit-optimization.html
翻译成中文,大概意思就是:“limit 语句可以用到 select 语句中去限制返回结果的行数。limit 子语句可以带一个或两个参数,这些参数都必须是非负整数常量,但有以下例外:一个是预执行语句中可以用?替代,另外一个是在存储程序中用表达式替代”
简单来说,就是 limit 是用来限制查询返回行数的(这里举例的是 select 语句中limit的用法,在update 等语句中也有相关 limit 的介绍,大概类似)。
好吧,讲了等会没讲🤣
接着,在官网文档中举例了 limit 的一些简单用法示例,还有一些其他说明。
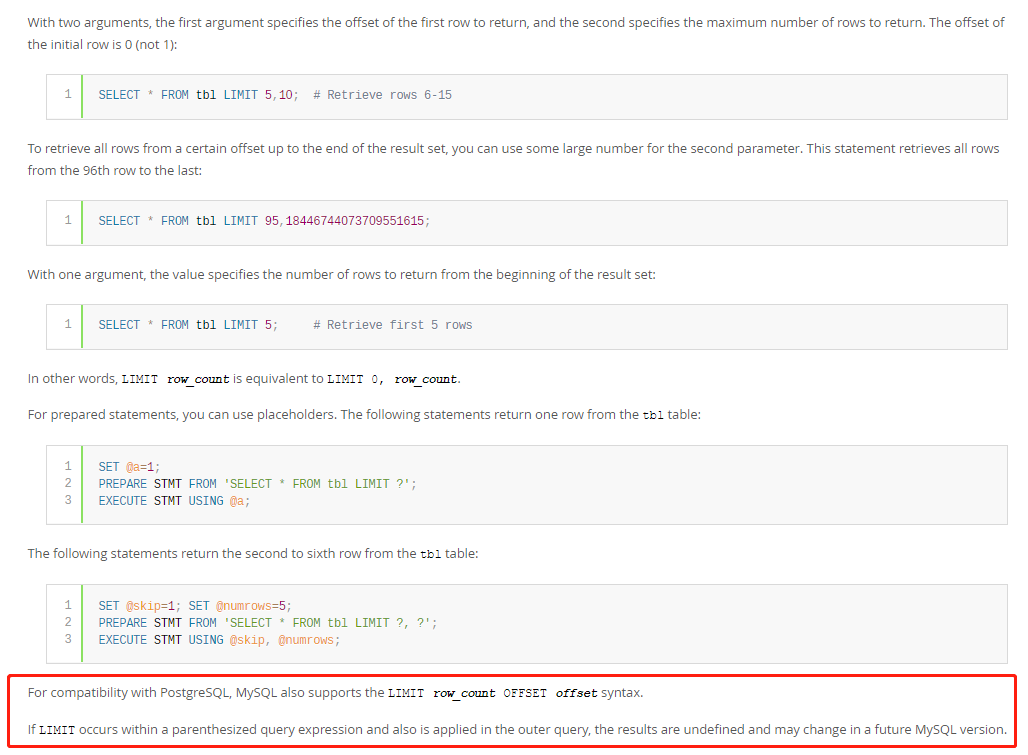
可以重点关注下后面红框部分的两句描述。
第一句为:为了兼容PostgreSQL,MySQL 也支持 limit offset 这种方式的语句
这里说的是,MySQL 分页 除了可以这样写
select * from test_t limit 11,10
也可以这样写
select * from test_t limit 10 offset 11
offset 这种方式,我之前还真没见过MySQL这样用的😂,又得到一个冷知识。
至于为什么需要兼容 PostgreSQL ,我搜了一下网上资料,估计是 当时PostgreSQL 很火,可以让用户没有什么成本就迁移到MySQL上
第二句为:如果LIMIT出现在带圆括号的查询表达式中,并且也应用在外部查询中,则查询的结果未准确定义,并且可能在将来的MySQL版本中更改。
这里说的就是,例如这样的 SQL 结果有可能以后会发生变化:
