ext4块分配机制及源码分析
对于文件系统来说,碎片问题是永恒的话题,碎片少的文件系统不仅能够存储更多的数据而且能够带来显著的性能提升,为此ext4文件系统从inode分配到块分配都做了相当多的努力。本文主要是结合源码分析ext4文件系统的块分配机制,所采用的源码版本是4.20。
ext4文件系统采用多种分配方式相结合的方式解决碎片问题,此外还需要考虑到分配效率、大文件小文件、超大文件、分配后的读写效率等问题,其机制不可谓不复杂,限于当前的水平难免有叙述错误和未叙述到的地方,欢迎一起交流。
块分配机制
预分配
给文件预留空间,当需要分配的时候从预留的空间里面分配能够降低碎片数量。ext4文件系统考虑到大文件和小文件的不同需求,对于大文件,ext4采用per inode的方式给每个文件预留分配空间;对于小文件,ext4的策略是尽量让这些文件都集中存储在一起,采用的方式per_cpu locality group的方式。至于什么是per_inode,什么是per_cpu locality group就留到具体的章节详说吧。
mballoc多块分配
相比于ext2文件系统的块分配器一次性只能分配一个数据块,效率低下;ext4采用了多块分配机制,一次性能够分配多块的空间,效率非常高的同时碎片也会相当的少。ext4的开发人员参考了linux内核内存管理的buddy算法来实现多块分配,如果读者熟悉内存管理的buddy算法的话,理解起来会快很多。
延迟分配
缓存IO的写命令会先将数据写入页缓存中,然后立即返回,待到某个特定的时候再将缓存中的数据回写到磁盘上。ext4利用此机制,在数据写到页缓存中的时候不做磁盘空间的分配,当写IO持续累积在统一回写到磁盘上的时候再统一地进行分配磁盘空间,一次性大的磁盘空间分配所产生的碎片肯定比多次小IO产生的碎片少,再结合mballoc多块分配一次性分配多块物理磁盘空间能够继续减少碎片。
但是延迟分配有一个缺点,那就是在回写时会进行磁盘空间的分配,这会一定程度上影响刷盘的效率,而且会导致部分IO的延时会突然拔高一段时间,对于追求延时稳定的上层应用来说会有影响,例如数据库系统的某一次SQL执行时间突然变长等。
bigAlloc
在ext4的块组中有一个块叫做block bitmap数据块位图,用于记录块组中的块使用情况,一个ext4块一般情况下是4k,也就是32768个bit位,一个bit位代表一个4k块的使用情况,32768个bit位就能表示128M的空间的使用情况,这也是一般情况下ext4的一个块组是128M的原因。
但是随着单个磁盘空间的越来越大(TB级),如果ext4文件系统任然采用4k为一个文件块的方式来管理数据,那么相对应的位图等元数据也会增多,这方面的管理开销也会越来越大。
暴力地增大单个块的大小是个看起来简单的方法,但是由于块大小跟内核的内存管理、页缓存块缓存管理极为紧密,简单地增加文件块大小对于代码开发的工作量将是巨大的。聪明的内核开发者引入了bigalloc的策略,随之而来的是一个叫“block cluster”的概念,它是一系列4k的块的集合,当需要分配空间时以block cluster为单位进行分配而不是以4k 块为单位进行分配,与此同时,块组里面数据块位图的一个bit位也不在表示一个4k块,而是一个block cluster,当然我们的块组的大小也随之增大了(block cluster的大小在文件系统格式化的时候就决定了,因此块组的大小也就决定了)。
关于bigalloc特性,内核有一个“历史包袱”,那就是当初开发者在修改代码时并没有将内核代码的所有“blocks”都换成“cluster”,估计是为了尽快上线功能吧,因此后续我们在分析代码的时候一会儿代码是block,一会儿代码是cluster,这会让人很迷惑,需要记住的一点是看到block,其实它是cluster。
block cluster的大小一般设置为64k,如果文件系统只存储大文件,那么可以将block cluster设置为1M。假如一次性给文件分配了1M的空间,而文件并没有用完这片空间,那么下次在文件要分配的时候会将这部分未用完的空间也利用上就不分配了。值得注意的是,如果设置了过大的block cluster,而文件系统又存储了很多的小文件,那么会浪费很多的空间。
持久预分配
有的上层应用需要在文件开始写入数据之前就准备好足够的空间,例如下载软件会先创建同等大小的文件然后将下载的数据写入到文件等,ext4文件系统提供了持久预分配接口,能够一次性就给文件分配好所有的空间,效率更高,碎片更少。
其他策略
除了上述的几大分配策略以外,ext4还有很多的小策略以及分配inode的策略也会影响文件系统的性能:
1)在文件刚刚创建的时候ext4文件系统会为其分配8k的空间,然后在文件close的时候回收未用完的空间,以应对创建文件立马写入的场景以及临时小文件场景。
2)尽量将文件数据和文件的inode放在同一个块组中,以减少磁盘寻址耗时(机械硬盘)。
3) 如果启用了flexible块组特性,当4个以上的块组组成一个flexible块组的时候,将flexible块组内的第一个块组的inode分配给目录而不是普通文件。
4)ext4尽量将文件inode与它的目录inode放在同一个块组中,普遍认为目录下的文件是“相关的”,读取某一个文件也会同时读取其他文件。
5)ext4文件系统在分配inode的时候会将顶层的目录尽量分散开,而底层的目录尽量聚集在一起。
6)针对下层块设备是Raid的场景ext4采用与stripe对齐的方式分配,可以加速读写。你可以在创建文件系统时通过设置参数"-E stride=?, stripe=?"指定按照stripe对齐得方式分配,stride就是raid的chunk size 除以文件系统的block大小的倍数,stripe就是stride * raid的数据盘个数。对于raid5或者raid6这种来说满条带的写能够提升非常大的性能,因为raid引擎不用多次读取计算和写入校验值。至于你的raid的chunk size应该配置多大就得根据上层业务经常下发的IO大小决定,如果IO太大可以指定较小的chunk size使得数据能够分到各个磁盘上,如果经常下发的IO太小可以指定较大一点的chunk size,最好有benchmark可以测试这些参数带来的影响,选择最合适的参数。
7)ext4最终还可以用e4defrag工具整理碎片文件。
源码分析
代码流程主要是梳理预分配和多块分配的公共流程和数据结构,而bigalloc、延迟分配以及各种小策略会穿插在其中,持久预分配单独分析。
我们的流程从ext4_ext_map_blocks()函数开始,这个函数的作用是将一段连续的逻辑块号映射到连续的物理块号,在开始梳理流程之前我们需要了解一个结构体:ext4_map_blocks。
/*
文件系统将磁盘空间划分为4k的块(通常是4k),每一个4k的块有一个物理块号,物理块号从0开始,由于当前存放文件系统的磁盘空间可能是个分区,因此在通用块层根据下发的物理块号计算真正在磁盘上的sector(通常是512B)时要加上分区的sector偏移。
逻辑块号是相对于文件而言的,对于上层应用来说文件的内容是连续的,而实际的存储物理块号可能不连续,这个4k的块相对于文件起始位置的块号就是逻辑块号。
*/
/*
ext4_map_blocks用来描述逻辑块号和物理块号的映射关系
*/
struct ext4_map_blocks {
ext4_fsblk_t m_pblk; // 物理块号,相对于文件系统而言的
ext4_lblk_t m_lblk; // 逻辑块号,相对于文件的
unsigned int m_len; // 长度,单位为文件块
unsigned int m_flags; // 映射关系的各种标记,参考EXT4_MAP_NEW附近的宏定义
};
ext4_ext_map_blocks()函数:
/* 我们首先来看参数:
handle_t *handle: 是ext4文件系统的日志系统,此处用于保护分配时的元数据的修改
struct inode *inode: 要分配的文件的inode
struct ext4_map_blocks *map: 映射关系,找到了逻辑块号的物理块号就填入其中
int flags: 调用方对于此次分配行动的“要求”,参考EXT4_GET_BLOCKS_CREATE附件的宏定义
其次是返回值:
返回此次映射的长度,这个值可能会小于调用方要求的长度(ext4_map_blocks里的m_len),调用方需要处理这种情况
*/
int ext4_ext_map_blocks(handle_t *handle, struct inode *inode,
struct ext4_map_blocks *map, int flags)
{
struct ext4_ext_path *path = NULL;
struct ext4_extent newex, *ex, *ex2;
struct ext4_sb_info *sbi = EXT4_SB(inode->i_sb);
ext4_fsblk_t newblock = 0;
int free_on_err = 0, err = 0, depth, ret;
unsigned int allocated = 0, offset = 0;
unsigned int allocated_clusters = 0;
struct ext4_allocation_request ar;
ext4_lblk_t cluster_offset;
bool map_from_cluster = false;
ext_debug("blocks %u/%u requested for inode %lu\n",
map->m_lblk, map->m_len, inode->i_ino);
trace_ext4_ext_map_blocks_enter(inode, map->m_lblk, map->m_len, flags);
/*
ext4_ext_map_blocks()函数实在太长了,我们将其分为两个部分分析,此处为第一部分,主要是从ext4的extent树中采用二分法的方式寻找有无已经映射了的extent,查找期间如果某个extent树节点没有加载到页缓存中,则会发起读IO从磁盘读取并加载到页缓存中,并且加载的extent(包括空洞)会记录到ext4_inode_info的struct ext4_es_tree i_es_tree红黑树中方便查询。
*/
/*
此处涉及到很多的ext4文件系统extent树的知识,这里的分析从简。
*/
/* find extent for this block */
// path表示的是从extent树的根节点到extent所经过的所有extent_idx路径
path = ext4_find_extent(inode, map->m_lblk, NULL, 0);
if (IS_ERR(path)) {
err = PTR_ERR(path);
path = NULL;
goto out2;
}
depth = ext_depth(inode);
/*
* consistent leaf must not be empty;
* this situation is possible, though, _during_ tree modification;
* this is why assert can't be put in ext4_find_extent()
*/
if (unlikely(path[depth].p_ext == NULL && depth != 0)) {
EXT4_ERROR_INODE(inode, "bad extent address "
"lblock: %lu, depth: %d pblock %lld",
(unsigned long) map->m_lblk, depth,
path[depth].p_block);
err = -EFSCORRUPTED;
goto out2;
}
ex = path[depth].p_ext;
if (ex) { // 如果找到了extent,证明已经映射了
ext4_lblk_t ee_block = le32_to_cpu(ex->ee_block); // 起始逻辑块
ext4_fsblk_t ee_start = ext4_ext_pblock(ex); // 起始物理块
unsigned short ee_len;
/*
* unwritten extents are treated as holes, except that
* we split out initialized portions during a write.
*/
// 如果一个extent是初始化了的则ee_len <= 32768,
// 如果一个extent是没有初始化的则ee_len > 32768,且真实长度为ee_len - 32768
// 因此初始化了的最大长度为32768,未初始化的最大长度为INVALID_U16(65535)- 32768 = 32767
ee_len = ext4_ext_get_actual_len(ex);
trace_ext4_ext_show_extent(inode, ee_block, ee_start, ee_len);
/* if found extent covers block, simply return it */
if (in_range(map->m_lblk, ee_block, ee_len)) {
newblock = map->m_lblk - ee_block + ee_start;
/* number of remaining blocks in the extent */
allocated = ee_len - (map->m_lblk - ee_block); // 分配的长度可能小于要求分配的长度
ext_debug("%u fit into %u:%d -> %llu\n", map->m_lblk,
ee_block, ee_len, newblock);
/*
* If the extent is initialized check whether the
* caller wants to convert it to unwritten.
*/
// 调用者想要清零
if ((!ext4_ext_is_unwritten(ex)) &&
(flags & EXT4_GET_BLOCKS_CONVERT_UNWRITTEN)) {
allocated = convert_initialized_extent(
handle, inode, map, &path,
allocated);
goto out2;
} else if (!ext4_ext_is_unwritten(ex))
goto out;
ret = ext4_ext_handle_unwritten_extents(
handle, inode, map, &path, flags,
allocated, newblock);
if (ret < 0)
err = ret;
else
allocated = ret;
goto out2;
}
}
/*
到这里就说明传入的逻辑块范围没有映射物理块,
如果调用者不需要我们分配实际的空间此处就返回了,可能的情况有两种:
1、ext4的延迟分配就是这样的,写IO流程里面不需要分配空间,回刷的时候才分配空间。
2、可能这段空间是文件空洞,不需要分配物理块,只需要内存中有记录即可
*/
if ((flags & EXT4_GET_BLOCKS_CREATE) == 0) {
ext4_lblk_t hole_start, hole_len;
hole_start = map->m_lblk;
hole_len = ext4_ext_determine_hole(inode, path, &hole_start);
/*
记录这个空洞到ext4_inode_info的struct ext4_es_tree i_es_tree红黑树中
*/
ext4_ext_put_gap_in_cache(inode, hole_start, hole_len);
/* Update hole_len to reflect hole size after map->m_lblk */
if (hole_start != map->m_lblk)
hole_len -= map->m_lblk - hole_start;
map->m_pblk = 0;
map->m_len = min_t(unsigned int, map->m_len, hole_len);
goto out2;
}
......
}
下面开始梳理ext4_ext_map_blocks()函数的后半段,也就是分配物理块,不过首先我们需要了解一些结构体以及一些宏:
1)struct ext4_extent
/*
ext4_extent是extent树的叶子节点,用于在物理磁盘上描述逻辑块号和物理块号的映射关系。
*/
struct ext4_extent {
__le32 ee_block; /* extent包含的第一个逻辑块 */
__le16 ee_len; /* extent包含的数据块的个数 */
__le16 ee_start_hi; /* 物理数据块的高16位 */
__le32 ee_start_lo; /* 物理数据块的低32位 */
};
2)struct ext4_allocation_request
/*
ext4_allocation_request表示的是一次分配的具体请求。
ext4_lblk_t是logic block的意思,代表逻辑块号
ext4_fsblk_t是物理块号
*/
struct ext4_allocation_request { // 块分配请求
/* 要分配物理块的文件inode */
struct inode *inode;
/* 要分配的长度 */
unsigned int len;
/* 要分配物理块号的逻辑块号 */
ext4_lblk_t logical;
/* the closest logical allocated block to the left */
ext4_lblk_t lleft;
/* the closest logical allocated block to the right */
ext4_lblk_t lright;
/* phys. target (a hint) */
// 目标物理块号,分配器会首先看看在某些“相邻”的物理位置能不能分配,这些相邻的物理位置相当程度地保证数据局部性,具体可参考ext4_ext_find_goal()函数
ext4_fsblk_t goal;
/* phys. block for the closest logical allocated block to the left */
ext4_fsblk_t pleft;
/* phys. block for the closest logical allocated block to the right */
ext4_fsblk_t pright;
/* flags. see above EXT4_MB_HINT_* */
unsigned int flags;
};
3)EXT4_LBLK_COFF
/*
s是ext4_sb_info,字段s_cluster_ratio表示的是一个block cluster的block数目,它的值是2的幂,因此这个宏表示的是lblk在cluster里面的偏移。
*/
#define EXT4_LBLK_COFF(s, lblk) ((lblk) & \
((ext4_lblk_t) (s)->s_cluster_ratio - 1))
开始分配:
int ext4_ext_map_blocks(handle_t *handle, struct inode *inode,
struct ext4_map_blocks *map, int flags)
{
......
