

【CV】ICCV2015_Unsupervised Visual Representation Learning by Context Prediction
Unsupervised Visual Representation Learning by Context Prediction
Note here: it's a learning note on unsupervised learning model from Prof. Gupta's group.
Motivation:
- Similar to most motivations of unsupervised learning method, cut it out here.
Proposed Model:
- Given one central patch of the object, and another one arounding it, the model must guess the relative spatial configuration between these two patches.
- Intuition: when human doing this assignment, we get higher accuracy once we recognize what object it is and what it’s like with a whole look. That is to say, a model plays well on this game would have percepted the features of each object.
(i.e. we can get right answer for the following quizz once we recognize what objects they are.)
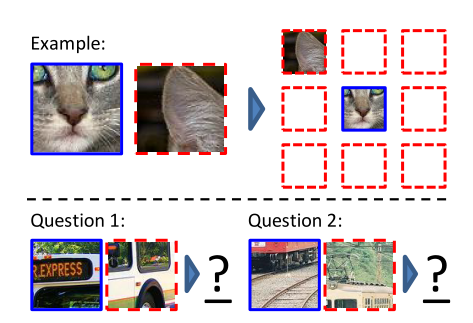
So the unsupervised representation learning can also be formulated as learning an embedding where images that are semantically similar close, while semantically different ones are far apart.
- Pipline:
- Feed two patches into a parallel convolutional network which share parameters.
- Fuse the feature vector of each patch and pass through stacked fully connected layers.
- Come out with an eight-dimension vector that predicts relative spatial configuration between the two patches.
- Compute loss, gradients and back propagate through this network to update weights.

Aoiding “trivial” solutions:
We need to preprocess images to avoid the model learns some trivial features, like:
- Low-level cues like boundary patterns or textures continuing between patches, which could potentially serve as a shortcut.
- Chromatic aberration: it arises from differences in the way the lens focuses light and different wavelengths. In some cameras, one color channel (commonly green) is shrunk toward the image center relative to the others. Once the network learns the absolute location on the lens, solving the relatve location task becomes trivial.