SELECT * FROM d_comment WHERE id IN (SELECT id FROM `d_app_info` ORDER BY id LIMIT 1,10) ORDER BY id LIMIT 0,10
挺怀疑它这里的描述的,这样的用法不是很正常吗?🙄会有什么影响吗?。我这里的用的是MySQL 5.6(2013年)版本的文档,于是我切换到的MySQL 5.8(2020年)的版本,发现这里的描述还是不变🙃。过了7年这里的描述还是没变,这以后都应该不会变化了吧。。。
但是当我执行上面的 SQL的时候,papa打脸了

提示这个错误:
This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
于是又去搜索了一下,发现在官方文档中就说明了,就不能这样使用
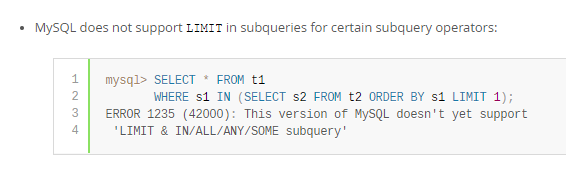
来自:https://dev.mysql.com/doc/refman/8.0/en/subquery-restrictions.html
需要改写成这样,嵌多一层子查询:
SELECT id,dt FROM d_comment WHERE id IN ( SELECT * FROM (SELECT id FROM `d_app_info` ORDER BY app_name,id LIMIT 1,10) t2 ) ORDER BY id LIMIT 0,10;
或者用多表关联查询来解决(这种方式在分页数量多的时候性能更好些)
