

day14
内置函数(68)
1. 迭代器/生成器相关(3)
# (1) range() for i in range(0, 10): print(i) # (2) iter()和 next() lst = ["白蛇传", "骷髅叹", "庄周闲游"] # it = lst.__iter__() # 获取生成器 it = iter(lst) # 内部封装的就是__iter__() print(it.__next__()) # 下一个 print(next(it)) # 内部封装的就是__next__()
2. 作用域相关(2)
# (1) globals 以字典形式返回所有全局变量和函数 a = 20 def func(): b = 10 print(b) print(globals) func() # (2) locals 以字典形式返回所有当前作用域的内容 a = 20 def func(): b = 10 print(b) print(locals()) func()
3. 基础数据类型相关(38)
1. 和数字相关 1.1 数据类型(4) # bool() s = bool() print(s) # False # int() s = "123" print(int(s)) # 123 # float() s = "1.25" print(float(s)) # 1.25 # complex() 创建⼀个复数. 第⼀个参数为实部, 第⼆个参数为虚部. 或者第⼀ 个参数直接⽤字符串来描述复数 s = complex(6, 3) print(s) # (6+3j) 1.2 进制转换(3) # bin() 转化为二进制 print(bin(5)) # 求5的2进制 0b二进制 结果: 0b101 # oct 转化为八进制 print(oct(8)) # 0o八进制 结果: 0o10 # hex 转化为十六进制 print(hex(16)) # 0x十六进制 0123456789ABCDEF 结果: 0x10 1.3 数学运算(7) # round() 四舍五入 print(round(4.51)) # 四舍五入 结果: 5 # pow(a, b, c) 求次幂, 第三个参数计算余数 print(pow(2, 4)) # 求次幂 print(2**4) 结果: 16 16 print(pow(2, 4, 5)) # 求次幂, 第三个参数计算余数 结果: 1 # sum() 求和 print(sum([1, 2, 3, 4, 5], 3)) # 求和 sum(iterable,start value) 结果: # min() 求最小值 print(min(5,12,45,6,7,34)) # 最小值 结果: 5 # max()求最大值 print(max(5,12,45,6,7,34)) # 最大值 结果: 45
2. 和数据结构相关(24) 2.1 序列 2.1.1 列表和元组(2) # list() 转化成列表类型 s = "123" print(list(s)) 结果: ['1', '2', '3'] # tuple() 转化成元组类型 s = [1, 2, 3] print(tuple(s)) 结果: (1, 2, 3) 2.1.2 相关内置函数(2) # reversed() 将⼀个序列翻转, 返回翻转序列的迭代器 lst = ["马化腾", "马云", "马大帅", "马超"] l1 = reversed(lst) # reversed 翻转. 返回的是迭代器 print(list(l1)) 结果: ['马超', '马大帅', '马云', '马化腾'] # slice() 列表的切片 lst = ["马化腾", "马云", "马大帅", "马超", "马良"] s = slice(1, 4, 2) # 切片(顾头不顾尾) print(lst[s]) print(lst[1:4:2]) 结果: ['马云', '马超'] ['马云', '马超'] 2.1.3 字符串(9) # str() 把对象转换成字符串类型 s = 123 print(str(s)) # 123 print(type(str(s))) # <class 'str'> # format() 有三种用法 (1) 字符串 s = "抽烟" print(s.center(20, "*")) # 拉长到20 原字符串居中(还可以填充单字符) # print(format(s, "^20")) # 居中 print(format(s, ">20")) # 右对齐 print(format(s, "<20")) # 左对齐 # (2) 数值 print(format(3, 'b')) # ⼆进制 print(format(97, 'c')) # 转换成unicode字符 print(format(11, 'd')) # ⼗进制 print(format(11, 'o')) # ⼋进制 print(format(11, 'x')) # ⼗六进制(⼩写字⺟) print(format(11, 'X')) # ⼗六进制(⼤写字⺟) print(format(11, 'n')) # 和d⼀样 print(format(11)) # 和d⼀样 # (3) 浮点数 print(format(123456789, 'e')) # 科学计数法. 