cs144Lab总结
CS144Lab总结
之所以要做这个课程,主要原因是自己对于网络知之甚少,之前为了找实习背诵过一些面试题,三次握手、四次挥手balabala…… 为了日后搞开发不至于对网络抓瞎,我做了一个违背祖宗 的决定,咳咳,一个艰难的决定,我说一镜到(bi)
准备工作
依赖
根据lab0的文档以及https://stanford.edu/class/cs144/vm_howto/vm-howto-byo.html要求,安装好需要用到的库。
并且根据要求修改networkmanager的config文件:
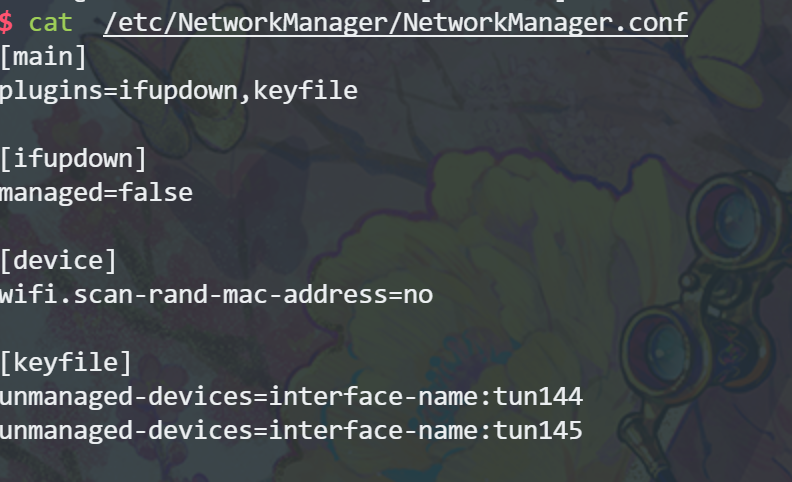
并且 sudo systemctl reload NetworkManager重启服务。
Debug
cs144推荐的debug方式是使用gdb调试,但是在这个系列lab的测试过程中,segment fault之类错误反而难以出发,因为我们整个实验都不会用到指针。
我的debug策略是打log,在实际lab的debug过程中,通过读log的方式判断自己实现那里有问题。
通过cpp的包扩展,可以写一个传入可变参数数量的模版函数,并且由一个宏来控制是否输出。
#define DEBUGPRINT false
template <typename T>
void DebugPrint(T &&t) {
if (!DEBUGPRINT) {
return;
}
std::cerr << t << std::endl;
}
template <typename T, typename... Targs>
void DebugPrint(T &&t, Targs &&...args) {
if (!DEBUGPRINT) {
return;
}
