Django框架:10、Ajax补充说明、多对多三种创建方法、Django内置序列化组件、批量操作数据方法、分页器思路
Django框架
一、Ajax补充说明
1、针对前端回调函数接受值的说明
主要针对回调函数args接收到的响应数据
1、后端如何判断请求发出方式
- 关键词:is_ajax()
- 通过request点的方式可以判断请求是否由Ajax发出
def home(request):
print(request.is_ajax())
return render(request, 'homepage.html')
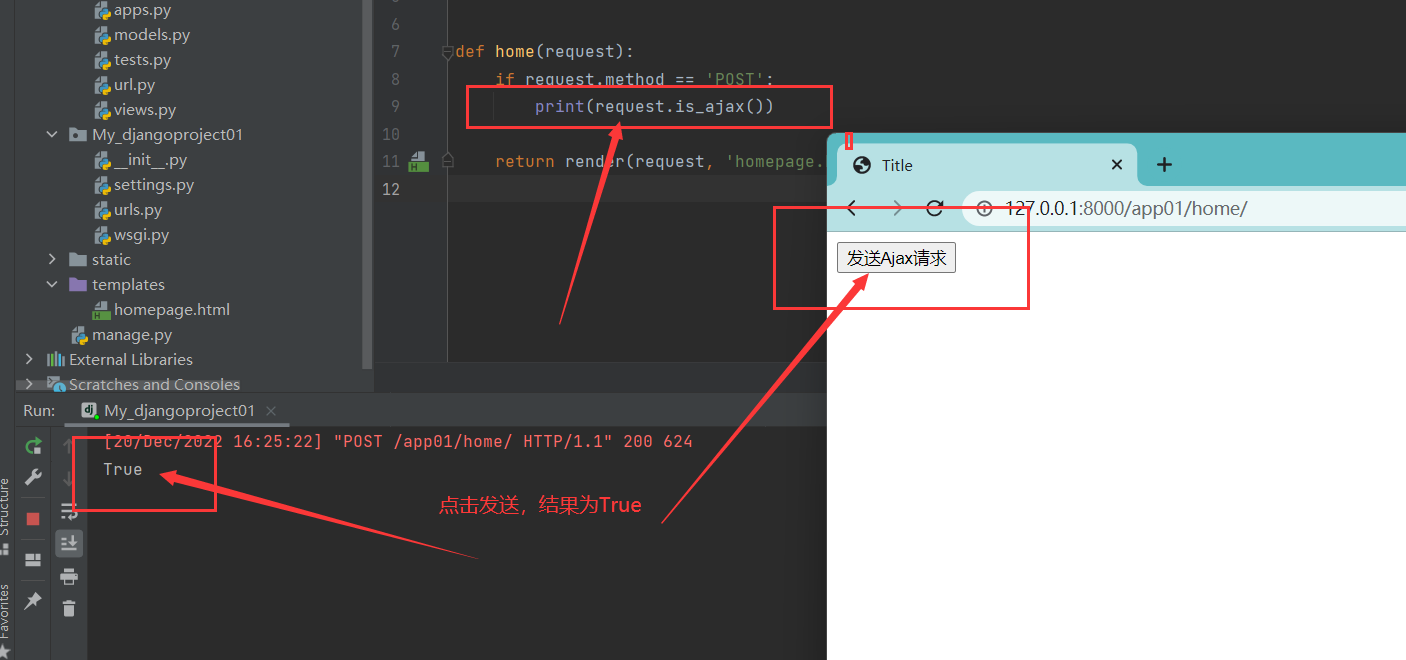
2、后端视图层return的返回值不在影响整个页面
在不使用ajax的时候,视图层函数return的返回值将直接影响整个页面,例如使用的’三板斧‘,会直接将返回结果影响到整个页面,而使用ajax后,返回值将会被前端页面ajax的回调函数所接收,不会影响到整个页面
# 视图层
def home(request):
if request.method == 'POST':
print(request.is_ajax())
return render(request, 'homepage.html')
return render(request, 'homepage.html')
# 前端HTML页面
<body>
<button id="d1">提交</button>
<script>
$('#d1').click(function () {
$.ajax({
url: '',
type: 'POST',
data: '{"name":"kang"}',
success: function (args) {
console.log(args)
}
})
})
</script>
</body>

3、选择Ajax做前后端交互时,后端一般都是返回字典数据
后端返回数据
在使用Ajax做交互的时候,后端一般都是返回字典类型的数据,需要将返回的数据转换成json格式,否则前端将无法接收
def home(request):
if request.method == 'POST':
print(request.is_ajax())
data = {'name': 'kangkang'}
# 需要返回的数据
import json
data = json.dumps(data)
# 将需要返回的数据进行序列化
return HttpResponse(data)
