ChCore Lab2 内存管理 实验笔记
本文为上海交大 ipads 研究所陈海波老师等人所著的《现代操作系统:原理与实现》的课程实验(LAB)的学习笔记的第二篇。所有章节的笔记可在此处查看:chcore | 康宇PL's Blog
实验准备
首先一句 git merge lab2 把 Lab 2 分支合并到当前分支下。
这章中为了方便调试我手动将 CMakeLists.txt 中构建类型从 Release 改为 Debug
set(CMAKE_BUILD_TYPE "Debug") # "Release" or "Debug"
物理内存管理
物理内存布局
问题 1
请简单解释,在哪个文件或代码段中指定了 ChCore 物理内存布局。你可以从两个方面回答这个问题: 编译阶段和运行时阶段。
还是用 ASCII Flow 画了个图:
┌─────────────┐◄─ page_end (metadata_end + (npages * PAGE_SIZE))
│ │
│ pages │
│ │
├─────────────┤◄─ metadata_end (img_end + (npages * sizeof(struct page))
│page metadata│
│ │
├─────────────┤◄─ metadata_start (img_end)
│ KERNEL IMG │
├─────────────┤◄─ init_end
│ bootloader │
├─────────────┤◄─ 0x00080000 (img_start, init_start)
│ reserved │
└─────────────┘◄─ 0x00000000
首先 我们在 Lab 1 的练习 4 里分析过 chcore 的链接脚本了。脚本里可以知道 reserved、bootloader、KERNEL IMG 这几个段的信息。这些都是在编译时可以确定的。
-
bootloader: Lab 1 里我们可以知道 img_start 和 init_start 都被硬编码为了 0x80000,分别代表 chcore 镜像的开始地址和 bootloader 的开始地址。整个 .init 段就是 bootloader 所有代码和全局变量的内存空间。至于 booloader 里的临时变量,我们在汇编课里学过临时变量优先放在寄存器里,其次选择放在函数栈里。放在寄存器里的不占内存;放在函数栈的,因为 bootloader 的函数栈就是一个全局数组,所以本质上还是放在全局变量里。
-
KERNEL IMG:这一块就是内核所有代码和全局变量的空间。链接脚本里指明了 .init 段之后就是内核的 .text、 .rodata、 .bss 等等的程序段。这些段的末尾就是镜像的末尾 img_end。为什么内核分这么多个段而 bootloader 只有一个段呢?因为 Lab 1 我们发现 CMakeLists.txt 中将 bootloader 所有的目标文件打包成了一个 init_object 的整体然后放在了 .init 段里。
-
reserved:bootloader 是从 0x00080000 之后放的。从 0x00000000 到 0x00080000 就是保留的区域,不使用。它的作用需要学完虚拟内存整章才能明白:把开头留出来是为了在方便在访问空指针时报段错误。因为这一段没有做任何映射,所以访问必引发异常。
再说 page metadata 和 pages。这两块都是运行时才能确定的。给这俩分配空间的过程在 kernel/mm.c 的 mm_init 函数里。
void mm_init(void)
{
vaddr_t free_mem_start = 0;
struct page *page_meta_start = NULL;
u64 npages = 0;
u64 start_vaddr = 0;
// 将 free_mem_start 指定为 img_end 并内存对齐
free_mem_start =
phys_to_virt(ROUND_UP((vaddr_t) (&img_end), PAGE_SIZE));
npages = NPAGES;
start_vaddr = START_VADDR;
// 预留最大页数 * page 结构体的内存作为 page metadata 的空间
if ((free_mem_start + npages * sizeof(struct page)) > start_vaddr) {
BUG("kernel panic: init_mm metadata is too large!\n");
}
// 物理页从 page metadata 之后的区域开始分配
page_meta_start = (struct page *)free_mem_start;
// 初始化 slab 和 buddy 这俩物理内存分配器
/* buddy alloctor for managing physical memory */
init_buddy(&global_mem, page_meta_start, start_vaddr, npages);
/* slab alloctor for allocating small memory regions */
init_slab();
map_kernel_space(KBASE + (128UL << 21), 128UL << 21, 128UL << 21);
//check whether kernel space [KABSE + 256 : KBASE + 512] is mapped
kernel_space_check();
}
- page metadata 是每个物理页的元数据,是一个
struct page,主要记录了当前物理页是否被分配、由哪个物理内存分配器管理、前后的页是谁等等。 - pages 就是我们要用的物理页,每个的大小由
PAGE_SIZE宏定义,为 4K。每个物理页都有对应的元数据。
伙伴系统
buddy system 核心思想
buddy system 的核心思想是把可供分配物理内存都分割成大小为 2 的整数次幂的块,并建立多个空闲块链表,将所有相同大小的块存放在同一个链表中。
