Djiango框架:5、pycharm虚拟环境,视图层之三板斧、JsonResponse对象、request对象、FBV与CBV,模板层之模板语法、模板传值、模板过滤器
Django框架
一、pycharm虚拟环境
1、简介
虚拟环境:能够针对相同版本的解释器创建多个分身 每个分身可以有自己独立的环境
在以后的工作中,会遇到多个django项目,多个项目所需的模块和插件各不相同,如果都存储在一个项目中,就会造成资源浪费的现象,针对这个问题就可以使用虚拟环境,创建多个项目独立的环境
pycharm创建虚拟环境:(每创建一个虚拟环境就相当于重新下载了一个全新的解释器)
2、创建方法
cmd命令窗口创建
命令行的方式:
python -m venv pyvenv38
激活:
activate
关闭:
deactivate
注意:
python命令此处不支持多版本共存的操作,如果想要创建自己所需要的版本的虚拟环境,就需要去系统环境变量中将需要创建的版本的环境添加到其他版本的上方
pycharm中创建
二、视图层
1、视图层必会三板斧
用来处理请求的视图函数都必须返回HttpResponse
- HttpResponse()
- 用来返回一串字符
- render()
- 用来返回html模板,或是路由后缀
- redirect():
- 重定向
2、JsonResponse对象
作用:序列化成json格式的数据
json格式的数据有什么作用:
前后端数据交互需要使用用到json作为过渡,实现跨语言传输数据
# 补充:
前端序列化:
JSON.stringify()
JSON.parse()
后端序列化:
json.dumps()
json.loads()
引子
# 使用json模块序列化
import json
def ab_json(request):
user_dict = {'username':'gary我是张三','password':'123','hobby':'girl美女'}
# 将字典序列化为json格式的字符串
json_str = json.dumps(user_dict)
# 将序列化后的字符串返回
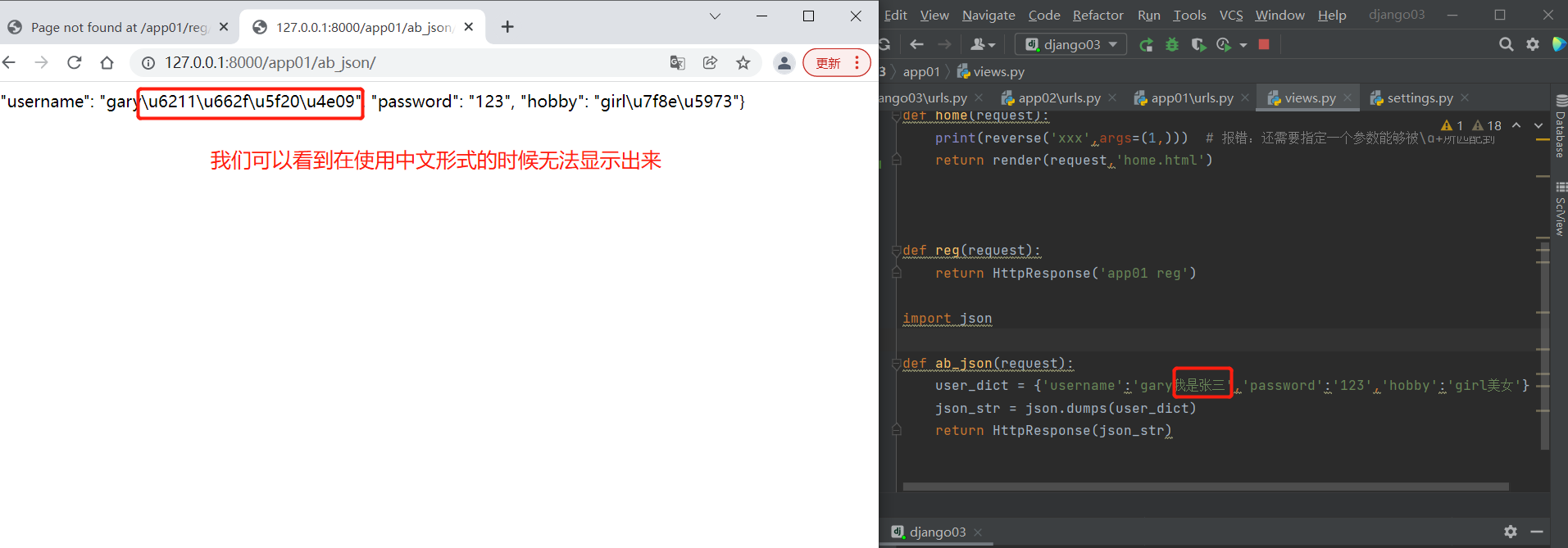
# 解决上述问题:
import json
def ab_json(request):
user_dict = {'username':'gary我是张三','password':'123','hobby':'girl美女'}
# 将字典序列化为json格式的字符串
json_str = json.dumps(user_dict,ensure_ascii=False) # 将内置编码修改
# 将序列化后的字符串返回
return HttpResponse(json_str)
