

mq-deadline调度器原理及源码分析
linux内核块层有kyber、mq-deadline以及bfq三个针对multi queue设计的调度器,这篇文章主要是讲解mq-deadline调度器的原理和源码,分析的内核版本是4.20。
原理
mq-deadline调度器是根据以前的deadline调度器来的,适配了block层的多队列,基本原理和代码都差不多,因此如果熟悉deadline调度器的话,mq-deadline调度器也不在话下。
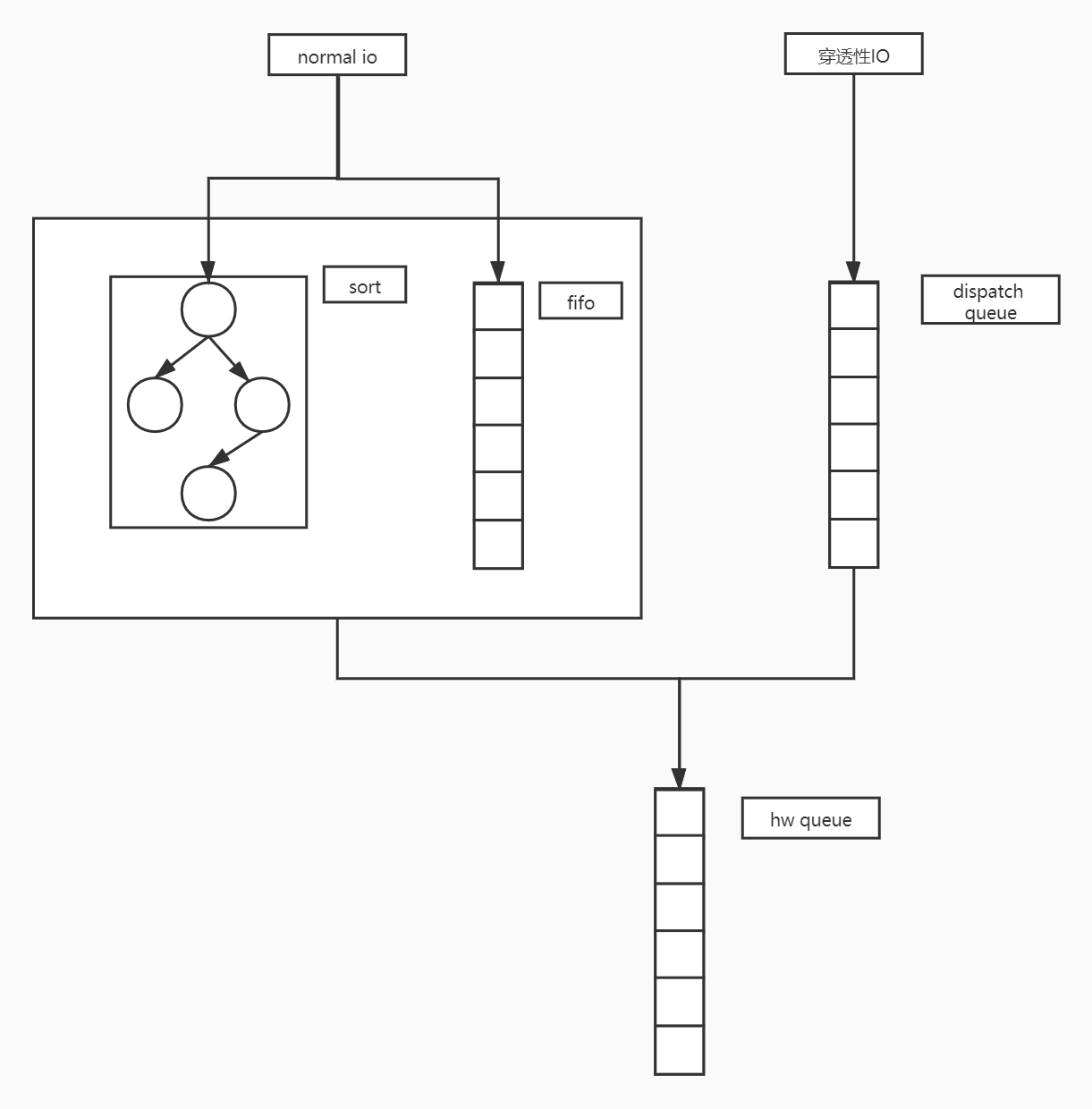
mq-deadline调度器将IO分为read和write两种类型,对于这每种类型的IO有一棵红黑树和一个fifo的队列,红黑树用于将IO按照其访问的LBA排列方便查找合并,fifo队列则记录了io进入mq-deadline调度器的顺序,以提供超时期限的保障。
read类型的IO可以抢write的分发机会,但不可一直抢,有一个计数保证read不会饿死write。
mq-deadline调度器会优先去批量式地分发IO而不去管IO的到期时间,当批量分发到一定的个数再关心到期时间,然后去分发即将到期的IO。
最后mq-deadline针对穿透性IO这种需要尽快发送到设备的IO设置另外一个dispatch队列,然后每次派发的时候都优先派发dispatch队列上的IO。
数据结构
一个块设备对应一个deadline_data,上述的队列也都只存在于deadline_data中。
struct deadline_data {
/*
* run time data
*/
/*
* requests (deadline_rq s) are present on both sort_list and fifo_list
*/
// 这里的数组的下标分别是read(0)和write(1)
struct rb_root sort_list[2]; // IO在红黑树上按照LBA排列
struct list_head fifo_list[2]; // IO在fifo队列上按照进入mq-deadline的先后排列
/*
* next in sort order. read, write or both are NULL
*/
struct request *next_rq[2]; // 批量分发时记录下一个要分发的IO
unsigned int batching; // 批量分发的个数,分发到一定个数就查看到期时间情况
unsigned int starved; // read让write饿的次数,不能超过writes_startved
/*
* settings that change how the i/o scheduler behaves
*/
int fifo_expire[2]; // read和write的到期时间
int fifo_batch; // 批量分发的IO个数的最大值,默认值是16
int writes_starved; // read让write饿的最大次数,默认值是2
int front_merges; // 是否可以向前合并,在bio合并到mq-deadline的时候使用
spinlock_t lock;
spinlock_t zone_lock; //
struct list_head dispatch; // 优先派发的队列,穿透性IO
};
初始化
Init的时候注册调度器
mq-deadline模块初始化注册调度器,包含了mq-deadline的名称、别名、模块、属性以及最重要的操作集。
static int __init deadline_init(void)
{
return elv_register(&mq_deadline);
}
注册的调度器如下:
static struct elevator_type mq_deadline = {
.ops.mq = {
.insert_requests = dd_insert_requests, // 插入request
.dispatch_request = dd_dispatch_request, // 分发request
.prepare_request = dd_prepare_request,
.finish_request = dd_finish_request, // request结束时调用
.next_request = elv_rb_latter_request, // 找到当前request的前一个request
.former_request = elv_rb_former_request, // 找到当前request的后一个request
.bio_merge = dd_bio_merge, // bio合并到mq-deadline的时候调用
.request_merge = dd_request_merge, // 找到一个可以将bio合并进去的request
.requests_merged = dd_merged_requests, // 两个request合并后调用
