【计算机网络】Stanford CS144 Lab Assignments 学习笔记
本文为我的斯坦福计算机网络课的编程实验(Lab Assignments)的学习总结。课程全称:CS 144: Introduction to Computer Networking。
事情发生于我读了半本《计算机网络:自顶向下方法》后,想要找点练手的东西,碰巧在知乎上看到了这个推荐帖:CS144: 什么,你学不会TCP?那就来自己写一个吧!。这门课的作业要求实现一个简单的TCP协议,自带充足评测程序,同时又比较有挑战性,我便欣然做之。
LAB0#
在我开始做实验的时候官方不知为何已经删掉了sponge的github代码仓库,不过庆幸的是有huangrt01老哥早早做完了实验把自己的代码发到了github上,我克隆到本地后利用git回退到最初状态就能做了。不过因为CS144官方不喜欢大伙儿把完成的代码公开到网上,防止后来的学生抄作业,所以本文发布时huangrt01已经把仓库给设为private了。咱这里给出自己做完后打包好的仓库,寄存在gitee上(老外应该不会上gitee吧)。
另一件尴尬的事儿是CS144的2020年开了新课,旧版网页被覆盖掉了,我在gitee上拉了仓库镜像,利用gitee的pages功能搭建了官网2019年的镜像(即我做实验对应的版本)。
CS144官方网页:https://cs144.github.io/
我的官网镜像:https://kangyupl.gitee.io/cs144.github.io/
官网前端源码备份:https://gitee.com/kangyupl/cs144.github.io 如果官网镜像打不开的话,可以直接把该仓库克隆到本地,用浏览器打开 index.html 访问
我的实验代码备份:https://gitee.com/kangyupl/sponge
LAB0初始代码对应着master的分支,我的题解放在solution分支下,有需要可以自行切换。
开工准备#
首先要安装g++-8或clang-6,请根据自己的linux发行版自行搜索对应方法。我用的是g++-8,如果安装后CMAKE的时候还是提示g++版本不够,那就百度一下怎么把用g++-8替代gcc,再不行的话那就为gcc-8创建一个名为cc的软连接,为g++-8创建一个名为c++的软链接。
另外,如果你CMAKE的时候报出了如下错误:
CMake Error: The following variables are used in this project, but they are set to NOTFOUND.
Please set them or make sure they are set and tested correctly in the CMake files:
LIBPCAP
linked by target "udp_tcpdump" in directory /home/kangyu/sponge/apps
linked by target "ipv4_parser" in directory /home/kangyu/sponge/tests
linked by target "ipv4_parser" in directory /home/kangyu/sponge/tests
linked by target "tcp_parser" in directory /home/kangyu/sponge/tests
linked by target "tcp_parser" in directory /home/kangyu/sponge/tests
此时安装libpcap-dev库来解决,大多数的Linux发行版的软件源中应该都有这玩意。
Writing webget#
要求实现get_URL函数,功能为向指定IP地址发送HTTP GET请求,然后输出所有响应。可参考配套Doc中TCPSocket的示例代码。此外多读读讲义提示,注意下EOF和shutdown()的参数即可。
webget.cc
void get_URL(const string &host, const string &path) {
TCPSocket sock{};
sock.connect(Address(host,"http"));
sock.write("GET "+path+" HTTP/1.1\r\nHost: "+host+"\r\n\r\n");
sock.shutdown(SHUT_WR);
while(!sock.eof()){
cout<<sock.read();
}
sock.close();
return;
}
An in-memory reliable byte stream#
要求实现一个有序字节流类(in-order byte stream),使之支持读写、容量控制。这个字节流类似于一个带容量的队列,从一头读,从另一头写。当流中的数据达到容量上限时,便无法再写入新的数据。特别的,写操作被分为了peek和pop两步。peek为从头部开始读取指定数量的字节,pop为弹出指定数量的字节。
第一反应是搞个循环队列,容器基于数组,长度等于容量,这样内存被充分利用,效率也不错。不过讲义要求我们用“Modern C++”,避免用普通指针,所以我退而求其次用std::deque代替。为什么不用std::queue?因为queue只能访问开头的节点,无法实现peek操作。
byte_stream.hh
class ByteStream {
private:
// Your code here -- add private members as necessary.
std::deque<char> _buffer = {};
size_t _capacity = 0;
size_t _read_count = 0;
size_t _write_count = 0;
bool _input_ended_flag = false;
bool _error = false; //!< Flag indicating that the stream suffered an error.
//......
byte_stream.cc
ByteStream::ByteStream(const size_t capacity) : _capacity(capacity) {}
size_t ByteStream::write(const string &data) {
size_t len = data.length();
if (len > _capacity - _buffer.size()) {
len = _capacity - _buffer.size();
}
_write_count += len;
for (size_t i = 0; i < len; i++) {
_buffer.push_back(data[i]);
}
return len;
}
//! \param[in] len bytes will be copied from the output side of the buffer
string ByteStream::peek_output(const size_t len) const {
size_t length = len;
if (length > _buffer.size()) {
length = _buffer.size();
}
return string().assign(_buffer.begin(), _buffer.begin() + length);
}
//! \param[in] len bytes will be removed from the output side of the buffer
void ByteStream::pop_output(const size_t len) {
size_t length = len;
if (length > _buffer.size()) {
length = _buffer.size();
}
_read_count += length;
while (length--) {
_buffer.pop_front();
}
return;
}
void ByteStream::end_input() { _input_ended_flag = true; }
bool ByteStream::input_ended() const { return _input_ended_flag; }
size_t ByteStream::buffer_size() const { return _buffer.size(); }
bool ByteStream::buffer_empty() const { return _buffer.size() == 0; }
bool ByteStream::eof() const { return buffer_empty() && input_ended(); }
size_t ByteStream::bytes_written() const { return _write_count; }
size_t ByteStream::bytes_read() const { return _read_count; }
size_t ByteStream::remaining_capacity() const { return _capacity - _buffer.size(); }
调试方法论#
因为我用的是vscode,所以讲一下使用vscode时debug的方法:
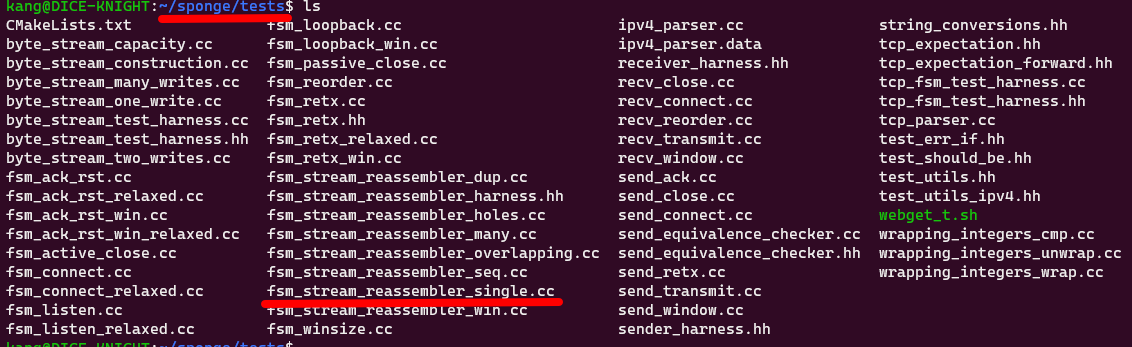
如下图,在本次check中,测试样例t_strm_reassem_single出错。

以t_strm_reassem_single为关键词全局搜索可发现,所有的测试样例对应的命令都在spong/etc/tests.cmake中定义,我们从中找到需要的部分
add_test(NAME t_strm_reassem_cap COMMAND fsm_stream_reassembler_cap)
add_test(NAME t_strm_reassem_single COMMAND fsm_stream_reassembler_single)
add_test(NAME t_strm_reassem_seq COMMAND fsm_stream_reassembler_seq)
add_test(NAME t_strm_reassem_dup COMMAND fsm_stream_reassembler_dup)
add_test(NAME t_strm_reassem_holes COMMAND fsm_stream_reassembler_holes)