默认保留6位⼩数 print(format(123456789, '0.2e')) # 科学计数法. 保留2位⼩数(⼩写) print(format(123456789, '0.2E')) # 科学计数法. 保留2位⼩数(⼤写) print(format(1.23456789, 'f')) # ⼩数点计数法. 保留6位⼩数 print(format(1.23456789, '0.2f')) # ⼩数点计数法. 保留2位⼩数 print(format(1.23456789, '0.10f')) # ⼩数点计数法. 保留10位⼩数 print(format(1.23456789e+10000, 'F')) # ⼩数点计数法. INF 无穷大 # bytes() 把字符串转化成bytes类型 # s = "我" # bs = s.encode("utf-8") # print(bs) # b'\xe6\x88\x91' # print(bytes("我", encoding="utf-8")) # b'\xe6\x88\x91' # bytearray() 返回⼀个新字节数组. 这个数字⾥的元素是可变的, 并且每个元素 的值范围是[0,256) ret = bytearray('alex',encoding='utf-8') print(ret[0]) # 97 print(ret) # bytearray(b'alex') # memoryview()查看bytes字节在内存中的情况 s = "你好啊. 不要睡了. 我也困" print(memoryview(s.encode("utf-8"))) # 还不如id() # 结果: <memory at 0x000001D52FB18408> # ord() 查看字符的编码位置 print(ord("a")) # 查看字母a的编码的位置 97 print(ord("A")) # 65 print(ord("中")) # 20013 # chr() 通过位置找字符 print(chr(97)) # a # ascii() 是ascii码中的返回该值 不是就返回\u... print(ascii("a")) # 'a' print(ascii("中")) # '\u4e2d' # repr() 返回对象的字符串形式 print("你好. 我\\叫周润发") # 对用户是友好的. 非正式的字符串 # 正式(官方)的字符串, 面向对象的时候 print(repr("你好, 我叫\"周润发")) # 程序中内部存储的内容, 这个是给程序员看的 print("我叫%r" % "周润发") # %r 实际上调用的是repr() # 原样输出 print(r"马化腾说:\"哈哈哈,\" \n \t") # C: \ 在字符串中是转义字符 # \n 换行 # \t 制表符 # \\ \ # \" " # \' '
2.2 数据集合 2.2.1 字典 # dict() 创建一个字典 dic = dict() # 这里创建了一个空字典,也可以不是空的. 后面会学到 print(dic) 2.2.2 集合(2) # set() 创建一个集合,或者转化成集合类型 st = set() print(st) # set() # lst = [1, 2, 1, 3] print(set(lst)) # {1, 2, 3} # frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素 lst = [1, 2, 1, 3] print(frozenset(lst)) # frozenset({1, 2, 3})