// 开始分配物理块
/*
* Okay, we need to do block allocation.
*/
newex.ee_block = cpu_to_le32(map->m_lblk); // 起始逻辑块
cluster_offset = EXT4_LBLK_COFF(sbi, map->m_lblk); // 起始逻辑块在cluster内的偏移
/*
* If we are doing bigalloc, check to see if the extent returned
* by ext4_find_extent() implies a cluster we can use.
*/
// bigalloc上一次分配的cluster可能还没有用完,剩余的空间可以用于这一次的分配
// 值得注意的时候如果本次的起始位置在cluster内的偏移是0,那么证明这一次是新分配一个cluster,因此也就没有必要检查了
// ext4_extent ex可以理解为离这一次分配逻辑块段左边最近的逻辑块段
// 此时cluster、extent、request region之间的重叠关系就决定了能否使用前面分配的cluster未使用的区域
if (cluster_offset && ex &&
// 检查重叠关系
get_implied_cluster_alloc(inode->i_sb, map, ex, path)) {
ar.len = allocated = map->m_len;
newblock = map->m_pblk;
map_from_cluster = true;
goto got_allocated_blocks;
}
/* find neighbour allocated blocks */
// 如果没法利用左边的extent分配的cluster未使用完的区域,则搜索右边有无可用区域
// 设想当前要分配的这段逻辑块段是在一个空洞内,那么它的前后逻辑块都是被分配了的extent
// 往ext4_allocation_request里记录要分配的起始逻辑块地址
ar.lleft = map->m_lblk;
// 首先记录左边的extent的逻辑块和物理块地址,在预估后续的文件大小时使用
err = ext4_ext_search_left(inode, path, &ar.lleft, &ar.pleft);
if (err)
goto out2;
ar.lright = map->m_lblk;
ex2 = NULL;
// 搜索右边的extent,找到离分配段最近的extent,存到ex2中
err = ext4_ext_search_right(inode, path, &ar.lright, &ar.pright, &ex2);
if (err)
goto out2;
/* Check if the extent after searching to the right implies a
* cluster we can use. */
// 如果右边有extent则可以看看有没有未使用的cluster的区域,有则将这段区域分配出去
if ((sbi->s_cluster_ratio > 1) && ex2 &&
get_implied_cluster_alloc(inode->i_sb, map, ex2, path)) {
ar.len = allocated = map->m_len;
newblock = map->m_pblk;
map_from_cluster = true;
goto got_allocated_blocks;
}
/*
如果要分配的长度大于最大值,将分配长度对齐到最大值
*/
if (map->m_len > EXT_INIT_MAX_LEN &&
!(flags & EXT4_GET_BLOCKS_UNWRIT_EXT))
map->m_len = EXT_INIT_MAX_LEN;
else if (map->m_len > EXT_UNWRITTEN_MAX_LEN &&
(flags & EXT4_GET_BLOCKS_UNWRIT_EXT))
map->m_len = EXT_UNWRITTEN_MAX_LEN;
/* Check if we can really insert (m_lblk)::(m_lblk + m_len) extent */
newex.ee_len = cpu_to_le16(map->m_len);
// 检查分配的区域跟右边的extent是否有重叠,有则缩短分配的长度
err = ext4_ext_check_overlap(sbi, inode, &newex, path);
if (err)
// err表示有重叠,那么用新的调整了的分配长度
allocated = ext4_ext_get_actual_len(&newex);
else
// 否则使用调用者传入的长度
allocated = map->m_len;
/* 分配一个新的物理块段 */
ar.inode = inode;
// 先找到目标区域,开始分配的时候先检查能否从目标区域分配物理块
ar.goal = ext4_ext_find_goal(inode, path, map->m_lblk);
ar.logical = map->m_lblk;
/*
* We calculate the offset from the beginning of the cluster
* for the logical block number, since when we allocate a
* physical cluster, the physical block should start at the
* same offset from the beginning of the cluster. This is
* needed so that future calls to get_implied_cluster_alloc()
* work correctly.
*/
offset = EXT4_LBLK_COFF(sbi, map->m_lblk); // 起始逻辑块在cluster内的偏移
ar.len = EXT4_NUM_B2C(sbi, offset+allocated); // 把要分配的长度换算成cluster数量
// 有可能因为偏移的原因占用多个cluster
// 将goal和logical都对齐到cluster,方便分配
ar.goal -= offset;
ar.logical -= offset;
// 如果inode是普通文件,则置上EXT4_MB_HINT_DATA标记
if (S_ISREG(inode->i_mode))
ar.flags = EXT4_MB_HINT_DATA;
else
/* disable in-core preallocation for non-regular files */
ar.flags = 0;
// 将调用者的“要求”一一转换到ext4_allocation_request中
if (flags & EXT4_GET_BLOCKS_NO_NORMALIZE)
ar.flags |= EXT4_MB_HINT_NOPREALLOC;
if (flags & EXT4_GET_BLOCKS_DELALLOC_RESERVE)
ar.flags |= EXT4_MB_DELALLOC_RESERVED;
if (flags & EXT4_GET_BLOCKS_METADATA_NOFAIL)
ar.flags |= EXT4_MB_USE_RESERVED;
newblock = ext4_mb_new_blocks(handle, &ar, &err); // 核心分配函数!
if (!newblock)
goto out2;
ext_debug("allocate new block: goal %llu, found %llu/%u\n",
ar.goal, newblock, allocated);
free_on_err = 1;
allocated_clusters = ar.len;
ar.len = EXT4_C2B(sbi, ar.len) - offset; // 分配到的cluster还原到要分配的长度
if (ar.len > allocated)
ar.len = allocated;
......
}
get_implied_cluster_alloc()函数:
cluster、extent、request region之间的重叠关系决定了此次分配的具体长度,能够走到这个函数的证明request region的起始逻辑地址是不在extent的逻辑地址范围内的。
static int get_implied_cluster_alloc(struct super_block *sb,
struct ext4_map_blocks *map,
struct ext4_extent *ex,
struct ext4_ext_path *path)
{
struct ext4_sb_info *sbi = EXT4_SB(sb);
ext4_lblk_t c_offset = EXT4_LBLK_COFF(sbi, map->m_lblk);
ext4_lblk_t ex_cluster_start, ex_cluster_end;
ext4_lblk_t rr_cluster_start;
ext4_lblk_t ee_block = le32_to_cpu(ex->ee_block);
ext4_fsblk_t ee_start = ext4_ext_pblock(ex);
unsigned short ee_len = ext4_ext_get_actual_len(ex);
/* The extent passed in that we are trying to match */
ex_cluster_start = EXT4_B2C(sbi, ee_block); // extent起始逻辑地址所在的cluster
ex_cluster_end = EXT4_B2C(sbi, ee_block + ee_len - 1); // extent结束逻辑地址所在的cluster
/* The requested region passed into ext4_map_blocks() */
// request region的起始逻辑地址所在的cluster
rr_cluster_start = EXT4_B2C(sbi, map->m_lblk);
// 当起始cluster或者结束cluster重合时才有可能分配
if ((rr_cluster_start == ex_cluster_end) ||
(rr_cluster_start == ex_cluster_start)) {
/*
第一种情况,”|==|“表示分配的长度以及起始物理块:
* |--- cluster # N--|
* |--- extent ---| |---- requested region ---|
* |==|
*/
if (rr_cluster_start == ex_cluster_end)
ee_start += ee_len - 1;
// EXT4_PBLK_CMASK表示的是ee_start所在的cluster的起始的物理地址
// c_offset表示的是requested region的起始逻辑地址在cluster内的偏移量
map->m_pblk = EXT4_PBLK_CMASK(sbi, ee_start) + c_offset;
map->m_len = min(map->m_len,
(unsigned) sbi->s_cluster_ratio - c_offset);
/*
* 第二种情况:
细分之下有两种情况,这也是第51行代码取最小值的原因:
* |--------- cluster # N ----------------|
* |--- requested region --| |------- extent ----|
* |=======================|
*
* |--------- cluster # N-------------|
* |------- extent ----|
* |--- requested region ---|
* |=======|
*/
if (map->m_lblk < ee_block)
map->m_len = min(map->m_len, ee_block - map->m_lblk);
/*
* 第三种情况,此时要考虑到右边的extent的分配情况,其实这里没有画出来,细分之下也类似第二种情况有两种,因此第63行也有个取最小值的动作:
*
* |------------- cluster # N-------------|
* |----- ex -----| |---- ex_right ----|
* |------ requested region ------|
* |================|
*/
if (map->m_lblk > ee_block) {
ext4_lblk_t next = ext4_ext_next_allocated_block(path);
map->m_len = min(map->m_len, next - map->m_lblk);
}
trace_ext4_get_implied_cluster_alloc_exit(sb, map, 1);
return 1;
}
trace_ext4_get_implied_cluster_alloc_exit(sb, map, 0);
return 0;
}
以上是bigalloc的情况下从前面已经分配了的cluster未用完的区域分配的情况,接下来分析分配新物理块的流程:
这个流程主要有两个函数:ext4_ext_find_goal()函数和ext4_mb_new_blocks()函数,
// 返回的是一个物理块号,分配的时候检查从这个物理块号起始分配是否可行
static ext4_fsblk_t ext4_ext_find_goal(struct inode *inode,
struct ext4_ext_path *path,
ext4_lblk_t block)
{
if (path) {
int depth = path->p_depth;
struct ext4_extent *ex;
ex = path[depth].p_ext; // path的终点是数据extent,即ext4_extent
// path是从根节点到叶子节点的路径
if (ex) {
ext4_fsblk_t ext_pblk = ext4_ext_pblock(ex);
ext4_lblk_t ext_block = le32_to_cpu(ex->ee_block);
/*
举两个例子:
|---request region---| |---extent---|
|-> goal
或者
|---extent---| |---request region---|
|-> goal
*/
if (block > ext_block) // 寻找与其最近的空闲物理块,左边或者右边
return ext_pblk + (block - ext_block);
else
return ext_pblk - (ext_block - block);
}
/* it looks like index is empty;
* try to find starting block from index itself */
if (path[depth].p_bh) // index节点为空
return path[depth].p_bh->b_blocknr; // 最后一个extent block对应的物理块号
}
/* OK. use inode's group */
return ext4_inode_to_goal_block(inode); // inode刚刚创建时,没有path
}
ext4_inode_to_goal_block()函数:
ext4_fsblk_t ext4_inode_to_goal_block(struct inode *inode)
{
struct ext4_inode_info *ei = EXT4_I(inode);
ext4_group_t block_group;
ext4_grpblk_t colour;
int flex_size = ext4_flex_bg_size(EXT4_SB(inode->i_sb));
ext4_fsblk_t bg_start;
ext4_fsblk_t last_block;
// 找到inode所在的block group
block_group = ei->i_block_group;
// EXT4_FLEX_SIZE_DIR_ALLOC_SCHEME的值为4
// 如果ext4启用了flexible group特性,并且每个flexible group的block group数量大于等于4
// 则将第一个block group用于目录和特殊文件,以加速目录的访问和fsck的时间
if (flex_size >= EXT4_FLEX_SIZE_DIR_ALLOC_SCHEME) {
/*
* If there are at least EXT4_FLEX_SIZE_DIR_ALLOC_SCHEME
* block groups per flexgroup, reserve the first block
* group for directories and special files. Regular
* files will start at the second block group. This
* tends to speed up directory access and improves
* fsck times.
*/
// 此时的block_group为flexible group的第一个block group的编号
block_group &= ~(flex_size-1);
// 如果文件是普通文件,则将block group号加一
if (S_ISREG(inode->i_mode))
block_group++;
}
// bg_start为block group的第一个块的块号(物理块号)
bg_start = ext4_group_first_block_no(inode->i_sb, block_group);
last_block = ext4_blocks_count(EXT4_SB(inode->i_sb)->s_es) - 1;
/*
* If we are doing delayed allocation, we don't need take
* colour into account.
*/
if (test_opt(inode->i_sb, DELALLOC))
return bg_start;
// 计算一个随机值color,最终goal会在flexible group的随机的一个block group上
// 当flex_group的block数量大于4时goal才确定不会在其第一个block group上
if (bg_start + EXT4_BLOCKS_PER_GROUP(inode->i_sb) <= last_block)
colour = (current->pid % 16) *
(EXT4_BLOCKS_PER_GROUP(inode->i_sb) / 16);
else
colour = (current->pid % 16) * ((last_block - bg_start) / 16);
return bg_start + colour;
}
正式第分配物理块,首先会调用ext4_mb_use_preallocated()函数从预分配空间里分配物理块,如果分配失败则调用ext4_mb_regular_allocator()函数进行常规的分配。
首先来看分配过程种的两个结构体:
struct ext4_free_extent结构体:
// 表示分配的请求和结果
struct ext4_free_extent {
ext4_lblk_t fe_logical; // 要分配的起始逻辑块号
ext4_grpblk_t fe_start; // 分配的起始
ext4_group_t fe_group; // 从哪个block group分配的
ext4_grpblk_t fe_len; // 分配的长度,单位为cluster
};
struct ext4_allocation_context结构体:
// 对分配行为本身的描述,记录分配的中间过程数据以及分配的结果
struct ext4_allocation_context {
struct inode *ac_inode; // 要分配的inode
struct super_block *ac_sb; // inode的super_block
/* original request */
struct ext4_free_extent ac_o_ex; // 最开始的分配请求
/* goal request (normalized ac_o_ex) */
struct ext4_free_extent ac_g_ex; // 如果goal能分配成功
/* the best found extent */
struct ext4_free_extent ac_b_ex; // 最终的分配结果
/* copy of the best found extent taken before preallocation efforts */
struct ext4_free_extent ac_f_ex; // ac_b_ex的一份拷贝
// 分配过程种的相关信息
__u16 ac_groups_scanned;
__u16 ac_found;
__u16 ac_tail;
__u16 ac_buddy;
__u16 ac_flags; /* allocation hints */
__u8 ac_status;
__u8 ac_criteria;
__u8 ac_2order; /* if request is to allocate 2^N blocks and
* N > 0, the field stores N, otherwise 0 */
__u8 ac_op; /* operation, for history only */
// 跟mballoc相关的bit位信息
struct page *ac_bitmap_page;
struct page *ac_buddy_page;
// 预分配相关信息
struct ext4_prealloc_space *ac_pa;
struct ext4_locality_group *ac_lg;
};
ext4_mb_new_blocks()函数:
ext4_fsblk_t ext4_mb_new_blocks(handle_t *handle,
struct ext4_allocation_request *ar, int *errp)
{
int freed;
struct ext4_allocation_context *ac = NULL;
struct ext4_sb_info *sbi;
struct super_block *sb;
ext4_fsblk_t block = 0;
unsigned int inquota = 0;
unsigned int reserv_clstrs = 0;
might_sleep();
sb = ar->inode->i_sb;
sbi = EXT4_SB(sb);
trace_ext4_request_blocks(ar);
/*
......
