
python爬虫基础学习——1
python爬虫基础学习——1
1.概念
一、什么是爬虫
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
二、Python爬虫架构
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
- 调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
- 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
- 网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
- 应用程序:就是从网页中提取的有用数据组成的一个应用。
涉及知识:前端html,css,javascrip https://www.runoob.com/html/html5-intro.html
大概了解到 选择器 就差不多了
大概写一下
html 包含整个html文档
head 元素包含了所有的头部标签元素。在 元素中你可以插入脚本(scripts), 样式文件(CSS),及各种meta信息。
可以添加在头部区域的元素标签为:
<title>, <style>, <meta>, <link>, <script>, <noscript> 和 <base>
body 里写文档的主体
一般利用style,id等属性进行选择和爬取
网站:TCP/IP协议 https://www.runoob.com/http/http-tutorial.html
正则表达式等进行数据处理
只用大概了解即可
常用库
请求库:实现 HTTP 请求操作
- urllib:一系列用于操作URL的功能。
- requests:基于 urllib 编写的,阻塞式 HTTP 请求库,发出一个请求,一直等待服务器响应后,程序才能进行下一步处理。
- selenium:自动化测试工具。一个调用浏览器的 driver,通过这个库你可以直接调用浏览器完成某些操作,比如输入验证码。
- aiohttp:基于 asyncio 实现的 HTTP 框架。异步操作借助于 async/await 关键字,使用异步库进行数据抓取,可以大大提高效率。
解析库:从网页中提取信息
- beautifulsoup:html 和 XML 的解析,从网页中提取信息,同时拥有强大的API和多样解析方式。
- pyquery:jQuery 的 Python 实现,能够以 jQuery 的语法来操作解析 HTML 文档,易用性和解析速度都很好。
- lxml:支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。
- tesserocr:一个 OCR 库,在遇到验证码(图形验证码为主)的时候,可直接用 OCR 进行识别。
存储库:Python 与数据库交互
- pymysql:一个纯 Python 实现的 MySQL 客户端操作库。
- pymongo:一个用于直接连接 mongodb 数据库进行查询操作的库。
- redisdump:一个用于 redis 数据导入/导出的工具。基于 ruby 实现的,因此使用它,需要先安装 Ruby。
爬虫框架
- Scrapy:很强大的爬虫框架,可以满足简单的页面爬取(比如可以明确获知url pattern的情况)。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。但是对于稍微复杂一点的页面,如 weibo 的页面信息,这个框架就满足不了需求了。
- Crawley:高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为 JSON、XML 等。
- Portia:可视化爬取网页内容。
- newspaper:提取新闻、文章以及内容分析。
- python-goose:java 写的文章提取工具。
- cola:一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高。
Web 框架库
- flask:轻量级的 web 服务程序,简单,易用,灵活,主要来做一些 API 服务。做代理时可能会用到。
- django:一个 web 服务器框架,提供了一个完整的后台管理,引擎、接口等,使用它可做一个完整网站。
2.请求库--requests库
requests功能比urllib强大,入门简单
安装
1.在cmd中 输入 pip install requests
!
