

链接的思考
引言
最近做一些工程,经常遇到链接错误,为此翻阅了相关的资料,梳理了一下编译链接的流程和原理。编程语言分为编译型和解释型,编译型语言是用编译器将高级语言翻译成计算机可执行的低级语言;而解释型语言是使用解释器是将低级语言“提升”成高级语言。解释型语言一次执行一句,缺少程序的全局信息,解释器中包含大量的“if”“else”判断,因此速度较慢,但是一次执行一句的方式却增加了语言灵活性,直观来说python使用起来比c++方便多了吧;而编译型语言,需要将程序整体进行编译,编译器知道程序的全局信息,可以省略一些“if”、“else”的判断。所以编译型语言比解释型语言使用麻烦些,但是执行速度却要快得多。C/C++ 就属于编译型语言,一个大的C/C++工程往往由大量的源代码文件组成,这些源代码通过编译后会得到一个个“.o”的“零部件”(可重定位文件),而工程中的“.h”文件就像是这些零部件的连接指南,链接器的工作就是将“零部件”通过“.h”.文件组装成可执行文件。有时候这些“零部件”太多了,将这些相关的“零部件”放在一起就组成了一个库(.lib or .a),“零部件”组合起来生成一个库文件的过程我们就叫做“打包”。
那么链接器如何将这些“零部件”组装起来呢?其实每个“零部件”(可重定位文件)都有许多对外显示的“名字”(例如函数名字,全局变量),这些名字就是这个“零部件”对外的“触角”,有的名字是这个零部件定义好了的,而另一些名字是这个“零部件”内没有定义的,链接器要做的就是要将不同零部件的未定义的名字与其他零部件已定义的名字关联上,就能得到一个可执行的文件。
一个实例
现在举一个简单的c语言例子来说明,这个程序非常简单分别有main.c、function1.h、function1.c、function2.h、function2.c、function3.h、function3.c、function31.h、function31.c、function32.h、function32.c 几个文件,各个文件中代码如下:
main.c:
#include <stdio.h>
#include "function1.h"
#include "function2.h"
#include "function3.h"
extern int i;
int main()
{
printf("%d\n",i);
function1();
function2();
function3();
}
function1.h:
void function1();
function1.c:
#include <stdio.h>
#include "function1.h"
void function1()
{
printf("function1\n");
}
function2.h
void function2();
function2.c
#include <stdio.h>
#include "function2.h"
void function2()
{
printf("function2\n");
}
function3.h
void function3();
function3.c
#include <stdio.h>
#include "function3.h"
#include "function31.h"
#include "function32.h"
int i = 123;
void function3()
{
function31();
function32();
printf("function3\n");
}
function31.h
void function3();
function31.c
#include <stdio.h>