std::cerr << t << " ";
DebugPrint(std::forward<Targs>(args)...);
}
Lab1 StreamReassembler
由于TCP报文到达的顺序可以是无序的,但是最后返回给application调用者的结果一定是正常排序好了的数据,因此我们需要Reassembler对tcp报文进行收集,重排。并且缓存那些已经收到但是还没法确认的报文(因为如果前面的报文没有受到,只能对当前报文进行暂存)
lab的文档中对这个 reassembler的描述图可谓是相当准确,但是同时它也有一个没有讲清楚的点。first unacceptable index - first unassembled index也是受制于 给定的capacity,也就是说不能超过 capacity。这个点如果忽略了后续在 lab4就会触发bug。
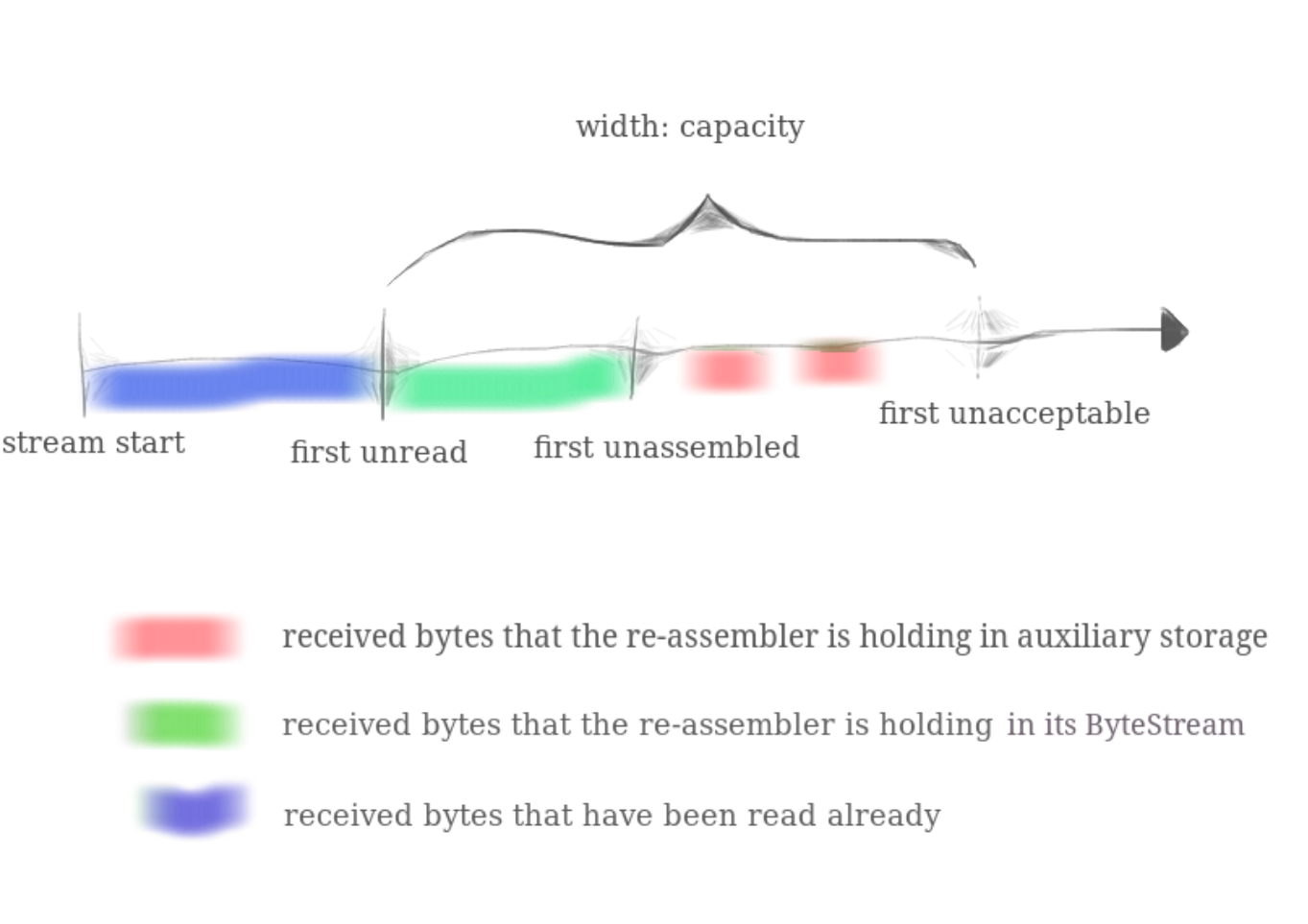
capacity 很重要,很重要,很重要!
fisrt unassembled index - first unread index <= capacity,已经收集好但是未被application读取的字节数(因为这段数据是连续的)不能超过capacity。first unacceptable index - first unassembled index <= capacity, 注意我这里是直接用 index相减,意味着我们reassambler能收集的最大index是有限制的。unassembled的数据量,也就是暂存的数据字节数不能超过capacity - (first unacceptable index - first unassembled index)
如果有测试点没有过,请仔细检查这三点条件是否满足!
