多线程实现
目录
程序提速
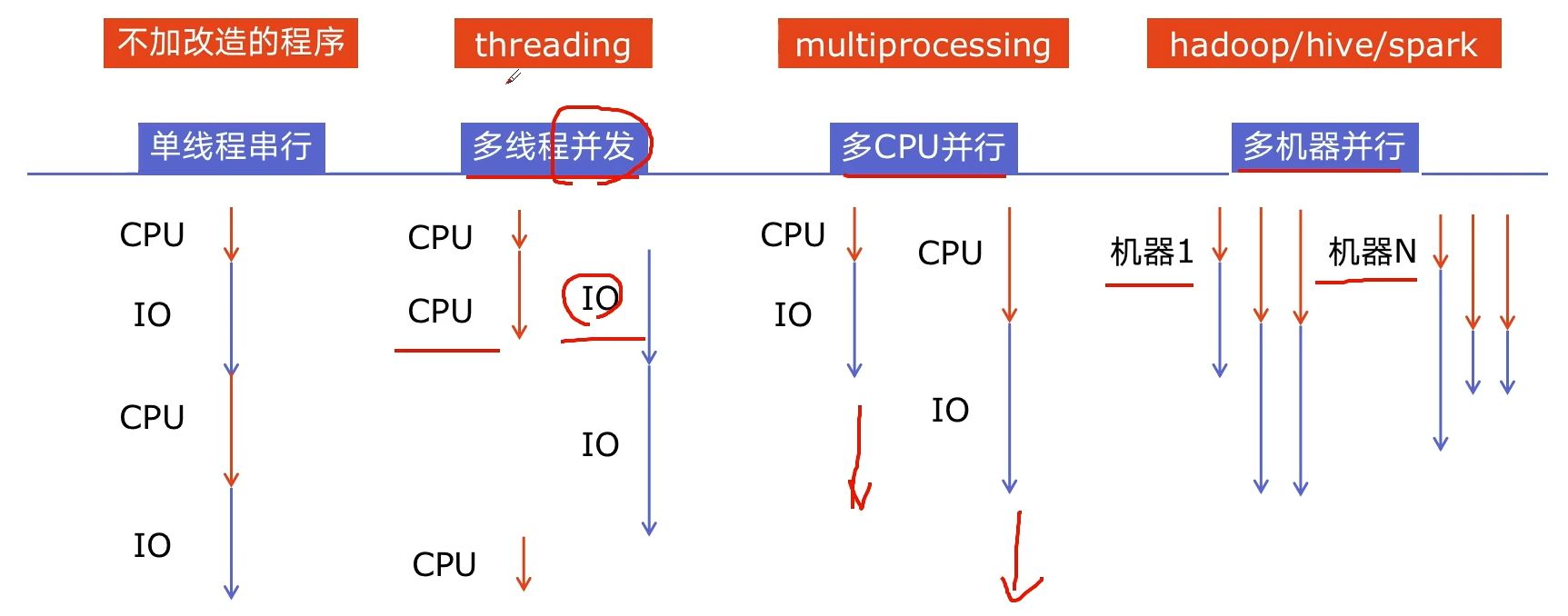

如何选择对应的技术?
CPU密集型计算,IO密集型计算?