SELECT a.id,a.dt FROM d_comment a , (SELECT id FROM `d_app_info` ORDER BY app_name,id LIMIT 1,10) b WHERE a.id=b.id ORDER BY a.id ;
然后,我与外层没有 limit 的 SQL 执行对比了一下:
SELECT id,dt FROM d_comment WHERE id IN ( SELECT * FROM (SELECT id FROM `d_app_info` ORDER BY app_name,id LIMIT 1,10) t2 ) ORDER BY id ;
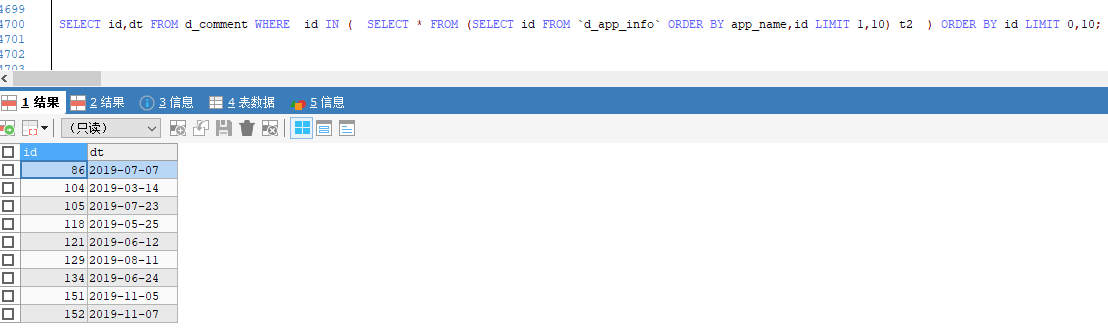
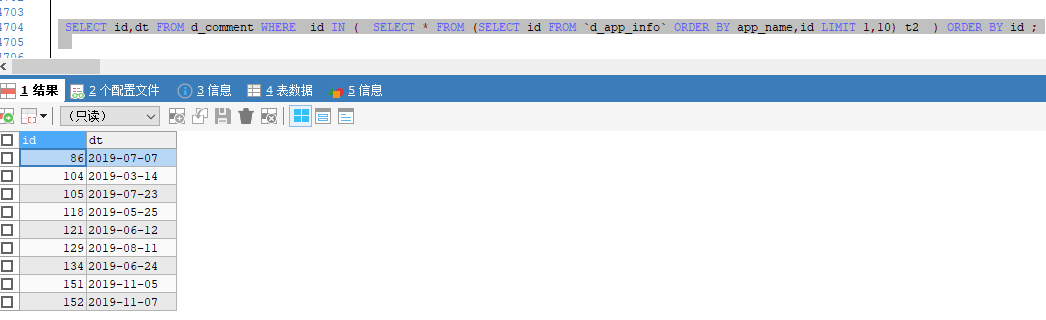
结果是一样的,与预想的一样,这里的应该是不需要管了🙃,除了注意一下要嵌套多一层
关于MySQL limit 优化相关的官方文档解读
想着官方文档上也会有分页相关优化的介绍,于是在官方文档的搜索栏输入 limit 或 page 上搜索了一下,发现与 limit 优化相关的只有以下这个:
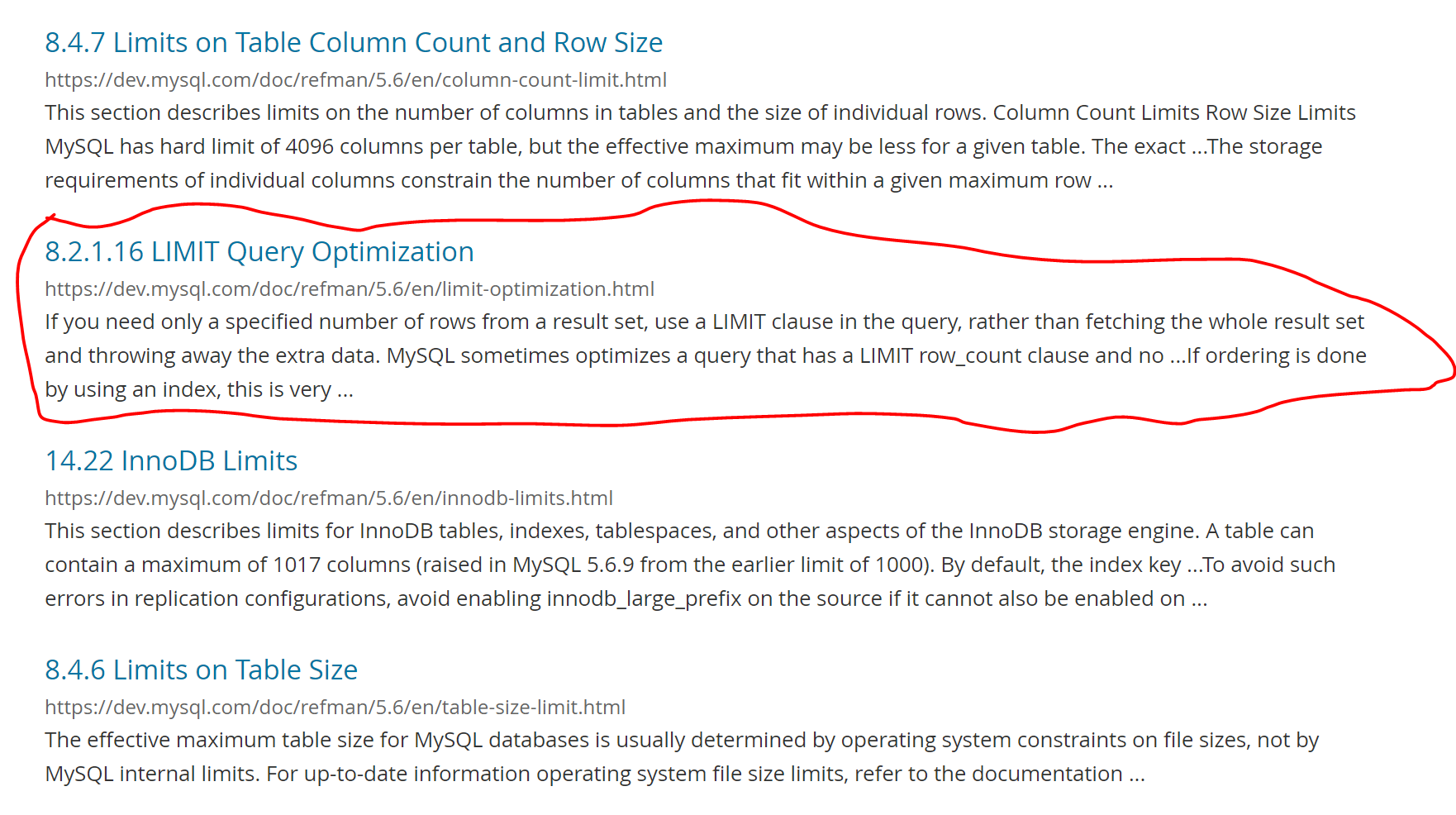
LIMIT Query Optimization
If you need only a specified number of rows from a result set, use a LIMIT clause in the query, rather than fetching the whole result set and throwing away the extra data.
