

kyber调度器原理及源码分析
linux内核块层有kyber、mq-deadline以及bfq三个针对multi queue设计的调度器,这篇文章主要是讲解kyber调度器的原理和源码,分析的内核版本是4.20。
原理
我们知道当Block层不使用任何的调度器的时候,调度队列是按照每个cpu核一个软队列,一定数量的硬队列,并将软队列和硬队列建立一定的映射关系“map”来调度IO的,通过当前的cpu_id能找到per_cpu的软队列,在软队列里面完成插入、合并等动作,然后通过map[cpu_id]找到其映射的硬队列,从而将IO分发到硬队列,最后硬队列将IO下发到驱动层,由驱动层将IO通过某个总线(PCIe、FC、RoCE等)发送到设备层。
当kyber调度器启用时,kyber舍弃软队列,创建read、write、discard、other四个队列将IO分类处理。kyber不是消耗光了某个队列再去分发下一个队列,而是消耗到一定的个数就切换到下一个队列,从而防止后面的队列被饿死,这个个数分别是16、8、1、1,也就是分发了16个读IO之后去分发写,分发了8个写之后再分发一个discard,最后分发一个other的IO,以此类推循环。
kyber是怎么找到应该往哪个硬队列分发呢?
答案是根据当前cpu_id找到软队列,然后通过记录在软队列里面的“该软队列在其对应的硬队列里面的所有跟这个硬队列关联的软队列的编号”就能找到其对应的硬队列。前面这句话有点绕,解释一下,系统内最好的情况下是软队列个数等于硬队列个数,这样软队列和硬队列就能一一对应,但是通常情况下受限于实际的块设备的处理能力,硬队列个数往往小于软队列的个数,因此需要将多个软队列跟一个硬队列映射绑定,形成多对一的关系,在硬队列里面有个数组struct blk_mq_ctx ctxs就记录了该硬队列对应的所有软队列,其下标则存在于软队列结构体里面unsigned int index_hw,详细可参考源码函数blk_mq_map_swqueue()。
下面说说kyber的这个“分发队列”,让人反直觉的是request(block层io结构体)不是直接insert到分发队列的,而是先insert到“暂存队列”(我们暂时给它这么个名字,后面有详细的结构体),在暂存队列IO被合并、分类,然后当分发队列为空而需要分发一个IO的时候就会将暂存队列的IO都挂到分发队列上,然后选择一个IO分发到硬队列。
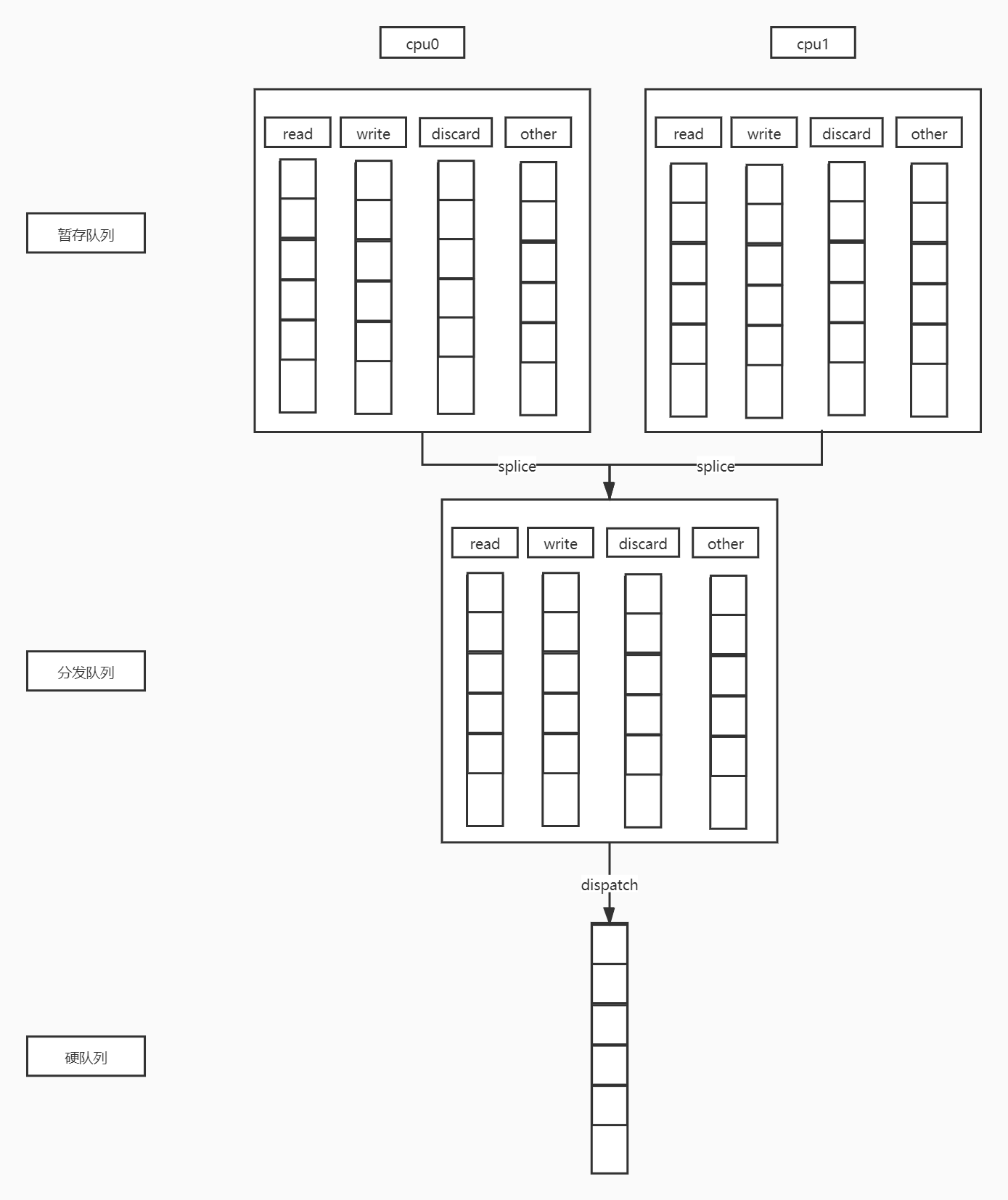
图中我们假设cpu0、cpu1对应这个硬队列。
挂入分发队列的IO个数理论是无限的,虽然每轮只会分发固定数量的IO,但是一轮循环完毕就会立马进行下一轮循环,而此时前面分发的IO可能都还没有回来,就没有起到控制的作用了。kyber针对read、write、discard、other分别设置了总的token数目,分别为256、128、64、16,当要分发一个IO到硬队列的时候,先得拿到这个token,然后才能分发,如果当前token已经耗光,也就是说底层硬处理地慢而上层下发地快了,就要将当前的分发队列挂起,在下层的某个IO执行完毕回来后看这个IO的类型的分发队列是否挂起的,有则将其唤醒去分发IO。
此外kyber还会统计IO的时延,并且针对read、write、discard设置了时延参考值,分别为2000000nsec、10000000nsec、5000000nsec。kyber通过将统计的时延与参考值进行对比,动态地调整每种类型IO的token数目,以求公平。
数据结构
kyber_queue_data
kyber_queue_data是kyber的主要数据结构之一,当将块设备的调度器切换到kyber时就会生成这样的结构体存放在elevator_queue的elevator_data中,通过request_queue可以找到elevator_queue,自然就能找到kyber_queue_data。
struct kyber_queue_data {