前面一段是检查是否有足够的空间分配这么多,并且检查quota是否有足够的余额
......
*/
// 从事先预留好的内存里分配一个ext4_allocation_context
ac = kmem_cache_zalloc(ext4_ac_cachep, GFP_NOFS);
if (!ac) {
ar->len = 0;
*errp = -ENOMEM;
goto out;
}
*errp = ext4_mb_initialize_context(ac, ar); // 初始化allocation_context
if (*errp) {
ar->len = 0;
goto out;
}
ac->ac_op = EXT4_MB_HISTORY_PREALLOC;
// 非文件不用预分配
if (!ext4_mb_use_preallocated(ac)) { // 预分配失败
ac->ac_op = EXT4_MB_HISTORY_ALLOC;
ext4_mb_normalize_request(ac, ar); // 对文件大小进行预估,预估后的大小比原来大一些
repeat:
// 常规分配
*errp = ext4_mb_regular_allocator(ac);
if (*errp)
goto discard_and_exit;
/* as we've just preallocated more space than
* user requested originally, we store allocated
* space in a special descriptor */
if (ac->ac_status == AC_STATUS_FOUND &&
ac->ac_o_ex.fe_len < ac->ac_b_ex.fe_len)
*errp = ext4_mb_new_preallocation(ac); // 将分配的多余的空间放到预分配空间里
if (*errp) {
discard_and_exit:
ext4_discard_allocated_blocks(ac);
goto errout;
}
}
if (likely(ac->ac_status == AC_STATUS_FOUND)) {
*errp = ext4_mb_mark_diskspace_used(ac, handle, reserv_clstrs);
if (*errp) {
ext4_discard_allocated_blocks(ac);
goto errout;
} else {
block = ext4_grp_offs_to_block(sb, &ac->ac_b_ex);
ar->len = ac->ac_b_ex.fe_len;
}
} else {
freed = ext4_mb_discard_preallocations(sb, ac->ac_o_ex.fe_len);
if (freed)
goto repeat;
*errp = -ENOSPC;
}
/*
......
分配失败的处理
*/
return block;
}
ext4_mb_initialize_context()函数初始化ext4_allocation_context。
static noinline_for_stack int
ext4_mb_initialize_context(struct ext4_allocation_context *ac,
struct ext4_allocation_request *ar)
{
struct super_block *sb = ar->inode->i_sb;
struct ext4_sb_info *sbi = EXT4_SB(sb);
struct ext4_super_block *es = sbi->s_es;
ext4_group_t group;
unsigned int len;
ext4_fsblk_t goal;
ext4_grpblk_t block;
/* we can't allocate > group size */
len = ar->len; // len就是要申请的cluster的数量
/* just a dirty hack to filter too big requests */
// 分配的cluster数量超过了一个block group的cluster数量,减小之
if (len >= EXT4_CLUSTERS_PER_GROUP(sb))
len = EXT4_CLUSTERS_PER_GROUP(sb);
/* start searching from the goal */
goal = ar->goal;
if (goal < le32_to_cpu(es->s_first_data_block) ||
goal >= ext4_blocks_count(es))
goal = le32_to_cpu(es->s_first_data_block);
// group为goal的block group的编号
// block为在group中的cluster的偏移(块组中的第几个cluster)
ext4_get_group_no_and_offset(sb, goal, &group, &block);
/* set up allocation goals */
ac->ac_b_ex.fe_logical = EXT4_LBLK_CMASK(sbi, ar->logical); // 逻辑块号
ac->ac_status = AC_STATUS_CONTINUE; // 分配的结果状态
ac->ac_sb = sb;
ac->ac_inode = ar->inode;
// 初始化ac_o_ex,表示原始的分配请求,初始化为goal的值,表示最开始想从goal分配
ac->ac_o_ex.fe_logical = ac->ac_b_ex.fe_logical;
ac->ac_o_ex.fe_group = group;
ac->ac_o_ex.fe_start = block;
ac->ac_o_ex.fe_len = len; // len就是要分配的cluster的数量
ac->ac_g_ex = ac->ac_o_ex; // ac_g_ex被赋值成ac_o_ex
ac->ac_flags = ar->flags;
// 这个函数在预分配一节里分析
ext4_mb_group_or_file(ac);
mb_debug(1, "init ac: %u blocks @ %u, goal %u, flags %x, 2^%d, "
"left: %u/%u, right %u/%u to %swritable\n",
(unsigned) ar->len, (unsigned) ar->logical,
(unsigned) ar->goal, ac->ac_flags, ac->ac_2order,
(unsigned) ar->lleft, (unsigned) ar->pleft,
(unsigned) ar->lright, (unsigned) ar->pright,
atomic_read(&ar->inode->i_writecount) ? "" : "non-");
return 0;
}
预分配
ext4对于大文件采用的是per inode预留分配空间的方式分配,对于小文件采用的是per_cpu locality group的方式,那么怎么定义文件是大文件还是小文件呢?在sys文件系统的“/sys/fs/ext4/
ext4在ext4_mb_group_or_file()函数决定是使用per inode预分配还是per_cpu locality group预分配,此时函数被ext4_mb_initialize_context()函数调用。
static void ext4_mb_group_or_file(struct ext4_allocation_context *ac)
{
struct ext4_sb_info *sbi = EXT4_SB(ac->ac_sb);
int bsbits = ac->ac_sb->s_blocksize_bits;
loff_t size, isize;
if (!(ac->ac_flags & EXT4_MB_HINT_DATA))
return;
if (unlikely(ac->ac_flags & EXT4_MB_HINT_GOAL_ONLY))
return;
// 此次分配后文件的大小,单位为文件块
size = ac->ac_o_ex.fe_logical + EXT4_C2B(sbi, ac->ac_o_ex.fe_len);
// 文件当前总长度,单位为文件块
isize = (i_size_read(ac->ac_inode) + ac->ac_sb->s_blocksize - 1)
>> bsbits;
if ((size == isize) &&
!ext4_fs_is_busy(sbi) &&
(atomic_read(&ac->ac_inode->i_writecount) == 0)) {
ac->ac_flags |= EXT4_MB_HINT_NOPREALLOC;
return;
}
// s_mb_group_prealloc未设置
if (sbi->s_mb_group_prealloc <= 0) {
ac->ac_flags |= EXT4_MB_STREAM_ALLOC;
return;
}
/* don't use group allocation for large files */
size = max(size, isize);
if (size > sbi->s_mb_stream_request) { // s_mb_stream_request默认是16个文件块
ac->ac_flags |= EXT4_MB_STREAM_ALLOC;
return;
}
// 小文件采用per_cpu locality group方式分配
BUG_ON(ac->ac_lg != NULL);
/*
* locality group prealloc space are per cpu. The reason for having
* per cpu locality group is to reduce the contention between block
* request from multiple CPUs.
*/
// 从ext4_sb_info里获取当前CPU的ext4_locality_group
ac->ac_lg = raw_cpu_ptr(sbi->s_locality_groups);
/* we're going to use group allocation */
ac->ac_flags |= EXT4_MB_HINT_GROUP_ALLOC;
/* serialize all allocations in the group */
mutex_lock(&ac->ac_lg->lg_mutex);
}
预分配空间struct ext4_prealloc_space结构体:
struct ext4_prealloc_space { // 预分配空间
struct list_head pa_inode_list; // 如果是per inode的预分配空间则挂在ext4_inode_info的i_prealloc_list链表; 如果是per_cpu locality group的预分配空间则挂在ext4_locality_group的lg_prealloc_list链表上
struct list_head pa_group_list; // 预分配空间同时也会挂在ext4_group_info的bb_prealloc_list链表上,用于初始化buddy bitmap的之前给block bitmap置上对应的已使用标记
union {
struct list_head pa_tmp_list;
struct rcu_head pa_rcu;
} u;
spinlock_t pa_lock;
atomic_t pa_count;
unsigned pa_deleted; // 预分配空间是否处于删除状态
ext4_fsblk_t pa_pstart; /* phys. block 起始物理地址 */
ext4_lblk_t pa_lstart; /* log. block 起始逻辑地址,相对于文件而言 */
ext4_grpblk_t pa_len; /* len of preallocated chunk, 空间长度 */
ext4_grpblk_t pa_free; /* how many blocks are free,空间的可用长度 */
unsigned short pa_type; /* pa type. inode or group */
spinlock_t *pa_obj_lock;
struct inode *pa_inode; /* hack, for history only */
};
ext4_locality_group结构体:
#define PREALLOC_TB_SIZE 10
struct ext4_locality_group {
/* for allocator */
/* to serialize allocates */
struct mutex lg_mutex;
/* list of preallocations */
// 挂ext4_prealloc_space的链表,按照预分配空间的可用长度进行分组
struct list_head lg_prealloc_list[PREALLOC_TB_SIZE];
spinlock_t lg_prealloc_lock;
};
ext4_mb_use_preallocated()函数,检查预分配空间里是否能够分配goal:
static noinline_for_stack int
ext4_mb_use_preallocated(struct ext4_allocation_context *ac)
{
struct ext4_sb_info *sbi = EXT4_SB(ac->ac_sb);
int order, i;
struct ext4_inode_info *ei = EXT4_I(ac->ac_inode);
struct ext4_locality_group *lg;
struct ext4_prealloc_space *pa, *cpa = NULL;
ext4_fsblk_t goal_block;
/* only data can be preallocated */
if (!(ac->ac_flags & EXT4_MB_HINT_DATA))
return 0;
// 先尝试per inode的预分配,遍历预分配空间链表
rcu_read_lock();
list_for_each_entry_rcu(pa, &ei->i_prealloc_list, pa_inode_list) {
/* all fields in this condition don't change,
* so we can skip locking for them */
// 不在这个预分配空间范围内,跳到下一个预分配空间
if (ac->ac_o_ex.fe_logical < pa->pa_lstart ||
ac->ac_o_ex.fe_logical >= (pa->pa_lstart +
EXT4_C2B(sbi, pa->pa_len)))
continue;
/* non-extent files can't have physical blocks past 2^32 */
// 非extent的ext4文件的最大可访问的物理块为2^32,如果
if (!(ext4_test_inode_flag(ac->ac_inode, EXT4_INODE_EXTENTS)) &&
(pa->pa_pstart + EXT4_C2B(sbi, pa->pa_len) >
EXT4_MAX_BLOCK_FILE_PHYS))
continue;
// 找到了合适的预分配空间,则分配之
spin_lock(&pa->pa_lock);
if (pa->pa_deleted == 0 && pa->pa_free) {
atomic_inc(&pa->pa_count);
// 往ext4_allocation_context记录分配的最终结果
ext4_mb_use_inode_pa(ac, pa);
spin_unlock(&pa->pa_lock);
ac->ac_criteria = 10;
rcu_read_unlock();
return 1;
}
spin_unlock(&pa->pa_lock);
}
rcu_read_unlock();
// 进行per_cpu locality group的预分配
/* can we use group allocation? */
if (!(ac->ac_flags & EXT4_MB_HINT_GROUP_ALLOC))
return 0;
/* inode may have no locality group for some reason */
lg = ac->ac_lg;
if (lg == NULL)
return 0;
// fls的意思是找到fe_len从右往左的最后一个1的位置,即为len的阶
order = fls(ac->ac_o_ex.fe_len) - 1;
if (order > PREALLOC_TB_SIZE - 1)
/* The max size of hash table is PREALLOC_TB_SIZE */
order = PREALLOC_TB_SIZE - 1;
// goal_block为goal在block group中的偏移
goal_block = ext4_grp_offs_to_block(ac->ac_sb, &ac->ac_g_ex);
/*
* search for the prealloc space that is having
* minimal distance from the goal block.
*/
for (i = order; i < PREALLOC_TB_SIZE; i++) {
rcu_read_lock();
// 遍历当前CPU的预分配空间链表
list_for_each_entry_rcu(pa, &lg->lg_prealloc_list[i],
pa_inode_list) {
spin_lock(&pa->pa_lock);
// 预分配空间没有被删除,且有足够的可用空间进行分配
if (pa->pa_deleted == 0 &&
pa->pa_free >= ac->ac_o_ex.fe_len) {
// 进一步检查,以找到最合适的
cpa = ext4_mb_check_group_pa(goal_block, pa, cpa);
}
spin_unlock(&pa->pa_lock);
}
rcu_read_unlock();
}
if (cpa) {
ext4_mb_use_group_pa(ac, cpa);
ac->ac_criteria = 20;
return 1;
}
return 0;
}
ext4_mb_use_inode_pa()函数:
/*
per inode的预分配成功分配
*/
static void ext4_mb_use_inode_pa(struct ext4_allocation_context *ac,
struct ext4_prealloc_space *pa)
{
struct ext4_sb_info *sbi = EXT4_SB(ac->ac_sb);
ext4_fsblk_t start;
ext4_fsblk_t end;
int len;
/* found preallocated blocks, use them */
start = pa->pa_pstart + (ac->ac_o_ex.fe_logical - pa->pa_lstart);
end = min(pa->pa_pstart + EXT4_C2B(sbi, pa->pa_len),
start + EXT4_C2B(sbi, ac->ac_o_ex.fe_len));
len = EXT4_NUM_B2C(sbi, end - start);
ext4_get_group_no_and_offset(ac->ac_sb, start, &ac->ac_b_ex.fe_group,
&ac->ac_b_ex.fe_start);
ac->ac_b_ex.fe_len = len; // 将分配结果置在ac_b_ex
ac->ac_status = AC_STATUS_FOUND; // 分配结果为找到了
ac->ac_pa = pa; // 保存是从哪个预分配空间分配的
BUG_ON(start < pa->pa_pstart);
BUG_ON(end > pa->pa_pstart + EXT4_C2B(sbi, pa->pa_len));
BUG_ON(pa->pa_free < len);
pa->pa_free -= len; // 减少预分配空间的可用长度
mb_debug(1, "use %llu/%u from inode pa %p\n", start, len, pa);
}
ext4_mb_check_group_pa()函数:
/*
找到一个最合适的预分配空间,什么是“最合适的”呢?
