LSTM调参经验
0、开始训练之前先要做些什么?
在开始调参之前,需要确定方向,所谓方向就是确定了之后,在调参过程中不再更改
1、根据任务需求,结合数据,确定网络结构。
例如对于RNN而言,你的数据是变长还是非变长;输入输出对应关系是many2one还是many2many等等,更多结构参考如下
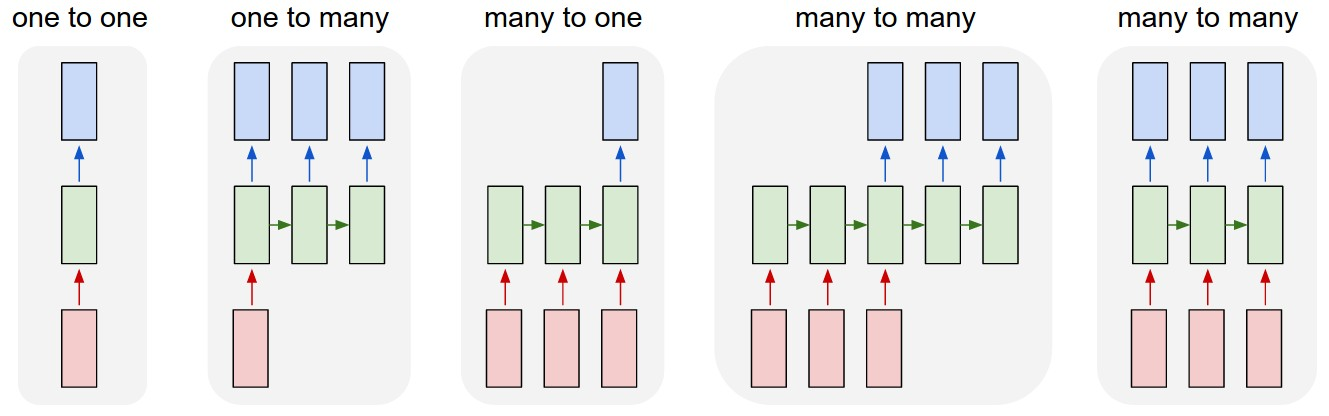
非RNN的普通过程,从固定尺寸的输入到固定尺寸的输出(比如图像分类)
输出是序列(例如图像标注:输入是一张图像,输出是单词的序列)
输入是序列(例如情绪分析:输入是一个句子,输出是对句子属于正面还是负面情绪的分类)
输入输出都是序列(比如机器翻译:RNN输入一个英文句子输出一个法文句子)
同步的输入输出序列(比如视频分类中,我们将对视频的每一帧都打标签)
2、确定训练集、验证集和测试集,并尽可能的确保它们来自相同的分布,并且训练集与测试集的划分通常是7:3,然后在训练集中在进行验证集的划分,验证集的划分可以是交叉验证,也可以是固定比例。
一旦确定了数据集的划分,就能够专注于提高算法的性能。如果能够保证三者来自相同的分布,对于后续的问题定位也会有着极大的意义。
例如,某个模型在训练集上效果很好,但是在测试集上的结果并不如意,如果它们来自相同的分布,那么就可以肯定:模型在训练集上过拟合了(overfitting),那么对应的解决办法就是获取更多的训练集。
但是如果训练集和测试集来自不同的分布,那么造成上述结果的原因可能会是多种的:
(i).在训练集上过拟合;(ii).测试集数据比训练集数据更难区分,这时,有必要去进行模型结构,算法方面的修改;(iii).测试集并不一定更难区分,只是与训练集的分布差异比较大,那么此时如果我们去想方设法提高训练集上的性能,这些工作都将是白费努力。
3、确定单一的评估算法的指标。
这里需要注意的是,在进行调参之前,我们需要明确我们的目的是什么,是尽可能的分的准(查准率,precision)还是尽可能的找的全(查全率,recall)亦或者两者都要考虑(F1或者ROC曲线下面积);还或者说,我不仅要关注准确率还要考虑时间效率(此时可以将准确率与算法的运行时间做一个简单的加权,来构建出一个新的指标)。
我们需要确定使用的指标,并且在优化过程中不再更改,否者你会不知道究竟哪个参数好,因为两个不同的指标之间不容易比较。另外,需要明确使用一个指标,这样能够更加直观的观察不同参数之间的好坏。
4、对数据进行归一化/标准化处理。
归一化的原因:统一量纲、便于梯度的计算、加快收敛等

归一化之前
归一化之后
归一化:一般采用max-min归一化,使得数据缩放到大小为(-1,1)或者(0,1)之间。
标准化:z-scores标准化,使得数据整体的均值为0,方差为1。
对于图像数据的归一化可以采用除以255(如果图像像素在0-255之间)的方式。
数据归一化的方式是对训练集进行归一化,然后将这种归一化方式应用到验证集和测试集中。
5、打印你的网络参数个数,与你的数据量进行一个对比。网络越大,功能越强,但也更容易过拟合。不要尝试用10,000个样本来学习一百万个参数。
1、开始调参之前先要做些什么?