当申请大小为 x 的块时,先会将 x 向上取整成 2 的整数次幂的形式。比如申请 15k 就会向上取整为 16k。此时再在管理 16k 大小的块的链表里取一个块出来。如果链表为空,那就继续向上申请块,大小为 32k、64k、128k ...... 假如申请到了一个 32k 的块,而我们只需要 16k,那就把 32k 块分割成两个 16k 的大小相等的伙伴块,一个用作申请的结果,另一个放回 16k 块的空闲链表里。
当回收某个块时,会检查它的伙伴块是否为空闲块,是的话就把它和伙伴块合并为一个总大小为当前 2 倍的块。然后递归的重复这一过程,直到伙伴块不是空闲块为止。最后把合并好的大块再插入对应的空闲块链表中。
引用讲义中的两张图:
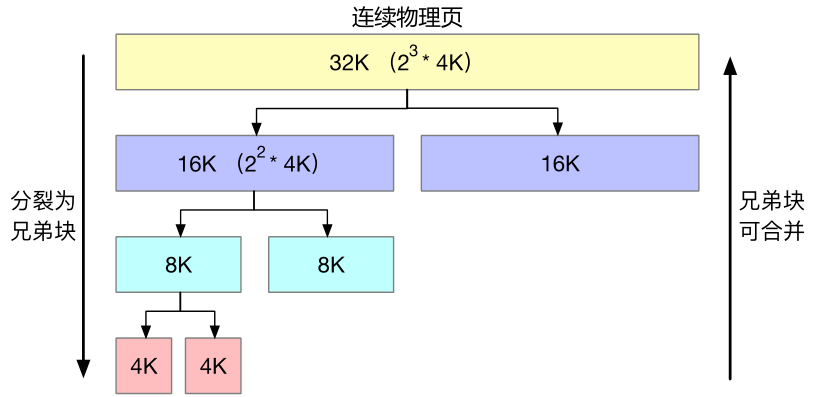
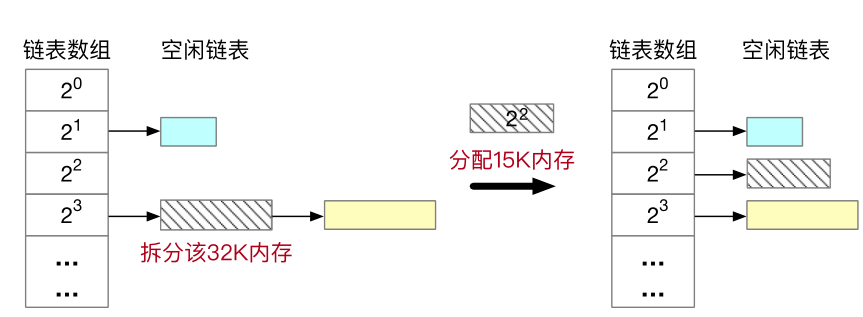
物理内存的组织方式
继续讲解伙伴系统前我们先研究下 chcore 里怎么组织物理内存的。
在前面的 mem_init 函数里我们求出了 page metadata 和 pages 的起始地址,以及可供分配的内存总量。由这些信息我们可以定义一个内存池 phys_mem_pool,在内存池里定义了多个空闲块链表 free_list。
/* Disjoint physical memory can be represented by several phys_mem_pool. */
struct phys_mem_pool {
u64 pool_start_addr; // 用于分配的内存区域的起始虚拟地址
u64 pool_mem_size; // 内存池总容量
u64 pool_phys_page_num; // 物理页个数
struct page *page_metadata; // 页元数据的数组
struct free_list free_lists[BUDDY_MAX_ORDER]; // 多级的空闲页链表
};
为了方便计数每个空闲块链表里维护了空闲块的个数 nr_free 和它所管理的空闲块的链表 free_list。(一个 free_list 是结构体名,一个 free_list 是变量名)
struct free_list {
struct list_head free_list;
u64 nr_free;
};
struct list_head {
struct list_head *prev;
struct list_head *next;
};
free_list 并不直接把 page 穿成链表,而是把 page 里的 list_head 类型的成员 node 传成了链表。画个图就是:
/* `struct page` is the metadata of one physical 4k page. */
struct page {
/* Free list */
struct list_head node;
/* Whether the correspond physical page is free now. */
int allocated;
/* The order of the memory chunck that this page belongs to. */
int order;
/* Used for ChCore slab allocator. */
void *slab;
};
/*
page page page
free_list ┌────┐ ┌────┐ ┌────┐
┌─────────┐ │ │ │ │ │ │
│nr_free │ │ │ │ │ │ │
├─────────┤ ─►├────┼─►├────┼─►├────┼─►
│free_list├───► │node│ │node│ │node│
└─────────┘ ◄─┴────┘◄─┴────┘◄─┴────┘◄─
*/
要将 list_head 转成 page 可以使用宏 list_entry(ptr, type, field), ptr 是指向结构体 type 内成员 field 的指针,通过把 type 里的成员 field 作为偏移量使用,并将 ptr 指针减去这个偏移量,就可以将 ptr 转换成 type 类型的指针了。
#define list_entry(ptr, type, field) \
container_of(ptr, type, field)
#define container_of(ptr, type, field) \
((type *)((void *)(ptr) - (u64)(&(((type *)(0))->field))))
// 示例
struct page *page = list_entry(pool->free_lists[current_order].free_list.next, struct page, node);
快速找到伙伴块
接下来分析 buddy.c 中已经实现的 init_buddy 和 get_buddy_chunk
void init_buddy(struct phys_mem_pool *pool, struct page *start_page,
vaddr_t start_addr, u64 page_num)
{
int order;
int page_idx;
struct page *page;
/* 初始化内存池 */
pool->pool_start_addr = start_addr;
pool->page_metadata = start_page;
pool->pool_mem_size = page_num * BUDDY_PAGE_SIZE;
/* This field is for unit test only. */
pool->pool_phys_page_num = page_num;
/* 初始化 free_lists,将每个链表清空,并将计数器设为 0 */
for (order = 0; order < BUDDY_MAX_ORDER; ++order) {
pool->free_lists[order].nr_free = 0;
init_list_head(&(pool->free_lists[order].free_list));
}
/* 清空元数据区 */
memset((char *)start_page, 0, page_num * sizeof(struct page));