要分配的目标物理块地址跟预分配空间的起始地址最近的预分配空间。
*/
static struct ext4_prealloc_space *
ext4_mb_check_group_pa(ext4_fsblk_t goal_block,
struct ext4_prealloc_space *pa,
struct ext4_prealloc_space *cpa)
{
ext4_fsblk_t cur_distance, new_distance;
if (cpa == NULL) {
atomic_inc(&pa->pa_count);
return pa;
}
cur_distance = abs(goal_block - cpa->pa_pstart);
new_distance = abs(goal_block - pa->pa_pstart);
// 找到一个goal离预分配空间起始地址最近的预分配空间
if (cur_distance <= new_distance)
return cpa;
/* drop the previous reference */
atomic_dec(&cpa->pa_count);
atomic_inc(&pa->pa_count);
return pa;
}
ext4_mb_use_group_pa()函数:
// 当从per_cpu locality group分配成功时
static void ext4_mb_use_group_pa(struct ext4_allocation_context *ac,
struct ext4_prealloc_space *pa)
{
unsigned int len = ac->ac_o_ex.fe_len;
ext4_get_group_no_and_offset(ac->ac_sb, pa->pa_pstart,
&ac->ac_b_ex.fe_group,
&ac->ac_b_ex.fe_start);
ac->ac_b_ex.fe_len = len;
ac->ac_status = AC_STATUS_FOUND;
ac->ac_pa = pa;
/*
对比ext4_mb_use_inode_pa()我们可以发现这里并没有着急地减少预分配空间的可用空间,一方面是因为此时是加了lg_mutex锁的,另一方面是为了防止其他流程也加载了block group而带来的竞争,最后在更新了block bitmap的时候才减少预分配空间的可用空间。
*/
mb_debug(1, "use %u/%u from group pa %p\n", pa->pa_lstart-len, len, pa);
}
预分配空间的来源
在ext4_mb_new_blocks()函数,当采用常规的分配方式分配成功后,如果所分得的长度大于最初要求分配的长度,那么多余出来的这部分空间就可以用来预分配:
ext4_fsblk_t ext4_mb_new_blocks(handle_t *handle,
struct ext4_allocation_request *ar, int *errp)
{
/* ...... */
if (!ext4_mb_use_preallocated(ac)) { // 预分配失败
ac->ac_op = EXT4_MB_HISTORY_ALLOC;
ext4_mb_normalize_request(ac, ar); // 对文件大小进行预估,预估后的大小比原来大一些
repeat:
/* 常规多块分配 */
*errp = ext4_mb_regular_allocator(ac);
if (*errp)
goto discard_and_exit;
/* as we've just preallocated more space than
* user requested originally, we store allocated
* space in a special descriptor */
if (ac->ac_status == AC_STATUS_FOUND &&
ac->ac_o_ex.fe_len < ac->ac_b_ex.fe_len)
*errp = ext4_mb_new_preallocation(ac); // 有多余的分配的空间作为预分配空间
if (*errp) {
discard_and_exit:
ext4_discard_allocated_blocks(ac);
goto errout;
}
}
/* ...... */
}
ext4_mb_new_preallocation()函数,将分配的多余的空间加入到预分配链表:
static int ext4_mb_new_preallocation(struct ext4_allocation_context *ac)
{
int err;
// 如果该文件是小文件则将多余空间加入到per_cpu locality group预分配空间,如果是大文件则将多余空间加入到per inode预分配空间
// 这个标记是在ext4_mb_group_or_file()函数根据配置的判别文件是大文件还是小文件的配置项来置上的
if (ac->ac_flags & EXT4_MB_HINT_GROUP_ALLOC)
err = ext4_mb_new_group_pa(ac);
else
err = ext4_mb_new_inode_pa(ac);
return err;
}
ext4_mb_new_group_pa()函数:
static noinline_for_stack int
ext4_mb_new_group_pa(struct ext4_allocation_context *ac)
{
struct super_block *sb = ac->ac_sb;
struct ext4_locality_group *lg;
struct ext4_prealloc_space *pa;
struct ext4_group_info *grp;
/* preallocate only when found space is larger then requested */
BUG_ON(ac->ac_o_ex.fe_len >= ac->ac_b_ex.fe_len);
BUG_ON(ac->ac_status != AC_STATUS_FOUND);
BUG_ON(!S_ISREG(ac->ac_inode->i_mode));
BUG_ON(ext4_pspace_cachep == NULL);
pa = kmem_cache_alloc(ext4_pspace_cachep, GFP_NOFS);
if (pa == NULL)
return -ENOMEM;
/* preallocation can change ac_b_ex, thus we store actually
* allocated blocks for history */
ac->ac_f_ex = ac->ac_b_ex;
pa->pa_pstart = ext4_grp_offs_to_block(sb, &ac->ac_b_ex);
pa->pa_lstart = pa->pa_pstart;
pa->pa_len = ac->ac_b_ex.fe_len; // 注意到pa的len是常规分配后分配到的长度!
pa->pa_free = pa->pa_len;
atomic_set(&pa->pa_count, 1);
spin_lock_init(&pa->pa_lock);
INIT_LIST_HEAD(&pa->pa_inode_list);
INIT_LIST_HEAD(&pa->pa_group_list);
pa->pa_deleted = 0;
pa->pa_type = MB_GROUP_PA;
mb_debug(1, "new group pa %p: %llu/%u for %u\n", pa,
pa->pa_pstart, pa->pa_len, pa->pa_lstart);
trace_ext4_mb_new_group_pa(ac, pa);
ext4_mb_use_group_pa(ac, pa); // 注意这一行
atomic_add(pa->pa_free, &EXT4_SB(sb)->s_mb_preallocated);
grp = ext4_get_group_info(sb, ac->ac_b_ex.fe_group);
lg = ac->ac_lg;
BUG_ON(lg == NULL);
pa->pa_obj_lock = &lg->lg_prealloc_lock;
pa->pa_inode = NULL;
ext4_lock_group(sb, ac->ac_b_ex.fe_group);
list_add(&pa->pa_group_list, &grp->bb_prealloc_list);
ext4_unlock_group(sb, ac->ac_b_ex.fe_group);
/*
* We will later add the new pa to the right bucket
* after updating the pa_free in ext4_mb_release_context
*/
return 0;
}
观察整个函数以及第38行可知,ext4_mb_new_group_pa()函数生成了一个ext4_prealloc_space但是没有急于将其挂入到per_cpu locality group中,而且ext4_prealloc_space的长度也是常规分配后分配到的长度而不是多余的长度,而是先调用ext4_mb_use_group_pa()函数将其保存到ac中(这里会改变分配到的长度len,因此在21行先将ac_b_ex拷贝到ac_f_ex),然后在最后的ext4_mb_release_context()流程中将其加入到per_cpu locality group,这样做是为了跟如果从per_cpu locality group分配到了预分配空间一起统一处理。
ext4_mb_release_context()函数:
static int ext4_mb_release_context(struct ext4_allocation_context *ac)
{
struct ext4_sb_info *sbi = EXT4_SB(ac->ac_sb);
struct ext4_prealloc_space *pa = ac->ac_pa;
if (pa) {
// 这里才减少ext4_prealloc_space的可用长度
if (pa->pa_type == MB_GROUP_PA) {
/* see comment in ext4_mb_use_group_pa() */
spin_lock(&pa->pa_lock);
pa->pa_pstart += EXT4_C2B(sbi, ac->ac_b_ex.fe_len);
pa->pa_lstart += EXT4_C2B(sbi, ac->ac_b_ex.fe_len);
pa->pa_free -= ac->ac_b_ex.fe_len;
pa->pa_len -= ac->ac_b_ex.fe_len;
spin_unlock(&pa->pa_lock);
}
}
if (pa) {
/*
* We want to add the pa to the right bucket.
* Remove it from the list and while adding
* make sure the list to which we are adding
* doesn't grow big.
*/
if ((pa->pa_type == MB_GROUP_PA) && likely(pa->pa_free)) {
spin_lock(pa->pa_obj_lock);
list_del_rcu(&pa->pa_inode_list);
spin_unlock(pa->pa_obj_lock);
ext4_mb_add_n_trim(ac); // 将其加入到per_cpu locality group中
}
ext4_mb_put_pa(ac, ac->ac_sb, pa);
}
if (ac->ac_bitmap_page)
put_page(ac->ac_bitmap_page);
if (ac->ac_buddy_page)
put_page(ac->ac_buddy_page);
if (ac->ac_flags & EXT4_MB_HINT_GROUP_ALLOC)
mutex_unlock(&ac->ac_lg->lg_mutex);
ext4_mb_collect_stats(ac);
return 0;
}
ext4_mb_add_n_trim()函数:
static void ext4_mb_add_n_trim(struct ext4_allocation_context *ac)
{
int order, added = 0, lg_prealloc_count = 1;
struct super_block *sb = ac->ac_sb;
struct ext4_locality_group *lg = ac->ac_lg;
struct ext4_prealloc_space *tmp_pa, *pa = ac->ac_pa;
// 根据预留空间的长度找到其应该所在的桶
order = fls(pa->pa_free) - 1;
if (order > PREALLOC_TB_SIZE - 1)
/* The max size of hash table is PREALLOC_TB_SIZE */
order = PREALLOC_TB_SIZE - 1;
/* Add the prealloc space to lg */
spin_lock(&lg->lg_prealloc_lock);
// 遍历桶的链表,然后将ext4_prealloc_space插入其中
list_for_each_entry_rcu(tmp_pa, &lg->lg_prealloc_list[order],
pa_inode_list) {
spin_lock(&tmp_pa->pa_lock);
if (tmp_pa->pa_deleted) {
spin_unlock(&tmp_pa->pa_lock);
continue;
}
// 在链表里面ext4_prealloc_space是按照可用空间由前到后的顺序排列的
if (!added && pa->pa_free < tmp_pa->pa_free) {
/* Add to the tail of the previous entry */
list_add_tail_rcu(&pa->pa_inode_list,
&tmp_pa->pa_inode_list);
added = 1;
/*
* we want to count the total
* number of entries in the list
*/
}
spin_unlock(&tmp_pa->pa_lock);
lg_prealloc_count++;
}
// 如果新的这个ext4_prealloc_space的可用空间是最大的,那么插入到链表尾端
if (!added)
list_add_tail_rcu(&pa->pa_inode_list,
&lg->lg_prealloc_list[order]);
spin_unlock(&lg->lg_prealloc_lock);
// 如果当前桶的预分配空间个数超过了8个,则相应的减少它们
if (lg_prealloc_count > 8) {
ext4_mb_discard_lg_preallocations(sb, lg,
order, lg_prealloc_count);
return;
}
return ;
}
ext4_mb_discard_lg_preallocations()函数:
static noinline_for_stack void
ext4_mb_discard_lg_preallocations(struct super_block *sb,
struct ext4_locality_group *lg,
int order, int total_entries)
{
ext4_group_t group = 0;
struct ext4_buddy e4b;
struct list_head discard_list;
struct ext4_prealloc_space *pa, *tmp;
mb_debug(1, "discard locality group preallocation\n");
INIT_LIST_HEAD(&discard_list);
spin_lock(&lg->lg_prealloc_lock);
list_for_each_entry_rcu(pa, &lg->lg_prealloc_list[order],
pa_inode_list) {
spin_lock(&pa->pa_lock);
// 如果预分配空间正在使用(刚刚分配流程在使用),则不能删除
if (atomic_read(&pa->pa_count)) {
/*
* This is the pa that we just used
* for block allocation. So don't
* free that
*/
spin_unlock(&pa->pa_lock);
continue;
}
if (pa->pa_deleted) {
spin_unlock(&pa->pa_lock);
continue;
}
/* only lg prealloc space */
BUG_ON(pa->pa_type != MB_GROUP_PA);
/* seems this one can be freed ... */
pa->pa_deleted = 1;
spin_unlock(&pa->pa_lock);
// 将预分配空间摘链
list_del_rcu(&pa->pa_inode_list);
// 加入到临时的discard_list链表中
list_add(&pa->u.pa_tmp_list, &discard_list);
total_entries--;
if (total_entries <= 5) { // 预分配空间个数减少到5个的时候才停止,以防止很快又调用本函数
/*
* we want to keep only 5 entries
* allowing it to grow to 8. This
* mak sure we don't call discard
* soon for this list.
*/
break;
}
}
spin_unlock(&lg->lg_prealloc_lock);
list_for_each_entry_safe(pa, tmp, &discard_list, u.pa_tmp_list) {
int err;
group = ext4_get_group_number(sb, pa->pa_pstart);
err = ext4_mb_load_buddy_gfp(sb, group, &e4b,
GFP_NOFS|__GFP_NOFAIL);
if (err) {
ext4_error(sb, "Error %d loading buddy information for %u",
err, group);
continue;
}
ext4_lock_group(sb, group);
list_del(&pa->pa_group_list); // 从ext4_group_info里面摘链
ext4_mb_release_group_pa(&e4b, pa); // 释放预分配空间,将其返还给文件系统
ext4_unlock_group(sb, group);
ext4_mb_unload_buddy(&e4b);
list_del(&pa->u.pa_tmp_list);
call_rcu(&(pa)->u.pa_rcu, ext4_mb_pa_callback); // 在callback里面会释放掉ext4_prealloc_space
}
}
ext4_mb_new_inode_pa()函数:
static noinline_for_stack int
ext4_mb_new_inode_pa(struct ext4_allocation_context *ac)
{
struct super_block *sb = ac->ac_sb;
struct ext4_sb_info *sbi = EXT4_SB(sb);
struct ext4_prealloc_space *pa;
struct ext4_group_info *grp;
struct ext4_inode_info *ei;
/* preallocate only when found space is larger then requested */
BUG_ON(ac->ac_o_ex.fe_len >= ac->ac_b_ex.fe_len);
BUG_ON(ac->ac_status != AC_STATUS_FOUND);
BUG_ON(!S_ISREG(ac->ac_inode->i_mode));
pa = kmem_cache_alloc(ext4_pspace_cachep, GFP_NOFS);
if (pa == NULL)
return -ENOMEM;
if (ac->ac_b_ex.fe_len < ac->ac_g_ex.fe_len) {
int winl;
int wins;
int win;
int offs;
/* we can't allocate as much as normalizer wants.