add_test(NAME t_strm_reassem_many COMMAND fsm_stream_reassembler_many)
add_test(NAME t_strm_reassem_overlapping COMMAND fsm_stream_reassembler_overlapping)
add_test(NAME t_strm_reassem_win COMMAND fsm_stream_reassembler_win)
可以发现t_strm_reassem_single 对应的测试命令为fsm_stream_reassembler_single,test.cmake中的COMMAND都是以sponge/build/tests/作为“当前路径”执行的,在这里就相当于运行sponge/build/tests/fsm_stream_reassembler_single程序,

而所有测试程序对应的源文件存放在sponge/tests/下
如果使用GDB的话,现在可以直接通过gdb 程序路径进行调试。不过我使用的是基于GDB插件的vscode,需要对launch.json做点小修改。我把修改的行加了注释。
{
"version": "0.2.0",
"configurations": [
{
"name": "sponge debug",//!挑个容易识别的名字
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/build/tests/${fileBasenameNoExtension}", //!设置为测试程序源码相对应的目标程序路径
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"setupCommands": [
{
"description": "为 gdb 启用整齐打印",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
//"preLaunchTask": "C/C++: g++-8 build active file", //!不需要前置任务
"miDebuggerPath": "/usr/bin/gdb"
}
]
}
此时在vscode中切回fsm_stream_reassembler_harness.cc,打完断点后即可正常调试
LAB1#
要求实现一个流重组器(stream reassembler),可以将带索引的字节流碎片重组成有序的字节流。每个字节流碎片都通过索引、长度、内容三要素进行描述。重组完的字节流应当被送入指定的字节流(byte stream)对象_output中。
特别注意:
0.这节需要安装pcap库和pcap-dev库才能正常编译,如果没编译没报错那就没事了。
1.碎片可能交叉或重叠。
2.如果某次新碎片到达后字节流的开头部分被凑齐,那就应当立刻把凑齐的部分立刻写入到_output中。即对应讲义中的:
When should bytes be written to the stream?
As soon as possible. The only situation in which a byte should not be in the stream is that when there is a byte before it that has not been “pushed” yet.
3.碎片可能是一个只包含EOF标志的空串
4.LAB0的顺序字节流和LAB1的流重组器各有各的容量限制。流重组器把字节流写满后,只有当字节流腾出空后才能继续写,相当于字节流满时流重组器出口被“堵住”了。同样当流重组器容量满了后自身也无法被写入新数据,此时到来的新碎片只能被丢弃掉。
第一反应联想到了操作系统里的进程内存管理,用一个二叉排序树来记录每个碎片的索引、长度,排序规则为按索引值升序,每次插入新碎片时判断能不能和前后碎片进行合并。流的内容则可以用一个数组来做缓冲区,或者干脆一块存储在二叉树的节点里。不过还是因为“Modern C++”的缘故,我再次退而求其次用std::list代替之。等我哼哧哼哧花了好几个小时写完LAB1后,又哼哧哼哧得改了一众BUG后,才想起std::set底层就是用红黑树实现的,可以直接拿来用。
“哼哼--哼哼哼---哼哼哼哼----啊啊啊啊啊啊啊啊”阿宅大哭。
最终实现与上文愿景差不多,用一个block_node结构体来存放每个碎片的索引、长度、内容。又因为set排序实现基于对应节点类型的小于运算符规则,所以我把block_node结构体的小于运算符重载为按索引值升序。再简单说下我的push_substring处理流程:
- 容量判断:满了就立刻返回。
- 处理子串的冗余前缀:如果子串包含已经被写入字节流的部分,就把这部分剪掉。
- 合并子串:运用
set自带的lowerbound快速确定插入位置,前后重复比较,用个自己写的子函数判断重叠的字顺便合并之。 - 写入字节流:如果流重组器头部非空,就把头部写入字节流,并更新指示头部的游标。
- EOF判断
stream_reassembler.hh
class StreamReassembler {
private:
// Your code here -- add private members as necessary.
struct block_node {
size_t begin = 0;
size_t length = 0;
std::string data = "";
bool operator<(const block_node t) const { return begin < t.begin; }
};
std::set<block_node> _blocks = {};
std::vector<char> _buffer = {};
size_t _unassembled_byte = 0;
size_t _head_index = 0;
bool _eof_flag = false;
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
//! merge elm2 to elm1, return merged bytes
long merge_block(block_node &elm1, const block_node &elm2);
//......
stream_reassembler.cc
StreamReassembler::StreamReassembler(const size_t capacity) : _output(capacity), _capacity(capacity) {
_buffer.resize(capacity);
}
long StreamReassembler::merge_block(block_node &elm1, const block_node &elm2) {
block_node x, y;
if (elm1.begin > elm2.begin) {
x = elm2;
y = elm1;
} else {
x = elm1;
y = elm2;
}
if (x.begin + x.length < y.begin) {
return -1; // no intersection, couldn't merge
} else if (x.begin + x.length >= y.begin + y.length) {
elm1 = x;
return y.length;
} else {
elm1.begin = x.begin;
elm1.data = x.data + y.data.substr(x.begin + x.length - y.begin);
elm1.length = elm1.data.length();
return x.begin + x.length - y.begin;
}
}
//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
if (index >= _head_index + _capacity) { // capacity over
return;
}
// handle extra substring prefix
block_node elm;
if (index + data.length() <= _head_index) { // couldn't equal, because there have emtpy substring
goto JUDGE_EOF;
} else if (index < _head_index) {
size_t offset = _head_index - index;
elm.data.assign(data.begin() + offset, data.end());
elm.begin = index + offset;
elm.length = elm.data.length();
} else {
elm.begin = index;
elm.length = data.length();
elm.data = data;
}
_unassembled_byte += elm.length;
// merge substring
do {
// merge next
long merged_bytes = 0;
auto iter = _blocks.lower_bound(elm);
while (iter != _blocks.end() && (merged_bytes = merge_block(elm, *iter)) >= 0) {
_unassembled_byte -= merged_bytes;
_blocks.erase(iter);
iter = _blocks.lower_bound(elm);
}
// merge prev
if (iter == _blocks.begin()) {
break;
}
iter--;
while ((merged_bytes = merge_block(elm, *iter)) >= 0) {
_unassembled_byte -= merged_bytes;
_blocks.erase(iter);
iter = _blocks.lower_bound(elm);
if (iter == _blocks.begin()) {
break;
}
iter--;
}
} while (false);
_blocks.insert(elm);
// write to ByteStream
if (!_blocks.empty() && _blocks.begin()->begin == _head_index) {