/* 开始时先将每个 page 都设置为已分配,并将大小 order 标为 0 */
for (page_idx = 0; page_idx < page_num; ++page_idx) {
page = start_page + page_idx;
page->allocated = 1;
page->order = 0;
}
/* 将每个 page 做回收操作,通过 buddy_free_pages 归类到对应的 free_list 中 */
for (page_idx = 0; page_idx < page_num; ++page_idx) {
page = start_page + page_idx;
buddy_free_pages(pool, page);
}
}
// 找到指定块的伙伴块
static struct page *get_buddy_chunk(struct phys_mem_pool *pool,
struct page *chunk)
{
u64 chunk_addr;
u64 buddy_chunk_addr;
int order;
/* 根据 page 获取对应物理块的起始地址 */
chunk_addr = (u64) page_to_virt(pool, chunk);
order = chunk->order;
/* 做个异或操作获得当前伙伴块 */
#define BUDDY_PAGE_SIZE_ORDER (12)
buddy_chunk_addr = chunk_addr ^
(1UL << (order + BUDDY_PAGE_SIZE_ORDER));
/* Check whether the buddy_chunk_addr belongs to pool. */
if ((buddy_chunk_addr < pool->pool_start_addr) ||
(buddy_chunk_addr >= (pool->pool_start_addr +
pool->pool_mem_size))) {
return NULL;
}
return virt_to_page(pool, (void *)buddy_chunk_addr);
}
page 中的 order 成员代表当前的块内部包含 \(2^{order}\) 个物理页,比如一个 32k 大小的块,它内部包含 8 个物理页(每个物理页 4k 大),\(2^3 = 8\),所有 order 为 3 。
伙伴系统每次回收一个块时都要找到它的伙伴块。因为每个块内包含 2 的整数幂个物理页,每个物理页的大小也是 2 的整数幂的。所以互为伙伴的两个块的物理地址可以通过如下公式获得:
buddy_chunk_addr = chunk_addr ^ (1UL << (order + BUDDY_PAGE_SIZE_ORDER));
如果要确定两个伙伴块谁在左谁在右可以比较下它俩的物理地址高低,低的在左,高的在右。
练习1
实现kernel/mm/buddy.c中 的四个函数:buddy_get_pages(),split_page(),buddy_free_pages(),merge_page()。请参考伙伴块索引等功能的辅助函数: get_buddy_chunk()。
在着手实现前先思考一下,我们每次对 free_list 增删元素时都得手动修改下它的 nr_free,所以增删元素和增减 nr_free 这两对操作可以封装成俩函数。因为每个 page 里都记录了它的 order ,所以我们只需要指定存放所有 free_list 的内存池就可以根据 order 将 page 插入到对应的 free_list 中。
void page_append(struct phys_mem_pool *pool, struct page *page) {
struct free_list *free_list = &pool->free_lists[page->order];
list_add(&page->node, &free_list->free_list);
free_list->nr_free++;
}
void page_del(struct phys_mem_pool *pool, struct page *page) {
struct free_list *free_list = &pool->free_lists[page->order];
list_del(&page->node);
free_list->nr_free--;
}
merge_page 与 buddy_free_pages 的实现
// 对指定块向上递归的做合并操作
static struct page *merge_page(struct phys_mem_pool *pool, struct page *page)
{
// <lab2>
// 只能对空闲块做合并操作,禁止对已分配的块做合并操作
if (page->allocated) {
kwarn("Try to merge an allocated page\n", page);
return NULL;
}
// 合并前先将空闲块从它所属的 free_list 中拆出来
page_del(pool, page);
// 递归地向上合并空闲块,循环停止地条件:
// 1) 当前块的 order 已达到允许的最大值
// 2) 找不到伙伴块或者无法与伙伴块合并
while (page->order < BUDDY_MAX_ORDER - 1) {
struct page* buddy_page = get_buddy_chunk(pool, page);
// 只能与等大的、空闲的伙伴块合并
if (buddy_page == NULL ||
buddy_page->allocated ||
buddy_page->order != page->order) {
break;
}
// 调整下位置,保证 page 为左伙伴, buddy_page 为右伙伴
if(page > buddy_page) {
struct page *tmp = buddy_page;
buddy_page = page;
page = tmp;
}
// 做合并,将 buddy_page 标记为已分配并从 free_list 中删除
// 将 page 的 order ++