.request_merged = dd_request_merged, // 将bio合并到request后调用
.has_work = dd_has_work,
.init_sched = dd_init_queue, // 初始化
.exit_sched = dd_exit_queue,
},
.uses_mq = true,
#ifdef CONFIG_BLK_DEBUG_FS
.queue_debugfs_attrs = deadline_queue_debugfs_attrs,
#endif
.elevator_attrs = deadline_attrs,
.elevator_name = "mq-deadline",
.elevator_alias = "deadline",
.elevator_owner = THIS_MODULE,
};
初始化mq-deadline
当启用mq-deadline调度器时会调用其初始化函数dd_init_queue()。
static int dd_init_queue(struct request_queue *q, struct elevator_type *e)
{
struct deadline_data *dd;
struct elevator_queue *eq;
eq = elevator_alloc(q, e);
if (!eq)
return -ENOMEM;
dd = kzalloc_node(sizeof(*dd), GFP_KERNEL, q->node);
if (!dd) {
kobject_put(&eq->kobj);
return -ENOMEM;
}
eq->elevator_data = dd; // 关联deadline_data和elevator_queue
INIT_LIST_HEAD(&dd->fifo_list[READ]);
INIT_LIST_HEAD(&dd->fifo_list[WRITE]);
dd->sort_list[READ] = RB_ROOT;
dd->sort_list[WRITE] = RB_ROOT; // 初始化队列
dd->fifo_expire[READ] = read_expire; // 设置读写的超时时间
dd->fifo_expire[WRITE] = write_expire;
dd->writes_starved = writes_starved;
dd->front_merges = 1; // 初始化是1,还未找到在哪里修改的
dd->fifo_batch = fifo_batch; // 批量分发的IO个数上限
spin_lock_init(&dd->lock);
spin_lock_init(&dd->zone_lock);
INIT_LIST_HEAD(&dd->dispatch); // 初始化dispatch队列
q->elevator = eq; // 关联elevator_queue和request_queue
return 0;
}
bio合并如mq-deadline
到达block层的bio会首先尝试与现有的request进行合并,如果合并不成功再生成request,尝试合并调用的hook是bio_merge,对mq-deadline来说就是dd_bio_merge()函数。
static bool dd_bio_merge(struct blk_mq_hw_ctx *hctx, struct bio *bio)
{
struct request_queue *q = hctx->queue;
struct deadline_data *dd = q->elevator->elevator_data;
struct request *free = NULL;
bool ret;
spin_lock(&dd->lock);
// 调用通用处理流程的合并函数,详解这个函数不在本文范围内,
// 该函数会依次调用hook: request_merge找到一个可以跟bio合并的request
// requests_merged 尝试合并了两个相邻的request之后调用
// request_merged当request成功地与bio或者某个相邻的request合并之后调用
ret = blk_mq_sched_try_merge(q, bio, &free);
spin_unlock(&dd->lock);
if (free)
blk_mq_free_request(free);
return ret;
}
dd_request_merge()函数:
// 找到一个可以跟bio合并的request, 参数rq返回这个request
static int dd_request_merge(struct request_queue *q, struct request **rq,
struct bio *bio)
{
struct deadline_data *dd = q->elevator->elevator_data;
sector_t sector = bio_end_sector(bio);
struct request *__rq;