const block_node head_block = *_blocks.begin();
// modify _head_index and _unassembled_byte according to successful write to _output
size_t write_bytes = _output.write(head_block.data);
_head_index += write_bytes;
_unassembled_byte -= write_bytes;
_blocks.erase(_blocks.begin());
}
JUDGE_EOF:
if (eof) {
_eof_flag = true;
}
if (_eof_flag && empty()) {
_output.end_input();
}
}
size_t StreamReassembler::unassembled_bytes() const { return _unassembled_byte; }
bool StreamReassembler::empty() const { return _unassembled_byte == 0; }
LAB2#
Sequence Numbers#
要求实现序列号、绝对序列号与流索引间的转换。照着讲义的表格写就行:
| Sequence Numbers | Absolute Sequence Numbers | Stream Indices |
|---|---|---|
| Start at the ISN | Start at 0 | Start at 0 |
| Include SYN/FIN | Include SYN/FIN | Omit SYN/FIN |
| 32 bits, wrapping | 64 bits, non-wrapping | 64 bits, non-wrapping |
| “seqno” | “absolute seqno” | “stream index” |
需要提一下的地方有checkpoint表示最近一次转换求得的absolute seqno,而本次转换出的absolute seqno应该选择与上次值最为接近的那一个。原理是虽然segment不一定按序到达,但几乎不可能出现相邻到达的两个segment序号差值超过INT32_MAX的情况,除非延迟以年为单位,或者产生了比特差错(后面的LAB可能涉及)。
实际操作就是把算出来的 绝对序号分别加减1ul << 32做比较,选择与checkpoing差的绝对值最小的那个。
wrapping_integers.cc
WrappingInt32 wrap(uint64_t n, WrappingInt32 isn) {
return WrappingInt32(static_cast<uint32_t>(n) + isn.raw_value());
}
uint64_t unwrap(WrappingInt32 n, WrappingInt32 isn, uint64_t checkpoint) {
uint32_t offset = n.raw_value() - isn.raw_value();
uint64_t t = (checkpoint & 0xFFFFFFFF00000000) + offset;
uint64_t ret = t;
if (abs(int64_t(t + (1ul << 32) - checkpoint)) < abs(int64_t(t - checkpoint)))
ret = t + (1ul << 32);
if (t >= (1ul << 32) && abs(int64_t(t - (1ul << 32) - checkpoint)) < abs(int64_t(ret - checkpoint)))
ret = t - (1ul << 32);
return ret;
}
Implementing the TCP receiver#
要求实现一个基于滑动窗口的TCP接收端,类似于我在《计算机网络:自定向下方法》里看的选择重传协议,不过多了点小细节。上个图:
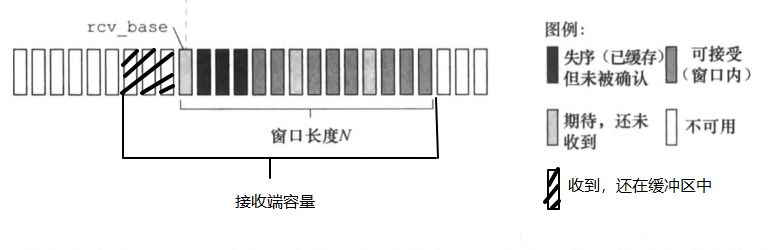
整个接收端的空间由窗口空间(基于StreamReassmbler)和缓冲区空间(基于ByteStream)两部分共享。需要注意窗口长度等于接收端容量减去还留在缓冲区的字节数,只有当字节从缓冲区读出后窗口长度才能缩减。
这节的数据结构部分在前两个LAB已经实现完了,我们只要写点业务逻辑就行,就是琐碎的细节多了点,需要疯狂调试疯狂修改。一些容易出问题的细节我都标注在代码里了。
为了达成本节任务,我在StreamReassembler里加了俩getter接口:
stream_reassembler.hh
class StreamReassembler {
public:
size_t head_index() const { return _head_index; }
bool input_ended() const { return _output.input_ended(); }
//......
}
tcp_receiver.hh
class TCPReceiver {
private:
//! Our data structure for re-assembling bytes.
StreamReassembler _reassembler;
bool _syn_flag = false;
bool _fin_flag = false;
size_t _base = 0; // when unintital, equal zero for ackno special judge
size_t _isn = 0;
//! The maximum number of bytes we'll store.
size_t _capacity;
//......
tcp_receiver.cc
bool TCPReceiver::segment_received(const TCPSegment &seg) {
bool ret = false;
static size_t abs_seqno = 0;
size_t length;
if (seg.header().syn) {
if (_syn_flag) { // already get a SYN, refuse other SYN.
return false;
}
_syn_flag = true;
ret = true;
_isn = seg.header().seqno.raw_value();
abs_seqno = 1;
_base = 1;
length = seg.length_in_sequence_space() - 1;
if (length == 0) { // segment's content only have a SYN flag
return true;
}
} else if (!_syn_flag) { // before get a SYN, refuse any segment
return false;
} else { // not a SYN segment, compute it's abs_seqno
abs_seqno = unwrap(WrappingInt32(seg.header().seqno.raw_value()), WrappingInt32(_isn), abs_seqno);
length = seg.length_in_sequence_space();
}
if (seg.header().fin) {
if (_fin_flag) { // already get a FIN, refuse other FIN
return false;
}
_fin_flag = true;
ret = true;
}
// not FIN and not one size's SYN, check border
else if (seg.length_in_sequence_space() == 0 && abs_seqno == _base) {
return true;
} else if (abs_seqno >= _base + window_size() || abs_seqno + length <= _base) {
if (!ret)
return false;
}
_reassembler.push_substring(seg.payload().copy(), abs_seqno - 1, seg.header().fin);
_base = _reassembler.head_index() + 1;
if (_reassembler.input_ended()) // FIN be count as one byte
_base++;
return true;
}
optional<WrappingInt32> TCPReceiver::ackno() const {
if (_base > 0)
return WrappingInt32(wrap(_base, WrappingInt32(_isn)));
else
return std::nullopt;
}
size_t TCPReceiver::window_size() const { return _capacity - _reassembler.stream_out().buffer_size(); }
LAB3#
这节课实现的是TCP的发送方,难度比上节要高一些,看完讲义后我一头雾水,不知如何下手。到最后抄了huangrt01兄的作业才算是理明白了。以下记录下我迷惑的几个点:
第一个迷惑点是书上描述选择重传的这张图:
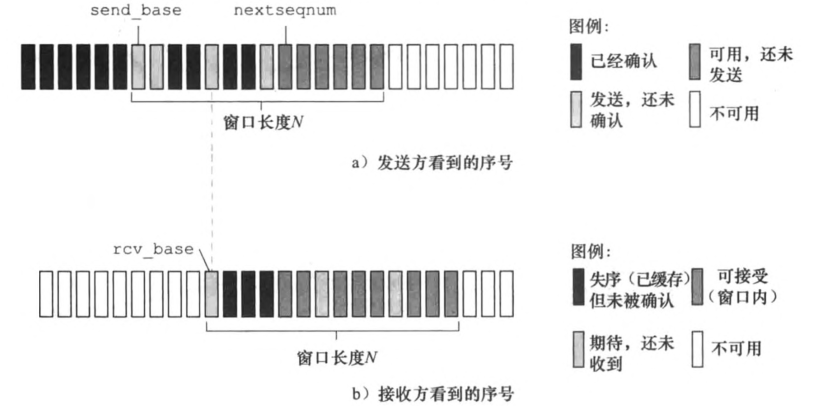
这副图里用的是“分别确认”的协议,即发送方收到一个ackno只代表接收方收到了该ackno对应的那个段。而我们在这个lab用的是基于“累计确认”的ARQ协议,即发送方收到一个ackno代表了接收方已经收到ackno之前的所有段。原先的时候我花了大部分的时间思考怎么设计分别确认的数据结构,又怎样来跟踪重传的段。换成累计确认就简单多了,直接一个queue就行,重传的时候只传头就行。
第二个迷惑点是接收方发出的首个段应是只包含SYN的段,用作第一次握手。课本里是这么讲的,但讲义里没说,所以我就按首个段也可以存数据的逻辑写了不少错代码。
第三个迷惑点是计时器启动的时机。讲义里在多个地方都提到了重启计时器,搞得我很混乱。这里推荐课本里的图3-33:

下面是最终代码
tcp_sender.hh
class TCPSender{
private:
//......