return render(request, 'homepage.html')
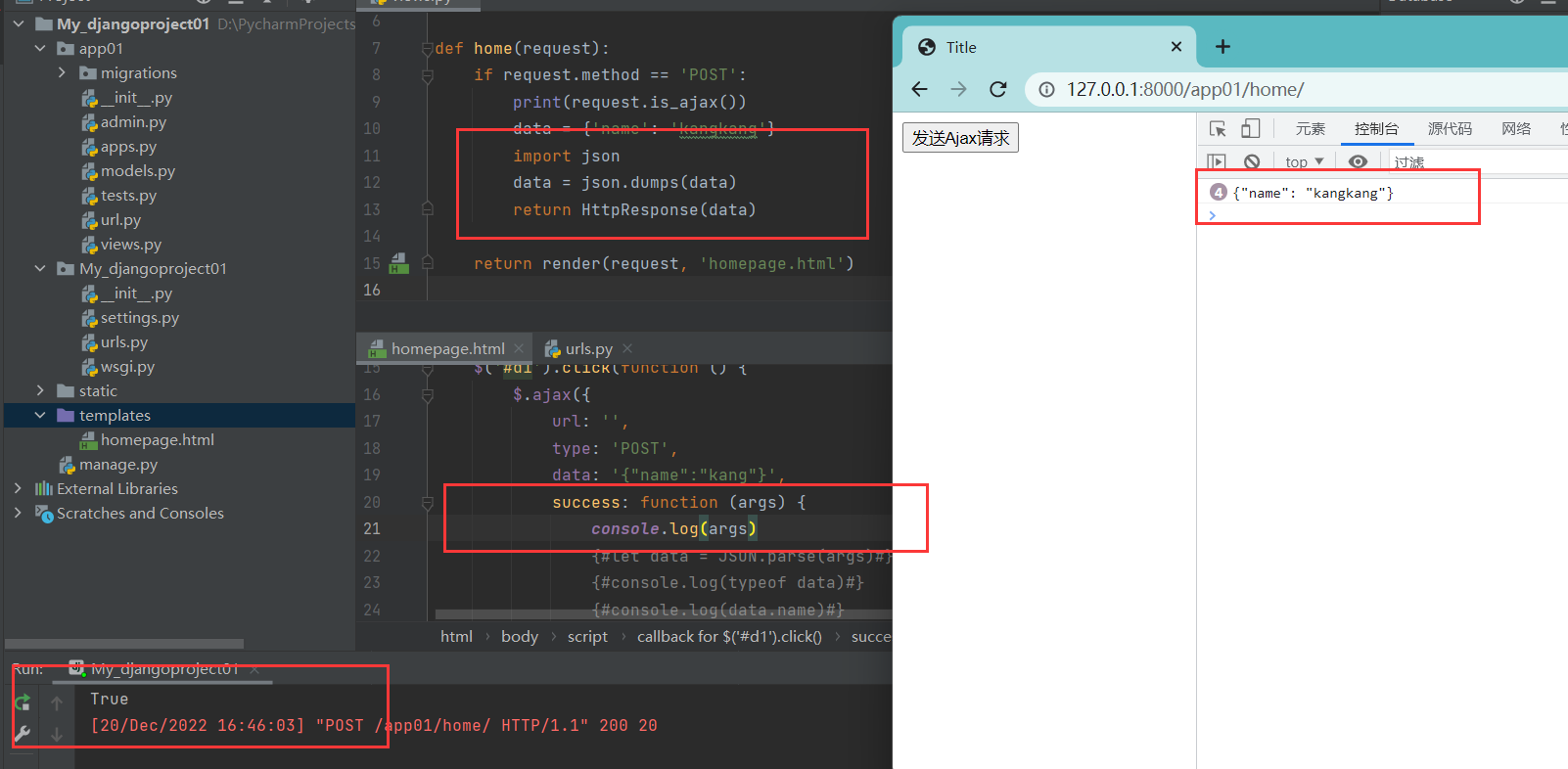
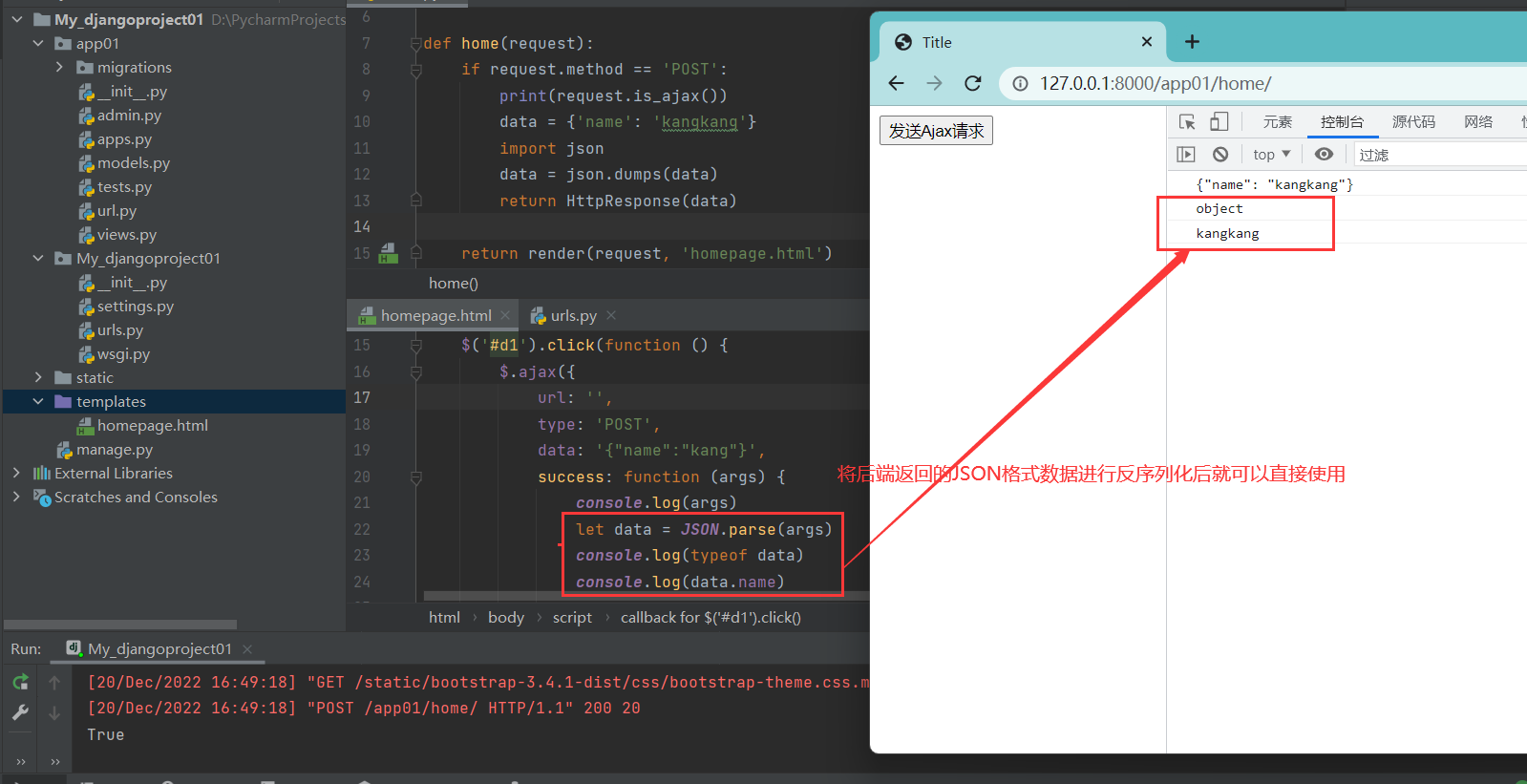
前端如何使用数据
针对发端发送的Json格式数据,前端是无法直接使用的,需要将json格式数据进行反序列化后才可以使用,反序列化后的数据会成为一个object对象,前端可以直接使用点的方式调用数据的值
success: function (args) {
console.log(args)
let data = JSON.parse(args)
# 将接收的数据进行反序列化
console.log(typeof data)
# 反序列化后的数据是一个object对象
console.log(data.name)
# 对象可以通过点的方式进行取值
}
JsonResponse对象方法
使用JsonResponse方法可以节省后端很多代码,而且此方法返回的值,前端不需要进行序列化就可以直接使用
# 导入JsonResponse对象
from django.http import JsonResponse
def home(request):
if request.method == 'POST':
data = {'name': 'kangkang'}
# 直接返回
return JsonResponse(data)
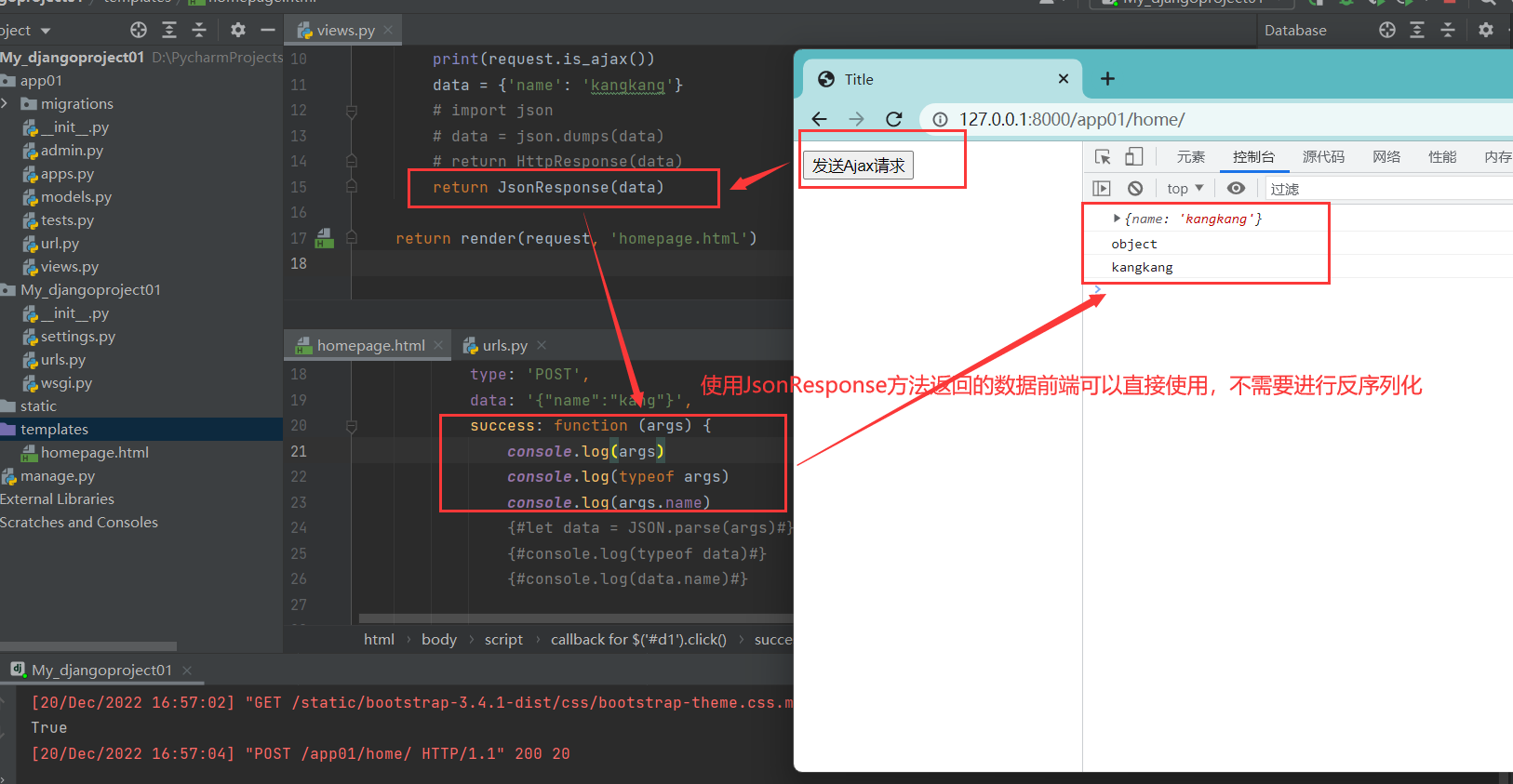
通过修改前端Ajax参数的方法
在前端没有使用JsonResponse的方法像后端传值时,前端可以通过设置参数的方式来进行自动反序列化操作
$.ajax({
url: '',
type: 'POST',
data: '{"name":"kang"}',
dataType:'json',
# 修改参数
success: function (args) {
console.log(args)
console.log(typeof args)
console.log(args.name)

二、多对多三种创建方式
1、自动创建
自动创建是指,在定义模板阶段,在模板内声明多对多外键字段,Django会自动识别,并创建出第三张表来存储多对多的关系
- 优点:全自动创建,提供了add、remove、set、clear四种操作
- 缺点:自动创建的第三张表无法创建更多的字段,拓展性较差
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author')