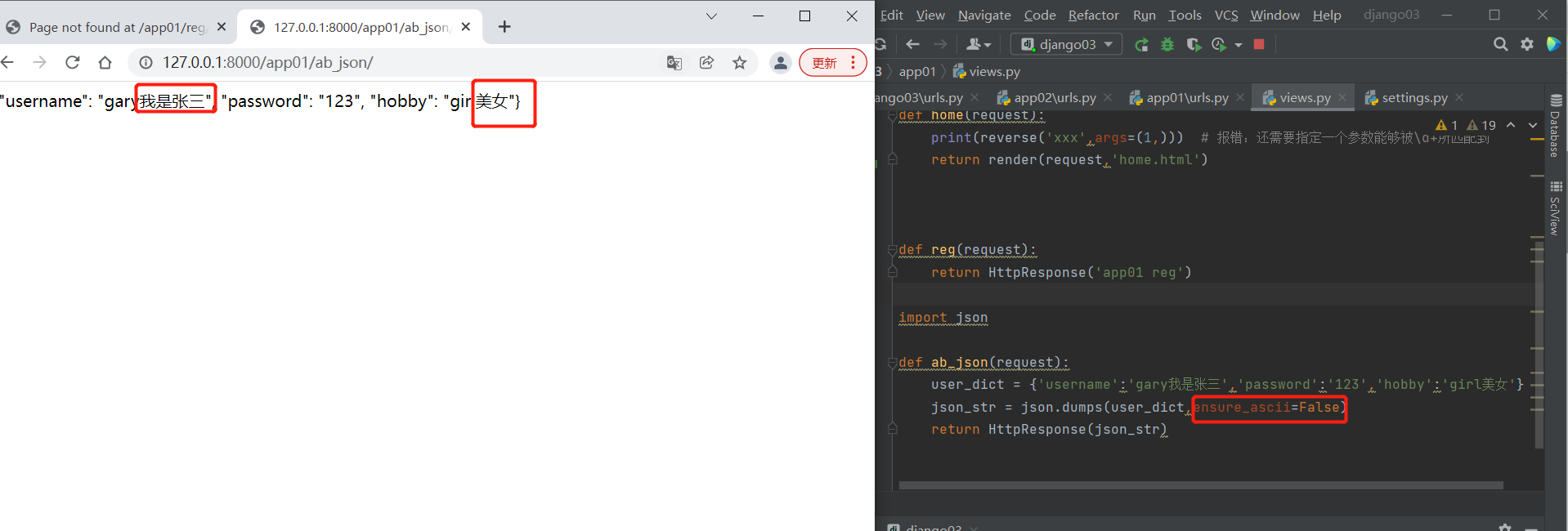
# django提供的模块
from django.http import JsonResponse
def ab_json(request):
user_dict = {'username':'gary我是张三','password':'123','hobby':'girl美女'}
return JsonResponse(user_dict)
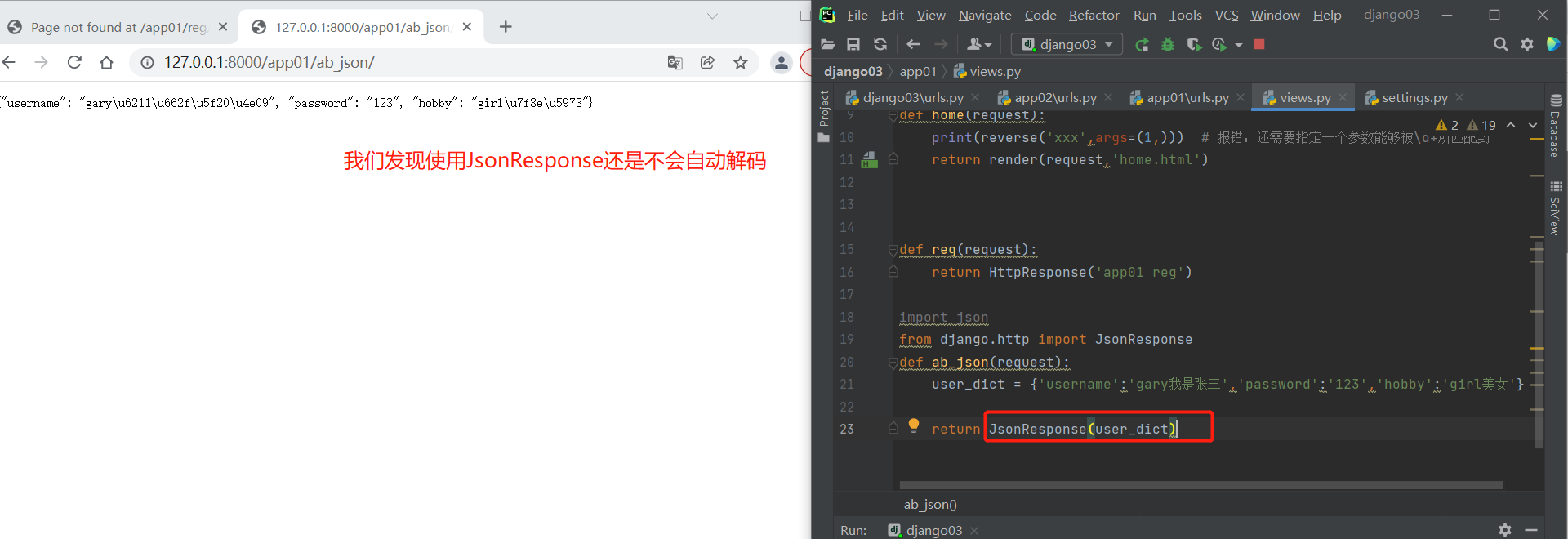
# 解决上述问题
from django.http import JsonResponse
def ab_json(request):
user_dict = {'username':'gary我是张三','password':'123','hobby':'girl美女'}
return JsonResponse(user_dict, json_dumps_params={'ensure_ascii': False})
# 通过研究源码推到出
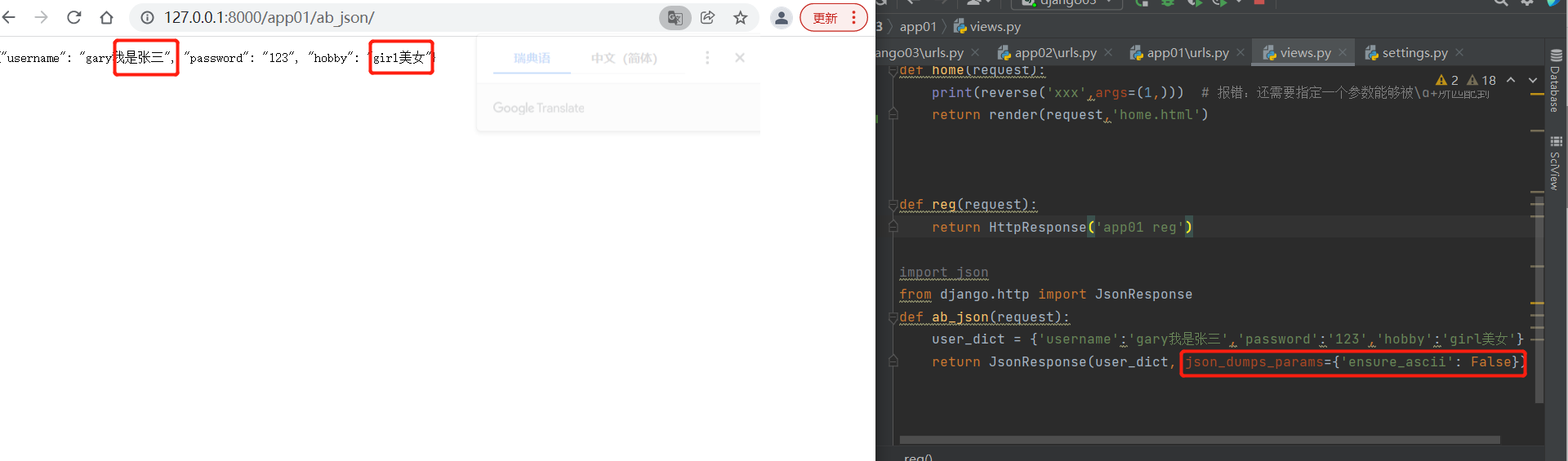
# 研究其他形式是否可以序列化:
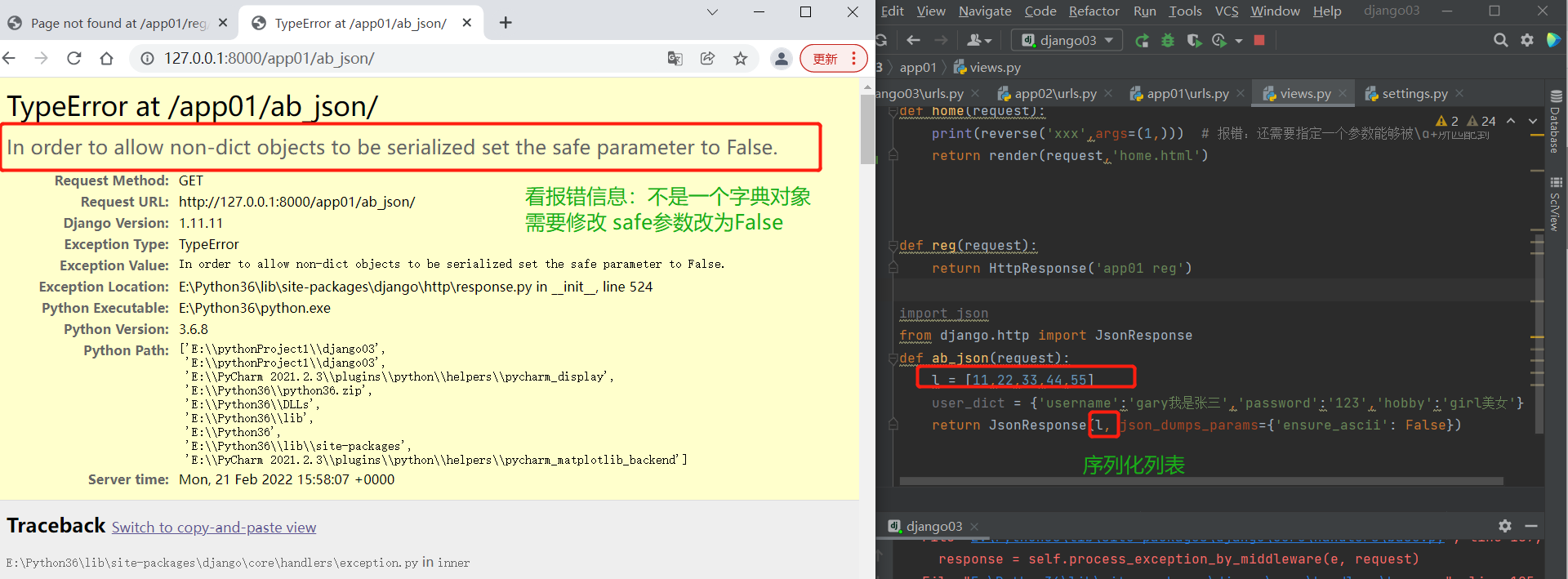
from django.http import JsonResponse
def ab_json(request):
l = [11,22,33,44,55]
return JsonResponse(l)
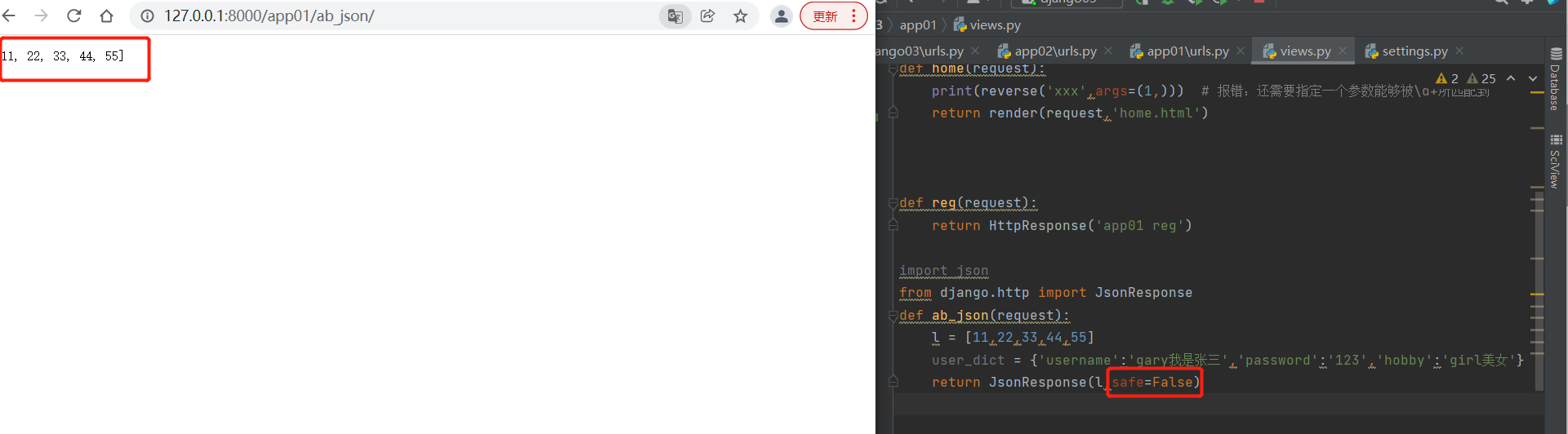
from django.http import JsonResponse
def ab_json(request):
l = [11,22,33,44,55]
return JsonResponse(l,safe=False)
# 默认只能序列化字典 序列化其他需要加safe参数
3、视图层之request对象获取文件
html页面
<form action="" method="post" enctype="multipart/form-data">
{% csrf_token %}
<input type="file" name="file">
<input type="submit">
</form>
1.method必须是post
2.enctype参数必须是multipart/form-data
前端获取文件数据
<input type="file" name="file"> 只能获取一个
<input type="file" name="file" multiple> 可以一次性获取多个
视图层(函数)