# (1) len() 返回对象的长度 lst = [1, 2, 3] print(len(lst)) # (2) enumerate() 枚举 # 用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中。 lst = ["张国荣", "黄渤", "郭达森", "泰森", "甄子丹"] for i, el in enumerate(lst): print(i,el) # (3) all() 用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False # 和and一样, 有一个是假就是假,全部是真才是真 print(all([True, 1, 1, 1])) # True print(all([True, 1, 1, 0])) # False # (4) any() 用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。 # 和or一样, 一个是真就是真, 全部是假才是假 print(any([1, False, 0, 0])) # True print(any([True, 0, 0, 0])) # False # (5) zip()用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。 # 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。 lst1 = ['甜蜜蜜', "往事只能回味", "难忘今宵", "分红的记忆", "十年"] lst2 = ["邓丽君", "韩宝仪", "李谷一", "王宝强", "陈奕迅"] lst3 = ["2000", "3000", "5", "120"] # 打包成元组 a = zip(lst1, lst2, lst3) # 水桶效应(取最短的),只要有对应位置没数据的就舍弃 print(a) # <zip object at 0x00000245F18E16C8> for el in a: print(el) # 结果(按照位置进行合并): # ('甜蜜蜜', '邓丽君', '2000') # ('往事只能回味', '韩宝仪', '3000') # ('难忘今宵', '李谷一', '5') # ('分红的记忆', '王宝强', '120') # 将元组解压为列表 b = zip(*a) print(list(b)) # 结果: [('甜蜜蜜', '往事只能回味', '难忘今宵', '分红的记忆'), ('邓丽君', '韩宝仪', '李谷一', '王宝强'), ('2000', '3000', '5', '120')] # (6)sorted 排序函数 # 语法: sorted(Iterable, key=None, reverse=False) # Iterable: 可迭代对象 # key: 排序方案, sorted函数内部会把可迭代对象中的每一个元素交给后面的key # 后面的key计算出一个数字. 作为当前这个元素的权重, 整个函数根据权重进行排序 # reverse: 是否是倒叙. False: 正序, True: 倒叙. (不写就默认是 True: 正序) lst = ["聊斋", "西游记", "三国演义", "葫芦娃", "水浒传", "年轮", "亮剑"] # 用普通函数 def func(s): return len(s) # 按照元素的长度大小来排序 ll = sorted(lst, key=func) print(ll) # 结果: ['聊斋', '年轮', '亮剑', '西游记', '葫芦娃', '水浒传', '三国演义'] # 用lambda函数 ll = sorted(lst, key=lambda el: len(el), reverse=False) print(ll) # 结果: ['聊斋', '年轮', '亮剑', '西游记', '葫芦娃', '水浒传', '三国演义'] # (7) filter 筛选函数 # 语法: filter(function, Iterable) # function: ⽤来筛选的函数. 在filter中会⾃动的把iterable中的元素传递给function. 然后 # 根据function返回的True或者False来判断是否保留此项数据 lst = ["张无忌", "张铁林", "闫子哲", "理想", "马大帅"] # 筛选, f = filter(lambda el: el[0] != "张", lst) # 将lst中的每一项传递给func, 所有返回True都会保留, 所有返回Flase都会被过滤掉 print(list(f)) # 结果: ['闫子哲', '理想', '马大帅'] # (8) map 映射函数 # 语法: map(function, iterable) 可以对可迭代对象中的每⼀个元素进⾏映射. 分别取执⾏function lst = [1, 4, 7, 2, 5, 8] m = map(lamda el: el**2, lst) # 把后面的可迭代对象中的每一个元素传递给function, 结果就function的返回值 print(list(m)) # 拿出所有值到一个列表里 # 结果: [1, 16, 49, 4, 25, 64]#
总结: 这里filter和map函数 返回的好像是迭代器, 可以用for或者list()提取数据.