class Author(models.Model):
name = models.CharField(max_length=32)
2、纯手动创建
指,在针对多对多关系时,手动创建第三张表,在第三张表内声明多对多之间的关系
- 优点:全由自己创建,拓展性强
- 缺点:编写繁琐,并且不支持add、remove、set、clear以及正反向概念
class Book(models.Model):
title = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
others = models.CharField(max_length=32)
join_time = models.DateField(auto_now_add=True)
3、半自动创建
创建方法类似纯手动创建,但是需要在主表中在额外手动定义一个与从表的多对多关系字段,并且在该字段后放参数内声明关联的从表名和第三张表名以及多对多的关系
- 优点:第三张表由自己创建,拓展性强,正反向概念清晰
- 缺点:编写繁琐,不支持add、remove、set、clear
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author',
through='Book2Author', through_fields=('book','author')
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model):
book = models.ForeignKey(to='Book', on_delete=models.CASCADE)
author = models.ForeignKey(to='Author', on_delete=models.CASCADE)
others = models.CharField(max_length=32)
join_time = models.DateField(auto_now_add=True)
三、Django内置序列化组件
在实际项目中,针对前后端分离,通常后端试图函数只需要返回给前端json格式字典,来满足前端的增删改查即可,但是在后端ORM操作中,我们一般都是直接获取到数据对象,这并不满足向前端传送数据的需求,所以我们还需要对这些对象进行处理,将对象里的数据转换成一键值对的形式进行返回
手动处理
from app01 import models
