prometheus 监控并发告警给企业微信
一、部署prometheus
采集系统数据的工具
时序图
1.1、部署node_exporte
node_exporter 是prometheus的一部分,用来装在被监控的服务器上
# 1、解压安装包
tar -zxvf node_exporter-1.7.0.linux-amd64.tar.gz
# 2、启动 默认监听9100端口 建议使用7100 防止跟现有程序冲突
# 2.1 先查看一下是端口是否被占用:netstat -tlnp | grep 7100
nohup ./node_exporter --web.listen-address=":7100" &
# 3、查看7100是否打开
sudo firewall-cmd --list-ports
# 4、打开7100端口
sudo firewall-cmd --zone=public --add-port=7100/tcp --permanent
# 5、刷新端口
sudo firewall-cmd --reload
1.2 、部署prometheus主程序
Prometheus 是主要采集端,安装的服务器
# 1、解压安装包
tar -zxvf prometheus-2.45.4.linux-amd64.tar.gz
# 2、配置 prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: '数据库:176'
static_configs:
- targets: ['xxx.xxx.xxx.176:7100']
labels:
instance: 'xxx.xxx.xxx.176'
- job_name: '数据库:178'
static_configs:
- targets: ['xxx.xxx.xxx.178:7100']
labels:
instance: 'xxx.xxx.xxx.178'
- job_name: '中间件:103'
static_configs:
- targets: ['xxx.xxx.xxx.103:7100']
labels:
instance: 'xxx.xxx.xxx.103'
- job_name: '中间件:205'
static_configs:
- targets: ['xxx.xxx.xxx.205:7100']
labels:
instance: 'xxx.xxx.xxx.205'
- job_name: '前置机:105'
static_configs:
- targets: ['xxx.xxx.xxx.105:7100']
labels:
instance: 'xxx.xxx.xxx.105'
- job_name: '前置机:192'
static_configs:
- targets: ['xxx.xxx.xxx.192:7100']
labels:
instance: 'xxx.xxx.xxx.192'
- job_name: '应用:55'
static_configs:
- targets: ['xxx.xxx.xxx.55:7100']
labels:
instance: 'xxx.xxx.xxx.55'
- job_name: '应用:121'
static_configs:
- targets: ['xxx.xxx.xxx.121:7100']
labels:
instance: 'xxx.xxx.xxx.121'
- job_name: '应用:227'
static_configs:
- targets: ['xxx.xxx.xxx.227:7100']
labels:
instance: 'xxx.xxx.xxx.227'
# 启动
nohup ./prometheus --config.file=prometheus.yml --web.listen-address=:7200 > prometheus.log 2>&1 &
二、部署grafana
grafanas是可视化和分析平台, 本身并不会监听数据,只是通过分析prometheus采集到的数据然后通过图形报表等方式直观的展示出来
# 1、在线的方式安装 【不推荐】
sudo yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-10.4.0-1.x86_64.rpm
# 3、配置服务和自启动
# 3.1、重新加载Systemd的守护程序配置
sudo systemctl daemon-reload
# 3.2、启动grafana
sudo systemctl start grafana-server
# 3.3、查看Grafana服务器的状态
sudo systemctl status grafana-server
# 3.4、配置成自启动
sudo systemctl enable grafana-server.service
firewall-cmd --zone=public --add-port=443/tcp --permanent
三、部署alertmanager
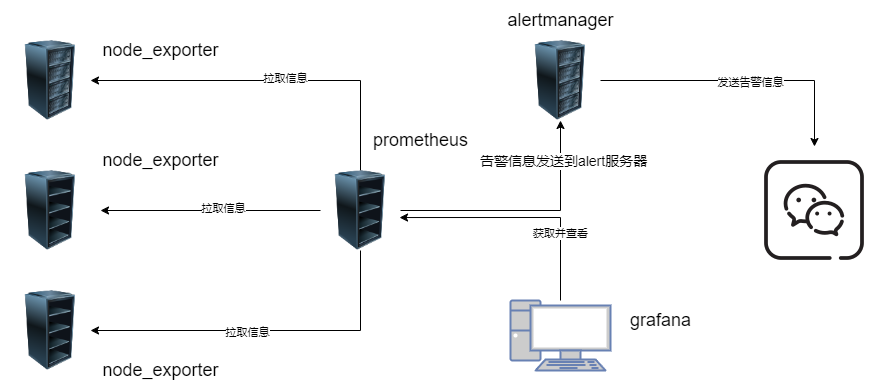
【提示:】 看第一张图 知道 告警信息是从Prometheus 服务器发送到alertmanager服务器的,所以在内网环境中只要服务器可以上外网就可以发送告警信息到企业微信
1、把告警信息发送到企业微信
1.1 配置Prometheus
Prometheus.yml:
prometheus与 alertmanager通信的配置
alerting:
alertmanagers:
- static_configs:
- targets:
- xxx.xxx.xxx.112:7201
# 报警规则文件配置
rule_files:
- rules/*.yml
rules 目录下的文件配置
node_alived.yml :
groups:
- name: 实例存活告警规则
rules:
- alert: 实例存活告警
expr: up == 0
for: 5m
labels:
user: prometheus
severity: warning
annotations:
summary: "主机宕机 !!!"
description: "{{ $labels.instance }} :实例主机已经宕机超过一分钟了。"
memory_over.yml
groups:
- name: 内存报警规则
rules:
- alert: 内存使用率告警
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 50
for: 1m
labels:
severity: warning
annotations:
summary: "服务器可用内存不足。"
description: "{{$labels.instance}}:内存使用率已超过50%(当前值:{{ $value }}%)"
dis_over.yml 硬盘告警
groups:
- name: 磁盘使用率报警规则
rules:
- alert: 磁盘使用率告警
expr: 100 - node_filesystem_free_bytes{fstype=~"xfs|ext4"} / node_filesystem_size_bytes{fstype=~"xfs|ext4"} * 100 > 80
for: 20m
labels:
severity: warning
annotations:
summary: "硬盘分区使用率过高"
description: "{{ $labels.instance }}:分区使用大于80%(当前值:{{ $value }}%)"
cpu_over.yml cpu 告警
groups:
- name: CPU报警规则
rules:
- alert: CPU使用率告警
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 50
for: 1m
labels:
severity: warning
annotations:
summary: "CPU使用率正在飙升。"
description: "{{ $labels.instance }}: CPU使用率超过50%(当前值:{{ $value }}%)"
1.2 配置 alertmanager.yml
发送消息的配置
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: '从企业微信后台获取'
to_party: '1'
agent_id: '从企业微信后台获取'
api_secret: '从企业微信后台获取'
to_user : '@all'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号