std::queue<TCPSegment> _segments_outstanding{};
size_t _bytes_in_flight = 0;
size_t _recv_ackno = 0;
bool _syn_flag = false;
bool _fin_flag = false;
size_t _window_size = 0;
size_t _timer = 0;
bool _timer_running = false;
size_t _retransmission_timeout = 0;
size_t _consecutive_retransmission = 0;
void send_segment(TCPSegment &seg);
//......
tcp_sender.cc
TCPSender::TCPSender(const size_t capacity, const uint16_t retx_timeout, const std::optional<WrappingInt32> fixed_isn)
: _isn(fixed_isn.value_or(WrappingInt32{random_device()()}))
, _initial_retransmission_timeout{retx_timeout}
, _stream(capacity)
, _retransmission_timeout(retx_timeout) {}
uint64_t TCPSender::bytes_in_flight() const { return _bytes_in_flight; }
void TCPSender::fill_window(bool send_syn) {
// sent a SYN before sent other segment
if (!_syn_flag) {
if (send_syn) {
TCPSegment seg;
seg.header().syn = true;
send_segment(seg);
_syn_flag = true;
}
return;
}
// take window_size as 1 when it equal 0
size_t win = _window_size > 0 ? _window_size : 1;
size_t remain; // window's free space
// when window isn't full and never sent FIN
while ((remain = win - (_next_seqno - _recv_ackno)) != 0 && !_fin_flag) {
size_t size = min(TCPConfig::MAX_PAYLOAD_SIZE, remain);
TCPSegment seg;
string str = _stream.read(size);
seg.payload() = Buffer(std::move(str));
// add FIN
if (seg.length_in_sequence_space() < win && _stream.eof()) {
seg.header().fin = true;
_fin_flag = true;
}
// stream is empty
if (seg.length_in_sequence_space() == 0) {
return;
}
send_segment(seg);
}
}
//! \param ackno The remote receiver's ackno (acknowledgment number)
//! \param window_size The remote receiver's advertised window size
//! \returns `false` if the ackno appears invalid (acknowledges something the TCPSender hasn't sent yet)
bool TCPSender::ack_received(const WrappingInt32 ackno, const uint16_t window_size) {
size_t abs_ackno = unwrap(ackno, _isn, _recv_ackno);
// out of window, invalid ackno
if (abs_ackno > _next_seqno) {
return false;
}
// if ackno is legal, modify _window_size before return
_window_size = window_size;
// ack has been received
if (abs_ackno <= _recv_ackno) {
return true;
}
_recv_ackno = abs_ackno;
// pop all elment before ackno
while (!_segments_outstanding.empty()) {
TCPSegment seg = _segments_outstanding.front();
if (unwrap(seg.header().seqno, _isn, _next_seqno) + seg.length_in_sequence_space() <= abs_ackno) {
_bytes_in_flight -= seg.length_in_sequence_space();
_segments_outstanding.pop();
} else {
break;
}
}
fill_window();
_retransmission_timeout = _initial_retransmission_timeout;
_consecutive_retransmission = 0;
// if have other outstanding segment, restart timer
if (!_segments_outstanding.empty()) {
_timer_running = true;
_timer = 0;
}
return true;
}
//! \param[in] ms_since_last_tick the number of milliseconds since the last call to this method
void TCPSender::tick(const size_t ms_since_last_tick) {
_timer += ms_since_last_tick;
if (_timer >= _retransmission_timeout && !_segments_outstanding.empty()) {
_segments_out.push(_segments_outstanding.front());
_consecutive_retransmission++;
_retransmission_timeout *= 2;
_timer_running = true;
_timer = 0;
}
if (_segments_outstanding.empty()) {
_timer_running = false;
}
}
unsigned int TCPSender::consecutive_retransmissions() const { return _consecutive_retransmission; }
void TCPSender::send_empty_segment() {