CPU-bound:压缩解压缩,加密解密,正则表达式
I/O bound:文件处理程序,网络爬虫,读写数据库
| 多进程Process (threading) | 多线程thread (multiprocessing) | 多协程Coroutine (asyncio) | |
|---|---|---|---|
| 优点 | 可以利用多核CPU并行运算 | 相比于进程,更加轻量级,占用资源少 | 内存开销最少,启动协程数量最多 |
| 缺点 | 占用资源最多,可启动数目比线程少 | 相比进程,多线程只能并发执行,不能利用多个CPU(GIL);相比于协程:启动数目有限制,占用内存资源,有线程切换开销 | 支持的库有限制(aiohttp vs requests)、代码实现复杂 |
| 适用于 | CPU密集型计算 | IO密集型计算、同时运行的任务数目不多 | IO密集型计算,需要超多任务运行,但是线程库支持的场景 |
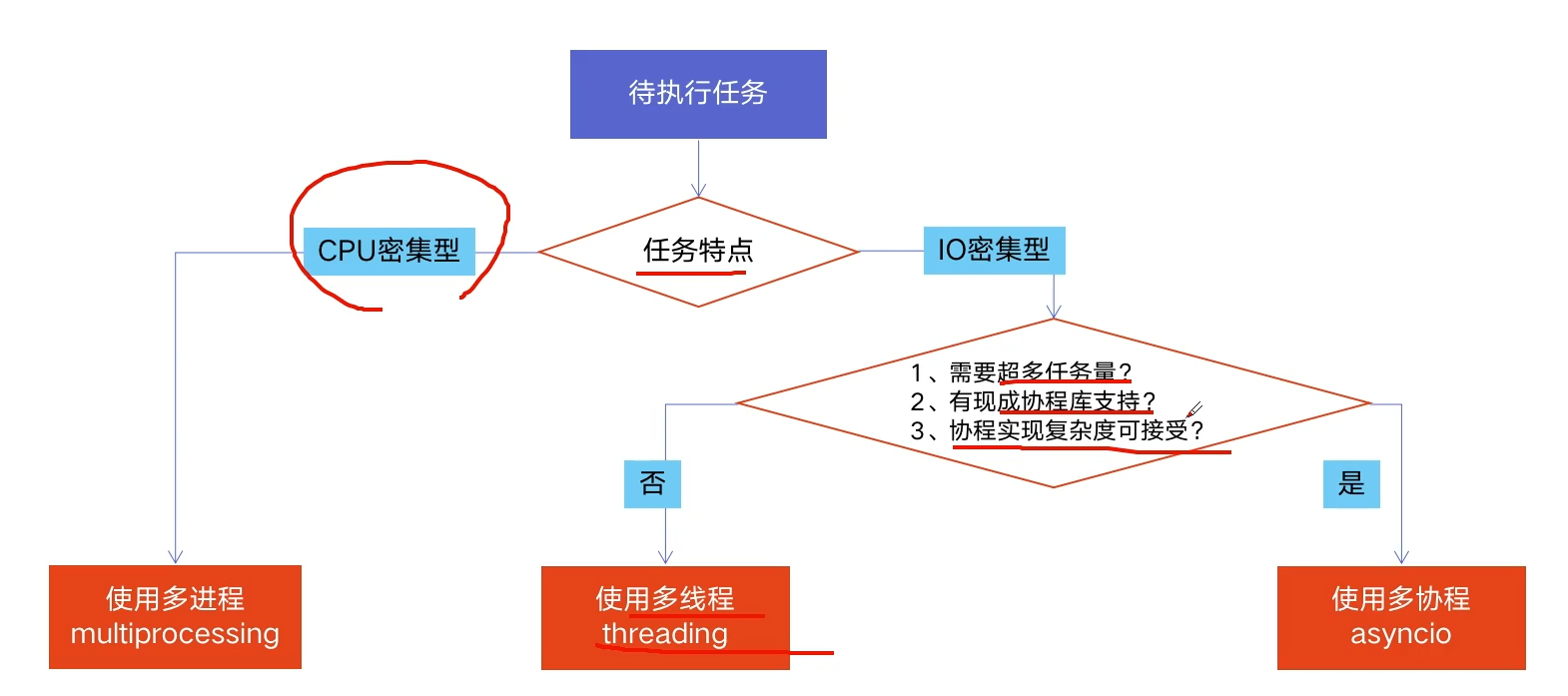
全局解释器锁 (Global Interpreter Lock,GIL)
Python速度为何慢?