buddy_page->allocated = 1;
page_del(pool, page);
page->order++;
}
// 将合并后的块插入对应的 free_list 中
page_append(pool, page);
return page;
// </lab2>
}
// 回收指定块
void buddy_free_pages(struct phys_mem_pool *pool, struct page *page)
{
// <lab2>
// 空闲的块无法被回收
if (!page->allocated) {
kwarn("Try to free a free page\n");
return;
}
// 将块标记为空闲,并插入到 free_list 中
page->allocated = 0;
page_append(pool, page);
// 递归的向上合并块
merge_page(pool, page);
// </lab2>
}
split_page 与 buddy_get_pages 的实现
// 递归的分割块,直到分割至指定大小
static struct page *split_page(struct phys_mem_pool *pool, u64 order,
struct page *page)
{
// <lab2>
// 禁止分割已分配的块
if (page->allocated) {
kwarn("Try to split an allocated page\n");
return 0;
}
// 标记块为未分配,并从 free_list 中删除
page->allocated = 0;
page_del(pool, page);
// 递归的分割块,直到 order 变成指定大小
while (page->order > order) {
// 先缩小 order,再找到对应的伙伴块
// 操作后原先的 page 就变成了当前 page 和 buddy_page
page->order--;
struct page *buddy_page = get_buddy_chunk(pool, page);
// 把 buddy_page 插入 free_list 中
if (buddy_page != NULL) {
buddy_page->allocated = 0;
buddy_page->order = page->order;
page_append(pool, buddy_page);
}
}
return page;
// </lab2>
}
// 申请指定 order 的块
struct page *buddy_get_pages(struct phys_mem_pool *pool, u64 order)
{
// <lab2>
// 找到一个非空的,最够大的 free_list
int current_order = order;
while (current_order < BUDDY_MAX_ORDER && pool->free_lists[current_order].nr_free <= 0)
current_order++;
// 申请的 order 太大或者没有足够大的块能分配
if (current_order >= BUDDY_MAX_ORDER) {
kwarn("Try to allocate an buddy chunk greater than BUDDY_MAX_ORDER");
return NULL;
}
// 得到指定 free_list 的表头块
struct page *page = list_entry(pool->free_lists[current_order].free_list.next, struct page, node);
if (page == NULL){
kdebug("buddy get a NULL page\n");
return NULL;
}
// 分割块
split_page(pool, order, page);
// 将返回的块标记为已分配
page->allocated = 1;
return page;
// </lab2>
}
然后就是漫长的调试过程了。我本以为一两小时就能写完,但没想到最后总共花了 7 小时才完成了 buddy 的内容,下面提几点我踩的坑:
因为对链表的操作涉及到指针操作,稍不留神就会触发段错误。定位段错误可以使用 gdb 调试程序,执行到段错误的位置会自动停止,此时可以用 bt 指令看一下函数栈来定位下位置。
因为实验指南里给的测试命令是在 docker 里运行的,所以可能会出现找不到 gdb 的情形,这时候就得在 docker 里手动 apt 或者 yum 装个 gdb 了。但其实如果你依赖配置好的话, test_buddy 在本地就能编译运行,不需要 make docker,不过我还是建议新手用 docker,毕竟环境统一。
test_buddy 这个测试程序是输出到 stdout 的,为了辅助测试可以在 buddy.c 和 test_buddy.c 引用 stdio.h 写几句 printf ,只要记得在做后面的实验前删掉 include <stdio.h> 就行。比如我为了调试在 test_buddy.c 里的每条 mu_check 前都输出了要检查的变量。在这过程中我踩的一个坑就是 nr_free 是无符号数,减到 0 后再减会直接溢出为最大值。
虚拟内存管理
内核与用户地址空间分离
为了保护进程间的隔离性,每个进程都有自己的用户态页表,所有进程又使用同一份内核态页表。操作系统在上下文切换时会进行页表的切换。但大部分的内存都由内核使用(各种内核数据结构、各种内核模块的管理等等)。
AArch64 中提供了 TTBR0_EL1 和 TTBR1_EL1 两个页表基地址寄存器。
TTBR0_EL1 供用户态使用,进程上下文切换时会刷新。
TTBR1_EL1 供内核态使用,进程上下文切换时不会刷新。
这俩寄存器负责的虚拟地址范围可以通过 TCR_EL1 寄存器指定。一种方法是根据虚拟地址第 63 位的值决定,为 0 的话用 TTBR0_EL1,否则用 TTBR1_EL1。
问题2
AArch64 采用了两个页表基地址寄存器,相较于 x86-64 架构中只有一个页表基地址寄存器,这样的好处是什么?
