【CV】ICCV2015_Unsupervised Learning of Spatiotemporally Coherent Metrics
Unsupervised Learning of Spatiotemporally Coherent Metrics
Note here: it's a learning note on the topic of unsupervised learning on videos, a novel work published by Yann LeCun's group.
Link: http://arxiv.org/pdf/1412.6056.pdf
Motivation:
Temporal coherence is a form of weak supervision, which they exploit to learn generic signal representations that are stable with respect to the variability in natural video, including local deformations.
This induces the assumption that data samples that are temporal neighbors are also likely to be neighbors in the latent space.
(The invariant features in temporal sequences are also called slow features.)
Proposed Model:
The loss function based on temporal coherence is shown below:
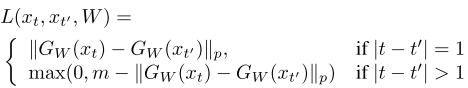
The first term denotes neighbor frames should be similar to maintain the slowness, but in case of the network learns a constant mapping, they add the second term to force frames at different time steps to be separated by at least a distance of m-units in feature space.
However, the second term only provides the discriminative criteria on pairwise distances in the feature space. This paper argues this discriminative constraint is too weak. Thus, they introduce a reconstruction term not only prevents the constant solution but also acts to explicitly preserve information about the input. So the new loss function is:
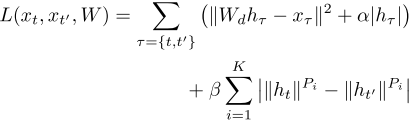
(The first term is reconstruction term, the second one is to train slow features. And \(a|h_{r}|\) denotes sparsity penalty term.)
The overall pipeline is shown below:
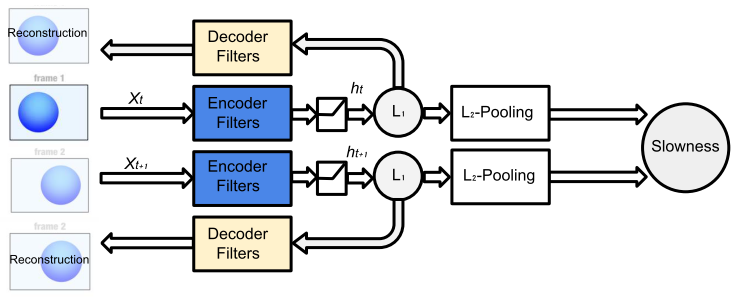
Tricks:
They leverage several intuitions and tricks in the paper, but as the limitation of knowledge in this field, I can just dive into one of these.
Pooling plays an important role in the architecture. Training through a local pooling operator enforces a local topology on the hidden activations, inducing units that are pooled together to learn complimentary features.
Also, pooling in space and across features when we use convolutional architecture can produce more invariant features.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号