* so, found space must get proper lstart
* to cover original request */
BUG_ON(ac->ac_g_ex.fe_logical > ac->ac_o_ex.fe_logical);
BUG_ON(ac->ac_g_ex.fe_len < ac->ac_o_ex.fe_len);
/* we're limited by original request in that
* logical block must be covered any way
* winl is window we can move our chunk within */
winl = ac->ac_o_ex.fe_logical - ac->ac_g_ex.fe_logical;
/* also, we should cover whole original request */
wins = EXT4_C2B(sbi, ac->ac_b_ex.fe_len - ac->ac_o_ex.fe_len);
/* the smallest one defines real window */
win = min(winl, wins);
offs = ac->ac_o_ex.fe_logical %
EXT4_C2B(sbi, ac->ac_b_ex.fe_len);
if (offs && offs < win)
win = offs;
ac->ac_b_ex.fe_logical = ac->ac_o_ex.fe_logical -
EXT4_NUM_B2C(sbi, win);
BUG_ON(ac->ac_o_ex.fe_logical < ac->ac_b_ex.fe_logical);
BUG_ON(ac->ac_o_ex.fe_len > ac->ac_b_ex.fe_len);
}
/* preallocation can change ac_b_ex, thus we store actually
* allocated blocks for history */
ac->ac_f_ex = ac->ac_b_ex; // 还是先将ac_b_ex拷贝到ac_f_ex
pa->pa_lstart = ac->ac_b_ex.fe_logical;
pa->pa_pstart = ext4_grp_offs_to_block(sb, &ac->ac_b_ex);
pa->pa_len = ac->ac_b_ex.fe_len;
pa->pa_free = pa->pa_len;
atomic_set(&pa->pa_count, 1);
spin_lock_init(&pa->pa_lock);
INIT_LIST_HEAD(&pa->pa_inode_list);
INIT_LIST_HEAD(&pa->pa_group_list);
pa->pa_deleted = 0;
pa->pa_type = MB_INODE_PA;
mb_debug(1, "new inode pa %p: %llu/%u for %u\n", pa,
pa->pa_pstart, pa->pa_len, pa->pa_lstart);
trace_ext4_mb_new_inode_pa(ac, pa);
// 同样的也会走ext4_mb_release_context()流程
ext4_mb_use_inode_pa(ac, pa);
atomic_add(pa->pa_free, &sbi->s_mb_preallocated);
ei = EXT4_I(ac->ac_inode);
grp = ext4_get_group_info(sb, ac->ac_b_ex.fe_group);
pa->pa_obj_lock = &ei->i_prealloc_lock;
pa->pa_inode = ac->ac_inode;
// 加入到block group的链表下
ext4_lock_group(sb, ac->ac_b_ex.fe_group);
list_add(&pa->pa_group_list, &grp->bb_prealloc_list);
ext4_unlock_group(sb, ac->ac_b_ex.fe_group);
// 加入到ext4_inode_info的i_prealloc_list链表下,供后续大文件的预分配
spin_lock(pa->pa_obj_lock);
list_add_rcu(&pa->pa_inode_list, &ei->i_prealloc_list);
spin_unlock(pa->pa_obj_lock);
return 0;
}
从上述流程分析可以看出per_cpu locality group的预分配方式的预分配空间是文件系统全局的,这样可以使得小文件都聚集在一起,而per inode的预分配方式是针对单个文件的,使得文件所占的物理空间尽量挨在一起。
mballoc多块分配
在开始分析ext4_mb_regular_allocator()的多块分配流程之前,我们先来分析多块分配所采用的buddy系统的数据结构和初始化流程。
buddy系统将block group内的空闲空间按照其长度的阶进行分组,分组的长度为20到213次方,一个block group通常有32768个block,因此最多可以划分成4个213和32768个20,其他的阶以此类推。
查看/proc/fs/ext4/

struct ext4_buddy结构体:
struct ext4_buddy {
struct page *bd_buddy_page; // buddy系统有一个4k大小的bitmap来表示block group内的空间使用情况,而这个bitmap是由页缓存来管理的,这里就是bitmap所在的页
void *bd_buddy; // 指向页里面具体的buddy的bitmap
// buddy的bitmap是根据block group内的block bitmap构建而成的,这里是对应的block bitmap
struct page *bd_bitmap_page;
void *bd_bitmap;
struct ext4_group_info *bd_info; // block group的信息
struct super_block *bd_sb;
__u16 bd_blkbits; // 在load buddy的时候初始化为super_block的s_blocksize_bits,通常为12
ext4_group_t bd_group;
};
buddy系统的bitmap是由页缓存来管理的,而这个页缓存必须是整个文件系统范围内的,因此ext4在ext4_sb_info结构里面用一个inode结构体来管理buddy的页缓存,字段名为s_buddy_cache。我们通过分析buddy系统的初始化流程来深入理解其构造:
ext4调用ext4_mb_init_group()函数对buddy系统进行初始化:
static noinline_for_stack
int ext4_mb_init_group(struct super_block *sb, ext4_group_t group, gfp_t gfp)
{
struct ext4_group_info *this_grp;
struct ext4_buddy e4b;
struct page *page;
int ret = 0;
might_sleep();
mb_debug(1, "init group %u\n", group);
this_grp = ext4_get_group_info(sb, group);
/*
* This ensures that we don't reinit the buddy cache
* page which map to the group from which we are already
* allocating. If we are looking at the buddy cache we would
* have taken a reference using ext4_mb_load_buddy and that
* would have pinned buddy page to page cache.
* The call to ext4_mb_get_buddy_page_lock will mark the
* page accessed.
*/
// 申请buddy系统的页
ret = ext4_mb_get_buddy_page_lock(sb, group, &e4b, gfp);
if (ret || !EXT4_MB_GRP_NEED_INIT(this_grp)) {
/*
* somebody initialized the group
* return without doing anything
*/
goto err;
}
page = e4b.bd_bitmap_page;
// 负责读取磁盘,并且初始化block bitmap
ret = ext4_mb_init_cache(page, NULL, gfp);
if (ret)
goto err;
if (!PageUptodate(page)) {
ret = -EIO;
goto err;
}
if (e4b.bd_buddy_page == NULL) {
/*
* If both the bitmap and buddy are in
* the same page we don't need to force
* init the buddy
*/
ret = 0;
goto err;
}
// 初始化buddy bit map
page = e4b.bd_buddy_page;
ret = ext4_mb_init_cache(page, e4b.bd_bitmap, gfp);
if (ret)
goto err;
if (!PageUptodate(page)) {
ret = -EIO;
goto err;
}
err:
ext4_mb_put_buddy_page_lock(&e4b);
return ret;
}
ext4_mb_get_buddy_page_lock()函数:
static int ext4_mb_get_buddy_page_lock(struct super_block *sb,
ext4_group_t group, struct ext4_buddy *e4b, gfp_t gfp)
{
// 所有buddy的内存内容都是由s_buddy_cache管理
struct inode *inode = EXT4_SB(sb)->s_buddy_cache;
int block, pnum, poff;
int blocks_per_page;
struct page *page;
e4b->bd_buddy_page = NULL;
e4b->bd_bitmap_page = NULL;
blocks_per_page = PAGE_SIZE / sb->s_blocksize; // 假定块大小为4k,则blocks_per_page为1
/*
在s_buddy_cache的页缓存里,page的index为偶数的时候代表这个page里面装的是block group的block bitmap,为奇数的时候page里面装的是buddy bitmap,也叫buddy cache,也就是说0、2、4、6、8...为block bit map的page,每个block bitmap page紧挨着的1、3、5、7、9..为buddy bitmap page,依次对应的block group的编号为0、1、2、3、4...
*/
block = group * 2;
pnum = block / blocks_per_page; // 就是block
poff = block % blocks_per_page; // 0
// 找到或者创建page来存储block bitmap
page = find_or_create_page(inode->i_mapping, pnum, gfp);
if (!page)
return -ENOMEM;
BUG_ON(page->mapping != inode->i_mapping);
e4b->bd_bitmap_page = page;
// 通常这里就是page的首地址
e4b->bd_bitmap = page_address(page) + (poff * sb->s_blocksize);
if (blocks_per_page >= 2) {
/* buddy and bitmap are on the same page */
return 0;
}
block++; // 获取到buddy_page,buddy bitmap的page排在block bitmap page的后面
pnum = block / blocks_per_page;
page = find_or_create_page(inode->i_mapping, pnum, gfp);
if (!page)
return -ENOMEM;
BUG_ON(page->mapping != inode->i_mapping);
e4b->bd_buddy_page = page;
return 0;
}
ext4_mb_init_cache()函数,ext4_mb_init_group()函数会调用两次这个函数,区别是第一次调时incore为空,为的是初始化block bitmap;第二次调用时,incore传入的是bd_bitmap,用block bitmap来初始化buddy bitmap。
static int ext4_mb_init_cache(struct page *page, char *incore, gfp_t gfp)
{
ext4_group_t ngroups;
int blocksize;
int blocks_per_page;
int groups_per_page;
int err = 0;
int i;
ext4_group_t first_group, group;
int first_block;
struct super_block *sb;
struct buffer_head *bhs;
struct buffer_head **bh = NULL;
struct inode *inode;
char *data;
char *bitmap;
struct ext4_group_info *grinfo;
mb_debug(1, "init page %lu\n", page->index);
inode = page->mapping->host;
sb = inode->i_sb;
ngroups = ext4_get_groups_count(sb);
blocksize = i_blocksize(inode);
blocks_per_page = PAGE_SIZE / blocksize;
// 通常情况下blocks_per_page为1,这里groups_per_page的最终结果为1
groups_per_page = blocks_per_page >> 1;
if (groups_per_page == 0)
groups_per_page = 1;
/* allocate buffer_heads to read bitmaps */
if (groups_per_page > 1) {
i = sizeof(struct buffer_head *) * groups_per_page;
bh = kzalloc(i, gfp);
if (bh == NULL) {
err = -ENOMEM;
goto out;
}
} else
bh = &bhs;
first_group = page->index * blocks_per_page / 2;
/* read all groups the page covers into the cache */
for (i = 0, group = first_group; i < groups_per_page; i++, group++) {
if (group >= ngroups)
break;
// block group信息以二维数组的形式存在ext4_sb_info里面的,
// 二维数组一行64个,通过对64取商能找到其在第几行,通过对64取余能找到在第几列
grinfo = ext4_get_group_info(sb, group);
/*
* If page is uptodate then we came here after online resize
* which added some new uninitialized group info structs, so
* we must skip all initialized uptodate buddies on the page,
* which may be currently in use by an allocating task.
*/
if (PageUptodate(page) && !EXT4_MB_GRP_NEED_INIT(grinfo)) {
bh[i] = NULL;
continue;
}
// 发送读IO去读取block bitmap
// 通过block group的编号能够拿到block group在磁盘上的描述ext4_group_desc,通过ext4_group_desc能够拿到block group的block bitmap在哪个block,然后通过在super_block里面的页缓存获取到block bitmap的具体内容
// 在super_block里面的页缓存是针对文件系统的元素据的缓存,而在inode里面的缓存是文件的数据的页缓存
bh[i] = ext4_read_block_bitmap_nowait(sb, group);
if (IS_ERR(bh[i])) {
err = PTR_ERR(bh[i]);
bh[i] = NULL;
goto out;
}
mb_debug(1, "read bitmap for group %u\n", group);
}
// 等待读block bitmap的IO完成
for (i = 0, group = first_group; i < groups_per_page; i++, group++) {