struct request_queue *q; // 块设备对应一个request_queue,也就对应一个kyber_queue_data
/*
* Each scheduling domain has a limited number of in-flight requests
* device-wide, limited by these tokens.
*/
// 每种队列的token占用情况,分发IO时从这里申请
struct sbitmap_queue domain_tokens[KYBER_NUM_DOMAINS];
/*
* Async request percentage, converted to per-word depth for
* sbitmap_get_shallow().
*/
// 用该值限制异步请求的带宽,防止同步请求被饿死
unsigned int async_depth;
// per_cpu地统计时延信息,IO完成时就会统计时延到这里
struct kyber_cpu_latency __percpu *cpu_latency;
/* Timer for stats aggregation and adjusting domain tokens. */
// 有一个timer,每隔一段时间统计一下时延情况,根据统计情况调整token数量
struct timer_list timer;
// 上面的timer每隔一段时间会将per_cpu统计的时延加到这里面计算新的token数量
unsigned int latency_buckets[KYBER_OTHER][2][KYBER_LATENCY_BUCKETS];
// 记录上一次调整token的时间
unsigned long latency_timeout[KYBER_OTHER];
// 记录上一次timer得到的时延好坏结果,如果下一次timer的时候时延的样本数量不够则用这一次的
// 下一次timer如果采用了这一次计算的延时好坏结果,则将其值置为-1,不再使用,只使用一次
int domain_p99[KYBER_OTHER];
/* Target latencies in nanoseconds. */
// 每种IO类型的时延参考值
u64 latency_targets[KYBER_OTHER];
};
kyber_hctx_data
存放于硬队列blk_mq_hw_ctx的sched_data字段,包含了原理一章中提到的“暂存队列”和“分发队列”。
struct kyber_hctx_data {
spinlock_t lock;
struct list_head rqs[KYBER_NUM_DOMAINS]; // 分发队列,IO从这个队列提交到硬队列
unsigned int cur_domain; // 当前分发的是read、write、discard还是other
unsigned int batching;
struct kyber_ctx_queue *kcqs; // 暂存队列,硬队列对应的软队列有多少个就有多少个暂存队列
// kcq_map用于表示暂存队列上是否有IO
struct sbitmap kcq_map[KYBER_NUM_DOMAINS];
// 当token耗光的时候,分发队列进入wait状态,等待回来的io释放token将之唤醒,以下是这个流程需要用到的结构
wait_queue_entry_t domain_wait[KYBER_NUM_DOMAINS];
struct sbq_wait_state *domain_ws[KYBER_NUM_DOMAINS];
atomic_t wait_index[KYBER_NUM_DOMAINS];
};
struct kyber_ctx_queue { // 暂存队列,由此可见一个暂存队列就有4个种类的队列
/*
* Used to ensure operations on rq_list and kcq_map to be an atmoic one.