MySQL sometimes optimizes a query that has a LIMIT row_count clause and no HAVING clause:
引用自:https://dev.mysql.com/doc/refman/5.6/en/limit-optimization.html
官方文档,这部分主要介绍的在包含limit row_count 这种语句的各种类型查询的情况下,MySQL会做了哪些优化。其中大部分是用不到的,这里重点介绍一下2种比较有趣的特点。
一,查询总行数的另一种方法
查询分页的总行数,我们一般情况下是使用的, select count(*) 去实现的。文档中介绍了另外一种方式,通过 select FOUND_ROWS(); 语句,不过这种方式的需要修改获取limit 数据的SQL 。例如:如果在SQL中同时执行这两条语句,就可以分别获取到分页的数据和分页总行数。
# 这个SQL 比平时的分页SQL 多了 SQL_CALC_FOUND_ROWS 修饰
SELECT SQL_CALC_FOUND_ROWS id,`name` FROM `d_common_all_select_info` ORDER BY `name` LIMIT 0,10;
# 这条SQL返回的为总行数,不过统计方式与select count(*) 有些不同,另外需要与上面的SQL 同时执行
SELECT FOUND_ROWS();
二,查询的order by 的顺序问题
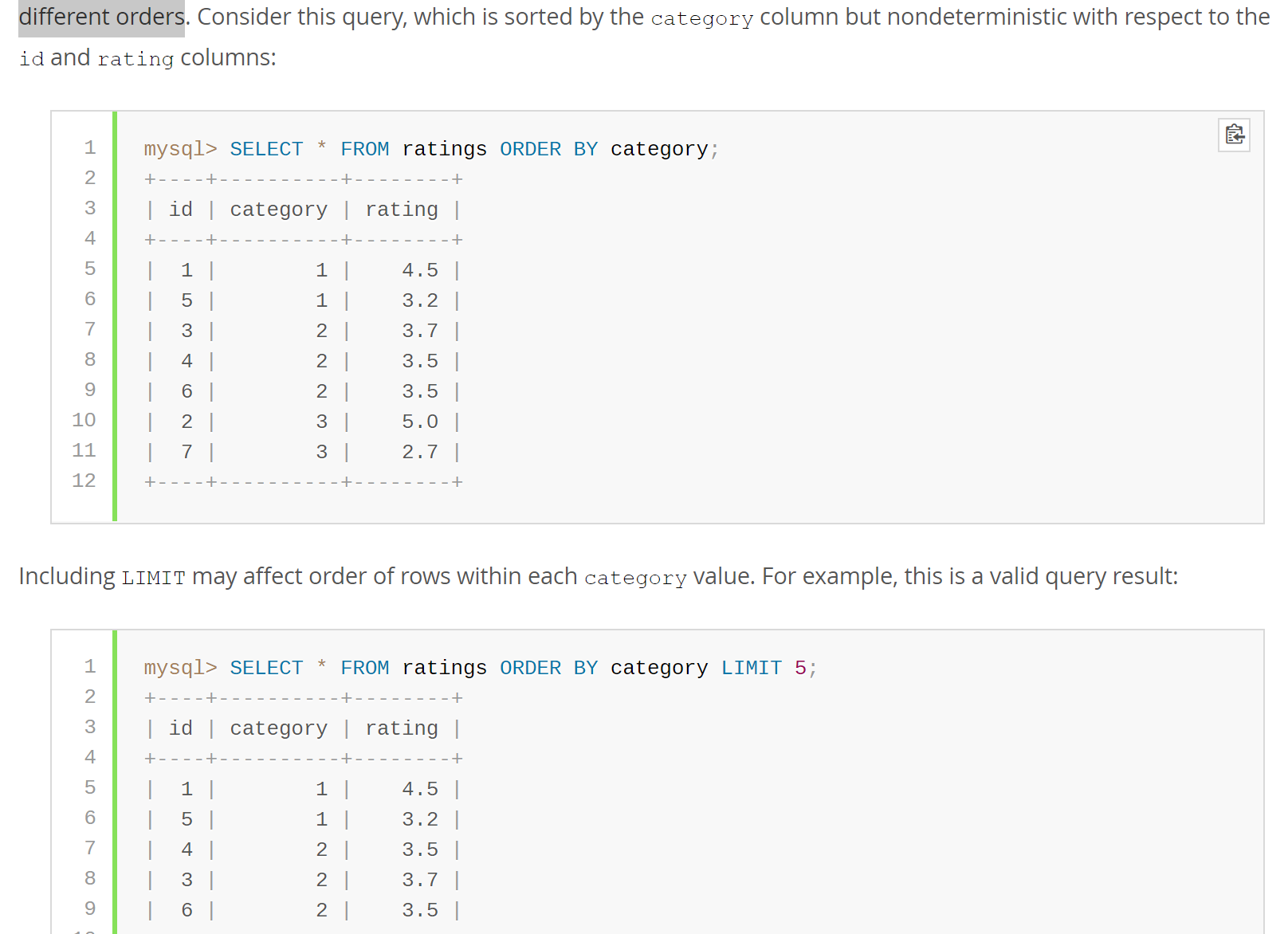
If multiple rows have identical values in the ORDER BY columns, the server is free to return those rows in any order, and may do so differently depending on the overall execution plan. In other words, the sort order of those rows is nondeterministic with respect to the nonordered columns.