int err2;
if (!bh[i])
continue;
err2 = ext4_wait_block_bitmap(sb, group, bh[i]);
if (!err)
err = err2;
}
first_block = page->index * blocks_per_page; // 这个页里面的第一个block
for (i = 0; i < blocks_per_page; i++) {
group = (first_block + i) >> 1; // 除以2,得到block group号
if (group >= ngroups)
break;
if (!bh[group - first_group])
/* skip initialized uptodate buddy */
continue;
if (!buffer_verified(bh[group - first_group]))
/* Skip faulty bitmaps */
continue;
err = 0;
/*
* data carry information regarding this
* particular group in the format specified
* above
*
*/
data = page_address(page) + (i * blocksize);
bitmap = bh[group - first_group]->b_data;
/*
* We place the buddy block and bitmap block
* close together
*/
if ((first_block + i) & 1) { // 奇数则为buddy bitmap
/* this is block of buddy */
BUG_ON(incore == NULL);
mb_debug(1, "put buddy for group %u in page %lu/%x\n",
group, page->index, i * blocksize);
trace_ext4_mb_buddy_bitmap_load(sb, group);
grinfo = ext4_get_group_info(sb, group);
grinfo->bb_fragments = 0;
memset(grinfo->bb_counters, 0,
sizeof(*grinfo->bb_counters) *
(sb->s_blocksize_bits+2)); // 0 到 13 一共14个
/*
* incore got set to the group block bitmap below
*/
ext4_lock_group(sb, group);
/* init the buddy */
memset(data, 0xff, blocksize); // 先把buddy page全部置成1,有空闲的则清为0
// 初始化buddy重点这个函数
ext4_mb_generate_buddy(sb, data, incore, group);
ext4_unlock_group(sb, group);
incore = NULL;
} else { // 偶数为block bitmap
/* this is block of bitmap */
BUG_ON(incore != NULL);
mb_debug(1, "put bitmap for group %u in page %lu/%x\n",
group, page->index, i * blocksize);
trace_ext4_mb_bitmap_load(sb, group);
/* see comments in ext4_mb_put_pa() */
ext4_lock_group(sb, group);
// 将读上来的block bitmap拷贝到buddy系统的页缓存里面
memcpy(data, bitmap, blocksize);
/* mark all preallocated blks used in in-core bitmap */
ext4_mb_generate_from_pa(sb, data, group);
ext4_mb_generate_from_freelist(sb, data, group);
ext4_unlock_group(sb, group);
/* set incore so that the buddy information can be
* generated using this
*/
incore = data;
}
}
SetPageUptodate(page);
out:
if (bh) {
for (i = 0; i < groups_per_page; i++)
brelse(bh[i]);
if (bh != &bhs)
kfree(bh);
}
return err;
}
在读取了block bitmap后将其拷贝到buddy系统的页缓存里面,此后还要调用两个函数来做一些标记:
1)ext4_mb_generate_from_pa()函数
static noinline_for_stack
void ext4_mb_generate_from_pa(struct super_block *sb, void *bitmap,
ext4_group_t group)
{
struct ext4_group_info *grp = ext4_get_group_info(sb, group);
struct ext4_prealloc_space *pa;
struct list_head *cur;
ext4_group_t groupnr;
ext4_grpblk_t start;
int preallocated = 0;
int len;
/*
遍历所有该block group下的预分配空间,将预分配空间的范围标记到block bitmap里面
*/
list_for_each(cur, &grp->bb_prealloc_list) {
pa = list_entry(cur, struct ext4_prealloc_space, pa_group_list);
spin_lock(&pa->pa_lock);
ext4_get_group_no_and_offset(sb, pa->pa_pstart,
&groupnr, &start);
len = pa->pa_len;
spin_unlock(&pa->pa_lock);
if (unlikely(len == 0))
continue;
BUG_ON(groupnr != group);
ext4_set_bits(bitmap, start, len);
preallocated += len;
}
mb_debug(1, "preallocated %u for group %u\n", preallocated, group);
}
2)ext4_mb_generate_from_freelist()函数
static void ext4_mb_generate_from_freelist(struct super_block *sb, void *bitmap,
ext4_group_t group)
{
struct rb_node *n;
struct ext4_group_info *grp;
struct ext4_free_data *entry;
grp = ext4_get_group_info(sb, group);
n = rb_first(&(grp->bb_free_root));
// 遍历block group的bb_free_root红黑树,将空间范围标记到block bitmap里面
while (n) {
entry = rb_entry(n, struct ext4_free_data, efd_node);
ext4_set_bits(bitmap, entry->efd_start_cluster, entry->efd_count);
n = rb_next(n);
}
return;
}
初始化buddy bitmap:
struct ext4_group_info结构体,用于描述block group在内存中的信息:
struct ext4_group_info {
unsigned long bb_state;
struct rb_root bb_free_root; // 挂ext4_free_data的红黑树
ext4_grpblk_t bb_first_free; // 第一个是空闲的块
ext4_grpblk_t bb_free; // 总的空间块个数
ext4_grpblk_t bb_fragments; // 连续的空闲空间段数目
ext4_grpblk_t bb_largest_free_order; // block group中最大的空闲空间的阶
struct list_head bb_prealloc_list; // 挂ext4_prealloc_space
#ifdef DOUBLE_CHECK
void *bb_bitmap;
#endif
struct rw_semaphore alloc_sem;
ext4_grpblk_t bb_counters[]; // 用一个0长数组记录每个阶的空闲空间有多少个
};
初始化buddy bitmap需要知道这到底是个什么,它跟block bitmap的关系是什么:
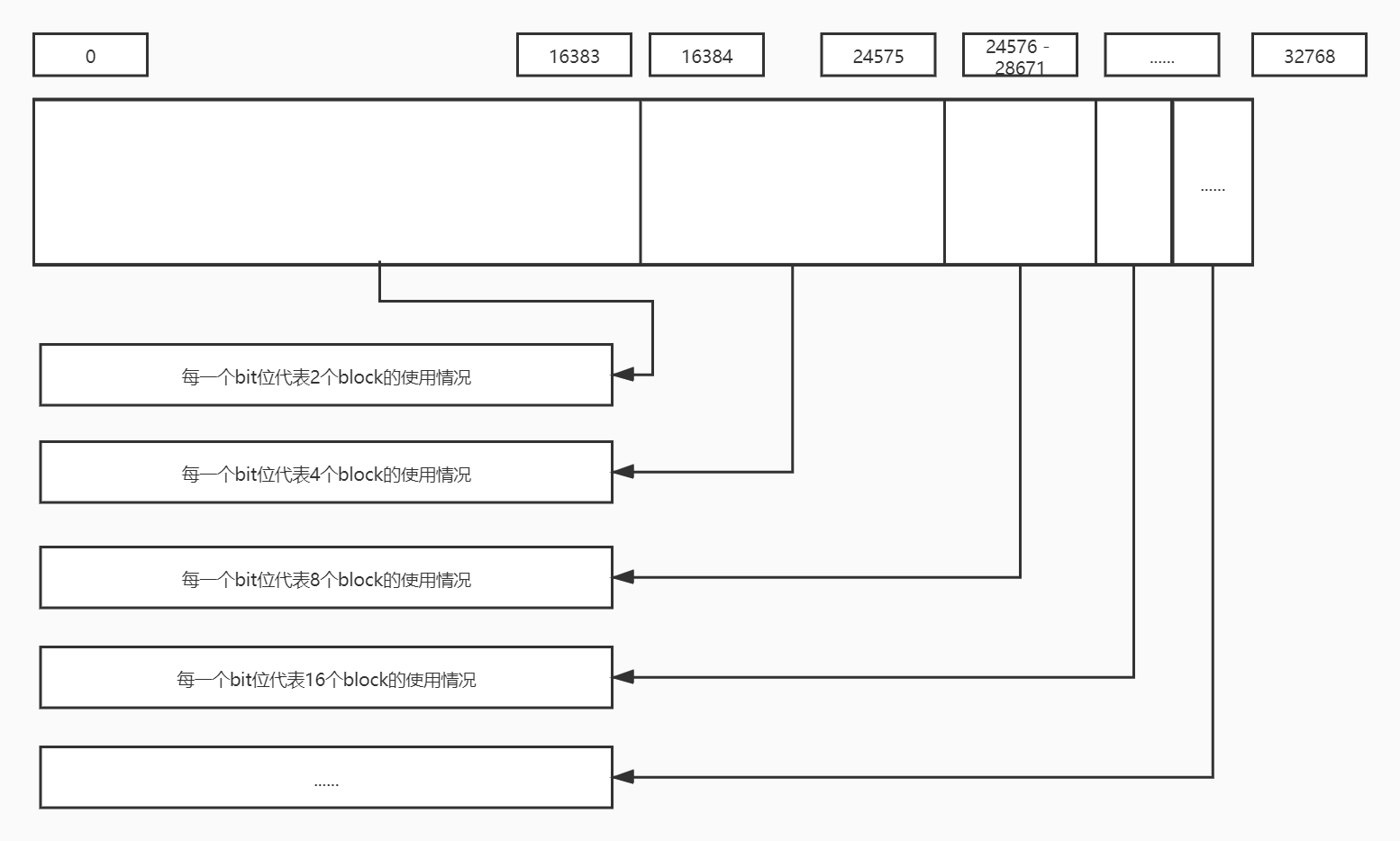
通常情况下block bitmap和buddy bitmap的大小都是4k,对于block bitmap来说,4k的空间有32768个bit位,而每一个bit位代表一个block块(4k)的使用情况(1为占用,0为空闲),因此能表示128M的空间。
buddy bitmap首先拿出这32768个bit位的前一半,也就是0-16383,这些bit位每一个bit位表示连续的两个(21)block的空闲情况;然后再从剩下的一半bit中拿出一半的bit来表示连续4个(22)block的使用情况;接着再从剩下的一半bit位里面拿出一半来表示连续8个(23)block的使用情况......依次类推,最终可以表示4个213个block的使用情况。
举个例子,在初始化的时候,buddy系统通过block bitmap发现有连续的14个空间是连续的,并假设其地址为0-13(相对于block group的第一个block而言的),此时流程会将这个14个block按照阶划分为8+4+2,即分到3阶、2阶和1阶,对应在buddy bitmap的bit位里面(借用一张其他人画的图):
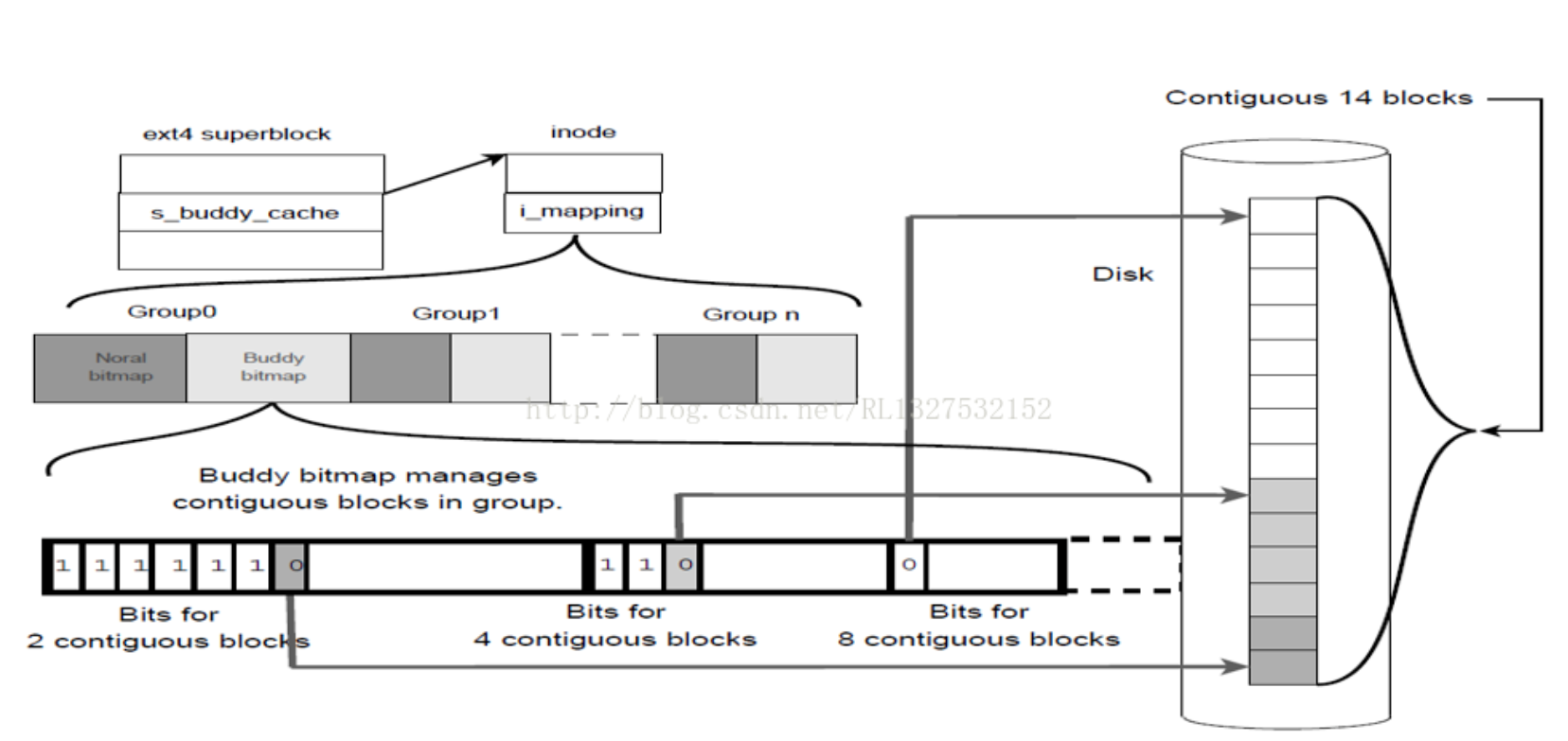
由图可见,buddy bitmap里面不仅仅包含了block的使用情况信息,而且还包含了block的位置信息(划分到1阶的那两个block的偏移为12-13,bitmap里面的第7个bit位为0)。此外,我们还可以看出当高阶为0时所有的低阶都为1,这是初始化的结果。
那么有的同学会问了,当只有一个block是连续的空闲空间时怎么表示呢?
当空闲空间只有一个block时,buddy系统将其记录在ext4_group_info的bb_counters[0]里面。
ext4_mb_init_cache()函数的第114到133行:
首先获取ext4_group_info准备初始化,将bb_fragments和bb_counters都置为0,后续会增加这两个值,接着第129行将buddy bitmap全部置1,当后续遍历block bitmap时划分了阶再置相应的bit为0,最后调用ext4_mb_generate_buddy()函数根据block bitmap初始化buddy bitmap:
static noinline_for_stack
void ext4_mb_generate_buddy(struct super_block *sb,
void *buddy, void *bitmap, ext4_group_t group)
{
struct ext4_group_info *grp = ext4_get_group_info(sb, group);
struct ext4_sb_info *sbi = EXT4_SB(sb);
ext4_grpblk_t max = EXT4_CLUSTERS_PER_GROUP(sb); // max为每个group的cluster数量
ext4_grpblk_t i = 0;
ext4_grpblk_t first;
ext4_grpblk_t len;
unsigned free = 0;
unsigned fragments = 0;
unsigned long long period = get_cycles();
/* initialize buddy from bitmap which is aggregation
* of on-disk bitmap and preallocations */
i = mb_find_next_zero_bit(bitmap, max, 0); // 找到bitmap里面第一个0,也就是第一个空闲block的位置
grp->bb_first_free = i;
while (i < max) {
fragments++;
first = i;
// 找到从i开始的下一个1的位置,从i到这个位置就是这一段空闲空间的长度(i - first)
i = mb_find_next_bit(bitmap, max, i);
len = i - first;
free += len; // 记录总的空闲空间的长度
if (len > 1)
// 如果长度大于1则去划分阶,然后记录到buddy bitmap和bb_counters
ext4_mb_mark_free_simple(sb, buddy, first, len, grp);
else
// 如果长度为1则记录到bb_counters中即可
grp->bb_counters[0]++;
// 继续寻找下一段空闲空间
if (i < max)
i = mb_find_next_zero_bit(bitmap, max, i);
}
grp->bb_fragments = fragments; // 碎片数
.......
}
ext4_mb_mark_free_simple()函数:
static void ext4_mb_mark_free_simple(struct super_block *sb,
void *buddy, ext4_grpblk_t first, ext4_grpblk_t len,
struct ext4_group_info *grp)
{
struct ext4_sb_info *sbi = EXT4_SB(sb);
ext4_grpblk_t min;
ext4_grpblk_t max;
ext4_grpblk_t chunk;
unsigned int border;
BUG_ON(len > EXT4_CLUSTERS_PER_GROUP(sb));
border = 2 << sb->s_blocksize_bits; // 8192即2^13次方, 32M的空间
while (len > 0) { // 将长度进行拆分,比如长度为14会拆分成8+4+2
/* find how many blocks can be covered since this position */
// ffs为find first set,转换成二进制之后从右往左的第一个1的位置
max = ffs(first | border) - 1;
// find last set,转换成二进制之后从右往左的最后一个1的位置
min = fls(len) - 1;
if (max < min)
min = max;
chunk = 1 << min;
// 往bb_counters记录计数
grp->bb_counters[min]++;
if (min > 0)
// 将buddy bitmap里面的相应的bit位置0
// buddy + sbi->s_mb_offsets[min]的意思是找到对应阶的bit位的起始位置
// 例如1阶的起始位置是0,二阶的起始位置是16384......
mb_clear_bit(first >> min,
buddy + sbi->s_mb_offsets[min]);
len -= chunk;
first += chunk;
}
}
到此位置buddy bitmap和相关的计数就已经完成了,可以进行多块分配动作,让我们回到ext4_mb_regular_allocator()函数,这个函数太长,我们还是分成两个部分来分析:
static noinline_for_stack int
ext4_mb_regular_allocator(struct ext4_allocation_context *ac)
{
ext4_group_t ngroups, group, i;
int cr;
int err = 0, first_err = 0;
struct ext4_sb_info *sbi;
struct super_block *sb;
struct ext4_buddy e4b;
sb = ac->ac_sb;
sbi = EXT4_SB(sb);
ngroups = ext4_get_groups_count(sb); // 文件系统的block group个数
/* non-extent files are limited to low blocks/groups */
if (!(ext4_test_inode_flag(ac->ac_inode, EXT4_INODE_EXTENTS)))
ngroups = sbi->s_blockfile_groups;
BUG_ON(ac->ac_status == AC_STATUS_FOUND);
// 先尝试在goal的地方能不能分配
err = ext4_mb_find_by_goal(ac, &e4b);
if (err || ac->ac_status == AC_STATUS_FOUND)
goto out;
if (unlikely(ac->ac_flags & EXT4_MB_HINT_GOAL_ONLY))
goto out;
......