收集合并的策略有很多,我的实现不算高效。因为我刚刚写了 LeetCode的 57 插入区间这道题目,我发现它是如此地和这道题目相吻合。
给你一个 无重叠的 ,按照区间起始端点排序的区间列表。
在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)
这简直完美符合……
Lab2 TCP Receiver
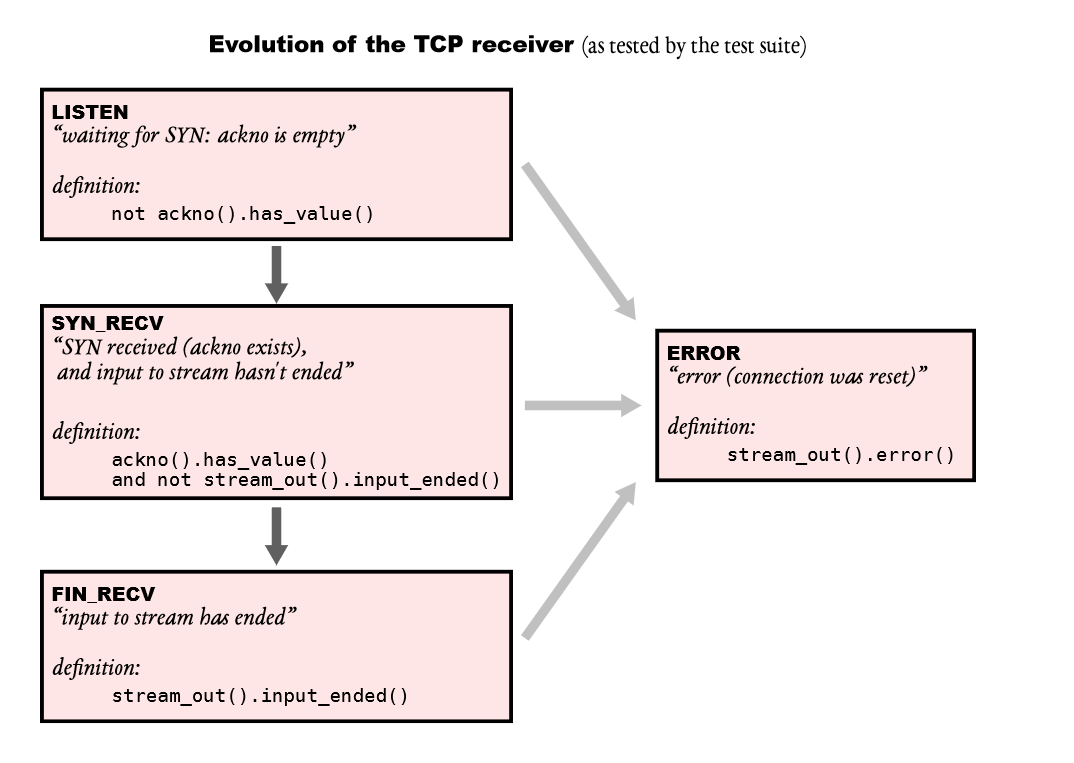
Receiver的实现,我感觉到时没有什么坑点,主要还是在 segment receive这个函数的逻辑里面:
- 如果receiver处于listen 状态,那么需要拒绝所有非 syn的tcp 报文。
- 如果是过时的报文
payload_abs_seqno + payload.size() + header.fin <= _next_abs_seqno也就是当前报文已经带来不了新的消息,直接拒收。
如果 reassembler实现的好,那么实际上这个lab没什么太多工作,我们能做的也只是把payload传给 reassembler。
Lab3 TCP Sender
做lab之前一定要好好看明白这个图片,不然后续又在debug。
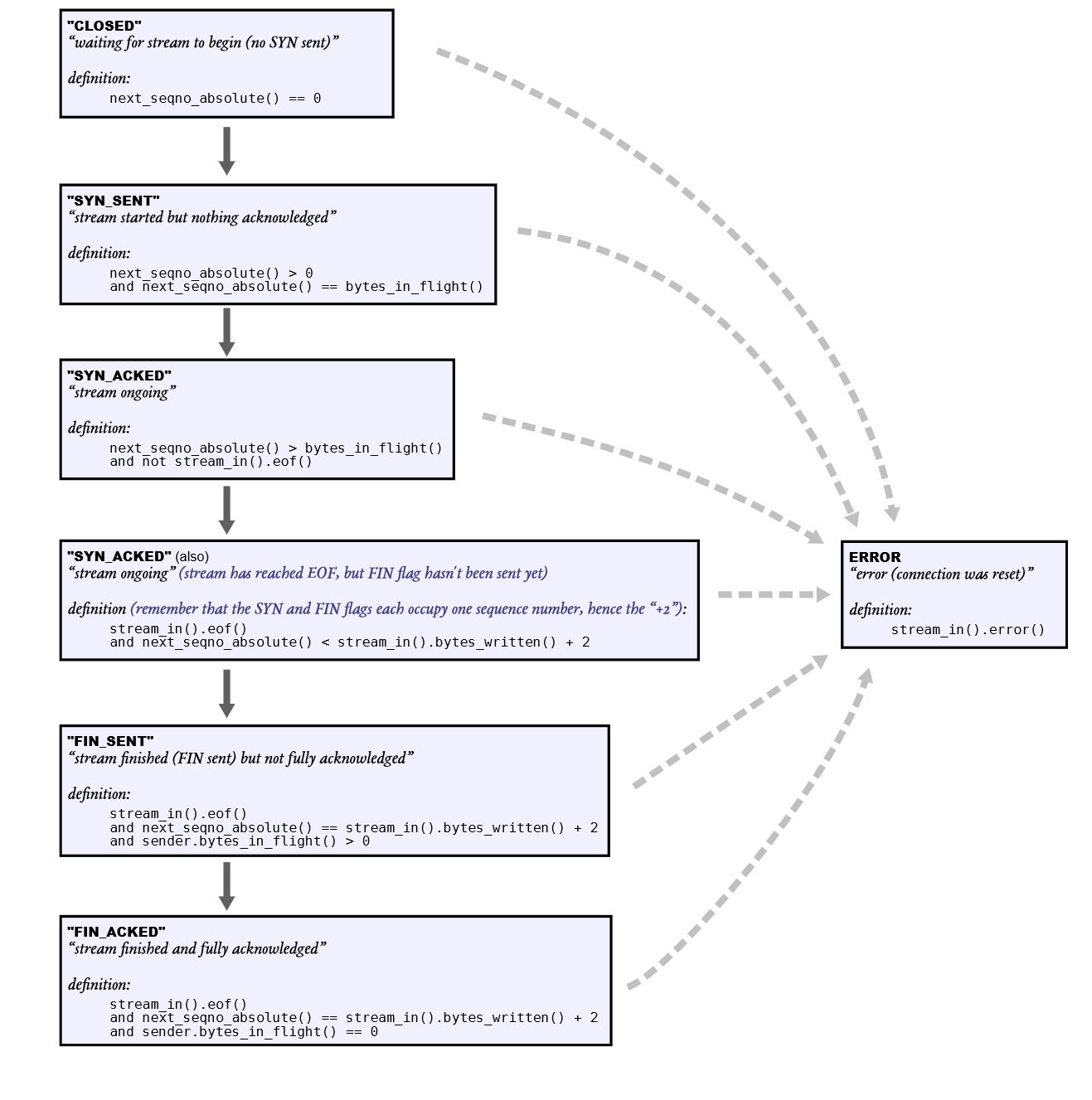
因为sender每一个报文的发送,都需要一个ack,如果没有收到ack,那么就会涉及重传报文。cs144要求我们自己维护一个数据结构来保存这些需要重传的报文。