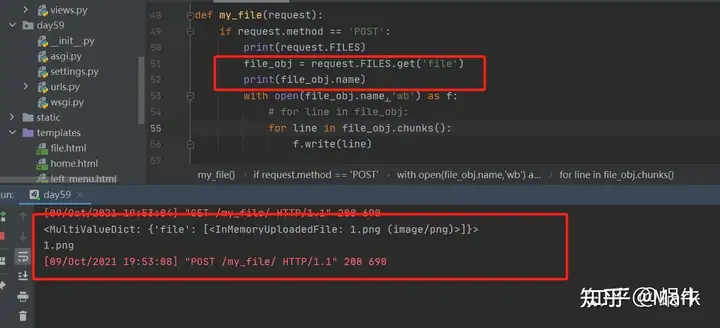
def ab_file(request):
if request.method == 'POST':
# print(request.POST) # 只能获取普通的简直对数据 文件不行
print(request.FILES) # 获取文件数据
# <MultiValueDict: {'file': [<InMemoryUploadedFile: u=1288812541,1979816195&fm=26&gp=0.jpg (image/jpeg)>]}>
file_obj = request.FILES.get('file') # 文件对象
rint(file_obj.name)
with open(file_obj.name,'wb') as f:
for line in file_obj.chunks(): # 推荐加上chunks方法 其实跟不加是一样的都是一行行的读取
f.write(line)
return render(request,'form.html')
4、request对象获取路径
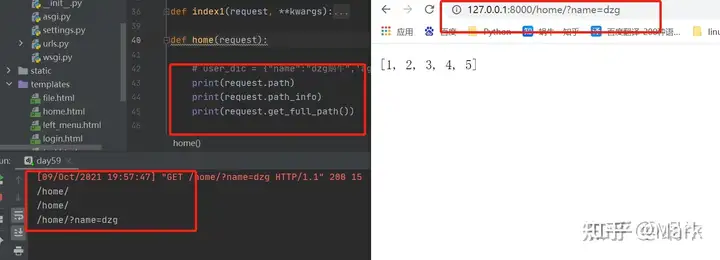
request.path
request.path_info:仅仅获取url匹配部分
request.get_full_path() : 能够获取完整的url及问号后面的参数
5、视图层之FBV与CBV
FBV
基于函数的视图,直接执行路由对应的视图功能
CBV
基于类的视图,在类下创建不同名称的功能,会根据请求方式自动做出处理找到对应的功能并执行
1、视图层
from django import views # 导入模块
class Myclass(views.View): # 继承模块的方法
def get(self, request): # 创建对应的方法
return HttpResponse('from CBV get function')
def post(self, request): # 创建对应的方法
return HttpResponse('from CBV post function')
2、路由层
path('login/', views.MyLoginView.as_view()) # 路由层配置方法
6、CBV源码剖析(重要)
CBV:class base view -- 基于类的视图
1、先写一个类
2、继承 View
3、url(r'^login/', views.Mylogin.as_view())
CBV 是根据请求方式区别访问哪个方法
"""
CBV
- 能够直接根据请求方式不同直接匹配对应的方法执行
"""
源码剖析:———非常重要——————
