Word2vec之CBOW
一、Word2vec
word2vec是Google与2013年开源推出的一个用于获取word vecter的工具包,利用神经网络为单词寻找一个连续向量看空间中的表示。word2vec是将单词转换为向量的算法,该算法使得具有相似含义的单词表示为相互靠近的向量。
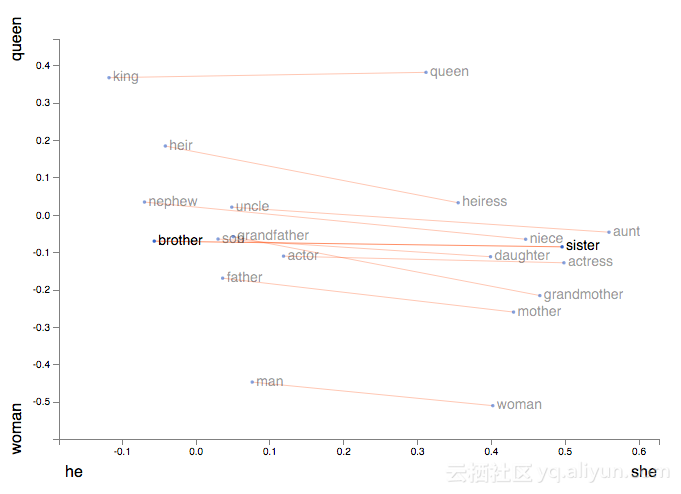
此外,它能让我们使用向量算法来处理类别,例如着名等式King−Man+Woman=Queen。
word2vec一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型:
1、CBOW:根据中心词周围的词来预测中心词,有negative sample和Huffman两种加速算法;
2、Skip-Gram:根据中心词来预测周围词;
二者的结构十分相似,理解了CBOW,对于Skip-Gram也就基本理解了。下面主要来讲讲CBOW。
来源:word2vec原理(一) CBOW与Skip-Gram模型基础
二、CBOW

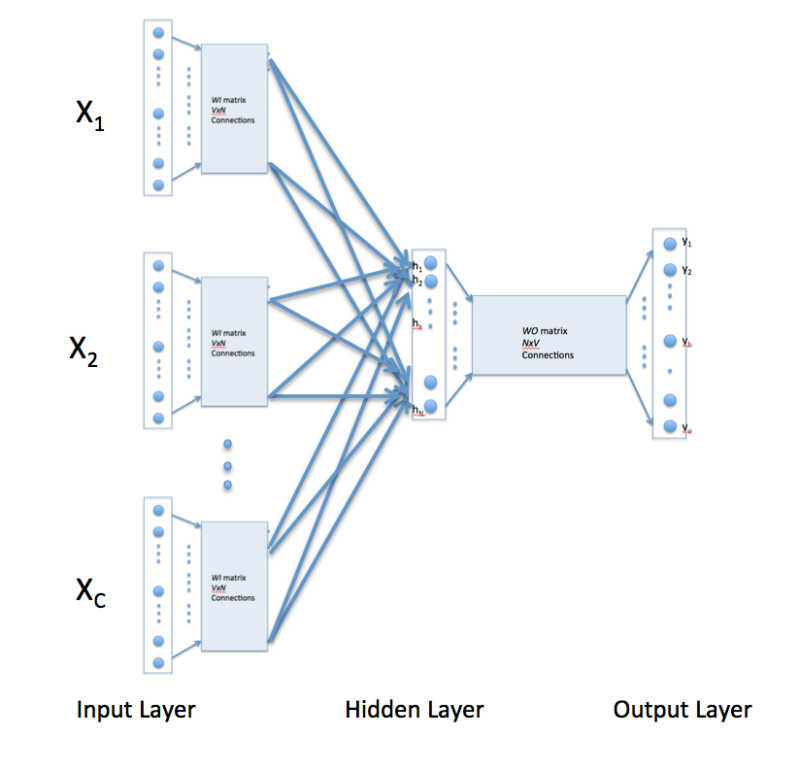
上图为CBOW的主要结构形式。对于上图,假设单词的向量空间维度为V,上下文单词个数为C,求解两个权重均值W和W'。对于上图的解释如下:
1、输入层:上下文单词的onehot形式;
2、隐藏层:将输入层所有onehot后的向量乘以第一个权重矩阵W(所有的权重矩阵相同,即共享权重矩阵),然后相加求平均作为隐藏层向量,该向量的大小与输入层的每一个样本大小相同;
3、输出层:将隐藏层向量乘以第二权重矩阵W‘,得到一个V维的向量,然后再通过激活函数(softmax)得到每一维词的概率分布,概率最大的位置所指示的单词为预测出的中间词;
4、一般使用使用的损失函数为交叉熵损失函数,采用梯度下降的方式来更新W和W’;这实际上是一个假任务,即我们需要的只是第一个权重矩阵W。得到第一个矩阵W之后,我们就能得到每个单词的词向量了。
更具体的结构以及流程如下:
来源:究竟什么是Word2vec ? Skip-Gram模型和Continuous Bag of Words(CBOW)模型 ?
I drink coffee everyday
我们使用的window size设为2。
三、word2vec的python使用
可以使用python中的gensim库。
具体可以见谈谈Word2Vec的CBOW模型最后一个部分,以及官网https://radimrehurek.com/gensim/models/word2vec.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号