分离用户态和内核态的寄存器使得在系统调用过程时不需要切换页表,因此也避免了 TLB 刷新的开销。
x86-64 体系仅提供一个页表基地址寄存器 CR3。但内核不使用单独的页表,而是把自己映射到应用程序的高地址部分,以此也避免了系统调用过程中造成的页表切换。
虚拟地址的组成
chcore 中使用四级页表实现虚拟地址到物理地址的映射
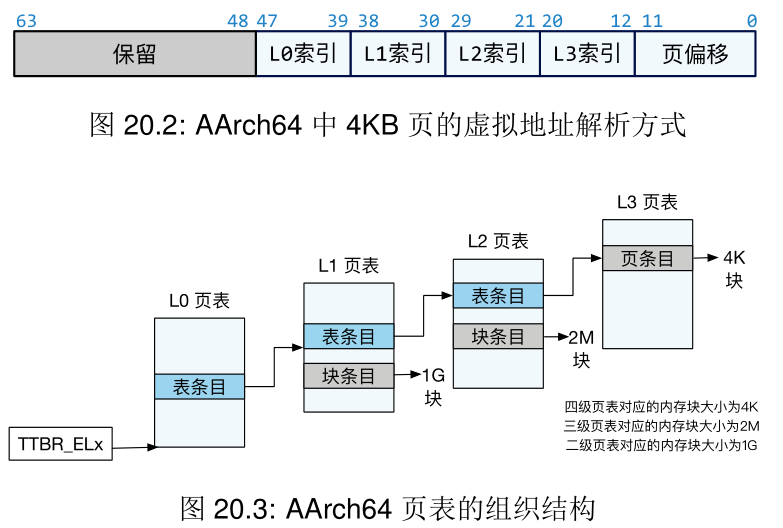
每一级页表中的条目结构如下:

想要理解表条目、块条目、页条目的区别,得看一源码:
/* table format */
typedef union {
struct {
u64 is_valid:1, is_table:1, ignored1:10, next_table_addr:36, reserved:4, ignored2:7, PXNTable:1, // Privileged Execute-never for next level
XNTable:1, // Execute-never for next level
APTable:2, // Access permissions for next level
NSTable:1;
} table;
struct {
u64 is_valid:1, is_table:1, attr_index:3, // Memory attributes index
NS:1, // Non-secure
AP:2, // Data access permissions
SH:2, // Shareability
AF:1, // Accesss flag
nG:1, // Not global bit
reserved1:4, nT:1, reserved2:13, pfn:18, reserved3:2, GP:1, reserved4:1, DBM:1, // Dirty bit modifier
Contiguous:1, PXN:1, // Privileged execute-never
UXN:1, // Execute never
soft_reserved:4, PBHA:4; // Page based hardware attributes
} l1_block;
struct {
u64 is_valid:1, is_table:1, attr_index:3, // Memory attributes index
NS:1, // Non-secure
AP:2, // Data access permissions
SH:2, // Shareability
AF:1, // Accesss flag
nG:1, // Not global bit
reserved1:4, nT:1, reserved2:4, pfn:27, reserved3:2, GP:1, reserved4:1, DBM:1, // Dirty bit modifier
Contiguous:1, PXN:1, // Privileged execute-never
UXN:1, // Execute never
soft_reserved:4, PBHA:4; // Page based hardware attributes
} l2_block;
struct {
u64 is_valid:1, is_page:1, attr_index:3, // Memory attributes index
NS:1, // Non-secure
AP:2, // Data access permissions
SH:2, // Shareability
AF:1, // Accesss flag
nG:1, // Not global bit
pfn:36, reserved:3, DBM:1, // Dirty bit modifier
Contiguous:1, PXN:1, // Privileged execute-never
UXN:1, // Execute never
soft_reserved:4, PBHA:4, // Page based hardware attributes
ignored:1;
} l3_page;
u64 pte;
} pte_t;
#define PTE_DESCRIPTOR_INVALID (0)
/* page_table_page type */
typedef struct {
pte_t ent[PTP_ENTRIES];
} ptp_t;
虽然这里面的标志位很多,但目前我们只要关心每个条目里存储的地址是啥作用就行。
表条目即 table 结构体,存储着下一级页表的表头物理地址。
页条目即 l3_page 结构体,存储着页框的物理地址。
块条目即 l1_block 和 l2_block,可以视作粒度更大的页,Lab 2 中作为选作的挑战。
每个页表都是一个 ptp_t 结构体,内部存储着一个 pte_t 条目数组。
虚拟地址的翻译
进行地址翻译时首先指定 L0 页表的基址,使用页表基址和 L0 索引定位到 L0 页表里的一个表条目,从中取出 L1 页表的基地址。递归进行这一过程,直到从 L3 页表里取出页框的基地址 pfn 为止。用该基地址与页偏移组合得到物理地址。
组合的具体方法是把 (pfn << PAGE_SHIFT) + GET_VA_OFFSET_L3(vir_addr) 。其中 PAGE_SHFIT 为 12,\(2^{12} == 4096\) ,恰好为一个页的大小。
为了更深入的理解地址翻译的流程,我们分析一下 kernel/mm/page_table.c 里的 get_next_ptp 函数。前面我们说过每个页表都是一个 ptp_t 结构体,内部存储着一个 pte_t 条目数组。get_next_ptp 函数的作用就是在指定当前页表的 ptp_t、页表等级、待寻址的虚拟地址这几个参数下求出下一级页表(对于 L3 页表来说求的就是页框)的虚拟地址和存储着这些元数据的 pte_t。
/*
* Find next page table page for the "va".