- 动态类型语言,边解释边执行
- GIL无法利用多核CPU进行
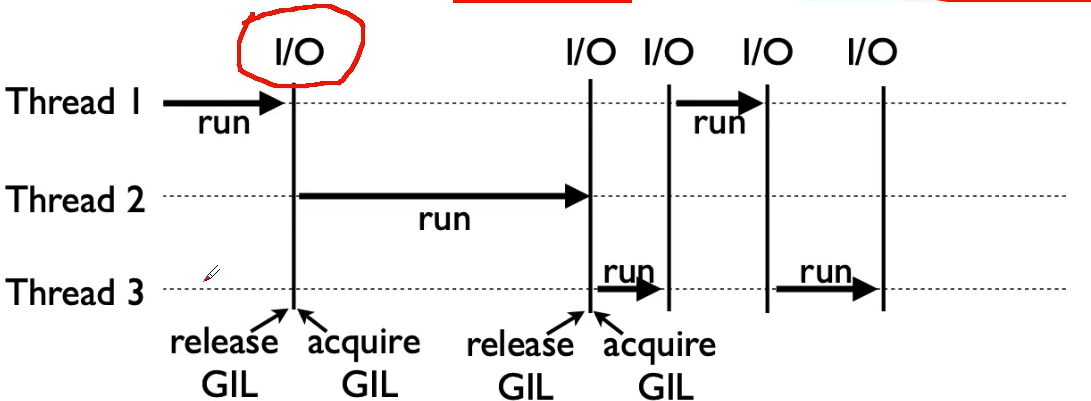
如何规避GIL的限制
多线程只适用于IO密集型运算,mulitproccessing
多线程改进爬虫
# blog_spider.py
import requests
urls = [
f"https://www.cnblogs.com/#p{page}"
for page in range(1,50+1)
]
def craw(url):
r = requests.get(url)
print(url,len(r.text))
craw(urls[0])
# multi_thread_craw.py
import blog_spider
import threading
import time
def single_thread():
for url in blog_spider.urls:
blog_spider.craw(url)
def multi_thread():
print("multi_thread begin")
threads = []
for url in blog_spider.urls:
threads.append(
threading.Thread(target=blog_spider.craw,args=(url,))
)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
if __name__ == "__main__":
start = time.time()
single_thread()
end = time.time()
print("single thread cost:",end-start,"seconds")
start = time.time()
multi_thread()
end = time.time()
print("single thread cost:",end-start,"seconds")
生产者消费者爬虫
多组件的pipeline技术架构
# blog_spider.py
import requests
from bs4 import BeautifulSoup
urls = [
f"https://www.cnblogs.com/#p{page}"
for page in range(1,50+1)
]
def craw(url):
r = requests.get(url)
return r.text
def parse(html):
# class="post-item-title"
soup = BeautifulSoup(html,"html.parser")
links = soup.find_all("a",class_="post-item-title")
return [(link["href"],link.get_text()) for link in links]
if __name__ == "__main__":
for result in parse(craw(urls[2])):
print(result)
# producer_custumer.py
import queue
import blog_spider
import threading
import random
import time
def do_craw(url_queue:queue.Queue, html_queue:queue.Queue):
while True:
url = url_queue.get()
html = blog_spider.craw(url)
html_queue.put(html)
print(threading.current_thread().name,f"craw{url}","url_queue.size=",url_queue.qsize())
time.sleep(random.randint(1,2))
def do_parse(html_queue:queue.Queue,fout):
while True:
html = html_queue.get()
results = blog_spider.parse(html)
for result in results:
fout.write(str(result)+"\n")
print(threading.current_thread().name,f"results.size",len(results),"html_queue.size=",html_queue.qsize())
time.sleep(random.randint(1,2))
if __name__ == "__main__":
url_queue = queue.Queue()