* Also protect the rqs on rq_list when merge.
*/
spinlock_t lock;
struct list_head rq_list[KYBER_NUM_DOMAINS];
} ____cacheline_aligned_in_smp;
初始化
初始化kyber
当kyber模块注册时回调用kyber_init()函数注册kyber给elevator,包括kyber的名字、属性、debugfs相关信息、owner以及最重要的hook。
static int __init kyber_init(void)
{
return elv_register(&kyber_sched);
}
static struct elevator_type kyber_sched = { // 这些hook在后续的章节中会一一讲到
.ops.mq = {
.init_sched = kyber_init_sched,
.exit_sched = kyber_exit_sched,
.init_hctx = kyber_init_hctx,
.exit_hctx = kyber_exit_hctx, // 以上是初始化和释放kyber内部结构体的函数
.limit_depth = kyber_limit_depth, // 限制request队列的深度
.bio_merge = kyber_bio_merge, // 将bio合并到kyber
.prepare_request = kyber_prepare_request, // 初始化request时调用
.insert_requests = kyber_insert_requests, // 将request插入到kyber
.finish_request = kyber_finish_request, // 释放request时调用
.requeue_request = kyber_finish_request, // 将request重新入队时调用
.completed_request = kyber_completed_request, // request完成时调用
.dispatch_request = kyber_dispatch_request, // 分发request
.has_work = kyber_has_work, // kyber是否有未分发的request
},
.uses_mq = true,
#ifdef CONFIG_BLK_DEBUG_FS
.queue_debugfs_attrs = kyber_queue_debugfs_attrs,
.hctx_debugfs_attrs = kyber_hctx_debugfs_attrs,
#endif
.elevator_attrs = kyber_sched_attrs,
.elevator_name = "kyber",
.elevator_owner = THIS_MODULE,
};
初始化kyber_queue_data
当块设备的调度器被设置成kyber时会调用kyber_init_sched()函数初始化kyber_queue_data,将kyber_queue_data与request_queue绑定。
static int kyber_init_sched(struct request_queue *q, struct elevator_type *e)
{
struct kyber_queue_data *kqd;
struct elevator_queue *eq;
eq = elevator_alloc(q, e); // 申请电梯队列结构,request可通过该结构访问到kyber_queue_data
if (!eq)
return -ENOMEM;
kqd = kyber_queue_data_alloc(q); // 申请kyber_queue_data并初始化
if (IS_ERR(kqd)) {
kobject_put(&eq->kobj);
return PTR_ERR(kqd);
}
blk_stat_enable_accounting(q);
eq->elevator_data = kqd; // 将kyber_queue_data和elevator_queue绑定
q->elevator = eq; // 将elevator_queue和request_queue绑定
return 0;
}
kyber_queue_data_alloc函数
static struct kyber_queue_data *kyber_queue_data_alloc(struct request_queue *q)
{
struct kyber_queue_data *kqd;
unsigned int shift;
int ret = -ENOMEM;
int i;
kqd = kzalloc_node(sizeof(*kqd), GFP_KERNEL, q->node);
if (!kqd)
goto err;
kqd->q = q; // 将kyber_queue_data与request_queue绑定
// 初始化per_cpu的时延统计
kqd->cpu_latency = alloc_percpu_gfp(struct kyber_cpu_latency,
GFP_KERNEL | __GFP_ZERO);
if (!kqd->cpu_latency)
goto err_kqd;
// 初始化时延统计timer
// kyber_timer_fn会将所有per_cpu的时延统计加起来,然后通过一定的算法调整每个类型队列的 token数目
timer_setup(&kqd->timer, kyber_timer_fn, 0);
// 初始化每种队列的token数,kyber_depth全局变量显示为256、128、64、16
// token的申请、挂起、释放是通过sbitmap实现的
for (i = 0; i < KYBER_NUM_DOMAINS; i++) {
WARN_ON(!kyber_depth[i]);
WARN_ON(!kyber_batch_size[i]);
ret = sbitmap_queue_init_node(&kqd->domain_tokens[i],
kyber_depth[i], -1, false,
GFP_KERNEL, q->node);
if (ret) {
while (--i >= 0)
sbitmap_queue_free(&kqd->domain_tokens[i]);
goto err_buckets;
}
}
// 初始化总的时延统计和每种队列的时延参考值(kyber_latency_targets)
for (i = 0; i < KYBER_OTHER; i++) {
kqd->domain_p99[i] = -1;
kqd->latency_targets[i] = kyber_latency_targets[i];
}
shift = kyber_sched_tags_shift(q);
// 限制异步IO的带宽为百分之七十五,留百分之二十五给同步IO,防止同步IO被饿死
kqd->async_depth = (1U << shift) * KYBER_ASYNC_PERCENT / 100U;
return kqd;
err_buckets:
free_percpu(kqd->cpu_latency);
err_kqd:
kfree(kqd);
err:
return ERR_PTR(ret);
}
初始化kyber_hctx_data
static int kyber_init_hctx(struct blk_mq_hw_ctx *hctx, unsigned int hctx_idx)
{
struct kyber_queue_data *kqd = hctx->queue->elevator->elevator_data;
struct kyber_hctx_data *khd;
int i;