* 根据当前页表虚拟地址和指定虚拟地址求出下一级的页表或者物理页的虚拟地址
*
* cur_ptp: current page table page,当前的页表虚拟地址
* level: current ptp level,当前页表等级(0、1、2、3)
*
* next_ptp: returns "next_ptp",下一级页表的地址
* pte : returns "pte" (points to next_ptp) in "cur_ptp"
* 当前页表里存储着下一级页表的那个页表条项的地址
*
* alloc: if true, allocate a ptp when missing
*
*/
static int get_next_ptp(ptp_t * cur_ptp, u32 level, vaddr_t va,
ptp_t ** next_ptp, pte_t ** pte, bool alloc)
{
u32 index = 0;
pte_t *entry;
// 页表不存在,返回错误码
if (cur_ptp == NULL)
return -ENOMAPPING;
// 从虚拟地址里提取出指定等级的页表的索引(条目在上一级页表中的偏移值)
switch (level) {
case 0:
index = GET_L0_INDEX(va);
break;
case 1:
index = GET_L1_INDEX(va);
break;
case 2:
index = GET_L2_INDEX(va);
break;
case 3:
index = GET_L3_INDEX(va);
break;
default:
BUG_ON(1);
}
// 求出页表里条目的地址
entry = &(cur_ptp->ent[index]);
if (IS_PTE_INVALID(entry->pte)) {
if (alloc == false) {
return -ENOMAPPING;
} else {
/* alloc a new page table page */
ptp_t *new_ptp;
paddr_t new_ptp_paddr;
pte_t new_pte_val;
/* 分配一个物理页以此创建新的页条目 */
new_ptp = get_pages(0);
BUG_ON(new_ptp == NULL);
memset((void *)new_ptp, 0, PAGE_SIZE);
/* 页条目内部记录的地址都是物理地址 */
new_ptp_paddr = virt_to_phys((vaddr_t) new_ptp);
new_pte_val.pte = 0;
new_pte_val.table.is_valid = 1;
new_pte_val.table.is_table = 1;
// 做偏移运算,只保留基地址
// 因为 next_table_addr 定义为了 36 位,所以超出部分会自动截断
new_pte_val.table.next_table_addr
= new_ptp_paddr >> PAGE_SHIFT;
/* 因为 pte_t 是个 union,所以 new_pte_val.pte 的内容
和 new_pte_val.table相同 */
/* same effect as: cur_ptp->ent[index] = new_pte_val; */
entry->pte = new_pte_val.pte;
}
}
// 等价于求 entry 对应的 table.next_table_addr,然后转成虚拟地址
*next_ptp = (ptp_t *) GET_NEXT_PTP(entry);
*pte = entry;
if (IS_PTE_TABLE(entry->pte))
return NORMAL_PTP;
else
return BLOCK_PTP;
}
这里引出了几个问题:
下一级页表或者页框不存在时会怎样?根据指定的 alloc 参数,要么给你分配个页作为下一级页表,要么直接返回错误码 -ENOMAPPING 代表虚拟地址没有映射到物理地址上。
怎么区分 table 和 l3_page ?get_next_ptp 不做区分。观察下函数的流程可以发现只对 pte_t 中的 table.is_valid 、table.is_page 、table.next_table_addr 三个字段做了修改。而观察下 pte_t 的定义可知,这三个字段的长度和位置都恰好与 l3_page.is_valid 、l3_page.is_page 、l3_page.pfn 三个字段一一对应。所以 get_next_ptp 具有了一定的通用性,既可以分配页表也可以分配页框。只不过其他的标志位需要我们手动更改。
条目里存的表基址都是物理地址,而启用了虚拟内存后所有的地址都被解释为虚拟地址,我怎么把表基址的虚拟地址求出来?回一下 Lab 1 里我们对链接脚本的研究,内核的物理地址加上一个偏移量就能得到虚拟地址。所以在内核态我们不用费心的走页表也能完成地址翻译。那还用页表干啥呢?是为了服务用户态进程,内核态进程都共用一套虚拟地址空间,自然不需要区分。但用户态的进程彼此间是隔离的,为了保证隔离性、提高内存利用率、方便程序员实现我们提供了基于页表的虚拟内存机制。
问题3
1) 请问在页表条目中填写的下一级页表的地址是物理地址还是虚拟地址?
上面已经分析过了,无论是指向页表还是页框,条目里的地址都是物理地址。
2) 在 ChCore 中检索当前页表条目的时候,使用的页表基地址是虚拟地址还是物理地址?