One factor that affects the execution plan is LIMIT, so an ORDER BY query with and without LIMIT may return rows in different orders
翻译过来并简单来说就是,如果order by 中包含相同的值,则order by出来的结果不一定每次一样,它返回的顺序与总体执行计划有关。例如,带limit 和不带limit的order by 语句,返回顺序不一样的。
所以如果order by 的列包含相同值的时候,保证每次都是相同的结果,最好在最后的加上id列(这里假设自增id列名为id)。例如:平常要order by dt 的,然后dt中会包含相同值的最好修改为 order by dt,id
MySQL 分页优化的两种方法
经过多次在官方文档中查找,没有发现其他关于 MySQL 分页优化的描述,但是如果在表数据量大的时候,直接使用 limit offset, row_num 这种方式去查询的会很慢的。所以这里再介绍一下MySQL 分页查询的另一种方式,并与原方式进行一些对比。
普通的limit offset,row_num 方式,会先从数据文件中查到offset + row_num 记录,然后把前 offset 记录抛弃掉返回的。例如:limit 1000,10 ,会从数据文件中查询1010 行记录,只返回的10记录,前1000行记录会被抛弃掉。为了优化这种的大偏移的查询的,主要有两种方法:延迟关联 和 书签记录。其中延迟关联应用的业务场景更加广泛。
这里使用一张测试表 page_test_t 来进行测试,表的行数如下(大约110万行):
-- 查询表行数
SELECT TABLE_NAME, PARTITION_NAME, TABLE_ROWS, AVG_ROW_LENGTH, DATA_LENGTH FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME='page_test_t' ;

这里假设将 offset 设置为 600000,取 10 行记录来对比各个分页方法之间的查询速度
普通分页
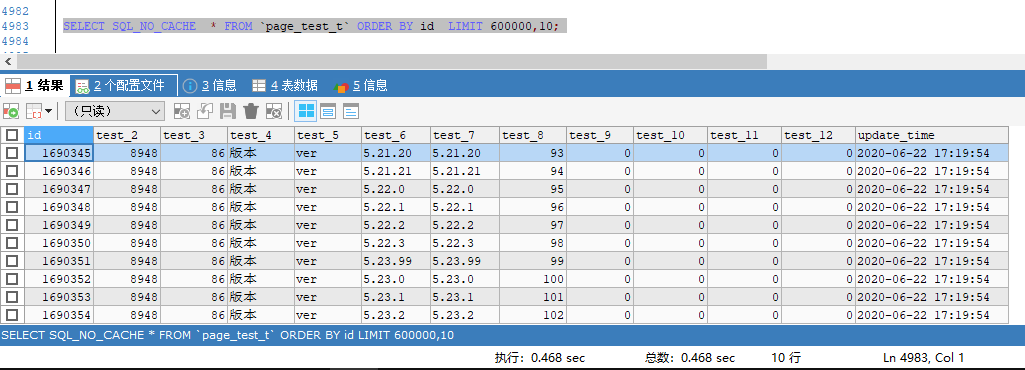
普通分页,直接使用 limit offset,row_num 去查询
SELECT SQL_NO_CACHE * FROM `d_common_all_select_info` ORDER BY id LIMIT 600000,10;
查询10次,查询结果与以下结果相差不超过0.01s,查询时间耗时稳定在 0.46 s
延迟关联
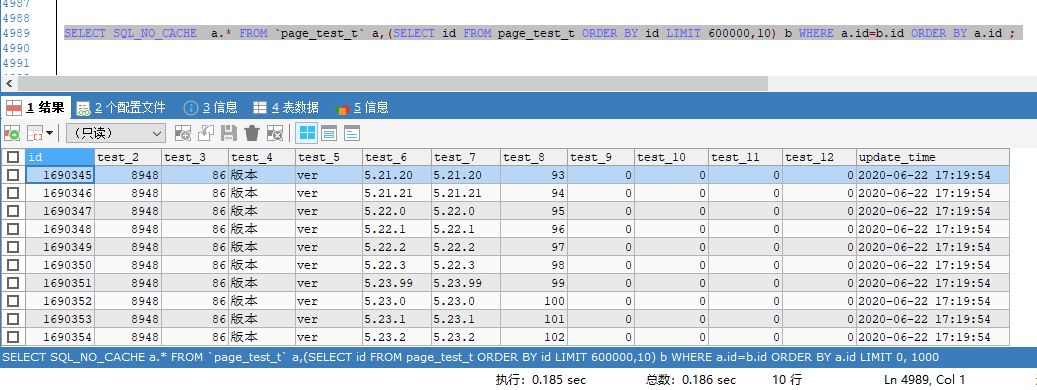
可以先按照条件分页查询出主键,然后根据主键的再去关联表,查询出所有需要列的记录数,这样可以避免扫描太多的数据页。按照要求条件,可以写出这样的例子 SQL:
SELECT SQL_NO_CACHE a.* FROM `page_test_t` a,(SELECT id FROM page_test_t ORDER BY id LIMIT 600000,10) b WHERE a.id=b.id ORDER BY a.id ;
查询10次,查询结果与以下结果相差不超过0.01s,查询时间耗时稳定在 0.18 s
书签记录
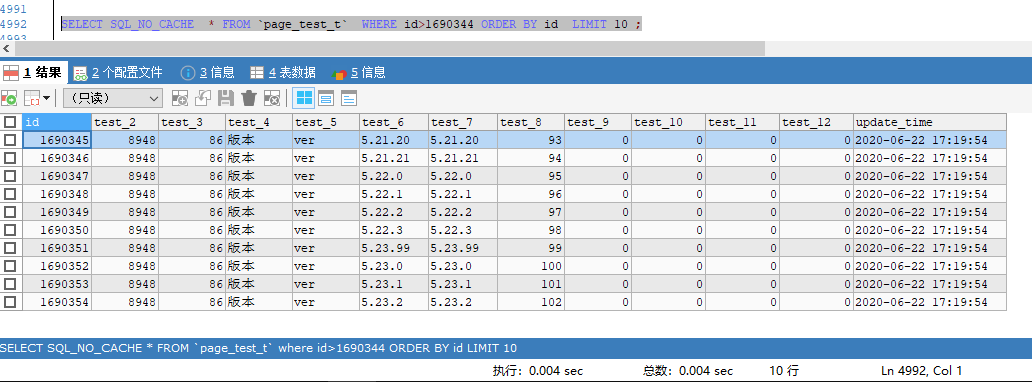
“书签记录”指我们可以用一个临时变量来存储上一次取数记录的位置,然后在获取下一页的时候,可以根据这个值,来获取大于这个值的下一页记录(上一页类似),直接从该值以后开始扫描。例如,假设我们上一次获取到了分页 limit 599990,10 的记录,最大的值的id为 1690344(这里的值作为了一个书签记录),则我们获取 limit 600000,10 的记录可以这样写:
SELECT SQL_NO_CACHE * FROM `page_test_t` where id>1690344 ORDER BY id LIMIT 10 ;
查询10次,查询结果与以下结果相差不超过0.01s,查询时间耗时稳定在 0.004 s
小结
可以看到,延迟关联 比 普通分页方式查询速度快了近3倍,“书签记录”比普通分页方式快了近100倍。不过“书签记录”只适合只有前翻页,后翻页这种类型的分页交互,不能跳转到任意页码,延迟关联则可以支持,所以一般情况下,我们都可以使用延迟关联方式来替换原普通分页的方式。
除了这两种方法,还有例如使用预先计算的汇总表 或者关联到另外一张冗余表,冗余表中包含表的主键和需要做排序的数据列 等方法去优化分页。 参考自:《高性能MySQL(第三版)》
总结
本文从SQL 的 limit 分页语句出发,详细介绍了 limit 的语法及简要的概括了MySQL 官方文档对 limit 的优化,另外对比了两种常用的分页优化方法 延迟关联 和 “书签记录”。
参考:
https://dev.mysql.com/doc/refman/5.6/en/limit-optimization.html
https://dev.mysql.com/doc/refman/5.6/en/select.html
https://www.liaoxuefeng.com/wiki/1177760294764384/1217864791925600
https://segmentfault.com/a/1190000017059239?utm_source=sf-related
MySQL中SQL_CALC_FOUND_ROWS的用法 https://www.cnblogs.com/chinesern/p/8260506.html



 浙公网安备 33010602011771号
浙公网安备 33010602011771号