html_queue = queue.Queue()
for url in blog_spider.urls:
url_queue.put(url)
for idx in range(3):
t = threading.Thread(target=do_craw,args=(url_queue,html_queue),name=f"craw{idx}")
t.start()
fout = open("02.data.txt","w")
for idx in range(2):
t = threading.Thread(target=do_parse,args=(html_queue, fout),name=f"parse{idx}")
t.start()
线程安全与lock解决方案
- 线程的执行随时会发生切换,共享变量容易出问题。
- 解决
#try-finally
import threading
lock = threading.Lock()
lock.acquire()
try:
do something
finally:
lock.release()
#with
import threading
lock = threading.Lock()
with lock:
#do something
import threading
lock = threading.Lock()
class Account:
def __init__(self, balance):
self.balance = balance
def draw(account,amount):
with lock:
if account.balance >= amount:
print(threading.current_thread().name,"success")
account.balance -= amount
print(threading.current_thread().name,"余额",account.balance)
else:
print(threading.current_thread().name,"fail")
if __name__ == "__main__":
account = Account(1000)
ta = threading.Thread(name='ta',target=draw,args=(account,800))
tb = threading.Thread(name='tb',target=draw,args=(account,800))
ta.start()
tb.start()
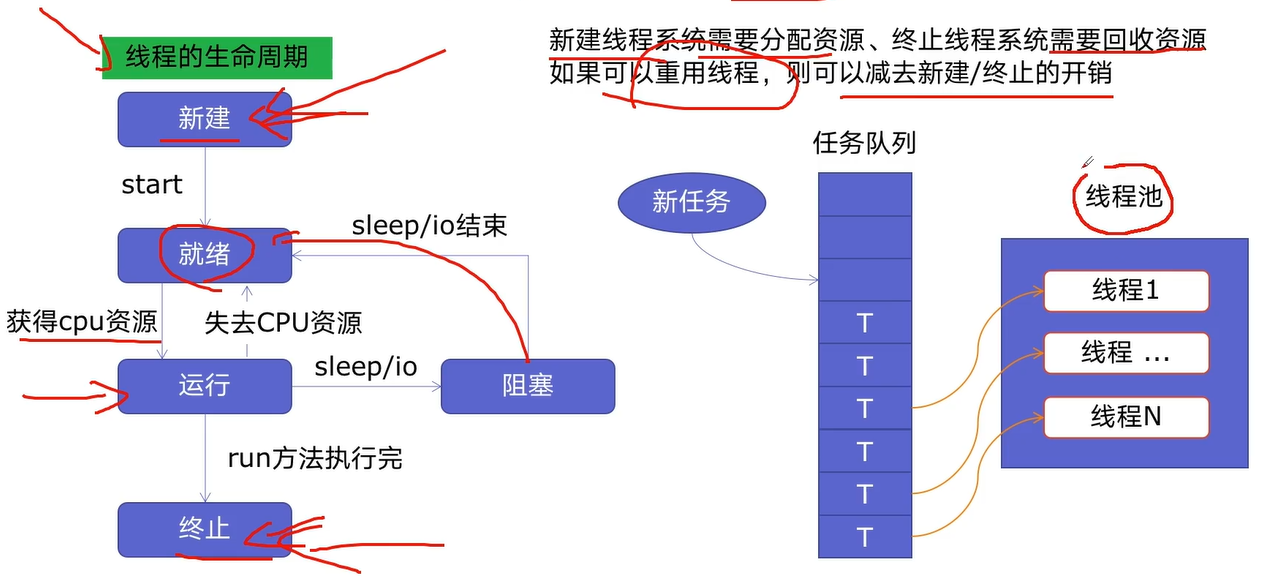
线程池
- 通过减少线程的新建与终止,减少系统开销。能够大大提升性能。
- 适用于突发性大量请求或需要大量线程完成任务,但实际任务处理时间短,
- 有一定的防御功能
- 简洁

import concurrent.futures
import blog_spider
#craw
with concurrent.futures.ThreadPoolExecutor() as pool:
htmls = pool.map(blog_spider.craw,blog_spider.urls)
htmls = list(zip(blog_spider.urls,htmls))
for url,html in htmls:
print(url,len(html))
print("done")
#parse
with concurrent.futures.ThreadPoolExecutor() as pool:
futures = {}
for url,html in htmls:
future =pool.submit(blog_spider.parse,html)
futures[future] = url
# for future,url in futures.items():
# print(url,future.result())
for future in concurrent.futures.as_completed(futures):#解析时即完成即打印,结果不按照顺序
url = futures[future]
print(url,future.result())
一句话结束
with concurrent.futures.ThreadPoolExecutor() as pool:
futures = [pool.submit(generate_lane,image_list,cfg) for image_list in tqdm(image_lists)]
使用线程池在web服务中进行加速(待完成)
mutiprocessing


 浙公网安备 33010602011771号
浙公网安备 33010602011771号