// front_merges默认是1
if (!dd->front_merges)
return ELEVATOR_NO_MERGE;
// 从红黑树中找到一个起始LBA是bio的结束LBA的request,表明bio可以front merge到request
// bio_data_dir表明bio是read还是write
__rq = elv_rb_find(&dd->sort_list[bio_data_dir(bio)], sector);
if (__rq) {
BUG_ON(sector != blk_rq_pos(__rq));
// 检查是否可以合并
if (elv_bio_merge_ok(__rq, bio)) {
*rq = __rq;
return ELEVATOR_FRONT_MERGE;
}
}
return ELEVATOR_NO_MERGE;
}
当bio成功地合入进了一个request之后,request的请求返回增大了,elv会检查request的前一个request或者后一个request,尝试将这两个request进行合并,那么如何找到当前request的前一个或者后一个呢?
部分调度器在注册的时候会注册next_request和former_request两个hook,用于找到request的后一个或者前一个request,对于mq-deadline来说这两个函数分别为elv_rb_latter_request()和elv_rb_former_request(),这两个函数都是elv的通用函数,通过按照LBA排列的红黑树,可以很方便地找到当前request的前一个或者后一个request。
struct request *elv_rb_latter_request(struct request_queue *q,
struct request *rq)
{
struct rb_node *rbnext = rb_next(&rq->rb_node);
if (rbnext)
return rb_entry_rq(rbnext);
return NULL;
}
struct request *elv_rb_former_request(struct request_queue *q,
struct request *rq)
{
struct rb_node *rbprev = rb_prev(&rq->rb_node);
if (rbprev)
return rb_entry_rq(rbprev);
return NULL;
}
dd_merged_requests()函数
// 将两个request合并后通知调度器
static void dd_merged_requests(struct request_queue *q, struct request *req,
struct request *next)
{
/*
* if next expires before rq, assign its expire time to rq
* and move into next position (next will be deleted) in fifo
*/
if (!list_empty(&req->queuelist) && !list_empty(&next->queuelist)) {
if (time_before((unsigned long)next->fifo_time,
(unsigned long)req->fifo_time)) {
// next是被合并的那个IO,
// 当next的到期时间在req之前时,要将req的到期时间提前到next一样,这样保证next的到期时间,并且要调整req在fifo队列里的位置为next的位置
list_move(&req->queuelist, &next->queuelist);
req->fifo_time = next->fifo_time;
}
}
/*
* kill knowledge of next, this one is a goner
*/
// 将next移除出mq-deadline,因为它已经跟req合并了
deadline_remove_request(q, next);
}
将request移除出mq-deadline:
static inline void
deadline_del_rq_rb(struct deadline_data *dd, struct request *rq)
{
const int data_dir = rq_data_dir(rq);
// 如果移除的是批量下发的下一个request,那么需要找到下一个批量下发的request
if (dd->next_rq[data_dir] == rq)
dd->next_rq[data_dir] = deadline_latter_request(rq);
// 从红黑树移除
elv_rb_del(deadline_rb_root(dd, rq), rq);
}
/*
* remove rq from rbtree and fifo.