from django.http import JsonResponse
def ab_ser_func(request):
# 1.查询所有的书籍对象
book_queryset = models.Book.objects.all() # queryset [对象、对象]
# 2.封装成大字典返回
data_dict = {}
for book_obj in book_queryset:
temp_dict = {}
temp_dict['pk'] = book_obj.pk
temp_dict['title'] = book_obj.title
temp_dict['price'] = book_obj.price
temp_dict['info'] = book_obj.info
data_dict[book_obj.pk] = temp_dict # {1:{},2:{},3:{},4:{}}
return JsonResponse(data_dict)
使用序列化组件
1、导入模块:
from django.core import serializers
from app01 import models
def ab_ser_func(request):
# 获取全部表对象
book_queryset = models.Book.objects.all()
# 生成序列化组件对象,第一个参数是选择序列化的方式
res = serializers.serialize('json', book_queryset)
# 直接将数据进行返回
return HttpResponse(res)
四、批量操作数据
批量操作数据是指,当前端访问的数据量较为庞大时,通过自己的方法进行处理时会暂用非常长的时间,下面通过代码展示
手动生成
这种方式是在不停的向数据库中插入数据,当数据比较庞大的时候时间非常的满,10秒500条左右
def temp(request):
# 设置一个循环,当用户访问时,生成10万条数据,并插入数据库
for i in range(1, 100000):
book = models.Book01.objects.create(title='number %s book' % i)
# 读出数据库中10万条数据,并传递到前端
obj_list = models.Book01.objects.all()
return render(request, 'temp.html', locals())
使用内置序列化组件
提前定义一个空列表,然后生成10万条数据添加到列表中去,再通过内置组件生成,然后展示到前端页面,5秒10万条数据