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^analysis', views.MyLogin.as_view())
'''
函数名/方法名 加括号执行优先级最高
猜测:
1.as_view() 是被 @classmethod 修饰的类方法
2.as_view() 是被 @staticmethod 修饰的静态方法
'''
# 由于上述代码在执行之后会立即执行并返回 view 方法的内存地址
# 因此可以转化为 url(r'^analysis', views.view)
]
因此 CBV 与 FBV 在路由匹配上本质是一样的,都是路由对应函数的内存地址
def view(request, *args, **kwargs):
self = cls(**initkwargs) ==> selg = MyLogin(**initkwargs) # 产生一个我们自己写的类的对象
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
def dispatch(self, request, *args, **kwargs):
# 获取当前请求的小写格式,然后比对当前请求方式是否合法,http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
"""
反射:通过字符串来操作对象的属性或方法
handler = getattr(自定义的类产生的对象,请求方式,找不到该请求方式的属性或方法时就会使用第三个参数)
"""
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
# 自动调用自定义的方法
在查看 Python 源码时,一定要时刻牢记面相对象属性方法查找顺序
- 先从对象自己找
- 再去产生对象的类里找
- 之后再去父类里找
四、模板层
1、django模板语法
- 操作相关
- 数据相关:{{ 操作的数据 }}
- 逻辑相关:
- 注释相关:
django的模板语法是自己写的,跟jinja2不一样
注意
- 针对需要加括号调用的名字,django模板语法会自动加括号调用你只需要写名字就行
- 模板语法的注释前端浏览器是无法查看的
2、模板语法传值
精确传值:用到哪个值,就传哪个
- 优点:不会浪费资源
- 缺点:针对多个资源都需要传入时,书写较为麻烦
方法:
return render(request, 'demo02.html', {'n1': name, 'a1': age})
传递名称空间中所有
- 优点:一次性传入全部
- 缺点:浪费资源
方法: 关键词:locals
return render(request,'demo02.html', locals())
模板语法传值特性
- 基本数据类型正常显示
