CS149笔记01现代多核CPU
A Modern Multi-Core Processor
一个处理器在做什么?
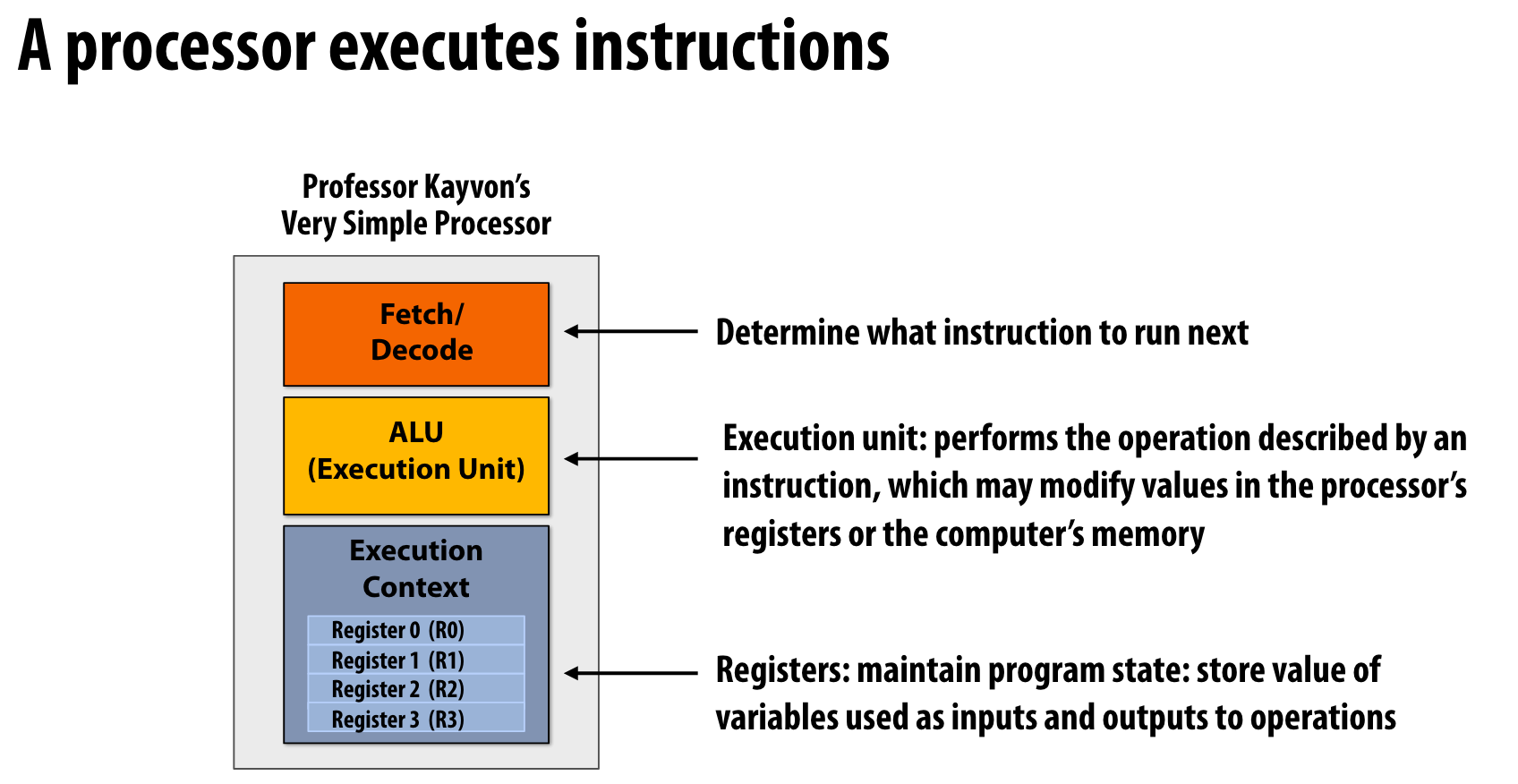
- Fetch Decode:指令流解码,决定下一条执行的指令
- ALU:执行单元,执行一条指令,决定如何修改寄存器和计算机内存
- Context 一组寄存器,保存了进程的状态。
这部分有点像科普性质了,有点像CPU的发展史。
原本的CPU,一个时钟周期拉取一个指令执行
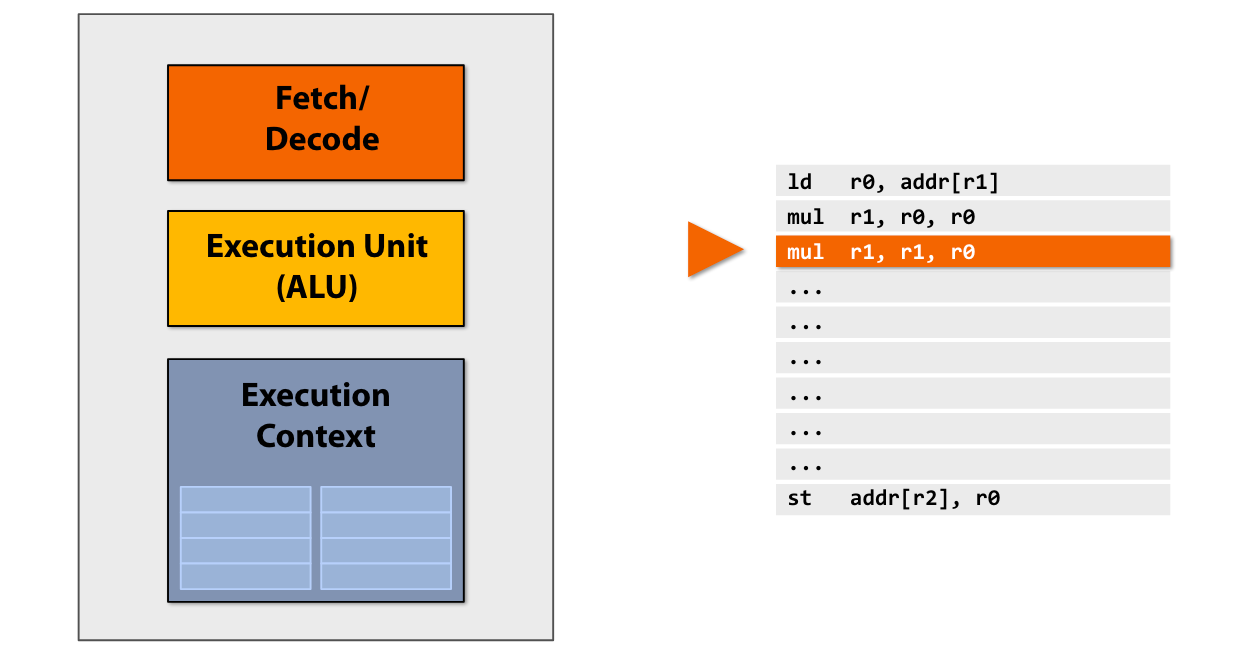
但是程序中很多指令之间是无关的,所以cpu在内部多做了一个执行单元,这样我们可以在一个时钟周期执行两个命令。