4. 其他(12)
4.1 字符串代码类型的执行(3) # eval() 执⾏字符串类型的代码. 并返回最终结果 s = "5 + 6" ret = eval(s) # 动态执行一个代码片段, 侧重点在返回上 print(ret) # 结果: 11 # exec() 只执⾏字符串类型的代码,但是不返回 s = "a = 10" exec(s) # 执行代码 print(a) # pycharm里的报错信息,不一定是对的 # 结果: 10 content = input("请输入你的代码:") # 这里输入的: a = 6 + 2 exec(content) print(a) # 结果: 8 # compile() 将字符串类型的代码变异. 代码对象能够通过exec语句来执⾏或者eval()进⾏求值 ''' 参数说明: 1. resource 要执⾏的代码, 动态代码⽚段 2. ⽂件名, 代码存放的⽂件名, 当传⼊了第⼀个参数的时候, 这个参数给空就可以了 3. 模式, 取值有3个, (1). exec: ⼀般放⼀些流程语句的时候 (2). eval: resource只存放⼀个求值表达式. (3). single: resource存放的代码有交互的时候. mode应为single ''' s = "5 + 9" c = compile(s, "", "eval") ret = eval(c) print(ret) # 结果: 14 s = "for i in range(3): print(i)" c = compile(s, "", "exec") exec(c) # 结果: 0 # 1 # 2 s = "content = input('请输入你的名字:')" # 这里输入的是:闫子哲大傻子 c = compile(s, "", "single") exec(c) # 把字符串s变成代码执行,结果存到content里,不会返回 print(content) # 结果: 闫子哲大傻子
4.2 输入输出(2) # input() 用于用户交互 content = input("请输入您的外号:") print(content) # 结果: 小飞侠 # print() 用于打印输出 s = "复仇者联盟" print(s) # 结果: 复仇者联盟
4.3 内存相关(2) # id() 用于获取对象的内存地址 lst = [1, 2, 3, 4, 5, 6] print(id(lst)) # 结果: 2475936932424 # hash() 用于获取取一个对象(不可变的对象:字符串,数字,元组)的哈希值 tp = (1, 2, 3, 4, 5, 6) # 这里tp是元组 print(hash(tp)) # 结果: -14564427693791970
注意: 字典 浪费空间. 换句话说: 字典或者hash算法是拿空间换时间
4.4 文件操作相关(1) # open() 打开一个文件 f = open("01 课程大纲", mode="r", encoding="utf-8") for line in f: print(line,end="") f.close()
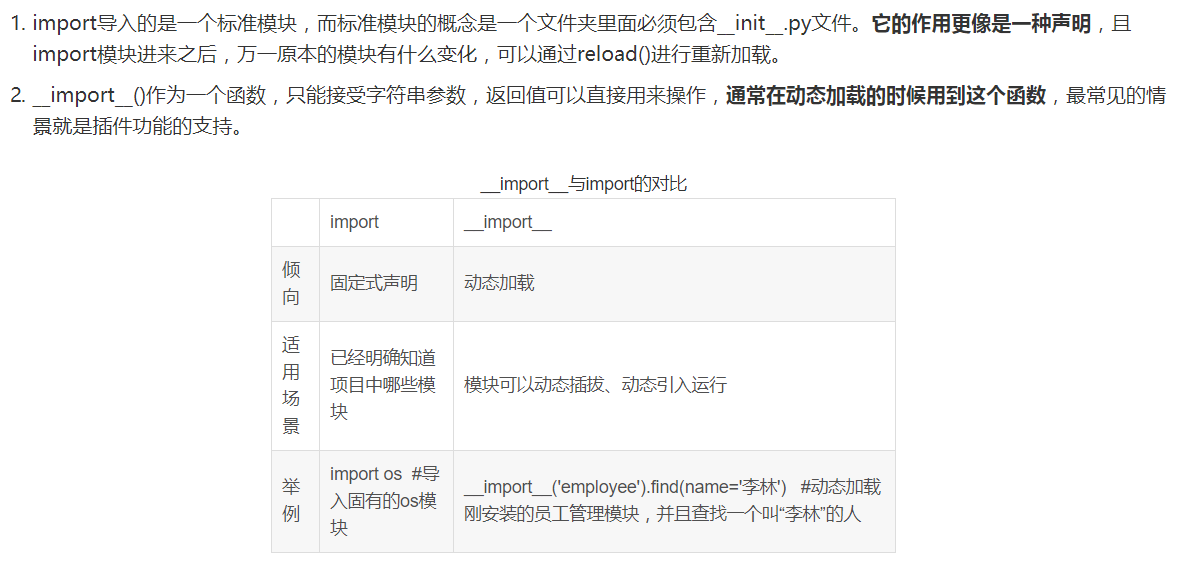
4.5 模块相关(1) # __import__ 用于动态加载类和函数 。 # 如果一个模块经常变化就可以使用 __import__() 来动态载入。
附件: import和__import__的区别
4.6 帮助(1) # help() 用于查看函数或模块用途的详细说明。 print(dir(str)) # 所有方法的名字 print(help(str)) # 帮助文档(也有所有方法的名字,但是是有注释的)
4.7 调用相关(1) # callable() 用于检查一个对象是否是可调用的 def a(): pass a() # 10不是函数. 10不是可以被调用的 print(callable(a)) # 是否可以被调用执行
4.8 查看内置属性(1) # dir() 不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,查看对象的内置属性, ⽅法. 访问的是对象中的__dir__()⽅法. print(dir(str))

{kind=link}