注意!我自己的定义 std::list<TCPSegment> _store{}; ,直到_store 为空,我才会从 _stream中再一次读取数据。
fill_window:从 _stream中读取数据并制作报文,syn和fin也是由此函数完成。只有 seg.length_in_sequence_space() > 0 也就是做好的tcp报文非空,才会发送。对于每个发送但未被 ack的报文都会进行记录,以保证重传,即使该报文payload为0。
ack_received:接受ack信息,及时更新重传列表,以及重传次数信息,并重置定时器。
tick: 如果超时,那么重传一个报文并且记录重传次数。
踩过的坑:
-
关于重传,文档其实有一点误导性。文档中说如果报文没有
payload,那么我们不需要暂存以便重传,因为如果没有payload相当于这个报文可以随时重新制作。看上去有点道理,但是实际上,如果你不将syn或者fin报文纳入_store重传列表,那么在实现起来会给带来很多麻烦,维护任何已经发送但是没有ack的报文,包括syn报文,将已发送但是没有ack的报文放到重传列表,重传列表为空后才去读取数据制作报文。 -
另一个你可能也会和我一样犯的错误,就是
fin和synflag位也是需要占用size的,如果你的left window size(还留有的,未发送的空间)为 0,那么是不能发送fin和synflag的。(初始的window size为1) -
sender 可能会收到过期或者错误的ack,那么什么是过期或者错误的ack报文?