// 申请kyber_hctx_data
khd = kmalloc_node(sizeof(*khd), GFP_KERNEL, hctx->numa_node);
if (!khd)
return -ENOMEM;
// 申请hctx->nr_ctx个kyber_ctx_queue(暂存队列)
// hctx->nr_ctx就是与硬队列对应的软队列的个数
khd->kcqs = kmalloc_array_node(hctx->nr_ctx,
sizeof(struct kyber_ctx_queue),
GFP_KERNEL, hctx->numa_node);
if (!khd->kcqs)
goto err_khd;
// 初始化暂存队列
for (i = 0; i < hctx->nr_ctx; i++)
kyber_ctx_queue_init(&khd->kcqs[i]);
// 初始化kcq_map,用来记录暂存队列上是否有IO挂着,如果有当分发队列为空时就从暂存队列将IO都取到分发队列。
for (i = 0; i < KYBER_NUM_DOMAINS; i++) {
if (sbitmap_init_node(&khd->kcq_map[i], hctx->nr_ctx,
ilog2(8), GFP_KERNEL, hctx->numa_node)) {
while (--i >= 0)
sbitmap_free(&khd->kcq_map[i]);
goto err_kcqs;
}
}
spin_lock_init(&khd->lock);
for (i = 0; i < KYBER_NUM_DOMAINS; i++) {
// 初始化分发队列
INIT_LIST_HEAD(&khd->rqs[i]);
// 初始化token消耗完了时挂起的IO被唤醒的函数
init_waitqueue_func_entry(&khd->domain_wait[i],
kyber_domain_wake);
khd->domain_wait[i].private = hctx;
// 挂起的IO就挂在这里
INIT_LIST_HEAD(&khd->domain_wait[i].entry);
atomic_set(&khd->wait_index[i], 0);
}
khd->cur_domain = 0;
khd->batching = 0;
hctx->sched_data = khd;
sbitmap_queue_min_shallow_depth(&hctx->sched_tags->bitmap_tags,
kqd->async_depth);
return 0;
err_kcqs:
kfree(khd->kcqs);
err_khd:
kfree(khd);
return -ENOMEM;
}
bio合并入kyber
当一个bio来到块层时,首先看看这个bio是否能够合并到当前已有的request里面。
static bool kyber_bio_merge(struct blk_mq_hw_ctx *hctx, struct bio *bio)
{
struct kyber_hctx_data *khd = hctx->sched_data;
struct blk_mq_ctx *ctx = blk_mq_get_ctx(hctx->queue);
// 根据软队列在硬队列里的下标找到应该合并哪个暂存队列
struct kyber_ctx_queue *kcq = &khd->kcqs[ctx->index_hw];
// 根据op flag找到是read、write、discard还是other
unsigned int sched_domain = kyber_sched_domain(bio->bi_opf);
// 是什么类型的IO就尝试合并到什么类型的暂存队列
struct list_head *rq_list = &kcq->rq_list[sched_domain];
bool merged;
spin_lock(&kcq->lock);
// 调用block层通用函数去合并bio到某个request
// blk_mq_bio_list_merge会从后往前遍历队列,检查8次能否合并
merged = blk_mq_bio_list_merge(hctx->queue, rq_list, bio);
spin_unlock(&kcq->lock);
blk_mq_put_ctx(ctx);
return merged;
}
request插入到kyber
当发现bio并不能合并到已有的request时,根据这个bio生成一个新的request,并且将这个request插入到kyber当前的队列里面。
生成时调用prepare函数进行request的调度器相关的初始化。
static void kyber_prepare_request(struct request *rq, struct bio *bio)
{
// 设置token为-1,表示还未分配token
rq_set_domain_token(rq, -1);
}
插入到相应的队列上:
static void kyber_insert_requests(struct blk_mq_hw_ctx *hctx,
struct list_head *rq_list, bool at_head)
{
struct kyber_hctx_data *khd = hctx->sched_data;
struct request *rq, *next;
list_for_each_entry_safe(rq, next, rq_list, queuelist) {
// 与bio合并时同理找到sched_domain和kyber_ctx_queue
unsigned int sched_domain = kyber_sched_domain(rq->cmd_flags);
struct kyber_ctx_queue *kcq = &khd->kcqs[rq->mq_ctx->index_hw];
struct list_head *head = &kcq->rq_list[sched_domain];
spin_lock(&kcq->lock);
// 将request插入到队列上
if (at_head)
list_move(&rq->queuelist, head);
else
list_move_tail(&rq->queuelist, head);
// 设置bit表示暂存队列上有request
sbitmap_set_bit(&khd->kcq_map[sched_domain],
rq->mq_ctx->index_hw);
blk_mq_sched_request_inserted(rq);
spin_unlock(&kcq->lock);
}
}
kyber分发request
kyber注册的分发hook为kyber_dispatch_request()函数。kyber采用round robin的方式遍历分发队列的read、write、discard、other队列,选择一个IO分发到硬队列,当分发队列上没有IO时会遍历与这个分发队列相关联的所有暂存队列,将暂存队列上的所有IO都转到分发队列上,然后再看有没有IO可以分发的。
static struct request *kyber_dispatch_request(struct blk_mq_hw_ctx *hctx)
{
struct kyber_queue_data *kqd = hctx->queue->elevator->elevator_data;
struct kyber_hctx_data *khd = hctx->sched_data;
struct request *rq;
int i;
spin_lock(&khd->lock);
/*
* First, if we are still entitled to batch, try to dispatch a request
* from the batch.