// empty segment doesn't need store to outstanding queue
TCPSegment seg;
seg.header().seqno = wrap(_next_seqno, _isn);
_segments_out.push(seg);
}
void TCPSender::send_empty_segment(WrappingInt32 seqno) {
// empty segment doesn't need store to outstanding queue
TCPSegment seg;
seg.header().seqno = seqno;
_segments_out.push(seg);
}
void TCPSender::send_segment(TCPSegment &seg) {
seg.header().seqno = wrap(_next_seqno, _isn);
_next_seqno += seg.length_in_sequence_space();
_bytes_in_flight += seg.length_in_sequence_space();
_segments_outstanding.push(seg);
_segments_out.push(seg);
if (!_timer_running) { // start timer
_timer_running = true;
_timer = 0;
}
}
LAB4#
这节课要求实现一个TCPConnection类,主要功能有:封装TCPSender和TCPReceiver;构建TCP的有限状态机(FSM)。虽然讲义里说这节课不需要设计啥新东西,只要拼拼凑凑就行,但实际实现难度比前四个实验加起来还难。主要难点在于TCP的FSM涉及到12种状态间的转换,需要很多的细节逻辑来控制。并且老师说因为不想让大家“面向样例编程”,所以LAB4之前的几个LAB的测试样例并非“全面”的,到了LAB4再给你套“完备”的测试,这就导致很多前几个LAB潜在的BUG都集中在LAB4里爆发出来,需要修改前面实现过的代码才行。
思路分析也实在没啥好说的了,去网上狂啃资料把TCP的FSM吃透,把讲义完全吃透,把官网FAQ里的东西吃透,把libsponge/tcp_helpers/tcp_state.cc吃透。然后疯狂的改BUG吧。
我敢肯定你大把的时间最后都会花在研究下面这三幅图上的:
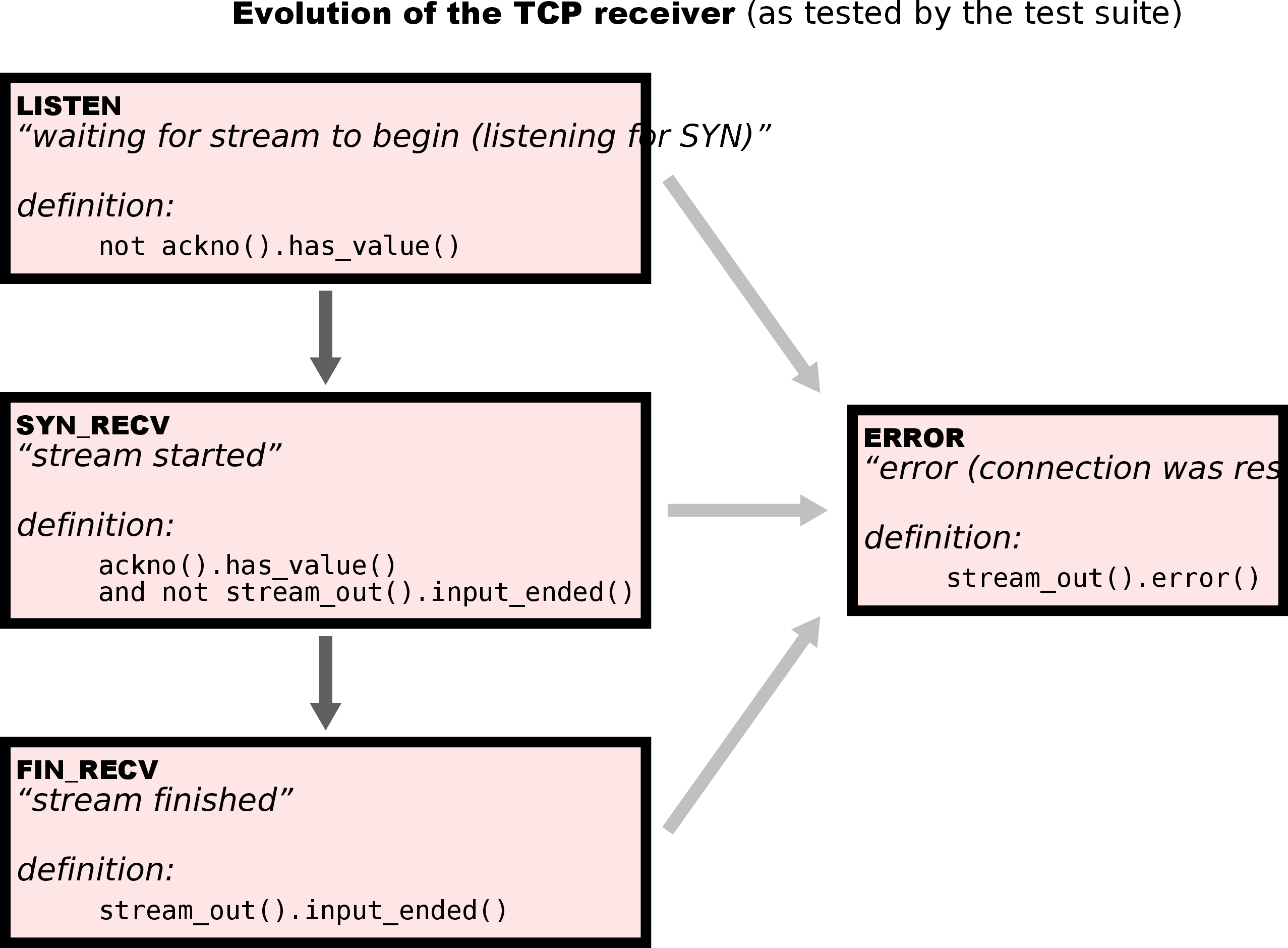
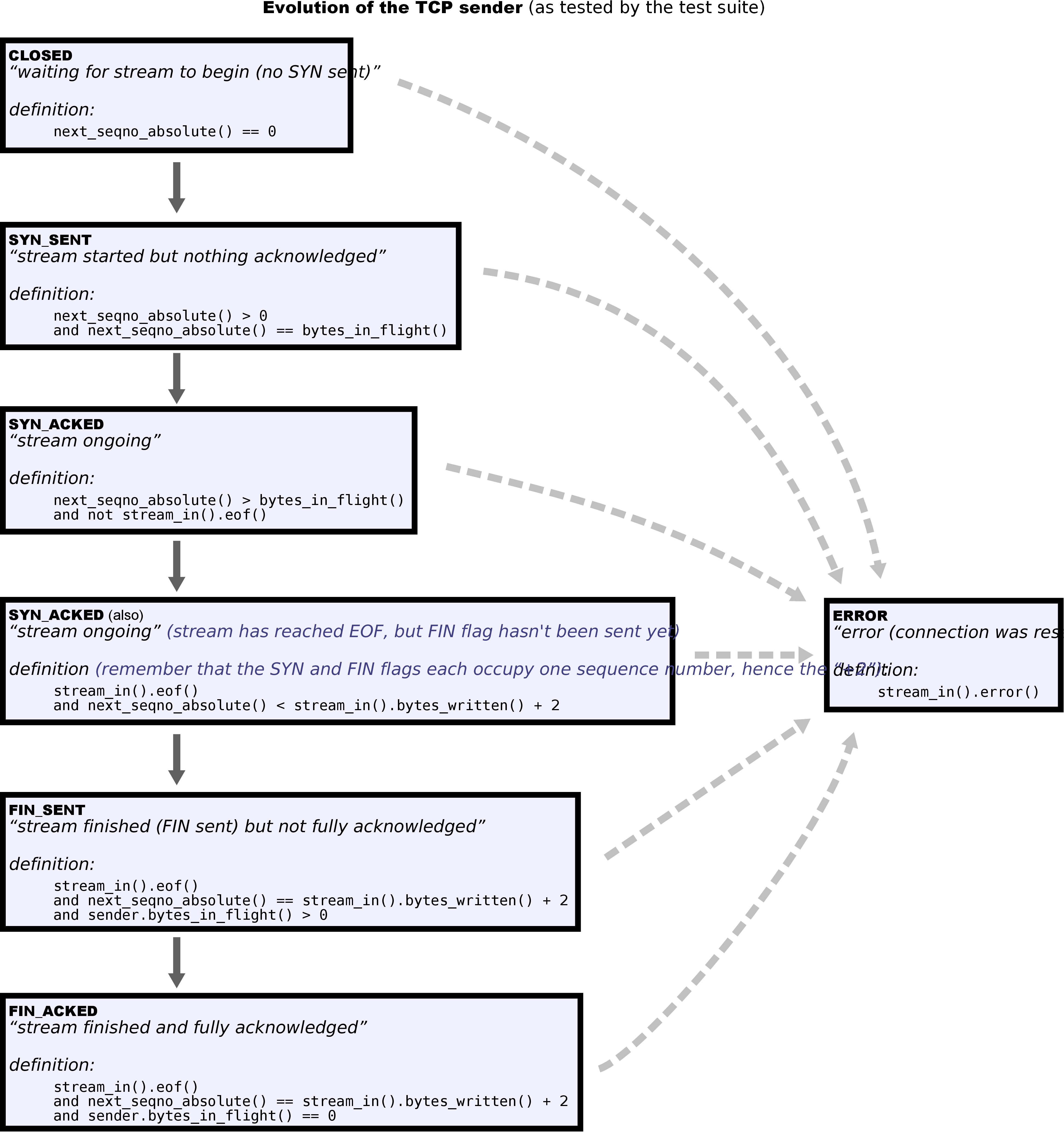
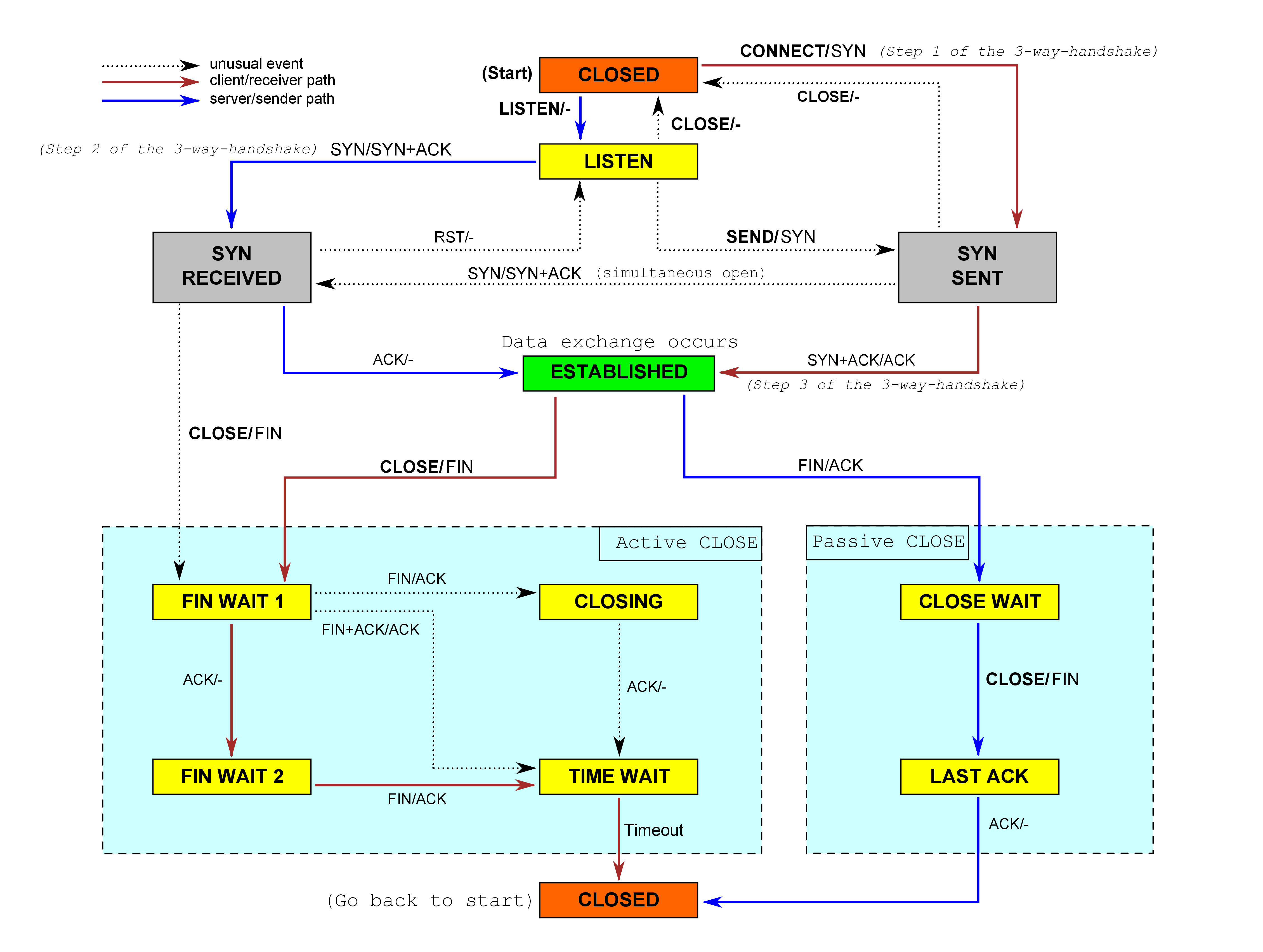
虽然不想讲实现思路,但在编写过程中有几个恼人的环境问题我还是要提一下:
tun.cc编译错误#
如果你编译的时候爆出了如下错误:
[ 5%] Building CXX object libsponge/CMakeFiles/sponge.dir/util/tun.cc.o
In file included from /home/kang/sponge/libsponge/util/tun.cc:8:
/usr/include/linux/if.h:211:19: error: field ‘ifru_addr’ has incomplete type ‘sockaddr’
struct sockaddr ifru_addr;
^~~~~~~~~
In file included from /usr/include/linux/if.h:23,
from /home/kang/sponge/libsponge/util/tun.cc:8:
/usr/include/linux/socket.h:19:27: note: forward declaration of ‘struct sockaddr’
} __attribute__ ((aligned(_K_SS_ALIGNSIZE))); /* force desired alignment */
^~~~~~~~~~~~~~~
请参考interfaces code fails with incomplete type 'struct sockaddr',在libsponge/util/tun.cc中添加
#include <sys/socket.h>
make check超时或随机几个样例报错#
天朝特色网络问题,因为webget测试网站服务器在国外,所以多重试几次吧。如果还有错那就是系统问题了,我本地运行出错概率比较大,换用阿里的云主机处出错概率就比较小了。
最终代码如下:
tcp_connection.hh
class TCPConnection {
private:
//......
size_t _time_since_last_segment_received = 0;
bool _active = true;
bool _need_send_rst = false;
bool _ack_for_fin_sent = false;
bool push_segments_out(bool send_syn = false);
void unclean_shutdown(bool send_rst);
bool clean_shutdown();
bool in_listen();
bool in_syn_recv();
bool in_syn_sent();
//.......
tcp_connection.cc
size_t TCPConnection::remaining_outbound_capacity() const { return _sender.stream_in().remaining_capacity(); }
size_t TCPConnection::bytes_in_flight() const { return _sender.bytes_in_flight(); }
size_t TCPConnection::unassembled_bytes() const { return _receiver.unassembled_bytes(); }
size_t TCPConnection::time_since_last_segment_received() const { return _time_since_last_segment_received; }
void TCPConnection::segment_received(const TCPSegment &seg) {
if (!_active)
return;
_time_since_last_segment_received = 0;
// data segments with acceptable ACKs should be ignored in SYN_SENT
if (in_syn_sent() && seg.header().ack && seg.payload().size() > 0) {
return;
}
bool send_empty = false;
if (_sender.next_seqno_absolute() > 0 && seg.header().ack) {
// unacceptable ACKs should produced a segment that existed
if (!_sender.ack_received(seg.header().ackno, seg.header().win)) {
send_empty = true;
}
}
bool recv_flag = _receiver.segment_received(seg);