- 当前
ackno小于_last_ackno,也就是这个ackno实际上已经被确认了,因此属于过期ack。 - 如果当前
ackno等于_last_ackno,但是传递过来 windows_size 要小于当前的window_size,同样也属于过期报文。(也同样意味着,我们需要处理 ackno == last_ackno,但是 window size变大的情况) - 如果ackno 甚至超过了已经发送的 seqno,那么说明这个报文是戳我的。
这三个条件必须处理好,不然很容易挂测试。
- 当前
-
还有一个特殊的条件,window size 为 0,实际上的处理是把它当做1,这是文档中要求的,我认为这个也是有道理的。并且我们只有在 win_size 不为 0的时候出现重传,才会要求倍增 rto,并且记录重传次数。还记得我们上面说的 初始window size为1吗? 这意味着 syn报文如果被重传,同样会被记录重传次数,当重传次数超过一定限制,那么就是直接关闭 tcp连接。
这个lab就是需要读文档细心,做实验细心,debug细心,多想多看。一定要把测试的错误信息看懂。
lab4 tcp connection
这个lab其实不难,但是这个lab是我花时间最多的,主要这个之前的lab没有做好,导致出现有些测试案例不过。
通过这个lab主要还是更好地梳理了tcp连接的过程。
- 每个socket 对应一个tcp connection,而一个tcp connection既包含了sender也包含了receiver,所以一个tcp连接是双向的。做完了lab4 之后我觉得之前的client server划分其实不准确,因为client 和server都是一样的,都需要sender发送数据,都需要receiver接受数据。
- sender最开始是处于一个close的状态。也就是waiting for stream begin。这里有点讲究。begin可以是 socket 主动调用 sender的
fill_window函数,这时候sender从close状态变成发送syn但是。也可以是receiver接受 报文之后,再要求sender发送syn报文。这或许就是 client 和server之间的差异吧。 - TCP共识一 等待退出 。TCP的receiver和 sender如果都结束了,那么TCP连接可以正常关闭。一般在面试的八股文里面会说,tcp连接断开后续等待一段时间。那么为什么等待呢?可以确定的是,如果我的TCP连接主动断开,那么我的
receiver和 sender都 已经结束的,sender也收到的fin的ack报文,receiver也发送了对方的fin ack报文。但是问题就是出在receiver,receiver确实发送了对方fin的ack,但是我们不确定tcp的另一端的sender能不能收到这个fin ack。如果我们直接关闭tcp连接,如果这个fin ack丢失了,另一端的tcp connection的sender就会不断重传,知道超过了最多重传次数后,另一端的tcp connector以error形式关闭 tcp 连接,这无疑是一个失败的设计。所以我们需要等待一段时间,以保证fin ack丢失后能够重传,最后两端的tcp都是正常退出连接,而不是一个正常退出,一个以error状态退出(因为网络其实没有发生error)。 - TCP共识二 直接退出 。但是有一种情况下,tcp可以不需要等待直接退出。tcp connection推出的条件是 receiver和sender都结束了。那么如果receiver已经结束了,但是sender没有结束,并且还没有发送sender的fin报文。那么因为receiver的ack是夹带在sender的报文中,如果sender需要达到fully acknowledge状态,那么这个receiver的fin ack一定会另一端的tcp connection接受。核心就是sender会保证receiver fin ack一定会被对方接受。这种情况下,如果sender和receiver到达结束状态,那么tcp连接可以不等待直接退出。
Lab5 lab6
这两个lab其实没太多好说的,就是看文档然后写,这两个lab我基本上都是编译然后测试全通过。
通关图


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· DeepSeek 开源周回顾「GitHub 热点速览」
2020-03-06 1005 继续(3n+1)猜想 (25分)
2020-03-06 1025 PAT Ranking (25分)