def temp(request):
# 提交定义一个空列表
book_obj_list = []
# 设置一个循环,生成10万条数据
for i in range(1, 100000):
book_obj = models.create(title='number %s book' % i)
# 将生成的对象添加到列表中去
book_list_obj.append(book_obj)
# 使用内置组件将对象添加到数据库中
# 读出数据库中10万条数据,并传递到前端
obj_list = models.Book01.objects.all()
return render(request, 'temp.html', locals())
五、分页器思路
分页器主要听处理逻辑 代码最后很简单
推导流程
1.queryset支持切片操作(正数)
2.研究各个参数之间的数学关系
每页固定展示多少条数据、起始位置、终止位置
3.自定义页码参数
current_page = request.GET.get('page')
4.前端展示分页器样式
5.总页码数问题
divmod方法
6.前端页面页码个数渲染问题
后端产生 前端渲染
六、自定义分页器的使用
django自带分页器模块但是使用起来很麻烦 所以我们自己封装了一个
只需要掌握使用方式即可
def ab_pg_func(request):
book_queryset = models.Books01.objects.all()
from app01.utils.mypage import Pagination
current_page = request.GET.get('page')
page_obj = Pagination(current_page=current_page, all_count=book_queryset.count())
page_queryset = book_queryset[page_obj.start:page_obj.end]
return render(request, 'pgPage.html', locals())
{% for book_obj in page_queryset %}
<p>{{ book_obj.title }}</p>
{% endfor %}
{{ page_obj.page_html|safe }}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号