输入 pip list 可以查看已安装的库
2.也可以在IDE(比如pycharm)中安装,操作类似
方法
import requests
requests.get()
requets.post()#常用
#此外还有
r = requests.put()
r = requests.delete()
r = requests.head()
r = requests.options()
使用type()函数可以查看返回的类型为Response对象
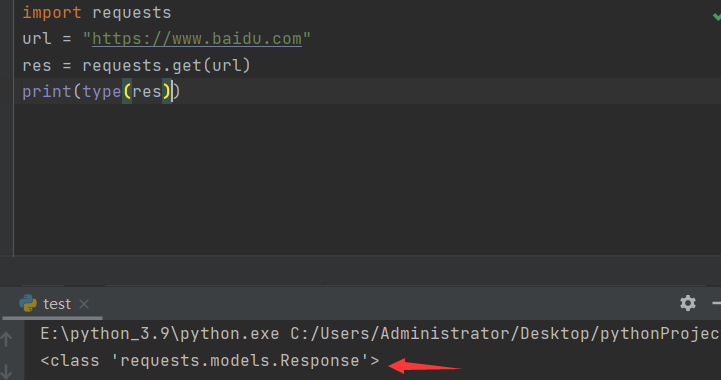
Response对象的常用属性
| 属性 | 作用 |
|---|---|
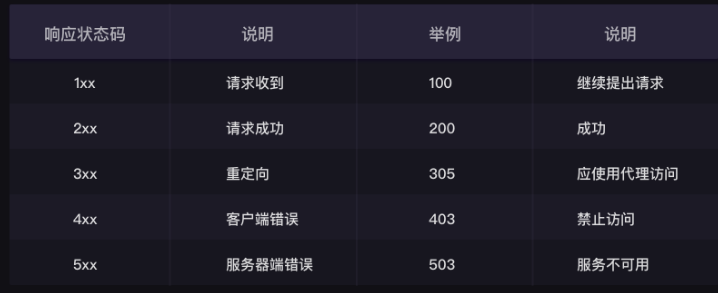
| response.status_code | 检查请求是否成功 |
| response.content | 把response对象转为二进制数据 |
| response.text | 把response对象转为字符串数据 |
| response.encoding | 定义对象的编码 |
一般来说
response.text用来保存文本
response.content保存图片,视频和音频等
实例
import requests
url = "https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fattachments.gfan.com%2Fforum%2Fattachments2%2F201304%2F18%2F001339jv88x0qs06vo3qq6.jpg&refer=http%3A%2F%2Fattachments.gfan.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1614588056&t=fd6b4b36498a6fc51211219640a34d1f"#百度图片
res = requests.get(url)
with open(r"C:\Users\Administrator\Desktop\pic.jpg","wb") as f:
f.write(res.content)
桌面上已有下载好的图片
当然,在用open()时,在windows上创建一个新文件是gbk的编码格式,如果出现编码错误,可以在open()里加上encoding = "utf-8"
注意
GET请求与POST请求
一般post请求带参数,用于登录网站等
get请求传递参数:
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get("http://httpbin.org/get", params=payload)
上面代码向服务器发送的请求中包含了两个参数key1和key2,以及两个参数的值。实际上它构造成了如下网址:
http://httpbin.org/get?key1=value1&key2=value2
post请求
无参数的post请求:
r = requests.post("http://httpbin.org/post")
有参数的post请求:
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.post("http://httpbin.org/post", data=payload)
post请求多用来提交表单数据,即填写一堆输入框,然后提交
3.解析库--beautifulsoup
下载bs4
pip install BeautifulSoup4
使用
bs对象 = BeautifulSoup(要解析的文本,'解析器')
注意 要解析的文本必须是字符串
解析器可以用内置库html.parser(也可以下载更加强大lxml库)
import requests