- 文件对象也可以展示,并调用方法
- 函数名会自动加括号调用,并将返回值进行展示(不支持额外传参)
- 类名会自动加括号调用
- 对象不需要加括号调用
总结
总结针对可以加括号调用的名字模板语法都会自动加括号调用
3、模板语法过滤器
使用管道符"|"来应用过滤器
例如:{{ name|lower }}会将name变量应用lower过滤器之后再显示它的值。lower在这里的作用是将文本全都变成小写。
过滤器的语法:
{{ value|filter_name:参数 }}
注意事项:
- 过滤器支持“链式”操作。即一个过滤器的输出作为另一个过滤器的输入。
- 过滤器可以接受参数,例如:{{ sss|truncatewords:30 }},这将显示sss的前30个词。
- 过滤器参数包含空格的话,必须用引号包裹起来。比如使用逗号和空格去连接一个列表中的元素,如:{{ list|join:', ' }}
- '|'左右没有空格。
- 为模版过滤器提供参数的方式是:过滤器后加个冒号,再紧跟参数,中间不能有空格,目前只能为过滤器最多提供一个参数。
| 过滤器 | 例子 |
|---|---|
| lower, upper | {{ article.title | lower }} 大小写 |
| length | {{ name | length }} 长度 |
| default | {{ value | default: "0" }} 默认值 |
| date | {{ picture.date | date:"Y-m-j" }} 日期格式 |
| dicsort | {{ value | dicsort: "name" }} 字典排序 |
| escape | {{ title | escape }} 转义 |
| filesizeformat | {{ file | filesizeformat }} 文件大小 |
| first, last | {{ list | first }} 首或尾 |
| floatformat | {{ value | floatformat }} 浮点格式 |
| get_digit | {{ value | get_digit }} 位数 |
| join | {{ list | join: "," }} 字符连接 |
| make_list | {{ value | make_list }} 转字符串 |
| pluralize | {{ number | pluralize }} 复数 |
| random | {{ list | random }} 随机 |
| slice | {{ list | slice: ":2" }} 切 |
| slugify | {{ title | slugify }} 转为slug |