*/
// 如果当前队列派发的IO个数还没有达到最大值则继续派发当前队列的IO
if (khd->batching < kyber_batch_size[khd->cur_domain]) {
rq = kyber_dispatch_cur_domain(kqd, khd, hctx);
if (rq)
goto out;
}
/*
* Either,
* 1. We were no longer entitled to a batch.
* 2. The domain we were batching didn't have any requests.
* 3. The domain we were batching was out of tokens.
*
* Start another batch. Note that this wraps back around to the original
* domain if no other domains have requests or tokens.
*/
// 否则将batching置为0,选择下一个派发的队列,如果当前已经是other队列了,
// 则跳到第一个的read队列
khd->batching = 0;
for (i = 0; i < KYBER_NUM_DOMAINS; i++) {
if (khd->cur_domain == KYBER_NUM_DOMAINS - 1)
khd->cur_domain = 0;
else
khd->cur_domain++;
rq = kyber_dispatch_cur_domain(kqd, khd, hctx);
if (rq)
goto out;
}
rq = NULL;
out:
spin_unlock(&khd->lock);
return rq;
}
kyber_dispatch_cur_domain()函数
static struct request *
kyber_dispatch_cur_domain(struct kyber_queue_data *kqd,
struct kyber_hctx_data *khd,
struct blk_mq_hw_ctx *hctx)
{
struct list_head *rqs;
struct request *rq;
int nr;
// 获取当前的分发队列
rqs = &khd->rqs[khd->cur_domain];
/*
* If we already have a flushed request, then we just need to get a
* token for it. Otherwise, if there are pending requests in the kcqs,
* flush the kcqs, but only if we can get a token. If not, we should
* leave the requests in the kcqs so that they can be merged. Note that
* khd->lock serializes the flushes, so if we observed any bit set in
* the kcq_map, we will always get a request.
*/
// 选择队列里面第一个IO
rq = list_first_entry_or_null(rqs, struct request, queuelist);
if (rq) {
// 获取token
nr = kyber_get_domain_token(kqd, khd, hctx);
if (nr >= 0) {
// 获取到了token
khd->batching++;
// 将token保存在request的priv字段里面
rq_set_domain_token(rq, nr);
// 从分发队列上摘链
list_del_init(&rq->queuelist);
return rq;
} else {
trace_kyber_throttled(kqd->q,
kyber_domain_names[khd->cur_domain]);
}
// kcq_map的bit位被设置表示当前分发的IO类型在暂存队列是有IO的
// kcq_map在insert request的时候置的
} else if (sbitmap_any_bit_set(&khd->kcq_map[khd->cur_domain])) {
nr = kyber_get_domain_token(kqd, khd, hctx);
if (nr >= 0) {
// 暂存队列有IO,并且当前IO类型的token还没有被消耗完
// 将暂存队列的IO转到分发队列上
kyber_flush_busy_kcqs(khd, khd->cur_domain, rqs);
// IO转到分发队列后肯定能获取到IO进行分发
rq = list_first_entry(rqs, struct request, queuelist);
khd->batching++;
rq_set_domain_token(rq, nr);
list_del_init(&rq->queuelist);
return rq;
} else {
trace_kyber_throttled(kqd->q,
kyber_domain_names[khd->cur_domain]);
}
}
/* There were either no pending requests or no tokens. */
return NULL;
}
kyber_get_domain_token()函数
static int kyber_get_domain_token(struct kyber_queue_data *kqd,
struct kyber_hctx_data *khd,
struct blk_mq_hw_ctx *hctx)
{
unsigned int sched_domain = khd->cur_domain;
// 根据当前分发的IO类型找到申请token的sbitmap_queue
struct sbitmap_queue *domain_tokens = &kqd->domain_tokens[sched_domain];
// 用于将当前分发队列挂到等待队列的结构
wait_queue_entry_t *wait = &khd->domain_wait[sched_domain];
struct sbq_wait_state *ws;
int nr;
// 从sbitmap_queue获取一个没有在用的token
nr = __sbitmap_queue_get(domain_tokens);
/*
* If we failed to get a domain token, make sure the hardware queue is
* run when one becomes available. Note that this is serialized on
* khd->lock, but we still need to be careful about the waker.
*/
// nr < 0表示没有获取到token,并且当前分发队列没有被挂起
if (nr < 0 && list_empty_careful(&wait->entry)) {
ws = sbq_wait_ptr(domain_tokens,
&khd->wait_index[sched_domain]);
khd->domain_ws[sched_domain] = ws;
// 将当前的分发队列挂到相应的等待队列
add_wait_queue(&ws->wait, wait);
/*
* Try again in case a token was freed before we got on the wait
* queue.