from bs4 import BeautifulSoup
url = "https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html"
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
print(type(soup))
print(soup)
说明返回了一个BeautifulSoup对象
方法
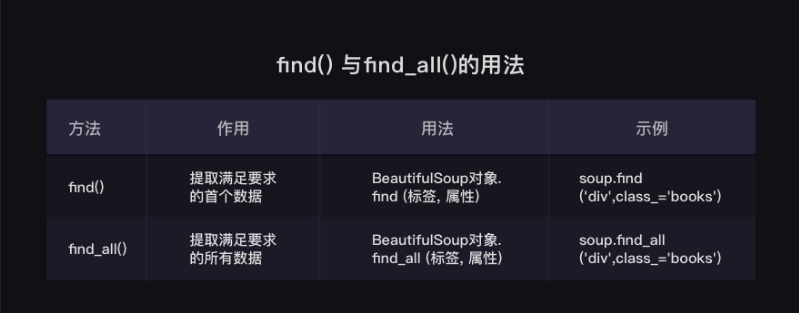
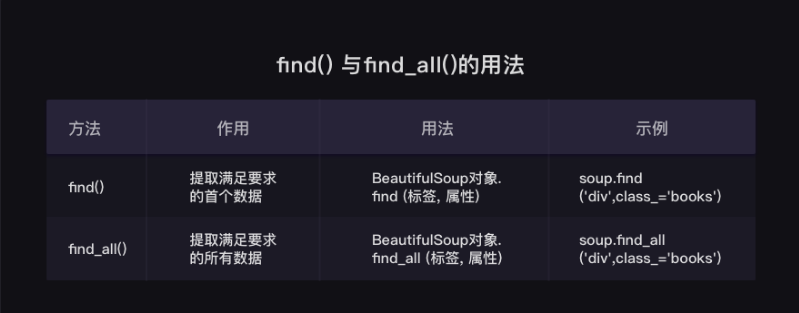
find() findall()
find()与find_all()是BeautifulSoup对象的两个方法,它们可以匹配html的标签和属性,把BeautifulSoup对象里符合要求的数据都提取出来。
find_all()返回类型 <class 'bs4.element.ResultSet'>
其实是Tag对象以列表结构储存了起来,可以把它当做列表来处理
import requests
from bs4 import BeautifulSoup
url = "https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html"
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
mes = soup.find("div")
print(type(mes))
数据类型是Tag
Tag对象的属性与用法

find()和find_all()返回类型依旧为Tag对象
Response对象——字符串——BS对象。到这里,又产生了两条分岔:一条是BS对象——Tag对象;另一条是BS对象——列表——Tag对象
利用Tag.text与Tag['属性']可以取到值
实例
import requests
# 引用requests库
from bs4 import BeautifulSoup
# 引用BeautifulSoup库
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
res_foods = requests.get('http://www.xiachufang.com/explore/',headers = headers)
# 获取数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 解析数据
tag_name = bs_foods.find_all('p',class_='name')
# 查找包含菜名和URL的<p>标签
tag_ingredients = bs_foods.find_all('p',class_='ing ellipsis')
# 查找包含食材的<p>标签
list_all = []
# 创建一个空列表,用于存储信息
for x in range(len(tag_name)):
# 启动一个循环,次数等于菜名的数量
list_food = [tag_name[x].text[18:-14],tag_name[x].find('a')['href'],tag_ingredients[x].text[1:-1]]
# 提取信息,封装为列表。
list_all.append(list_food)
# 将信息添加进list_all
print(list_all)
4.json
粗暴地来解释,在Python语言当中,json是一种特殊的字符串,这种字符串特殊在它的写法——它是用列表/字典的语法写成的。
两个函数
- json.dumps(): 对数据进行编码。
- json.loads(): 对数据进行解码。
查看Network
有时我们用requests,get()无法得到任何东西
这可能是因为网页是动态加载的