*/
static void deadline_remove_request(struct request_queue *q, struct request *rq)
{
struct deadline_data *dd = q->elevator->elevator_data;
// 从fifo队列移除
list_del_init(&rq->queuelist);
/*
* We might not be on the rbtree, if we are doing an insert merge
*/
if (!RB_EMPTY_NODE(&rq->rb_node))
deadline_del_rq_rb(dd, rq); // 从红黑树移除
elv_rqhash_del(q, rq);
if (q->last_merge == rq)
q->last_merge = NULL;
}
deadline_latter_request()函数:
static inline struct request *
deadline_latter_request(struct request *rq)
{
// 红黑树是按照LBA的顺序排列的,因此可以轻松地找到下一个LBA顺序的IO
struct rb_node *node = rb_next(&rq->rb_node);
if (node)
return rb_entry_rq(node);
return NULL;
}
最后调用dd_request_merged()函数:
static void dd_request_merged(struct request_queue *q, struct request *req,
enum elv_merge type)
{
struct deadline_data *dd = q->elevator->elevator_data;
/*
* if the merge was a front merge, we need to reposition request
*/
// request完成了合并(无论是bio合并到了request还是与其他的某个request合并,亦或者都发生了),此时request的起始LBA发生了变化,因此在红黑树上的位置也要发生改变
if (type == ELEVATOR_FRONT_MERGE) {
// 先将request取下
elv_rb_del(deadline_rb_root(dd, req), req);
// 再插入到新的位置
deadline_add_rq_rb(dd, req);
}
}
deadline_add_rq_rb()函数
static void
deadline_add_rq_rb(struct deadline_data *dd, struct request *rq)
{
struct rb_root *root = deadline_rb_root(dd, rq);
elv_rb_add(root, rq);
}
request插入到mq-deadline
当bio不能合并到现有的request时,会生成一个新的request,然后将request插入到mq-deadline中等待调度。
dd_insert_requests()函数:
static void dd_insert_requests(struct blk_mq_hw_ctx *hctx,
struct list_head *list, bool at_head)
{
struct request_queue *q = hctx->queue;
struct deadline_data *dd = q->elevator->elevator_data;
spin_lock(&dd->lock);
while (!list_empty(list)) {
struct request *rq;
// 将request取出
rq = list_first_entry(list, struct request, queuelist);
list_del_init(&rq->queuelist);
// 插入到mq-deadline
dd_insert_request(hctx, rq, at_head);
}
spin_unlock(&dd->lock);
}
dd_insert_request()函数:
static void dd_insert_request(struct blk_mq_hw_ctx *hctx, struct request *rq,
bool at_head)
{
struct request_queue *q = hctx->queue;
struct deadline_data *dd = q->elevator->elevator_data;
const int data_dir = rq_data_dir(rq);
/*
* This may be a requeue of a write request that has locked its
* target zone. If it is the case, this releases the zone lock.