*/
// 可能在挂起的时候有IO回来释放了token,在挂起之后再尝试一次看能否获取到token
// 如果能获取到则从等待队列上取下
nr = __sbitmap_queue_get(domain_tokens);
}
/*
* If we got a token while we were on the wait queue, remove ourselves
* from the wait queue to ensure that all wake ups make forward
* progress. It's possible that the waker already deleted the entry
* between the !list_empty_careful() check and us grabbing the lock, but
* list_del_init() is okay with that.
*/
// 如果获取到了token,并且分发队列是被挂起的
if (nr >= 0 && !list_empty_careful(&wait->entry)) {
ws = khd->domain_ws[sched_domain];
spin_lock_irq(&ws->wait.lock);
// 将分发队列从等待队列上摘下
list_del_init(&wait->entry);
spin_unlock_irq(&ws->wait.lock);
}
return nr;
}
kyber_flush_busy_kcqs()函数
static void kyber_flush_busy_kcqs(struct kyber_hctx_data *khd,
unsigned int sched_domain,
struct list_head *list)
{
struct flush_kcq_data data = {
.khd = khd,
.sched_domain = sched_domain,
.list = list,
};
// 这个函数会遍历当前IO类型的kcq_map的每一个bit,
// 然后执行flush_busy_kcq函数将暂存队列的IO都摘到分发队列上
// 我们知道一个bit代表一个跟硬队列对应的CPU核
sbitmap_for_each_set(&khd->kcq_map[sched_domain],
flush_busy_kcq, &data);
}
// bitnr就代表是跟硬队列对应的第几个cpu核
static bool flush_busy_kcq(struct sbitmap *sb, unsigned int bitnr, void *data)
{
struct flush_kcq_data *flush_data = data;
// 获取到这个核的暂存队列
struct kyber_ctx_queue *kcq = &flush_data->khd->kcqs[bitnr];
spin_lock(&kcq->lock);
// 将暂存队列的sched_domain IO种类的队列上的IO都摘到分发队列去,
// sched_domain是kyber_flush_busy_kcqs函数传入的
list_splice_tail_init(&kcq->rq_list[flush_data->sched_domain],
flush_data->list);
// 清理到bit位,表示当前这个核的这个IO类型的暂存队列已经没有IO了
sbitmap_clear_bit(sb, bitnr);
spin_unlock(&kcq->lock);
return true;
}
IO结束的时候释放token,同时这也是kyber的requeue操作的hook,重新进入队列要释放掉已经拿到的token。
static void kyber_finish_request(struct request *rq)
{
struct kyber_queue_data *kqd = rq->q->elevator->elevator_data;
// 释放掉request的priv字段记录的token
rq_clear_domain_token(kqd, rq);
}
static void rq_clear_domain_token(struct kyber_queue_data *kqd,
struct request *rq)
{
unsigned int sched_domain;
int nr;
nr = rq_get_domain_token(rq); // token保存在request的priv字段
if (nr != -1) {
// 获取IO类型
sched_domain = kyber_sched_domain(rq->cmd_flags);
// 释放token
sbitmap_queue_clear(&kqd->domain_tokens[sched_domain], nr,
rq->mq_ctx->cpu);
}
}
void sbitmap_queue_clear(struct sbitmap_queue *sbq, unsigned int nr,
unsigned int cpu)
{
sbitmap_clear_bit_unlock(&sbq->sb, nr); // 清除bit位
/*
* Pairs with the memory barrier in set_current_state() to ensure the
* proper ordering of clear_bit_unlock()/waitqueue_active() in the waker
* and test_and_set_bit_lock()/prepare_to_wait()/finish_wait() in the
* waiter. See the comment on waitqueue_active().
*/
smp_mb__after_atomic();
sbitmap_queue_wake_up(sbq); // 唤醒分发队列
if (likely(!sbq->round_robin && nr < sbq->sb.depth))
*per_cpu_ptr(sbq->alloc_hint, cpu) = nr;
}
唤醒动作会调用在初始化流程注册的kyber_domain_wake()函数。
static int kyber_domain_wake(wait_queue_entry_t *wait, unsigned mode, int flags,
void *key)
{
struct blk_mq_hw_ctx *hctx = READ_ONCE(wait->private);
list_del_init(&wait->entry); // 移出等待队列
blk_mq_run_hw_queue(hctx, true); // 执行run_hw_queue函数,去分发IO
return 1;
}
request完成
IO从设备驱动回到block层的时候会调用kyber调度器注册的hook--completed_request即kyber_completed_request()函数,在完成函数里面统计IO的时延以调整token数量。
kyber会统计两种时延:
KYBER_TOTAL_LATENCY:表示IO在kernel里的时延,即总的时延。
KYBER_IO_LATENCY:表示IO在设备上的执行时延。
kyber_cpu_latency:
/* buckets是一个atomic_t的三维数组,第一维表示要统计的IO类型,第二维表示是KYBER_TOTAL_LATENCY还是KYBER_IO_LATENCY,第三维表示的是8个IO时延相对于参考值的倍数的桶,先将时延统计到per_cpu的kyber_cpu_latency中,然后通过timer将所有cpu的统计加起来,通过一定的算法调整token数。 */
/*
KYBER_LATENCY_BUCKETS: 值为8,表示个桶,前KYBER_GOOD_BUCKETS(4)个桶表示“GOOD”的时延,后面4个表示“BAD”的时延。
GOOD时延表示IO时延小于等于时延参考值。
BAD时延表示IO时延大于时延参考值。
*/