我们可以查看network
Network的功能是:记录在当前页面上发生的所有请求。
浏览器总是在向服务器,发起各式各样的请求。当这些请求完成,它们会一起组成我们在Elements中看到的网页源代码。
所以我们用以上方法得到的其实是network中的第一项请求,
该请求中并未包含需要的信息
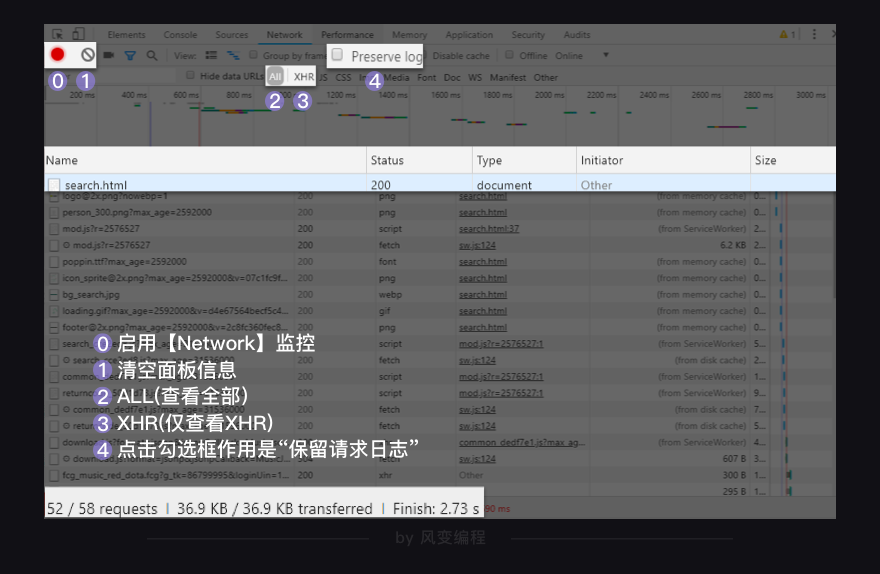
第0行的左侧,红色的圆钮是启用Network监控(默认高亮打开),灰色圆圈是清空面板上的信息。右侧勾选框Preserve log,它的作用是“保留请求日志”。如果不点击这个,当发生页面跳转的时候,记录就会被清空。所以,我们在爬取一些会发生跳转的网页时,会点亮它。
第1行,是对请求进行分类查看。我们最常用的是:ALL(查看全部)/XHR(仅查看XHR,我们等会重点讲它)/Doc(Document,第0个请求一般在这里),有时候也会看看:Img(仅查看图片)/Media(仅查看媒体文件)/Other(其他)。最后,JS和CSS,则是前端代码,负责发起请求和页面实现;Font是文字的字体
XHR
XHR的功能是传输数据,其中有非常重要的一种数据是用json格式写成的,和html一样,这种数据能够有组织地存储大量内容。json的数据类型是“文本”,在Python语言当中,我们把它称为字符串。我们能够非常轻易地将json格式的数据转化为列表/字典,也能将列表/字典转为json格式的数据。
完整表述是XHR and Fetch
我们平时使用浏览器上网的时候,经常有这样的情况:浏览器上方,它所访问的网址没变,但是网页里却新加了内容。
典型代表:如购物网站,下滑自动加载出更多商品。在线翻译网站,输入中文实时变英文。
import requests
# 引用requests库
res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60997426243444153&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 调用get方法,下载这个字典
json_music = res_music.json()
# 使用json()方法,将response对象,转为列表/字典
print(type(json_music))
# 打印json_music的数据类型
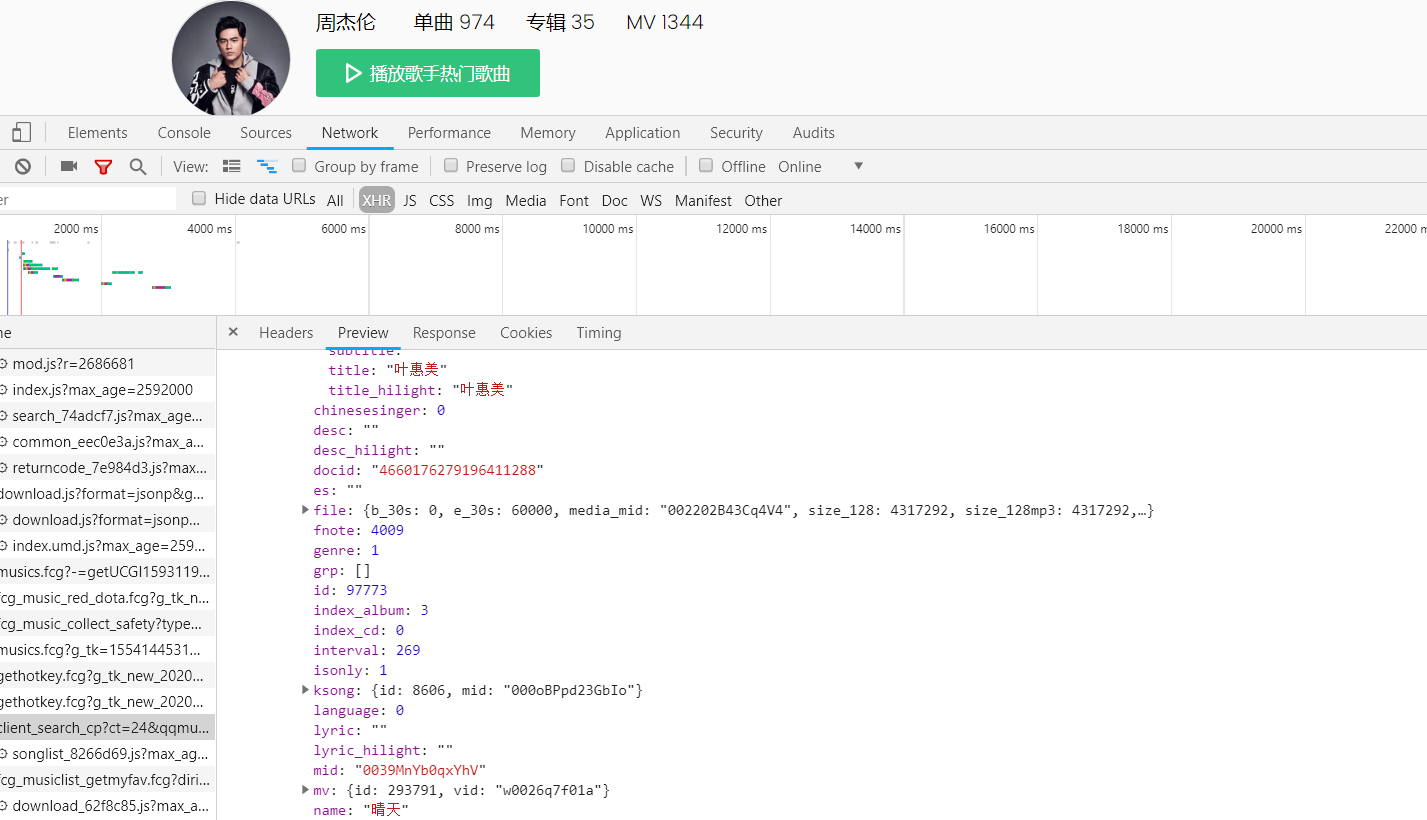
利用res.json()后,在preview中利用字典/列表爬取数据
在XHR中抓包,可以看看size较大的文件
import requests
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=64346650345599886&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk_new_20200303=1554144531&g_tk=1554144531&loginUin=1322767102&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'
res = requests.get(url,headers = headers)
js = res.json()
music = js['data']['song']['list']
for i in music:
print(i['name'],end=',')
print(i['album']['name'],end=',')
print(str(i['interval']),end=',')
print('https://y.qq.com/n/yqq/song/'+i['mid']+'.html')
5.数据存储
csv简介
csv:逗号分隔符文件
本质:文本文件
其文件以纯文本形式存储表格数据(数字和文本),文件的每一行都是一个数据记录。