页表地址是虚拟地址。上面说了因为内核态虚拟地址与物理地址间只差一个偏移量,所以不需要复杂的页表机制。但用户态进程需要这套东西。
问题4
1)如果我们有 4G 物理内存,管理内存需要多少空间开销? 这个开销是如何降低的?
假如只有一级页表。4G 内存,每页 4K,则总共有 \(10^6\) 个页,同样需要这么多个页条目。每个条目 4 字节,总共需要 4M 内存,只占千分之一。
为了节约开销,考虑到 4G 内存里大部分情况下都不会完全用完,所以我们使用了多级页表,只对那些使用了的物理页创建对应的页条目,以此节约了不少开销。弊端就是层数多了寻址会慢一点,内存占用率满了时页表占的内存相较于一级页表也会稍大一点。
2)总结一下 x86-64 和 AArch64 地址翻译机制的区别,AArch64 MMU 架构设计的优点是什么?
我能想到的点就是四级页表和两个页表基址寄存器了。
页表管理
练习2
在文件 kernel/mm/page_table.c 中,实现map_range_in_pgtbl(),unmap_range_in_pgtbl() 和query_in_pgtbl() 。可以调用辅助函数:set_pte_flags(), get_next_ptp(), flush_tlb()
第一步是在参透 get_next_ptp 的基础之上实现 query_in_pgtbl。实现虚拟地址到物理地址的翻译。
主要思路时多次使用 get_next_ptp 的到页框的物理基址,然后判断下合法性。合法的话求出对应的物理地址,不合法的话返回 -ENOMAPPING
/*
* Translate a va to pa, and get its pte for the flags
*/
/*
* query_in_pgtbl: translate virtual address to physical
* address and return the corresponding page table entry
*
* pgtbl @ ptr for the first level page table(pgd) virtual address
* va @ query virtual address
* pa @ return physical address
* entry @ return page table entry
*
* Hint: check the return value of get_next_ptp, if ret == BLOCK_PTP
* return the pa and block entry immediately
*/
int query_in_pgtbl(vaddr_t * pgtbl, vaddr_t va, paddr_t * pa, pte_t ** entry)
{
// <lab2>
ptp_t *cur_ptp = (ptp_t *)pgtbl;
ptp_t *next_ptp = NULL;
pte_t *next_pte = NULL;
int level = 0;
int err = 0;
// get page pte
while(level <= 3 &&
(err = get_next_ptp(cur_ptp, level, va, &next_ptp, &next_pte, false)) == NORMAL_PTP){
cur_ptp = next_ptp;
level++;
}
if(err == NORMAL_PTP){
// TODO: add hugepage support
if(level != 4) {
kwarn("query_in_pgtbl: level = %d < 4\n", level);
return -ENOMAPPING;
}
// page invalid
if(! next_pte->l3_page.is_valid || ! next_pte->l3_page.is_page){
return -ENOMAPPING;
}
// get phys addr
*pa = virt_to_phys((vaddr_t)next_ptp) + GET_VA_OFFSET_L3(va);
return 0;
}
// get an error
else if(err < 0) {
return err;
}
// should never be here
else {
kwarn("query_in_pgtbl: should never be here\n");
return err;
}
// </lab2>
return 0;
}
接着是 map_range_in_pgtbl 和 unmap_range_in_pgtbl 这一对操作。
map_range_in_pgtbl 我们可以借助 get_next_ptp 的 alloc 可参数来自动的完成新页表的创建,但只能创建指向 L1、L2、L3 的页表项。指向物理页框的页表项需要我们手动设置,如果用get_next_ptp 它会自动分配好一个页框,就没法按我们的要求指定物理地址了。手动设置的部分参考 get_next_ptp,主要是设置好 is_valid、is_page、pfn 这几个字段。然后用 set_pte_flags 设置下标识位。
与之对应的是在 unmap_range_in_pgtbl 我们要解除掉映射关系,这一步就是直接把 pte 所有位清零即可。
/*
* map_range_in_pgtbl: map the virtual address [va:va+size] to
* physical address[pa:pa+size] in given pgtbl
*
* pgtbl @ ptr for the first level page table(pgd) virtual address
* va @ start virtual address
* pa @ start physical address
* len @ mapping size
* flags @ corresponding attribution bit
*
* Hint: In this function you should first invoke the get_next_ptp()
* to get the each level page table entries. Read type pte_t carefully
* and it is convenient for you to call set_pte_flags to set the page
* permission bit. Don't forget to call flush_tlb at the end of this function
*/
int map_range_in_pgtbl(vaddr_t * pgtbl, vaddr_t va, paddr_t pa,
size_t len, vmr_prop_t flags)
{
// <lab2>
for(const vaddr_t end_va = va + len; va < end_va; va += PAGE_SIZE, pa += PAGE_SIZE) {
ptp_t *cur_ptp = (ptp_t *)pgtbl;
ptp_t *next_ptp = NULL;
pte_t *next_pte = NULL;
int level = 0;
int err = 0;
// get and create L3 ptp
while(level <= 2 &&
(err = get_next_ptp(cur_ptp, level, va, &next_ptp, &next_pte, true)) == NORMAL_PTP){
cur_ptp = next_ptp;
level++;
}
// map phys addr
u32 index = GET_L3_INDEX(va);
next_pte = &(cur_ptp->ent[index]);
next_pte->l3_page.is_valid = 1;
next_pte->l3_page.is_page = 1;
next_pte->l3_page.pfn = pa >> PAGE_SHIFT;
set_pte_flags(next_pte, flags, KERNEL_PTE);
}
flush_tlb();
// </lab2>
return 0;
}
/*
* unmap_range_in_pgtble: unmap the virtual address [va:va+len]
*
* pgtbl @ ptr for the first level page table(pgd) virtual address
* va @ start virtual address
* len @ unmapping size
*
* Hint: invoke get_next_ptp to get each level page table, don't
* forget the corner case that the virtual address is not mapped.