}
ext4_mb_find_by_goal()函数,从goal的位置尝试进行分配:
static noinline_for_stack
int ext4_mb_find_by_goal(struct ext4_allocation_context *ac,
struct ext4_buddy *e4b)
{
ext4_group_t group = ac->ac_g_ex.fe_group;
int max;
int err;
struct ext4_sb_info *sbi = EXT4_SB(ac->ac_sb);
struct ext4_group_info *grp = ext4_get_group_info(ac->ac_sb, group);
struct ext4_free_extent ex;
if (!(ac->ac_flags & EXT4_MB_HINT_TRY_GOAL))
return 0;
if (grp->bb_free == 0) // block group已经没有空闲空间了,直接返回
return 0;
// 初始化buddy bitmap,详细见上面
err = ext4_mb_load_buddy(ac->ac_sb, group, e4b);
if (err)
return err;
if (unlikely(EXT4_MB_GRP_BBITMAP_CORRUPT(e4b->bd_info))) {
ext4_mb_unload_buddy(e4b);
return 0;
}
ext4_lock_group(ac->ac_sb, group);
// 根据buddy bitmap寻找合适的空闲空间
max = mb_find_extent(e4b, ac->ac_g_ex.fe_start, // start为在group内的偏移
ac->ac_g_ex.fe_len, &ex);
ex.fe_logical = 0xDEADFA11; /* debug value */
// 这个分支是ext4文件系统对raid的优化,当分配的起始地址和长度都对齐到stripe时才分配
if (max >= ac->ac_g_ex.fe_len && ac->ac_g_ex.fe_len == sbi->s_stripe) {
ext4_fsblk_t start;
start = ext4_group_first_block_no(ac->ac_sb, e4b->bd_group) +
ex.fe_start;
/* use do_div to get remainder (would be 64-bit modulo) */
if (do_div(start, sbi->s_stripe) == 0) {
ac->ac_found++;
ac->ac_b_ex = ex;
ext4_mb_use_best_found(ac, e4b);
}
// 分配成功
} else if (max >= ac->ac_g_ex.fe_len) {
BUG_ON(ex.fe_len <= 0);
BUG_ON(ex.fe_group != ac->ac_g_ex.fe_group);
BUG_ON(ex.fe_start != ac->ac_g_ex.fe_start);
ac->ac_found++;
ac->ac_b_ex = ex;
ext4_mb_use_best_found(ac, e4b);
// 调用者只是想合并某些小的空闲空间,这就是其他流程了
} else if (max > 0 && (ac->ac_flags & EXT4_MB_HINT_MERGE)) {
/* Sometimes, caller may want to merge even small
* number of blocks to an existing extent */
BUG_ON(ex.fe_len <= 0);
BUG_ON(ex.fe_group != ac->ac_g_ex.fe_group);
BUG_ON(ex.fe_start != ac->ac_g_ex.fe_start);
ac->ac_found++;
ac->ac_b_ex = ex;
ext4_mb_use_best_found(ac, e4b);
}
ext4_unlock_group(ac->ac_sb, group);
ext4_mb_unload_buddy(e4b);
return 0;
}
mb_find_extent()函数,分配的核心函数,根据buddy bitmap进行分配动作,传入的block和needed都是以cluster为单位的,分别表示起始和长度:
static int mb_find_extent(struct ext4_buddy *e4b, int block,
int needed, struct ext4_free_extent *ex)
{
int next = block;
int max, order;
void *buddy;
assert_spin_locked(ext4_group_lock_ptr(e4b->bd_sb, e4b->bd_group));
BUG_ON(ex == NULL);
// max表示传入的阶能够遍历多少个bit位
// 例如0阶可以遍历整个block bitmap,此时max为32768
// 1阶就必须遍历buddy bitmap的前半段,max为16384
// 2阶max为8192
// 3阶......
buddy = mb_find_buddy(e4b, 0, &max);
BUG_ON(buddy == NULL);
BUG_ON(block >= max);
if (mb_test_bit(block, buddy)) { // 起始位置已经被分配了
ex->fe_len = 0;
ex->fe_start = 0;
ex->fe_group = 0;
return 0;
}
// 注意这里的block是起始位置,不是长度
// order表示的是从block位置开始的最长空闲空闲长度的阶
order = mb_find_order_for_block(e4b, block);
block = block >> order; // 将起始位置对齐到order
// fe_len表示已经分配到的长度,当前是假设分配了这么多
ex->fe_len = 1 << order;
// 暂时将fe_start与当前的阶对齐
ex->fe_start = block << order;
ex->fe_group = e4b->bd_group;
/* calc difference from given start */
next = next - ex->fe_start; //原始为起始位置减去当前阶的起始位置表示"多分配了"多少个block
// 与阶对齐的分配长度减去多分配的block就是实际分配到的长度
ex->fe_len -= next;
ex->fe_start += next; // 起始位置最终又被还原到最初的起始位置了
while (needed > ex->fe_len &&
mb_find_buddy(e4b, order, &max)) {
if (block + 1 >= max)
break;
// 此时的next被赋值为上一次的阶能找到的最长的分配长度后紧接着要从哪里开始分配
// next与上一次分配的起始位置相差上一次分配的长度
next = (block + 1) * (1 << order);
// 如果这一次探测的起始位置已经被占用了则结束后续的探测,因为空闲的block已经不连续了
if (mb_test_bit(next, e4b->bd_bitmap))
break;
// 从next开始的连续的空闲空间的长度的阶
order = mb_find_order_for_block(e4b, next);
// 如果申请分配的长度还没有分配完毕则继续往后探测
block = next >> order;
ex->fe_len += 1 << order;
}
// 检查一下
if (ex->fe_start + ex->fe_len > (1 << (e4b->bd_blkbits + 3))) {
/* Should never happen! (but apparently sometimes does?!?) */
WARN_ON(1);
ext4_error(e4b->bd_sb, "corruption or bug in mb_find_extent "
"block=%d, order=%d needed=%d ex=%u/%d/%d@%u",
block, order, needed, ex->fe_group, ex->fe_start,
ex->fe_len, ex->fe_logical);
ex->fe_len = 0;
ex->fe_start = 0;
ex->fe_group = 0;
}
return ex->fe_len;
}
mb_find_order_for_block()函数:
/*
block为起始地址,根据buddy bitmap探测从起始位置开始能够分配的最长空闲空间的阶
*/
static int mb_find_order_for_block(struct ext4_buddy *e4b, int block)
{
int order = 1;
int bb_incr = 1 << (e4b->bd_blkbits - 1); // 2048个字节
void *bb;
BUG_ON(e4b->bd_bitmap == e4b->bd_buddy);
BUG_ON(block >= (1 << (e4b->bd_blkbits + 3)));
bb = e4b->bd_buddy;
while (order <= e4b->bd_blkbits + 1) { // order <= 13
// order等于1时,buddy bitmap的一个bit位表示两个block,因此起始位置要除以2得到的便是这个起始位置对应这buddy bitmap里面的第几个bit位,然后看这个bit位有无被占用
block = block >> 1;
// 如果这个bit位没有被占用表示可以分配1 << order个block
if (!mb_test_bit(block, bb)) {
/* this block is part of buddy of order 'order' */
return order;
}
// 如果当前bit位为1,那么有两种情况:
// 1) 其上阶对应的bit位都为1表示占用,最终会返回order=0
// 2) 其上阶的某一阶对应的bit位为0表示可用,因此这里向高阶搜索
bb += bb_incr; // order = 1时,这里加的量是2048字节也就是16384个bit位,就找到了第2阶的buddy bitmap的起始位置
bb_incr >>= 1;
order++;
}
return 0;
}
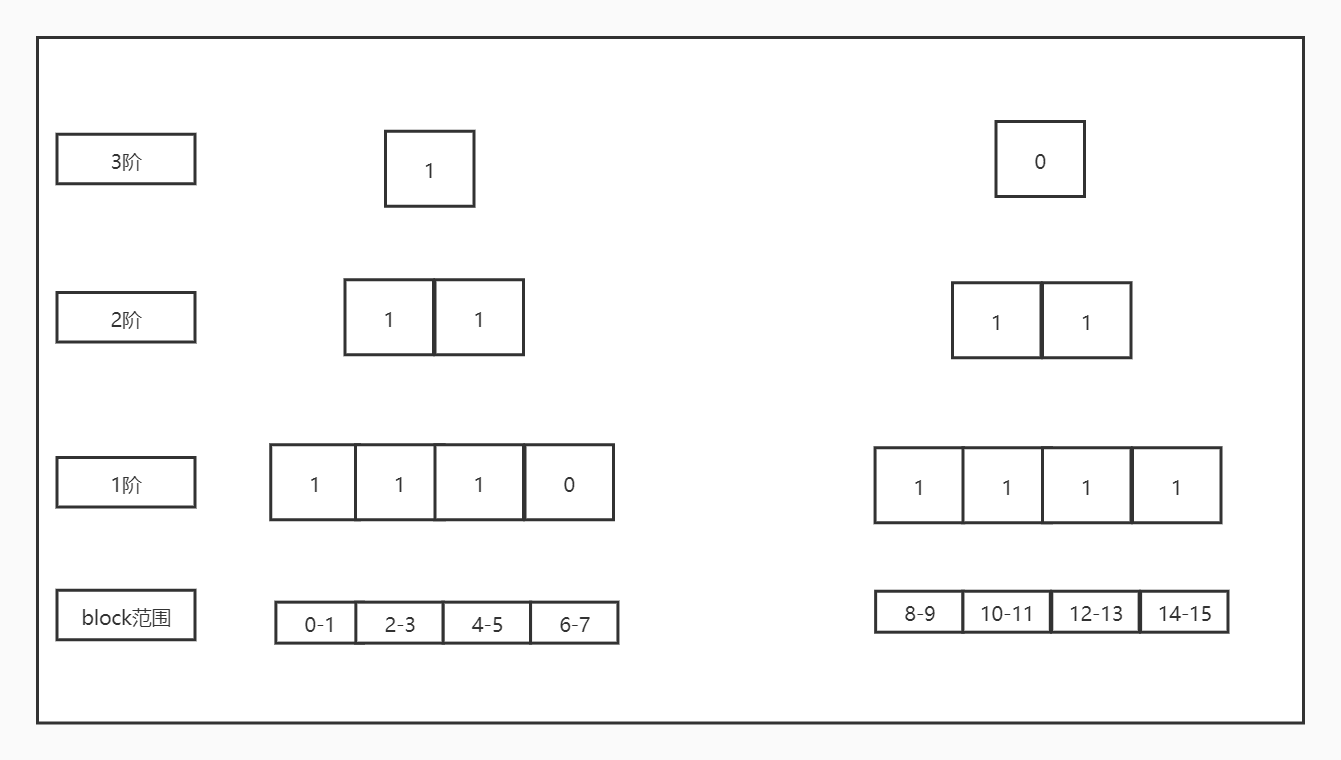
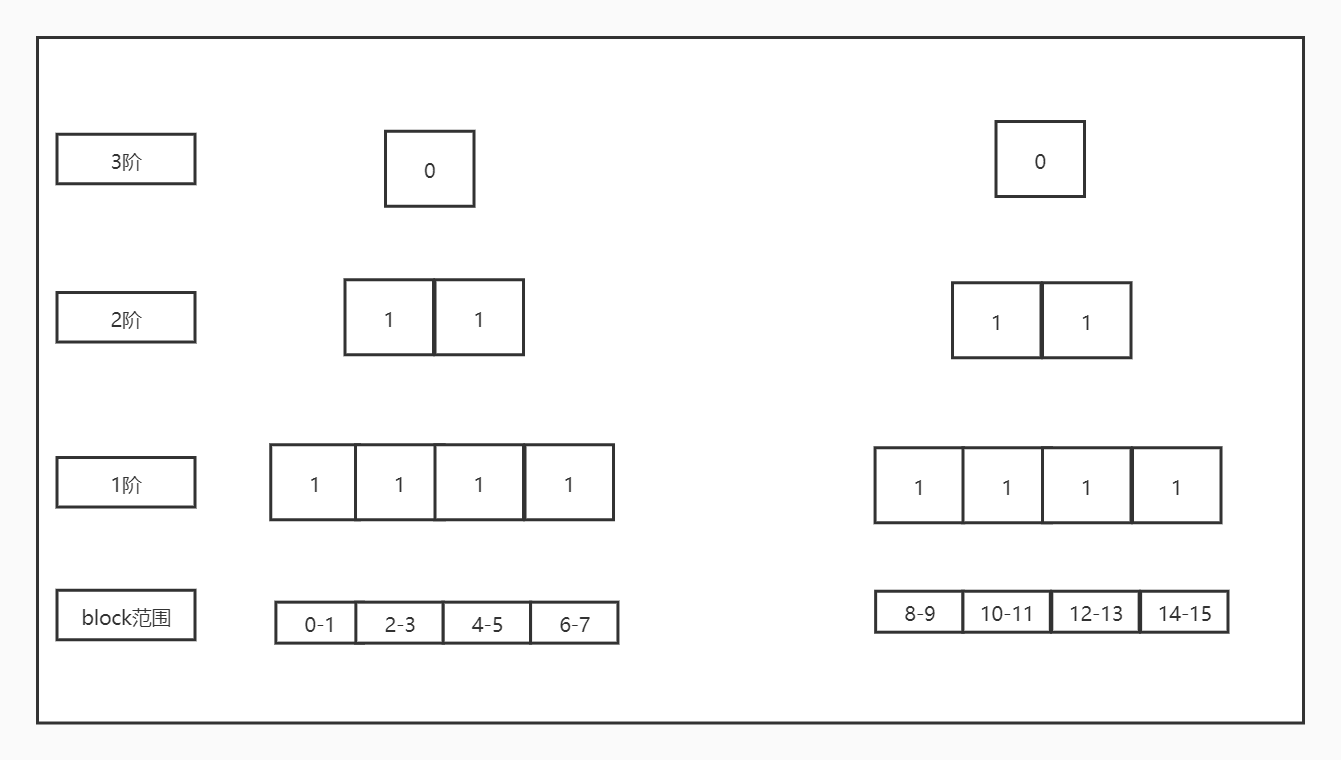
mb_find_extent()函数的第26到59行需要举个例子:
假设申请从7开始分配,分配9个block:
1)假设6-7的block是空闲的,0-5的block是占用的,8-15的block是空闲的,那么它构建出来的buddy bitmap如下:
2)假设0-7和8-9的空间都是空闲的,那么它构建出来的buddy bitmap如下:
可以把buddy bitmap当成一棵树来看待,28到41行的代码就是要找到起始位置所在的子树能够申请到多少个block,进入while循环后就是在"紧挨着的子树"上从最底层往上寻找能否分配了。
如果从goal分配成功会调用函数ext4_mb_use_best_found()置上最终的结果。
我们回到ext4_mb_regular_allocator()函数,分析一下如果在goal分配失败了会作何策略:
static noinline_for_stack int
ext4_mb_regular_allocator(struct ext4_allocation_context *ac)
{
/*
......
尝试从goal开始分配
*/
// 找到目标长度的二进制的从右往左数最后一个1的位置,len的order
i = fls(ac->ac_g_ex.fe_len);
ac->ac_2order = 0;
/*
当请求分配的长度的order大于等于s_mb_order2_reqs时,
s_mb_order2_reqs可以通过/sys/fs/ext4/<partition>/mb_order2_req配置
*/
if (i >= sbi->s_mb_order2_reqs && i <= sb->s_blocksize_bits + 2) {
/*
* 申请分配的数量刚好是2的N次方
*/
if ((ac->ac_g_ex.fe_len & (~(1 << (i - 1)))) == 0)
ac->ac_2order = array_index_nospec(i - 1,
sb->s_blocksize_bits + 2);
}
/* if stream allocation is enabled, use global goal */
if (ac->ac_flags & EXT4_MB_STREAM_ALLOC) {
/* TBD: may be hot point */
spin_lock(&sbi->s_md_lock);
// 从文件系统上一次分配的地方开始分配
ac->ac_g_ex.fe_group = sbi->s_mb_last_group;
ac->ac_g_ex.fe_start = sbi->s_mb_last_start;
spin_unlock(&sbi->s_md_lock);
}
/*
cr表示搜索block group的严苛程度,严苛程度从高到低
0是最严苛的程度,详见ext4_mb_good_group()函数
*/
cr = ac->ac_2order ? 0 : 1;
repeat:
// 每一轮的严苛程度不一样
for (; cr < 4 && ac->ac_status == AC_STATUS_CONTINUE; cr++) {
ac->ac_criteria = cr;
// 从goal的那个block group开始搜索,如果遍历到了最后一个block group则转去第一个block group
group = ac->ac_g_ex.fe_group;
for (i = 0; i < ngroups; group++, i++) {
int ret = 0;
cond_resched();
/*
* Artificially restricted ngroups for non-extent
* files makes group > ngroups possible on first loop.