struct kyber_cpu_latency {
atomic_t buckets[KYBER_OTHER][2][KYBER_LATENCY_BUCKETS];
};
static void kyber_completed_request(struct request *rq, u64 now)
{
struct kyber_queue_data *kqd = rq->q->elevator->elevator_data;
struct kyber_cpu_latency *cpu_latency;
unsigned int sched_domain;
u64 target;
// 获取完成的IO的类型
sched_domain = kyber_sched_domain(rq->cmd_flags);
// other类型的IO不会统计时延,自然也不会去调整其token数量
if (sched_domain == KYBER_OTHER)
return;
// cpu_latency延迟统计是per_cpu的,这里获取当前CPU的指针,将IO的时延统计到当前CPU
cpu_latency = get_cpu_ptr(kqd->cpu_latency);
// 当前IO的类型的延迟参考值
target = kqd->latency_targets[sched_domain];
// 统计总的IO时延,与下面对比,now减去的起始时间不一样的
add_latency_sample(cpu_latency, sched_domain, KYBER_TOTAL_LATENCY,
target, now - rq->start_time_ns);
// 统计IO在设备上的时延
add_latency_sample(cpu_latency, sched_domain, KYBER_IO_LATENCY, target,
now - rq->io_start_time_ns);
put_cpu_ptr(kqd->cpu_latency);
// 减小timer的到期时间
timer_reduce(&kqd->timer, jiffies + HZ / 10);
}
add_latency_sample()统计函数,kyber会统计当前IO的时延相对于参考时延的倍数(0~7倍),然后将这个倍数的计数记录在per_cpu的kyber_cpu_latency中。
static void add_latency_sample(struct kyber_cpu_latency *cpu_latency,
unsigned int sched_domain, unsigned int type,
u64 target, u64 latency)
{
unsigned int bucket;
u64 divisor;
if (latency > 0) {
// 这里将参考值除以4,计算所得的bucket表示时延是
// <= 1/4 * 时延参考值
// <= 1/2 * 时延参考值
// <= 3/4 * 时延参考值
// <= 时延参考值
// <= (1 + 1/4) * 时延参考值
// <= (1 + 1/2) * 时延参考值
// <= (1 + 3/4) * 时延参考值
// > 3/4 * 时延参考值
divisor = max_t(u64, target >> KYBER_LATENCY_SHIFT, 1);
// 这里将latency减去1,除法所得的值可以准确的落入buckets的下标里面,因为数组下标是从0开始的。
// 如果时延过大,除法所得的值超过了7,则约束其到7,这里取一个最小值
// 大家可以假设一些值来计算一下。
bucket = min_t(unsigned int, div64_u64(latency - 1, divisor),
KYBER_LATENCY_BUCKETS - 1);
} else {
bucket = 0;
}
// 增加相应的桶的计数
atomic_inc(&cpu_latency->buckets[sched_domain][type][bucket]);
}
根据时延统计调整token数
在初始化流程的kyber_queue_data_alloc()函数初始化了一个timer,timer每隔一段时间会执行来动态调整token数量,执行的函数为kyber_timer_fn()。
static void kyber_timer_fn(struct timer_list *t)
{
struct kyber_queue_data *kqd = from_timer(kqd, t, timer);
unsigned int sched_domain;
int cpu;
bool bad = false;
/* Sum all of the per-cpu latency histograms. */
// 将per_cpu的统计信息合并到kyber_queue_data的latency_buckets里面
for_each_online_cpu(cpu) {
struct kyber_cpu_latency *cpu_latency;
cpu_latency = per_cpu_ptr(kqd->cpu_latency, cpu);
for (sched_domain = 0; sched_domain < KYBER_OTHER; sched_domain++) {
flush_latency_buckets(kqd, cpu_latency, sched_domain,
KYBER_TOTAL_LATENCY);
flush_latency_buckets(kqd, cpu_latency, sched_domain,
KYBER_IO_LATENCY);
}
}
/*
* Check if any domains have a high I/O latency, which might indicate
* congestion in the device. Note that we use the p90; we don't want to
* be too sensitive to outliers here.
*/
// 看IO在设备上的时延是否是BAD的
for (sched_domain = 0; sched_domain < KYBER_OTHER; sched_domain++) {
int p90;
p90 = calculate_percentile(kqd, sched_domain, KYBER_IO_LATENCY,
90);
if (p90 >= KYBER_GOOD_BUCKETS)
bad = true;
}
/*
* Adjust the scheduling domain depths. If we determined that there was
* congestion, we throttle all domains with good latencies. Either way,
* we ease up on throttling domains with bad latencies.
*/
for (sched_domain = 0; sched_domain < KYBER_OTHER; sched_domain++) {
unsigned int orig_depth, depth;
int p99;
p99 = calculate_percentile(kqd, sched_domain,
KYBER_TOTAL_LATENCY, 99);
/*
* This is kind of subtle: different domains will not
* necessarily have enough samples to calculate the latency
* percentiles during the same window, so we have to remember
* the p99 for the next time we observe congestion; once we do,
* we don't want to throttle again until we get more data, so we
* reset it to -1.
