

deeplearning.ai课程学习(4)
第四周:深层神经网络(Deep Neural Networks)
1、深层神经网络(Deep L-layer neural network)
在打算使用深层神经网络之前,先去尝试逻辑回归,尝试一层然后两层隐含层,把隐含层的数量看做是另一个可以自由选择大小的超参数,然后再保留交叉验证数据上评估,或者用你的开发集来评估。
2、前向传播和反向传播(Forward and backward propagation)

前向传播:
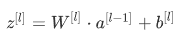
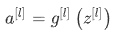

反向传播:
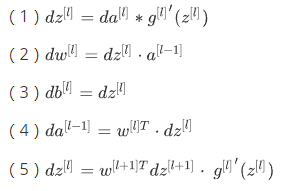
3、为什么使用深层表示?(Why deep representations?)
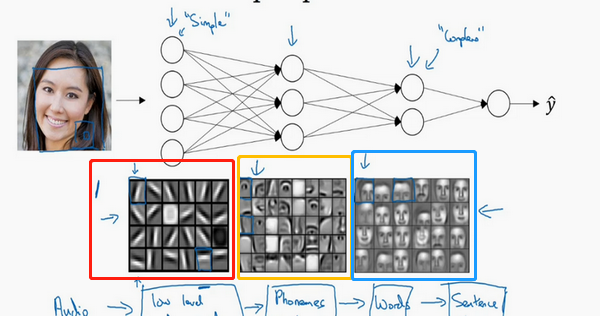
假设,建立一个人脸识别或是人脸检测系统,深度神经网络所做的事就是,当你输入一张脸部的照片,可以把深度神经网络的第一层,当成一个特征探测器或者边缘探测器。
第一张大图中的小方块(第一行第一列)就是一个隐藏单元,它会去找这张照片里(“|”)边缘的方向。那么这个隐藏单元(第四行第五列),可能是在找(“—”)水平向的边缘在哪里。
我们可以把照片里组成边缘的像素们放在一起看,然后它可以把被探测到的边缘组合成面部的不同部分(第二张大图)。比如说,可能有一个神经元会去找眼睛的部分,另外还有别的在找鼻子的部分,然后把这许多的边缘结合在一起,就可以开始检测人脸的不同部分。最后再把这些部分放在一起,比如鼻子眼睛下巴,就可以识别或是探测不同的人脸(第三张大图)。
4、参数VS超参数(Parameters vs Hyperparameters)
算法中的learning rate (学习率)、iterations(梯度下降法循环的数量)、L(隐藏层数目)、nL(隐藏层单元数目)、choice of activation function(激活函数的选择),这些数字实际上控制了最后的参数W和b的值,所以它们被称作超参数。
如何寻找超参数的最优值?
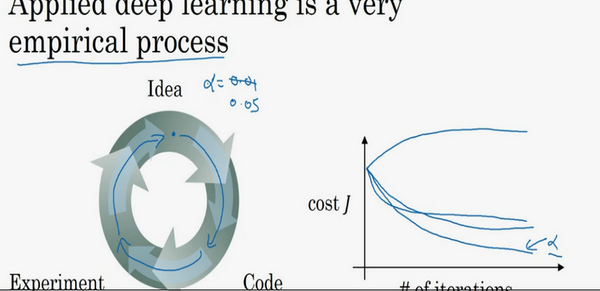
Idea—Code—Experiment—Idea这个循环,尝试各种不同的参数,实现模型并观察是否成功,然后再迭代。
例如,通常你有个想法,比如你可能大致知道一个最好的学习率值,可能说a=0.01最好,我会想先试试看,然后你可以实际试一下,训练一下看看效果如何。
然后基于尝试的结果你会发现,你觉得学习率设定再提高到0.05会比较好。如果你不确定什么值是最好的,你大可以先试试一个学习率a,再看看损失函数J的值有没有下降。
然后你可以试一试大一些的值,然后发现损失函数的值增加并发散了。然后可能试试其他数,看结果是否下降的很快或者收敛到在更高的位置。
你可能尝试不同a的并观察损失函数J怎么变换,如果这个a值会加快学习过程,并且收敛在更低的损失函数值上(箭头标识),那么就确定使用这个a值。