1、首先不使用Dropout以及正则化项,使用一个较小的数据集(从原始数据集中取出一小部分),让你的网络去训练拟合这个数据集,看看能否做到损失为0 / 准确率为1 (前提是这个小数据集不能只包含一类样本)。
2、在一轮epoch中,打印出输入、输出,检测数据的正确性(例如图像数据确保size,其他数据检查是否输入为0,以及检查是否每个batch都是相同的值,检查特征与标签是否对应)
3、去除正则化项,观察初始的loss值,并对loss进行预估。
例如,一个二分类问题,使用softmax分类器,那么当样本属于两个类的概率都为0.5的时候,此时的loss = -ln(0.5) = 0.69,后续当网络的loss不再变化时,看看那时候的loss与这个值的关系。如果最终不再变化的loss值等于这个值,那么也就是说网络完全不收敛。
4、可视化训练过程,在每一轮epoch训练完成后,计算验证集上的loss与准确率(你的评价指标),并记录下每一轮epoch后训练集与验证集的loss与评价指标。如果是图像数据,可以进行每一层的可视化。
5、如果可以的话,在开始训练之前,尝试用经典的数据集(网上公开数据集,经常在深度学习的网络中使用的数据集,例如MNIST,CIFAR10)先进行训练,因为这些经典数据集都有参考标准(baseline),而且没有数据方面的问题(如噪声、不平衡、随机性过大导致难以学习的问题等等,尤其是在你自己设计了一个新的网络结构时。
2、如何调参?
1、在确保了数据与网络的正确性之后,使用默认的超参数设置,观察loss的变化,初步定下各个超参数的范围,再进行调参。对于每个超参数,我们在每次的调整时,只去调整一个参数,然后观察loss变化,千万不要在一次改变多个超参数的值去观察loss。
2、对于loss的变化情况,主要有以下几种可能性:上升、下降、不变,对应的数据集有train与val(validation),那么进行组合有如下的可能:
train loss 不断下降,val loss 不断下降——网络仍在学习;
train loss 不断下降,val loss 不断上升——网络过拟合;
train loss 不断下降,val loss 趋于不变——网络欠拟合;
train loss 趋于不变,val loss 趋于不变——网络陷入瓶颈;
train loss 不断上升,val loss 不断上升——网络结构问题;
train loss 不断上升,val loss 不断下降——数据集有问题;
其余的情况,也是归于网络结构问题与数据集问题中。
3、当loss趋于不变时观察此时的loss值与1-3中计算的loss值是否相同,如果相同,那么应该是在梯度计算中出现了nan或者inf导致oftmax输出为0。
此时可以采取的方式是减小初始化权重、降低学习率。同时评估采用的loss是否合理。
3、解决方式
1、当网络过拟合时,可以采用的方式是正则化(regularization)与丢弃法(dropout)以及BN层(batch normalization),正则化中包括L1正则化与L2正则化,在LSTM中采用L2正则化。另外在使用dropout与BN层时,需要主要注意训练集和测试集上的设置方式不同,例如在训练集上dropout设置为0.5,在验证集和测试集上dropout要去除。
2、当网络欠拟合时,可以采用的方式是:去除 / 降低 正则化;增加网络深度(层数);增加神经元个数;增加训练集的数据量。
3、设置early stopping,根据验证集上的性能去评估何时应该提早停止。
4、对于LSTM,可使用softsign(而非softmax)激活函数替代tanh(更快且更不容易出现饱和(约0梯度))
5、尝试使用不同优化算法,合适的优化器可以是网络训练的更快,RMSProp、AdaGrad或momentum(Nesterovs)通常都是较好的选择。
6、使用梯度裁剪(gradient clipping),归一化梯度后将梯度限制在5或者15。
7、学习率(learning rate)是一个相当重要的超参数,对于学习率可以尝试使用余弦退火或者衰减学习率等方法。
7、可以进行网络的融合(网络快照)或者不同模型之间的融合。
参考文献:
2、Machine Learning Yearning,吴恩达

 浙公网安备 33010602011771号
浙公网安备 33010602011771号