*/
// 插入之前如果是持有了zone write lock的要解锁,关于zone看下面的简短解释
blk_req_zone_write_unlock(rq);
if (blk_mq_sched_try_insert_merge(q, rq))
return;
blk_mq_sched_request_inserted(rq);
// 对于穿透性IO,直接插入到dispatch队列
if (at_head || blk_rq_is_passthrough(rq)) {
if (at_head)
list_add(&rq->queuelist, &dd->dispatch);
else
list_add_tail(&rq->queuelist, &dd->dispatch);
} else {
// 普通io插入到mq-deadline的红黑树
deadline_add_rq_rb(dd, rq);
if (rq_mergeable(rq)) {
elv_rqhash_add(q, rq);
if (!q->last_merge)
q->last_merge = rq;
}
/*
* set expire time and add to fifo list
*/
// 设置request的超时时间
rq->fifo_time = jiffies + dd->fifo_expire[data_dir];
// 将request同时插入到fifo队列
list_add_tail(&rq->queuelist, &dd->fifo_list[data_dir]);
}
}
这里插入一下关于“zoned block device”,为了提高存储密度,有些设备被划分为若干个区域,这些区域的写IO只能顺序地写,不能随机写,能够随机读。因此这个区域的写IO必须是顺序的,mq-deadline的调度方式会打破IO来的顺序,因此需要在各个流程特殊处理zoned的情况。
// 最后将request插入到mq-deadline的红黑树
static void
deadline_add_rq_rb(struct deadline_data *dd, struct request *rq)
{
struct rb_root *root = deadline_rb_root(dd, rq);
elv_rb_add(root, rq);
}
mq-deadline分发request
启动硬件队列派发后会调用调度器注册的hook:dispatch_request接口获得一个可以派发的request,mq-deadline注册的派发函数为:dd_dispatch_request()。
static struct request *dd_dispatch_request(struct blk_mq_hw_ctx *hctx)
{
struct deadline_data *dd = hctx->queue->elevator->elevator_data;
struct request *rq;
// 由于mq-deadline是全局(块设备局域内)的,因此这里需要加锁
spin_lock(&dd->lock);
rq = __dd_dispatch_request(dd);
spin_unlock(&dd->lock);
return rq;
}
__dd_dispatch_request()函数:
static struct request *__dd_dispatch_request(struct deadline_data *dd)
{
struct request *rq, *next_rq;
bool reads, writes;
int data_dir;
// 如果dispatch队列不为空,则优先派发dispatch队列上的穿透性IO
if (!list_empty(&dd->dispatch)) {
rq = list_first_entry(&dd->dispatch, struct request, queuelist);
list_del_init(&rq->queuelist);
goto done;
}
// 看read队列和write队列是否是空的
reads = !list_empty(&dd->fifo_list[READ]);
writes = !list_empty(&dd->fifo_list[WRITE]);
/*
* batches are currently reads XOR writes
*/
// 批量派发,按照request的LBA顺序依次派发,先尝试从write队列获取批量派发的下一个request,获取不到则尝试从read队列获取。
rq = deadline_next_request(dd, WRITE);
if (!rq)
rq = deadline_next_request(dd, READ);
// 如果批量派发的个数在规定限制内,则可以派发,否则需要检查fifo有无到期的IO
if (rq && dd->batching < dd->fifo_batch)
/* we have a next request are still entitled to batch */
goto dispatch_request;
/*
* at this point we are not running a batch. select the appropriate
* data direction (read / write)
*/
// 优先看read队列是否由到期的IO
if (reads) {
BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[READ]));
// 如果write队列有到期的IO,并且read让write“饥饿”的次数超过了2次,则去派发write
// 否则派发read
if (deadline_fifo_request(dd, WRITE) &&
(dd->starved++ >= dd->writes_starved))
goto dispatch_writes;
data_dir = READ;
goto dispatch_find_request;
}
/*
* there are either no reads or writes have been starved
*/
// 派发write,并将starved置为0,表示read又可以抢占write了
if (writes) {
dispatch_writes:
BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[WRITE]));
dd->starved = 0;
data_dir = WRITE;
goto dispatch_find_request;
}
return NULL;
// 无论是派发read还是write,都走到这里
dispatch_find_request:
/*
* we are not running a batch, find best request for selected data_dir
*/
// 先获取批量派发的下一个request
next_rq = deadline_next_request(dd, data_dir);
// 如果队列有到期的IO,或者批量派发没有下一个IO了则从fifo队列里取出第一个IO来派发
if (deadline_check_fifo(dd, data_dir) || !next_rq) {
/*
* A deadline has expired, the last request was in the other
* direction, or we have run out of higher-sectored requests.
* Start again from the request with the earliest expiry time.
*/
rq = deadline_fifo_request(dd, data_dir);
} else {
/*
* The last req was the same dir and we have a next request in
* sort order. No expired requests so continue on from here.