* call flush_tlb() at the end of function
*
*/
int unmap_range_in_pgtbl(vaddr_t * pgtbl, vaddr_t va, size_t len)
{
// <lab2>
for(const vaddr_t end_va = va + len; va < end_va; va += PAGE_SIZE) {
ptp_t *cur_ptp = (ptp_t *)pgtbl;
ptp_t *next_ptp = NULL;
pte_t *next_pte = NULL;
int level = 0;
int err = 0;
// get L3 ptp
while(level <= 2 &&
(err = get_next_ptp(cur_ptp, level, va, &next_ptp, &next_pte, false)) == NORMAL_PTP){
cur_ptp = next_ptp;
level++;
}
if(err == NORMAL_PTP && level == 3 && cur_ptp != NULL) {
// unmap page
u32 index = GET_L3_INDEX(va);
next_pte = &(cur_ptp->ent[index]);
next_pte->pte = 0;
}
}
flush_tlb();
// </lab2>
return 0;
}
之后又是喜闻乐见的调试环节,果真如讲义所说需要注意诸多边界条件。我就是因为把 va ~ va + len 当成一个闭区间吃了不少苦头。如果没有头绪就去研究下 tests/mm/page_table/test_aarch64_page_table.c,自己加点输出中间变量的代码试试。
做完这一部分的内容又花费了 7 个小时。
内核地址空间
ChCore 用一个宏 KBASE 将地址空间分为用户态和内核态两部分。为了保证隔离性,ChCore 使用页表中的权限位保证用户态进程只能访问用户态地址。
问题5
在 AArch64 MMU 架构中,使用了两个 TTBR 寄存器,ChCore 使用一个 TTBR 寄存器映射内核地址空间,另一个寄存器映射用户态的地址空间,那么是否还需要通过设置页表位的属性来隔离内核态和用户态的地址空间?
这里存疑,我个人觉得标识位是个冗余的存在。
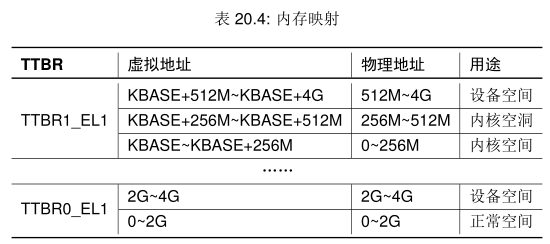
在 bootloader 的 init_boot_pt 函数中已经完成了设备空间和内核空间的映射。我们这一节只需要调用下前面写好的 map_range_in_pgtbl 完成内核空洞部分的映射就行。
问题6
1)ChCore 为什么要使用块条目组织内核内存? 哪些虚拟地址空间在 Boot 阶段必须映射,哪些虚拟地址空间可以在内核启动后延迟?
用块(2M)不用页(4K)的原因自然是因为内核内存访问的频率比较高,使用大页 TLB miss 出现的次数比使用普通页更少。
内存模块要用的地址应该在 boot 阶段完成映射,进程模块、文件系统模块等在虚拟内存启动之后才启动的可以在内核启动后延迟。
2)为什么用户程序不能读写内核内存? 保护内核内存的具体机制是什么?
访问内存时会用程序状态寄存器里的标识位和页表项的标识位做合法性检查,非法的话会触发一个保护异常。
练习3
完善kernel/mm/mm.c中的map_kernel_space()函数,实现对内核空间的映射,并且可以通过kernel_space_check()的检查。
就是单纯的函数调用,注意下标识位就行。
void map_kernel_space(vaddr_t va, paddr_t pa, size_t len)
{
// <lab2>
vaddr_t *ttbr1 = (vaddr_t *)get_ttbr1();
map_range_in_pgtbl(ttbr1, va, pa, len, KERNEL_PT);
// </lab2>
}
这部分比较简单,大概 1 个小时就整完了。
后记
做的挺爽,再来一个。
追更
网友 Syx-e 对练习 3 提出了问题,这里就留给后来的读者们实验吧。
2楼 2021-10-13 19:59 Syx-e
练习3要求映射的这段空间应该映射到2M块上而不是4KB的页上,虽然可以过,但可以尝试一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号