| striptags | {{ body | striptags }} 去除tags |
| time | {{ value | time: "H:i" }} 时间格式 |
| timesince | {{ pub_date | timesince: given_date }} |
| truncatechars | {{ title | truncatechars: 10 }} |
| truncatewords | {{ title | truncatewords: 2 }} |
| truncatechars_html | {{ title | truncatechars_html: 2 }} |
| urlencode | {{ path | urlencode }} URL转义 |
| wordcount | {{ body | wordcount }} 单词字数 |
4、模板层之标签
标签(不是指html的标签)在渲染过程中提供任意逻辑。可以是任意内容,也可以是if、for等语句,甚至可以放其他模板语句。
if判断
-
格式开头:
-
格式结尾:
-
条件的值可以直接在HTML写,也可以接收后端传的值
{% if 条件1 %}
条件1成立执行的结果
{% elif 条件2 %}
条件2成立执行的结果
{% else %}
条件1、2都不成立执行的结果
{% endif %}
for循环
- 格式开头:
- 格式结尾:
{% for k, v in dic.items %}
<li>{{ k }}: {{ v }}</li>
{% endfor %}
上面是通过for循环输出字典k, v键值对. for标签是一个特殊的标签, 中间的内容是包裹在 {% for %} 和{% endfor %}中
- forloop
- 在对可迭代对象进行遍历的过程中, 我们还可能经常需要访问索引, 这就需要用到模板内置的forloop对象
{% for l in lst %}
<p>{{ forloop }}</p>
{% endfor %}
# 浏览器输出结果
{'parentloop': {}, 'counter0': 0, 'counter': 1, 'revcounter': 5, 'revcounter0': 4, 'first': True, 'last': False}
{'parentloop': {}, 'counter0': 1, 'counter': 2, 'revcounter': 4, 'revcounter0': 3, 'first': False, 'last': False}
...
| 变量 | 描述 |
|---|---|
| forloop.counter | 当前循环的索引(从1开始) |
| forloop.counter0 | 当前循环的所用(从0开始) |