*/
if (bad) {
// 当前的样本数不够或者timer的时间不够1s,则返回的p99 < 0
// 采用上一次timer计算所得的p99
if (p99 < 0)
p99 = kqd->domain_p99[sched_domain];
kqd->domain_p99[sched_domain] = -1;
} else if (p99 >= 0) {
// 记录这一次计算的p99,下一次timer可能用到
kqd->domain_p99[sched_domain] = p99;
}
if (p99 < 0)
continue;
/*
* If this domain has bad latency, throttle less. Otherwise,
* throttle more iff we determined that there is congestion.
*
* The new depth is scaled linearly with the p99 latency vs the
* latency target. E.g., if the p99 is 3/4 of the target, then
* we throttle down to 3/4 of the current depth, and if the p99
* is 2x the target, then we double the depth.
*/
// 根据总的IO时延统计动态调整token数量的算法比较的“启发式”,也就是根据测试结果和经验来判断应该怎样去调整token的数量
if (bad || p99 >= KYBER_GOOD_BUCKETS) {
orig_depth = kqd->domain_tokens[sched_domain].sb.depth;
depth = (orig_depth * (p99 + 1)) >> KYBER_LATENCY_SHIFT;
kyber_resize_domain(kqd, sched_domain, depth);
}
}
}
// 根据统计的时延计算时延的“好坏”
static int calculate_percentile(struct kyber_queue_data *kqd,
unsigned int sched_domain, unsigned int type,
unsigned int percentile)
{
unsigned int *buckets = kqd->latency_buckets[sched_domain][type];
unsigned int bucket, samples = 0, percentile_samples;
for (bucket = 0; bucket < KYBER_LATENCY_BUCKETS; bucket++)
samples += buckets[bucket];
// 没有样本,表明这段时间没有IO
if (!samples)
return -1;
/*
* We do the calculation once we have 500 samples or one second passes
* since the first sample was recorded, whichever comes first.
*/
// 记录超时时间为1s
if (!kqd->latency_timeout[sched_domain])
kqd->latency_timeout[sched_domain] = max(jiffies + HZ, 1UL);
if (samples < 500 &&
time_is_after_jiffies(kqd->latency_timeout[sched_domain])) {
return -1;
}
kqd->latency_timeout[sched_domain] = 0;
// 找到最能代表延迟情况的那个bucket,
// 至于这里的算法以及为什么要先计算一个百分比就不清楚了,代码能看懂但却不知为什么。
percentile_samples = DIV_ROUND_UP(samples * percentile, 100);
for (bucket = 0; bucket < KYBER_LATENCY_BUCKETS - 1; bucket++) {
if (buckets[bucket] >= percentile_samples)
break;
percentile_samples -= buckets[bucket];
}
memset(buckets, 0, sizeof(kqd->latency_buckets[sched_domain][type]));
trace_kyber_latency(kqd->q, kyber_domain_names[sched_domain],
kyber_latency_type_names[type], percentile,
bucket + 1, 1 << KYBER_LATENCY_SHIFT, samples);
return bucket;
}
static void kyber_resize_domain(struct kyber_queue_data *kqd,
unsigned int sched_domain, unsigned int depth)
{
// 新的token数量不会大于最初的初始化值,也不会为0
depth = clamp(depth, 1U, kyber_depth[sched_domain]);
if (depth != kqd->domain_tokens[sched_domain].sb.depth) {
sbitmap_queue_resize(&kqd->domain_tokens[sched_domain], depth);
trace_kyber_adjust(kqd->q, kyber_domain_names[sched_domain],
depth);
}
}
kyber退出
kyber退出的时候有两个hook函数需要执行,kyber_exit_sched()和kyber_exit_hctx()。
static void kyber_exit_hctx(struct blk_mq_hw_ctx *hctx, unsigned int hctx_idx)
{
struct kyber_hctx_data *khd = hctx->sched_data;
int i;
for (i = 0; i < KYBER_NUM_DOMAINS; i++)
sbitmap_free(&khd->kcq_map[i]);
kfree(khd->kcqs);
kfree(hctx->sched_data);
}
static void kyber_exit_sched(struct elevator_queue *e)
{
struct kyber_queue_data *kqd = e->elevator_data;
int i;
del_timer_sync(&kqd->timer);
for (i = 0; i < KYBER_NUM_DOMAINS; i++)
sbitmap_queue_free(&kqd->domain_tokens[i]);
free_percpu(kqd->cpu_latency);
kfree(kqd);
}
释放掉timer和所有初始化时申请的内存。
总结
kyber调度器是一个适合于高速存储介质(如NVMe)的IO调度器,文章对其做了机制介绍和源码分析,关于根据时延统计动态调整token数目的部分还未弄懂开发者的用意,算是这篇文章的一个遗憾,如果有知道的大佬还请不吝赐教。
另外mq-deadline调度器和bfq调度器的分析文章也在撰写中,bfq比kyber复杂的很多(仅从代码量上看就能大概推断),因此可能需要一些时间理解代码,mq-deadline调度器则会尽快呈现。