if (!recv_flag) {
send_empty = true;
}
if (seg.header().syn && _sender.next_seqno_absolute() == 0) {
connect();
return;
}
if (seg.header().rst) {
// RST segments without ACKs should be ignored in SYN_SENT
if (in_syn_sent() && !seg.header().ack) {
return;
}
unclean_shutdown(false);
return;
}
if (seg.length_in_sequence_space() > 0) {
send_empty = true;
}
if (send_empty) {
if (_receiver.ackno().has_value() && _sender.segments_out().empty()) {
_sender.send_empty_segment();
}
}
push_segments_out();
}
bool TCPConnection::active() const { return _active; }
size_t TCPConnection::write(const string &data) {
size_t ret = _sender.stream_in().write(data);
push_segments_out();
return ret;
}
//! \param[in] ms_since_last_tick number of milliseconds since the last call to this method
void TCPConnection::tick(const size_t ms_since_last_tick) {
if (!_active)
return;
_time_since_last_segment_received += ms_since_last_tick;
_sender.tick(ms_since_last_tick);
if (_sender.consecutive_retransmissions() > TCPConfig::MAX_RETX_ATTEMPTS) {
unclean_shutdown(true);
}
push_segments_out();
}
void TCPConnection::end_input_stream() {
_sender.stream_in().end_input();
push_segments_out();
}
void TCPConnection::connect() {
// when connect, must active send a SYN
push_segments_out(true);
}
TCPConnection::~TCPConnection() {
try {
if (active()) {
// Your code here: need to send a RST segment to the peer
cerr << "Warning: Unclean shutdown of TCPConnection\n";
unclean_shutdown(true);
}
} catch (const exception &e) {
std::cerr << "Exception destructing TCP FSM: " << e.what() << std::endl;
}
}
bool TCPConnection::push_segments_out(bool send_syn) {
// default not send syn before recv a SYN
_sender.fill_window(send_syn || in_syn_recv());
TCPSegment seg;
while (!_sender.segments_out().empty()) {
seg = _sender.segments_out().front();
_sender.segments_out().pop();
if (_receiver.ackno().has_value()) {
seg.header().ack = true;
seg.header().ackno = _receiver.ackno().value();
seg.header().win = _receiver.window_size();
}
if (_need_send_rst) {
_need_send_rst = false;
seg.header().rst = true;
}
_segments_out.push(seg);
}
clean_shutdown();
return true;
}
void TCPConnection::unclean_shutdown(bool send_rst) {
_receiver.stream_out().set_error();
_sender.stream_in().set_error();
_active = false;
if (send_rst) {
_need_send_rst = true;
if (_sender.segments_out().empty()) {
_sender.send_empty_segment();
}
push_segments_out();
}
}
bool TCPConnection::clean_shutdown() {
if (_receiver.stream_out().input_ended() && !(_sender.stream_in().eof())) {
_linger_after_streams_finish = false;
}
if (_sender.stream_in().eof() && _sender.bytes_in_flight() == 0 && _receiver.stream_out().input_ended()) {
if (!_linger_after_streams_finish || time_since_last_segment_received() >= 10 * _cfg.rt_timeout) {
_active = false;
}
}
return !_active;
}
bool TCPConnection::in_listen() { return !_receiver.ackno().has_value() && _sender.next_seqno_absolute() == 0; }
bool TCPConnection::in_syn_recv() { return _receiver.ackno().has_value() && !_receiver.stream_out().input_ended(); }
bool TCPConnection::in_syn_sent() {
return _sender.next_seqno_absolute() > 0 && _sender.bytes_in_flight() == _sender.next_seqno_absolute();
}
通关截图:
性能测试结果:
本地的WSL,Intel(R) Core(TM) i5-6200U CPU @ 2.30GHz,Ubuntu 18.04.5 LTS
kang@DICE-KNIGHT:~/sponge/build$ ./apps/tcp_benchmark