| forloop.revcounter | 当前循环的倒序索引值(从1开始) |
| forloop.revcounter0 | 当前循环的倒序索引值(从0开始) |
| forloop.first | 当前循环是不是第一次循环(布尔值) |
| forloop.last | 当前循环是不是最后一次循环(布尔值) |
| forloop.parentloop | 本层循环的外层循环 |
5、自定义过滤器与标签
自定义过滤器与标签需要有以下的目录结构
# 目录的层级结构
app/
__init__.py
models.py
templatetags/
__init__.py
my_tag.py
views.py
如果想要自定义一些模板语法 需要先完成下列的三步走战略
如果想要自定义一些模板语法 需要先完成下列的三步走战略
1.在应用下创建一个名字必须叫templatetags的目录
2.在上述目录下创建任意名称的py文件
3.在上述py文件内先编写两行固定的代码
from django import template
register = template.Library()
这样我们就可以通过register对象的filter, simpletag方法来装饰注册我们的自定义标签过滤器.最后不要忘记需要在模板中导入我们的自定义过滤器或标签文件 {% load mytag %},导入自定义标签过滤器之后, 我们就可以正常像使用内置标签一样使用自定义的了.
# 自定义过滤器(最大只能接收两个参数)
@register.filter(name='myadd')
def func1(a, b):
return a + b
{% load mytags %}
<p>{{ i|myadd:1 }}</p>
# 自定义标签(参数没有限制)
@register.simple_tag(name='mytag')
def func2(a, b, c, d, e):
return f'{a}-{b}-{c}-{d}-{e}'
{% load mytags %}
{% mytag 'jason' 'kevin' 'oscar' 'tony' 'lili' %}
# 自定义inclusion_tag(局部的html代码)
@register.inclusion_tag('menu.html',name='mymenu')
def func3(n):
html = []
for i in range(n):
html.append('<li>第%s页</li>'%i)
return locals()
{% load mytags %}
{% mymenu 20 %}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号