*/
// 否则派发批量IO
rq = next_rq;
}
/*
* For a zoned block device, if we only have writes queued and none of
* them can be dispatched, rq will be NULL.
*/
if (!rq)
return NULL;
dd->batching = 0;
dispatch_request:
/*
* rq is the selected appropriate request.
*/
dd->batching++;
deadline_move_request(dd, rq); // 将IO从mq-deadline移除
done:
/*
* If the request needs its target zone locked, do it.
*/
// 如果访问的是zoned区域,则必须加上zoned锁
blk_req_zone_write_lock(rq);
rq->rq_flags |= RQF_STARTED;
return rq;
}
deadline_next_request()函数:
// 找到批量派发的下一个IO
static struct request *
deadline_next_request(struct deadline_data *dd, int data_dir)
{
struct request *rq;
unsigned long flags;
if (WARN_ON_ONCE(data_dir != READ && data_dir != WRITE))
return NULL;
// 批量派发的下一个IO已经被置上了
rq = dd->next_rq[data_dir];
if (!rq)
return NULL;
// 如果批量派发的是读IO,或者是写但是这个写没有zoned属性,则直接派发
if (data_dir == READ || !blk_queue_is_zoned(rq->q))
return rq;
/*
* Look for a write request that can be dispatched, that is one with
* an unlocked target zone.
*/
// 如果是写IO,则需要看是否加了zoned锁,如果没有加则不能派发,找到一个加了zoned锁的写IO派发
// 因为zoned device区域的写IO必须是顺序的,不能打乱顺序
spin_lock_irqsave(&dd->zone_lock, flags);
while (rq) {
if (blk_req_can_dispatch_to_zone(rq))
break;
rq = deadline_latter_request(rq);
}
spin_unlock_irqrestore(&dd->zone_lock, flags);
return rq;
}
deadline_check_fifo()函数:
static inline int deadline_check_fifo(struct deadline_data *dd, int ddir)
{
// 判断fifo队列的第一个IO是否过期
struct request *rq = rq_entry_fifo(dd->fifo_list[ddir].next);
/*
* rq is expired!
*/
if (time_after_eq(jiffies, (unsigned long)rq->fifo_time))
return 1;
return 0;
}
deadline_fifo_request()函数:
static struct request *
deadline_fifo_request(struct deadline_data *dd, int data_dir)
{
struct request *rq;
unsigned long flags;
if (WARN_ON_ONCE(data_dir != READ && data_dir != WRITE))
return NULL;
if (list_empty(&dd->fifo_list[data_dir]))
return NULL;
// 跟deadline_next_request的解释一样的
rq = rq_entry_fifo(dd->fifo_list[data_dir].next);
if (data_dir == READ || !blk_queue_is_zoned(rq->q))
return rq;
/*
* Look for a write request that can be dispatched, that is one with
* an unlocked target zone.
*/
spin_lock_irqsave(&dd->zone_lock, flags);
list_for_each_entry(rq, &dd->fifo_list[WRITE], queuelist) {
if (blk_req_can_dispatch_to_zone(rq))
goto out;
}
rq = NULL;
out:
spin_unlock_irqrestore(&dd->zone_lock, flags);
return rq;
}
request结束
request结束时调用:
static void dd_finish_request(struct request *rq)
{
struct request_queue *q = rq->q;
// 写访问结束要释放zoned锁,如果有必要的话
if (blk_queue_is_zoned(q)) {
struct deadline_data *dd = q->elevator->elevator_data;
unsigned long flags;
spin_lock_irqsave(&dd->zone_lock, flags);
blk_req_zone_write_unlock(rq);
spin_unlock_irqrestore(&dd->zone_lock, flags);
}
}
mq-deadline退出
static void dd_exit_queue(struct elevator_queue *e)
{
struct deadline_data *dd = e->elevator_data;
BUG_ON(!list_empty(&dd->fifo_list[READ]));
BUG_ON(!list_empty(&dd->fifo_list[WRITE]));
// 释放掉init时申请的内存
kfree(dd);
}
总结
mq-deadline适合于对实时性敏感的程序,它能保证IO在规定的时间内能下发下去,如果下层设备不出问题那么就能保证IO能够在期限内做出响应。