CPU-limited throughput : 0.67 Gbit/s
CPU-limited throughput with reordering: 0.52 Gbit/s
阿里云主机,Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz,CentOS Linux release 7.8.2003 (Core)
[kang@toy build]$ ./apps/tcp_benchmark
CPU-limited throughput : 0.63 Gbit/s
CPU-limited throughput with reordering: 0.53 Gbit/s
已经大大超过了讲义要去的最低性能0.1Gbit/s,所以可以宣告完工了!
瓶颈优化#
别以为这样就结束了!
虽然讲义要求最低达到0.1Gbit/s即可,可讲义里的示例可是我们效率的数倍啊!
user@computer: ~ /sponge/build$ ./apps/tcp benchmark
CPU-limited throughput : 1.78 Gbit/s
CPU-limited throughput with reordering: 1.21 Gbit/s
为了挑战这一数值我们需要利用之前看过的《深入理解计算机系统》中性能优化的知识。
第一步,查找性能瓶颈
首先修改sponge/etc/cflags.cmake中的编译参数,将-g改为-Og -pg,使生成的程序具有分析程序可用的链接信息。
然后编译并执行一遍benchmark程序,并将分析结果写入文本中
make -j8
./apps/tcp_benchmark
gprof ./apps/tcp_benchmark > prof.txt
vim prof.txt

可以看到write,pop,peek三个操作公共占据了80%左右的运行时间,所以我们主要对ByteStream类进行优化。
做这里我去狂补了一通std::move,assign,右值引用等C++11新特性,然后把sponge/libsponge/util/buffer.cc的代码翻了个底朝天,终于领悟了原来是要用这里面 BufferList类来作为ByteStream的容器,使得原来基于内存拷贝的存储方法变为基于内存所有权转移的存储方法。
比较尴尬的是虽然给了BufferList的代码,但没有示例,使用方法只能多看看源码了。
最终代码:
byte_stream.hh
#include "util/buffer.hh"
class ByteStream {
private:
BufferList _buffer = {};
//......
byte_stream.cc
//......
size_t ByteStream::write(const string &data) {
size_t len = data.length();
if (len > _capacity - _buffer.size()) {
len = _capacity - _buffer.size();
}
_write_count += len;
_buffer.append(BufferList(move(string().assign(data.begin(),data.begin()+len))));
return len;
}
//! \param[in] len bytes will be copied from the output side of the buffer
string ByteStream::peek_output(const size_t len) const {
size_t length = len;
if (length > _buffer.size()) {
length = _buffer.size();
}
string s=_buffer.concatenate();
return string().assign(s.begin(), s.begin() + length);
}
//! \param[in] len bytes will be removed from the output side of the buffer
void ByteStream::pop_output(const size_t len) {
size_t length = len;
if (length > _buffer.size()) {
length = _buffer.size();
}
_read_count += length;
_buffer.remove_prefix(length);
return;
}
//......
最终成绩:
本地的WSL,Intel(R) Core(TM) i5-6200U CPU @ 2.30GHz,Ubuntu 18.04.5 LTS
kang@DICE-KNIGHT:~/sponge/build$ ./apps/tcp_benchmark
CPU-limited throughput : 1.84 Gbit/s
CPU-limited throughput with reordering: 0.64 Gbit/s
阿里云主机,Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz,CentOS Linux release 7.8.2003 (Core)
[kang@toy build]$ ./apps/tcp_benchmark
CPU-limited throughput : 1.83 Gbit/s
CPU-limited throughput with reordering: 1.14 Gbit/s
可以看到经过优化后的代码在CentOS的阿里云主机上的性能已经达到了讲义所给示例的水平。但本地的reordering能力比云主机差半截,一开始怀疑是WSL的问题,后来我换了几台Ubuntu系统的电脑做测试,reordering始终不高,可能是Ubuntu特性吧。
不论怎样,停停走走历时二十多天,我们最终实现了一个能用的TCP协议,值得欢呼了。
LAB5#
这节要求实现一个ARP协议,在网络层与链路层间搭个桥,难度比LAB4低很多。要完成本节作业,除了熟读讲义和各个工具类的接口外,还可以参考这篇文章:ARP详解。
需要提一下的地方就是发送一个ARP request后,如果没有响应要五秒后重发,且在上一个请求被正常响应之前其他的请求都要排在后面。而讲义里并没有提到过这一点,导致最后make check_lab5完一看是闻所未闻的错误提示,一寻思还得再添加不少新代码,就比较不爽。
network_interface.hh
class NetworkInterface {
private:
//......
struct arp_item{
EthernetAddress mac;
size_t ttl;
};
struct waiting_frame{
EthernetFrame frame;
uint32_t ip;
};
std::map<uint32_t, arp_item> _table{};
std::queue<waiting_frame> _frames_waiting{};
std::queue<uint32_t> _pending_arg{};
bool _pending_flag=false;
size_t _pending_timer=0;
size_t _timer=0;
bool _ethernet_address_equal(EthernetAddress addr1,EthernetAddress addr2);
void _retransmission_arp_frame();
//......