#include "function31.h"
void function31()
{
printf("function31\n");
}
function32.h
void function32();
function32.c
#include <stdio.h>
#include "function32.h"
void function32()
{
printf("function32\n");
}
可以看到main.c分别引用了function1.c 、function2.c、function3.c中的函数,而function3.c中又引用了function31.c和function32.c的函数,它们之间通过各自的.h文件和#include引用“粘合”在一起。
现在我们通过gcc -c main.c function1.c function2.c function3.c function31.c function32.c命令编译出各个.c文件对应的.o文件(可重定位文件),这些.o文件是我们可执行文件的零部件。链接的工作是将这些零部件“拼装”起。上文说了链接器是将不同零部件的名字对应上实现链接。在linux中可以通过nm命令查看零部件的名字。例如我们要看main.o的名字,使用gcc -c main.o,结果如下:
U function1
U function2
U function3
U i
0000000000000000 T main
U printf
其中标志U代表未定义的符号,链接器要把这些未定义的名字在其他零部件.o文件中或者零部件的集合——库文件中对应上才能实现链接,生成可执行文件。我们再看看function3.o的名字gcc -c function3.o:
0000000000000000 T function3
U function31
U function32
0000000000000000 D i
U puts
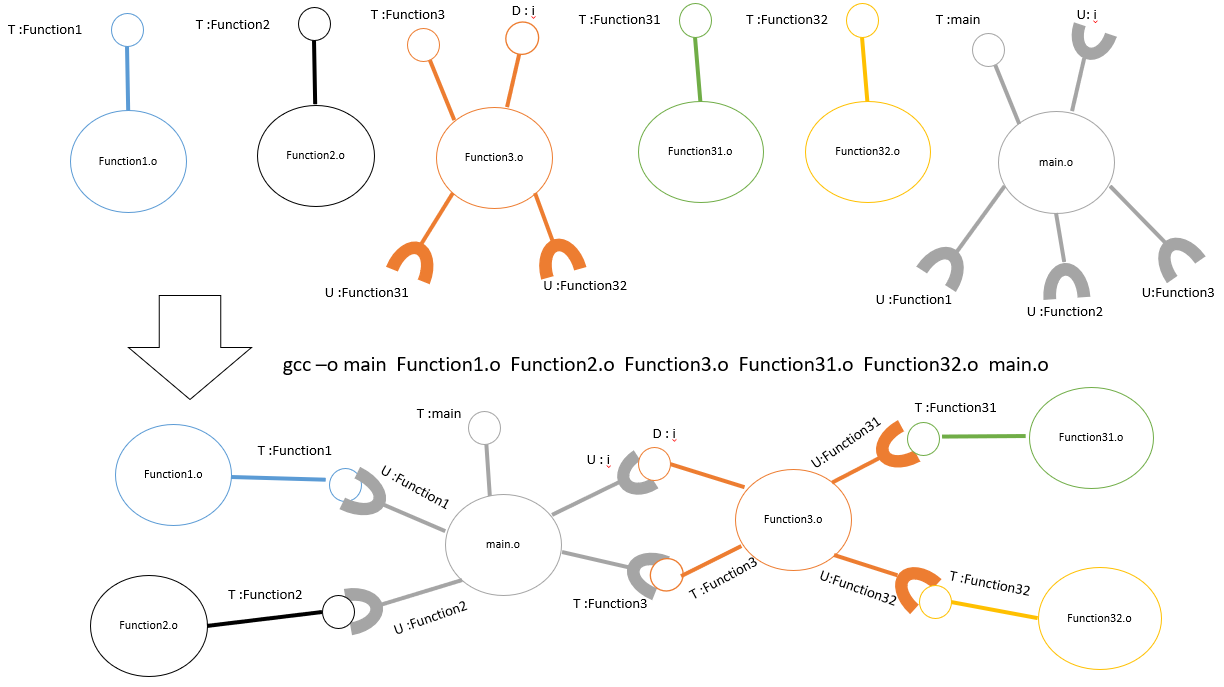
和预料中的一样吧,可以看出main.o 中未定义的function3 和 i 都能在function3.o中找到。接下我们利用这些“零部件”生成可执行文件gcc -o main *.o,可以看出程序没有报错,并且正常执行。
现在我们再试一下我们故意将function2.c中的function2 改成functionX:
#include <stdio.h>
#include "function2.h"
void functionX()
{
printf("function2\n");
}
我们重新进行之前的实验,这次能够成功编译生成.o文件,但是连接时出现如下错误:
main.o: In function `main':
main.c:(.text+0x2b): undefined reference to `function2'
collect2: error: ld returned 1 exit status
可以看出这次连接器报错,在main.o中未定义的function2在其他零部件中找不到对应名字。
示意图
以下对上述简单例子的直观示意图
- 编译的过程:
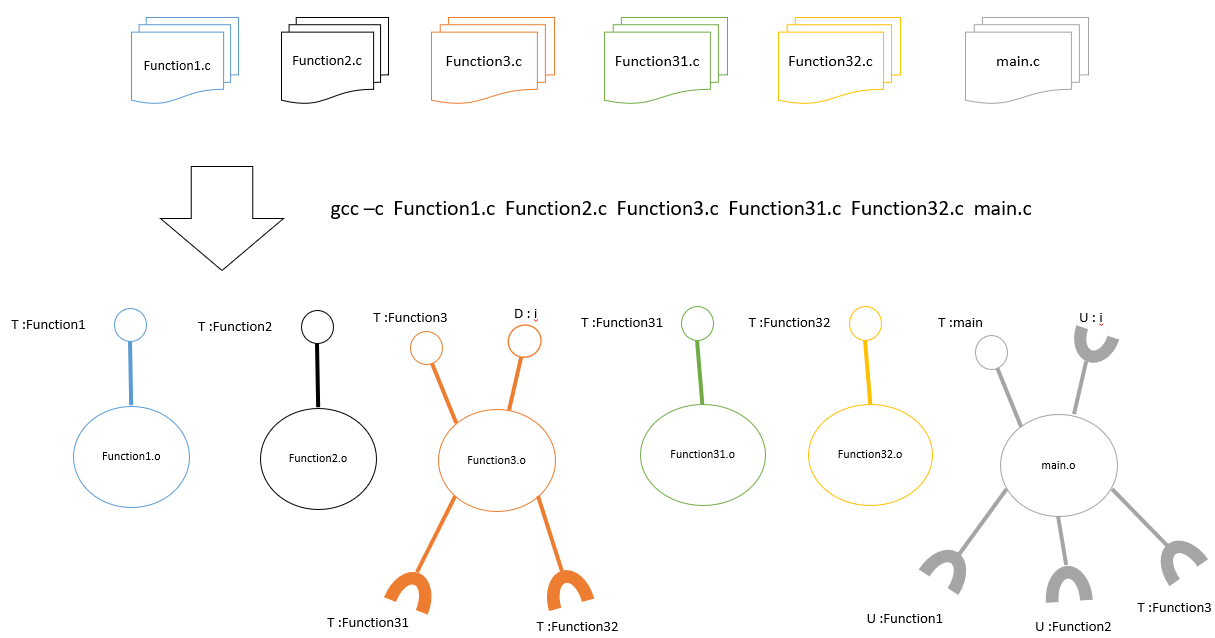
- 链接的过程:
思考
这篇文章是对链接过程的直观思考,写得并不严谨,但希望能对读者有所启发,主要参考了《深入理解计算机系统》《c专家编程》两本书。仔细想来这种将一个大的工程分解成一个个的“零部件”的做法在现实中也是广泛存在的,比如飞机、汽车这些复杂的机器哪个不是由零部件组成的?试想使用板钢一块制造一辆汽车其难度得有多大。所以链接器的存在也是合情合理。