*/
if (group >= ngroups) // 回到起始的第一个group看能否分配
group = 0;
// 在不加锁的情况下先检查一下能否分配,如果能则加锁去检查
ret = ext4_mb_good_group(ac, group, cr);
if (ret <= 0) {
if (!first_err)
first_err = ret;
continue;
}
// 加载buddy
err = ext4_mb_load_buddy(sb, group, &e4b);
if (err)
goto out;
ext4_lock_group(sb, group);
// 加载了buddy,加了锁之后再check能否分配
ret = ext4_mb_good_group(ac, group, cr);
if (ret <= 0) {
ext4_unlock_group(sb, group);
ext4_mb_unload_buddy(&e4b);
if (!first_err)
first_err = ret;
continue;
}
ac->ac_groups_scanned++;
if (cr == 0)
// 申请分配的长度刚好是2的N次方的时候才会走这里
ext4_mb_simple_scan_group(ac, &e4b);
else if (cr == 1 && sbi->s_stripe &&
!(ac->ac_g_ex.fe_len % sbi->s_stripe)) // 要分配的长度是stripe的整数倍,这是对raid的优化
ext4_mb_scan_aligned(ac, &e4b);
else
ext4_mb_complex_scan_group(ac, &e4b);
ext4_unlock_group(sb, group);
ext4_mb_unload_buddy(&e4b);
if (ac->ac_status != AC_STATUS_CONTINUE)
break;
}
}
// 最终也还是没有分配成功
if (ac->ac_b_ex.fe_len > 0 && ac->ac_status != AC_STATUS_FOUND &&
!(ac->ac_flags & EXT4_MB_HINT_FIRST)) {
// 有空闲空间就行
ext4_mb_try_best_found(ac, &e4b);
if (ac->ac_status != AC_STATUS_FOUND) {
/*
再尝试遍历一次所有的block group有空闲空间就行
*/
ac->ac_b_ex.fe_group = 0;
ac->ac_b_ex.fe_start = 0;
ac->ac_b_ex.fe_len = 0;
ac->ac_status = AC_STATUS_CONTINUE;
ac->ac_flags |= EXT4_MB_HINT_FIRST;
cr = 3;
atomic_inc(&sbi->s_mb_lost_chunks);
goto repeat;
}
}
out:
if (!err && ac->ac_status != AC_STATUS_FOUND && first_err)
err = first_err;
return err;
}
ext4_mb_good_group()函数,检查在当前的严苛程度下可否进行分配:
static int ext4_mb_good_group(struct ext4_allocation_context *ac,
ext4_group_t group, int cr)
{
unsigned free, fragments;
int flex_size = ext4_flex_bg_size(EXT4_SB(ac->ac_sb));
struct ext4_group_info *grp = ext4_get_group_info(ac->ac_sb, group);
BUG_ON(cr < 0 || cr >= 4);
free = grp->bb_free;
if (free == 0) // 没有空闲空间了直接返回
return 0;
// 如果空闲空间小于要分配的长度时,只在严苛程度为3,即最低时才往下走去检查
if (cr <= 2 && free < ac->ac_g_ex.fe_len)
return 0;
if (unlikely(EXT4_MB_GRP_BBITMAP_CORRUPT(grp)))
return 0;
// 有必要则初始化block group
if (unlikely(EXT4_MB_GRP_NEED_INIT(grp))) {
int ret = ext4_mb_init_group(ac->ac_sb, group, GFP_NOFS);
if (ret)
return ret;
}
fragments = grp->bb_fragments;
if (fragments == 0) // 没有空闲空间段了,直接返回
return 0;
switch (cr) {
case 0:
BUG_ON(ac->ac_2order == 0);
/* Avoid using the first bg of a flexgroup for data files */
// flex块组的第一个块组一般是给目录和特殊文件用的,当“最严苛的时候”跳过
if ((ac->ac_flags & EXT4_MB_HINT_DATA) &&
(flex_size >= EXT4_FLEX_SIZE_DIR_ALLOC_SCHEME) &&
((group % flex_size) == 0))
return 0;
if ((ac->ac_2order > ac->ac_sb->s_blocksize_bits+1) || // 大于13
(free / fragments) >= ac->ac_g_ex.fe_len) // 或者空闲空间的平均长度大于等于申请的长度,可以进行分配
return 1;
// 如果block group内最大的空闲空间的阶小于要分配的阶则不能分配
if (grp->bb_largest_free_order < ac->ac_2order)
return 0;
return 1;
case 1:
if ((free / fragments) >= ac->ac_g_ex.fe_len) // 空闲空间的平均长度大于等于申请的长度,可以进行分配
return 1;
break;
case 2:
if (free >= ac->ac_g_ex.fe_len) // 空闲空间的总长度大于申请的长度时可进行分配
return 1;
break;
case 3: // 只要有空闲空间就可以进行分配
return 1;
default:
BUG();
}
return 0;
}
ext4_mb_simple_scan_group()函数,当申请的长度刚好是2的N次方时才会调用这个函数:
static noinline_for_stack
void ext4_mb_simple_scan_group(struct ext4_allocation_context *ac,
struct ext4_buddy *e4b)
{
struct super_block *sb = ac->ac_sb;
struct ext4_group_info *grp = e4b->bd_info;
void *buddy;
int i;
int k;
int max;
BUG_ON(ac->ac_2order <= 0);
for (i = ac->ac_2order; i <= sb->s_blocksize_bits + 1; i++) {
if (grp->bb_counters[i] == 0)
continue;
buddy = mb_find_buddy(e4b, i, &max);
BUG_ON(buddy == NULL);
k = mb_find_next_zero_bit(buddy, max, 0);
BUG_ON(k >= max);
ac->ac_found++;
ac->ac_b_ex.fe_len = 1 << i;
ac->ac_b_ex.fe_start = k << i;
ac->ac_b_ex.fe_group = e4b->bd_group;
// 这里更新的是best,也就是最终的分配地方
ext4_mb_use_best_found(ac, e4b);
BUG_ON(ac->ac_b_ex.fe_len != ac->ac_g_ex.fe_len);
if (EXT4_SB(sb)->s_mb_stats)
atomic_inc(&EXT4_SB(sb)->s_bal_2orders);
break;
}
}
ext4_mb_scan_aligned()函数,这是ext4文件系统对raid的优化,针对分配的长度是stripe的整数倍的场景:
static noinline_for_stack
void ext4_mb_scan_aligned(struct ext4_allocation_context *ac,
struct ext4_buddy *e4b)
{
struct super_block *sb = ac->ac_sb;
struct ext4_sb_info *sbi = EXT4_SB(sb);
void *bitmap = e4b->bd_bitmap;
struct ext4_free_extent ex;
ext4_fsblk_t first_group_block;
ext4_fsblk_t a;
ext4_grpblk_t i;
int max;
BUG_ON(sbi->s_stripe == 0);
/* find first stripe-aligned block in group */
first_group_block = ext4_group_first_block_no(sb, e4b->bd_group);
a = first_group_block + sbi->s_stripe - 1;
do_div(a, sbi->s_stripe); // 计算后a表示起始块在第几个stripe
i = (a * sbi->s_stripe) - first_group_block; // 计算后的i为在block group内第一个与stripe对齐的块在block group内的编号
// 在一个cluster的范围内开始寻找
while (i < EXT4_CLUSTERS_PER_GROUP(sb)) {
// block group的block bitmap是从0开始编号的,结合上面对i的注释理解
if (!mb_test_bit(i, bitmap)) {
// 查看从这里起始能否找到一个stripe长度的空闲空间
max = mb_find_extent(e4b, i, sbi->s_stripe, &ex);
if (max >= sbi->s_stripe) { // 找到则置上best
ac->ac_found++;
ex.fe_logical = 0xDEADF00D; /* debug value */
ac->ac_b_ex = ex;
ext4_mb_use_best_found(ac, e4b);
break;
// 虽然调用者要求的是申请stripe的整数倍长度的空间,但是这里一次也只分配一个stripe长度的空间
}
}
i += sbi->s_stripe; // i指向下一个与stripe对齐的块
}
}
ext4_mb_complex_scan_group()函数, 遍历block group内的所有空闲空间段,然后找出最合适的空闲空间段:
static noinline_for_stack
void ext4_mb_complex_scan_group(struct ext4_allocation_context *ac,
struct ext4_buddy *e4b)
{
struct super_block *sb = ac->ac_sb;
void *bitmap = e4b->bd_bitmap;
struct ext4_free_extent ex;
int i;
int free;
free = e4b->bd_info->bb_free;
BUG_ON(free <= 0);
// 从第一个空闲的block开始搜索
i = e4b->bd_info->bb_first_free;
// 遍历搜索最佳的空闲空间,在ext4_mb_measure_extent()函数确定是否为最佳
while (free && ac->ac_status == AC_STATUS_CONTINUE) {
// 每一轮循环开始就找到下一段空闲空间的起始位置,第一轮的时候就是其本身,即第一个空闲空间的起始位置
i = mb_find_next_zero_bit(bitmap,
EXT4_CLUSTERS_PER_GROUP(sb), i);
if (i >= EXT4_CLUSTERS_PER_GROUP(sb)) {
/*
* IF we have corrupt bitmap, we won't find any
* free blocks even though group info says we
* we have free blocks
*/
ext4_grp_locked_error(sb, e4b->bd_group, 0, 0,
"%d free clusters as per "
"group info. But bitmap says 0",
free);
ext4_mark_group_bitmap_corrupted(sb, e4b->bd_group,
EXT4_GROUP_INFO_BBITMAP_CORRUPT);
break;
}
// 返回的ex的fe_len表示的是此次寻找能分配的最大的长度
mb_find_extent(e4b, i, ac->ac_g_ex.fe_len, &ex);
BUG_ON(ex.fe_len <= 0);
if (free < ex.fe_len) {
ext4_grp_locked_error(sb, e4b->bd_group, 0, 0,
"%d free clusters as per "
"group info. But got %d blocks",
free, ex.fe_len);
ext4_mark_group_bitmap_corrupted(sb, e4b->bd_group,
EXT4_GROUP_INFO_BBITMAP_CORRUPT);
/*
* The number of free blocks differs. This mostly
* indicate that the bitmap is corrupt. So exit
* without claiming the space.
*/
break;
}
ex.fe_logical = 0xDEADC0DE; /* debug value */
// 检查是否合适
ext4_mb_measure_extent(ac, &ex, e4b);
// 进入到下一轮寻找
i += ex.fe_len;
free -= ex.fe_len;
}
ext4_mb_check_limits(ac, e4b, 1);
}
ext4_mb_measure_extent()函数,负责判断当前的空闲空间段是否就是分配的最佳的段:
static void ext4_mb_measure_extent(struct ext4_allocation_context *ac,
struct ext4_free_extent *ex,
struct ext4_buddy *e4b)
{
struct ext4_free_extent *bex = &ac->ac_b_ex;
struct ext4_free_extent *gex = &ac->ac_g_ex;
BUG_ON(ex->fe_len <= 0);
BUG_ON(ex->fe_len > EXT4_CLUSTERS_PER_GROUP(ac->ac_sb));
BUG_ON(ex->fe_start >= EXT4_CLUSTERS_PER_GROUP(ac->ac_sb));
BUG_ON(ac->ac_status != AC_STATUS_CONTINUE);
ac->ac_found++;
/*
如果调用者要求直接就是找到的第一个段那么就直接分配
*/
if (unlikely(ac->ac_flags & EXT4_MB_HINT_FIRST)) {
*bex = *ex;
ext4_mb_use_best_found(ac, e4b); // 这里面会把ext4_allocation_context的状态置为FOUND,外面调用的循环自然就停止了。
return;
}
/*
检查是否最佳:
*/
// 如果空闲空间长度刚好跟要求分配的长度一致那么这个就是最佳的
if (ex->fe_len == gex->fe_len) {
*bex = *ex;
ext4_mb_use_best_found(ac, e4b);
return;
}
/*
第一个段进来还没有可比较的,就先保存着
*/
if (bex->fe_len == 0) {
*bex = *ex;
return;
}
/*
* If new found extent is better, store it in the context
*/
if (bex->fe_len < gex->fe_len) {
// 如果前面找到的段的长度小于要求分配的长度,而且当前找到的段的可分配长度比前面找到的要长,那么自然就是比前面的段要更合适一些
if (ex->fe_len > bex->fe_len)
*bex = *ex;
} else if (ex->fe_len > gex->fe_len) {
// 如果当前找到的段的可分配长度已经大于了要求分配的长度,那么就找到分配后剩余的长度最短的段
if (ex->fe_len < bex->fe_len)
*bex = *ex;
}
ext4_mb_check_limits(ac, e4b, 0);
}
ext4_mb_try_best_found()函数,遍历了很久但还是没有找到最佳的分配地点,需要做最后的尝试:
static noinline_for_stack
int ext4_mb_try_best_found(struct ext4_allocation_context *ac,
struct ext4_buddy *e4b)
{
struct ext4_free_extent ex = ac->ac_b_ex;
ext4_group_t group = ex.fe_group;
int max;
int err;
// ac_b_ex可能是在ext4_mb_complex_scan_group()的时候置上的,但没有成为最终的分配地点
BUG_ON(ex.fe_len <= 0);
err = ext4_mb_load_buddy(ac->ac_sb, group, e4b);
if (err)
return err;
// 尝试从这个前面可能找到的ext4_free_extent进行分配
ext4_lock_group(ac->ac_sb, group);
max = mb_find_extent(e4b, ex.fe_start, ex.fe_len, &ex);
if (max > 0) { // 都此时此刻了,有空闲空间就行,能分配多少分配多少了
ac->ac_b_ex = ex;
ext4_mb_use_best_found(ac, e4b);
}
ext4_unlock_group(ac->ac_sb, group);
ext4_mb_unload_buddy(e4b);
return 0;
}
在ext4_mb_regular_allocator()函数的最后,当所有的手段都不能分配到空闲空间,那么会做最后的一搏,将严苛程度置为3,然后回到repeat再一次遍历所有的block group看能否分配。
持久预分配
linux提供了一个非posix标准的接口fallocate()以实现持久预分配,同时还提供了一个posix标准的接口posix_fallocate(),此接口不需要下层文件系统支持持久预分配,而前面的fallocate()需要。
fallocate()从vfs最终会调到ext4文件系统注册的ext4_fallocate()接口,fallocate()提供持久预分配的同时还会提供打洞、清零等操作,这个可以单独开一期分析,但对于持久预分配来说就是调用ext4_map_blocks()函数去分配传入的逻辑空间。
参考资料
https://oenhan.com/ext4-mballoc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号