network_interface.cc
void NetworkInterface::send_datagram(const InternetDatagram &dgram, const Address &next_hop) {
// convert IP address of next hop to raw 32-bit representation (used in ARP header)
const uint32_t next_hop_ip = next_hop.ipv4_numeric();
EthernetFrame frame;
frame.header().type = EthernetHeader::TYPE_IPv4;
frame.header().src = _ethernet_address;
frame.payload() = move(dgram.serialize());
if (_table.count(next_hop_ip) && _timer <= _table[next_hop_ip].ttl) {
frame.header().dst = _table[next_hop_ip].mac;
_frames_out.push(frame);
} else {
_pending_arg.push(next_hop_ip);
_retransmission_arp_frame();
_frames_waiting.push({frame, next_hop_ip});
}
}
optional<InternetDatagram> NetworkInterface::recv_frame(const EthernetFrame &frame) {
if (!_ethernet_address_equal(frame.header().dst, ETHERNET_BROADCAST) &&
!_ethernet_address_equal(frame.header().dst, _ethernet_address)) {
return nullopt;
} else if (frame.header().type == EthernetHeader::TYPE_IPv4) {
InternetDatagram dgram;
if (dgram.parse(frame.payload()) == ParseResult::NoError) {
return dgram;
} else {
return nullopt;
}
} else if (frame.header().type == EthernetHeader::TYPE_ARP) {
ARPMessage msg;
if (msg.parse(frame.payload()) == ParseResult::NoError) {
uint32_t ip = msg.sender_ip_address;
_table[ip].mac = msg.sender_ethernet_address;
_table[ip].ttl = _timer + 30 * 1000; // active mappings last 30 seconds
if (msg.opcode == ARPMessage::OPCODE_REQUEST && msg.target_ip_address == _ip_address.ipv4_numeric()) {
ARPMessage reply;
reply.opcode = ARPMessage::OPCODE_REPLY;
reply.sender_ethernet_address = _ethernet_address;
reply.sender_ip_address = _ip_address.ipv4_numeric();
reply.target_ethernet_address = msg.sender_ethernet_address;
reply.target_ip_address = msg.sender_ip_address;
EthernetFrame arp_frame;
arp_frame.header().type = EthernetHeader::TYPE_ARP;
arp_frame.header().src = _ethernet_address;
arp_frame.header().dst = msg.sender_ethernet_address;
arp_frame.payload() = move(reply.serialize());
_frames_out.push(arp_frame);
}
while (!_pending_arg.empty()){
uint32_t t_ip=_pending_arg.front();
if(_table.count(t_ip) && _timer <= _table[t_ip].ttl){
_pending_arg.pop();
_pending_flag=false;
}
else {
break;
}
}
while (!_frames_waiting.empty()) {
waiting_frame node = _frames_waiting.front();
if (_table.count(node.ip) && _timer <= _table[node.ip].ttl) {
node.frame.header().dst = _table[node.ip].mac;
_frames_waiting.pop();
_frames_out.push(move(node.frame));
} else {
break;
}
}
} else {
return nullopt;
}
}
return nullopt;
}
void NetworkInterface::tick(const size_t ms_since_last_tick) {
_timer += ms_since_last_tick;
_retransmission_arp_frame();
}
bool NetworkInterface::_ethernet_address_equal(EthernetAddress addr1, EthernetAddress addr2) {
for (int i = 0; i < 6; i++) {
if (addr1[i] != addr2[i]) {
return false;
}
}
return true;
}
void NetworkInterface::_retransmission_arp_frame(){
if(!_pending_arg.empty()){
// pending mappings last five seconds
if (!_pending_flag || (_pending_flag && _timer - _pending_timer >= 5000)) {
uint32_t ip=_pending_arg.front();
ARPMessage msg;
msg.opcode = ARPMessage::OPCODE_REQUEST;
msg.sender_ethernet_address = _ethernet_address;
msg.sender_ip_address = _ip_address.ipv4_numeric();
msg.target_ethernet_address = {0, 0, 0, 0, 0, 0};
msg.target_ip_address = ip;
EthernetFrame arp_frame;
arp_frame.header().type = EthernetHeader::TYPE_ARP;
arp_frame.header().src = _ethernet_address;
arp_frame.header().dst = ETHERNET_BROADCAST;
arp_frame.payload() = move(msg.serialize());
_frames_out.push(arp_frame);
_pending_flag = true;
_pending_timer = _timer;
}
}
}
LAB6#
这节要求实现基于最长前缀匹配规则的路由器转发功能。难度嘛......大概比LAB0还要简单一点。怪不得大伙儿在网上都是把LAB5、LAB6一笔带过。
因为讲义里讲这次实验即便是O(N)的时间复杂度也完全可以接受,所以我直接用vector作为路由转发表的容器了。
此外需要注意的大概只有当next_hop为空的时候代表该路由器为目的路由器,此时next_hop取dgram的目的IP地址。
router.hh
class Router{
private:
//.......
struct RouteItem {
uint32_t route_prefix = 0;
uint8_t prefix_length = 0;
std::optional<Address> next_hop = std::nullopt;
size_t interface_num = 0;
};
std::vector<RouteItem> _route_list{};
bool prefix_equal(uint32_t ip1, uint32_t ip2, uint8_t len);
//.......
router.cc
void Router::add_route(const uint32_t route_prefix,
const uint8_t prefix_length,
const optional<Address> next_hop,
const size_t interface_num) {
_route_list.push_back(RouteItem{route_prefix, prefix_length, next_hop, interface_num});
}
void Router::route_one_datagram(InternetDatagram &dgram) {
bool route_found = false;
RouteItem item;
uint32_t dst_ip = dgram.header().dst;
for (size_t i = 0; i < _route_list.size(); i++) {
if (prefix_equal(dst_ip, _route_list[i].route_prefix, _route_list[i].prefix_length)) {
if (!route_found || item.prefix_length < _route_list[i].prefix_length) {
item = _route_list[i];
route_found = true;
}
}
}
if (!route_found) {
return;
}
if (dgram.header().ttl <= 1) {
return;
}
dgram.header().ttl--;
if (item.next_hop.has_value()) {
_interfaces[item.interface_num].send_datagram(dgram, item.next_hop.value());
} else { // if not have next_hop, the next_hop is dgram's destination hop
_interfaces[item.interface_num].send_datagram(dgram, Address::from_ipv4_numeric(dgram.header().dst));
}
}
bool Router::prefix_equal(uint32_t ip1, uint32_t ip2, uint8_t len) {
// special judge right when shift 32 bit
uint32_t offset = (len == 0) ? 0 : 0xffffffff << (32 - len);
printf("ip cmp: %x %x, offset: %x\n", ip1 & offset, ip2 & offset, offset);
return (ip1 & offset) == (ip2 & offset);
}
至此,CS144所有LAB均已完成,原本计划两个周,没想都最后花了近一个月。不过过程还是很充实的,我永远忘不了半夜调试LAB4调到骂娘的暴躁感受,也忘不了对着样例源码喊出无数遍的“这又什么阴间BUG啊?”。最后十分感谢斯坦福的前人们给了我这次黄金体验的机会。
最终git log截图:
下个挑战课程该轮到数据库了......



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通