每个记录由一个或多个字段组成,用逗号分隔。使用逗号作为字段分隔符是此文件格式的名称的来源,因为分隔字符也可以不是逗号,有时也称为字符分隔值。
CSV 广泛用于不同体系结构的应用程序之间交换数据表格信息,解决不兼容数据格式的互通问题。一般按照传输双方既定标准进行格式定义,而其本身并无明确格式标准。
特征
- 文件采用纯文本存储,需要使用某个字符集(ASCII、Unicode、UTF-8等)
- 数据由记录组成(一般是每一行一条记录)
- 每条记录被分隔符分为一个个字段(常用的分隔符有
',','\t',' ',';'等)- 每条记录都有同样的字段序列
file=open('test.csv','a+')
file.write('美国队长,钢铁侠,蜘蛛侠')
file.close()
可以用excel打开
缺点:无法存储图片等
存储成csv格式文件和存储成Excel文件,这两种不同的存储方式需要引用的模块也是不同的。
操作csv文件我们需要借助csv模块;操作Excel文件则需要借助openpyxl模块。
csv的写入与读取
import csv
#引用csv模块。
csv_file = open('demo.csv','w',newline='',encoding='utf-8')
加newline=' '参数的原因是,可以避免csv文件出现两倍的行距(就是能避免表格的行与行之间出现空白行)。加encoding='utf-8',可以避免编码问题导致的报错或乱码。
用csv.writer()函数创建一个writer对象
#接上
csv_write = csv.writer(csv_file)#创建writer对象
csv_write.writerow(['姓名','年龄'])#用.writerow方法写入一行
最后关闭文件
csv_file.close()
同时也有csv.reader()
import csv
csv_file = open(r'C:\Users\Administrator\Desktop\test.csv',"r+",newline='',encoding='utf-8')
reader = csv.reader(csv_file)
for row in reader:
print(row)
通过循环reader对象输出每一行的数据
excel的写入与读取
一个Excel文档也称为一个工作薄(workbook),每个工作薄里可以有多个工作表(wordsheet),当前打开的工作表又叫活动表。
每个工作表里有行和列,特定的行与列相交的方格称为单元格(cell)
下载第三方模块
pip3 install openpyxl
可能是网速的问题,需要多试试
或者
pip install requests -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
换源
说到换源
这里有一篇 windows下换源
写入数据
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = 'new title'
sheet['A1'] = '第一个数据'
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = 'new title'
sheet['A1'] = '额'
row = ['一个数据','两个数据']
sheet.append(row)
wb.save(r'C:\Users\Administrator\Desktop\new.xlsx')
读取数据
wb = openpyxl.load_workbook((r'C:\Users\Administrator\Desktop\new.xlsx')
sheet = wb['new title']
cell = sheet['A1']
print(cell.value)


