正则表达式
目录
常用的正则表达式
| 方案 | 代码 |
|---|---|
| 年份表达 | ^((19|20)\d{2})$ |
| 手机号码 | ^1[3456789]\d{9}$ |
| E-mail地址 | ^[\w-]+(.[\w-]+)*@[\w-]+(.[\w-]+)+$ |
| 网址URL | http: //(/[\w-]+.)+[\w-]+(/[\w-./?%&=]) |
正则表达式用于解决字符串,重在处理规则
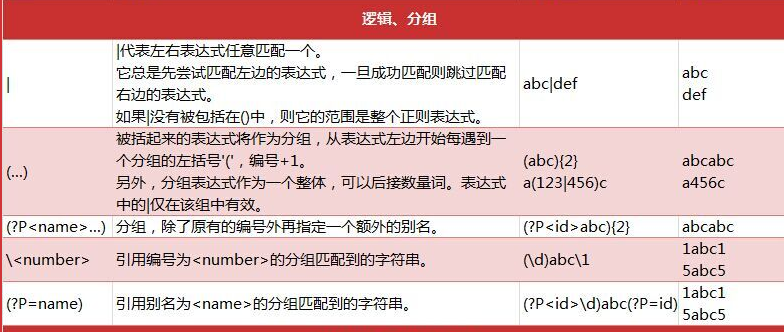
一些逻辑分组
字符分类
普通字符
import re
re.findall("p","python") #['p']
re.findall("python","I like python") #['python']
re.findall("p","I love python") #['o''o']
预定义字符
| 字符 | 含义 | 字符 | 含义 |
|---|---|---|---|
| \d | 所有的数字 | \D | 所有的非数字 |
| \w | 包含下划线的字符 | \W | 非下划线与字符 |
| ?? | 除下划线的特殊字符 | ?? | 非除下划线的特殊字符 |
| \s | 空白符 ,制表符\t,换行符\n |
\S | 非格式字符 |
元字符
[]匹配一个字符,括号内为或的关系,如[123]或者[1-3]表示为1或者2或者3的字符
一些功能性符号
^在与预定义字符和元字符一起使用时为取反,也就是说\s=^\S-代表区间()表示分组,括号外的参与搜索但是不参与输出{}重复匹配:{3}重复3次,{n,m}重复n-m次,可以留空{}?在与预定义字符和元字符一起使用时表示非贪婪匹配(默认是贪婪匹配),如{n,m}?基本上等价于{n}?表示前面的字符出现0次或1次+表示前面的字符出现至少一次*表示前面的字符出现0次或任意次r"……"转义符\.表示非换行符的一切字符
反向引用
wordstr=""" 'hello' "python" 'love" 'haha" """
result = re.findall(r"['/"]\w+["/']",worldstr) #无法选出引号正确的词组
result = re.findall(r"('|\")(\w+)(\1)",worldstr) #能够选出引号正确的词组
print([x[1] for x in result])
例子,寻找包含3个相同连续数字
result = re.findall(r"(\d)\1{2,}","122223")
print([x[0]+x[1] for x in result])
位置匹配
^表示从开头$表示到结尾
python相关函数
findall
以列表的方式返回全部匹配结果
match
从头开始匹配,匹配成功就返回
search
字符串内查找,找到匹配就返回
split分割
print("1 2 3 4".split(" "))
split_list = re.split(r"[\+\-\*\/]","1+2*3/4-40")#利用计算符号对算式进行分割
sub replace
myLine = "i am snipper, i like swimming"
re.sub(r'i','I',myLine,3)#用I替换I,最多替换3次
分组group
findall的使用方法见上面
result = re.match(r'h(.*)(\d{3})',hfadfadf2323adf223)
#正常输出
print(result.group()) #hfadfadf2323adf223
print(result.group(0)) #hfadfadf2323adf223
#输出第一个括号
print(result.group(1)) #fadfadf2323adf
#输出第二个括号
print(result.group(2)) #223
# ????为啥没有h了???
听课进度:1h30min

 浙公网安备 33010602011771号
浙公网安备 33010602011771号