Superscalar execution: processor automatically independent instructions in an instruction sequence and can execute them in parallel on multiple execution units.
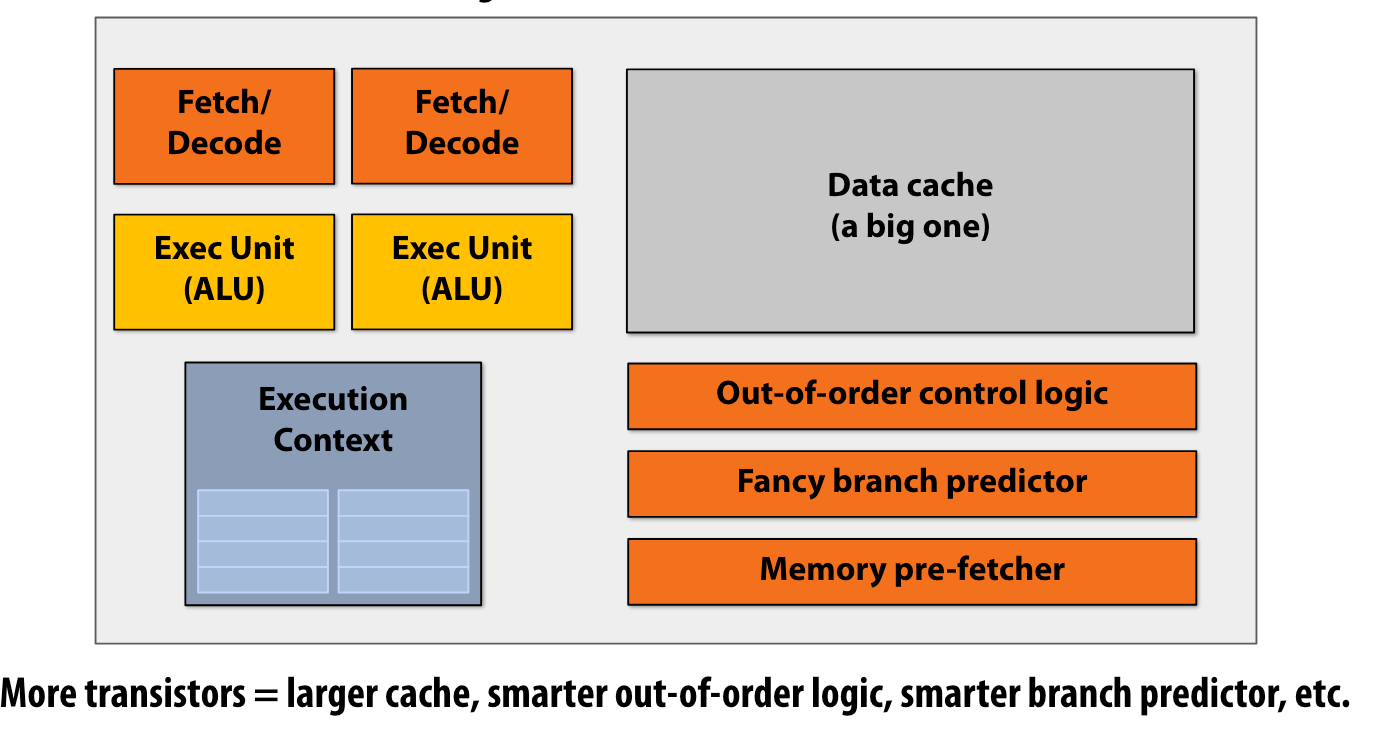
Processor pre multi-core era: Increase in chip transistors were used to help a single instruction stream run fast.(增加每个核的transistor数量,从而使得指令流执行更加迅速)
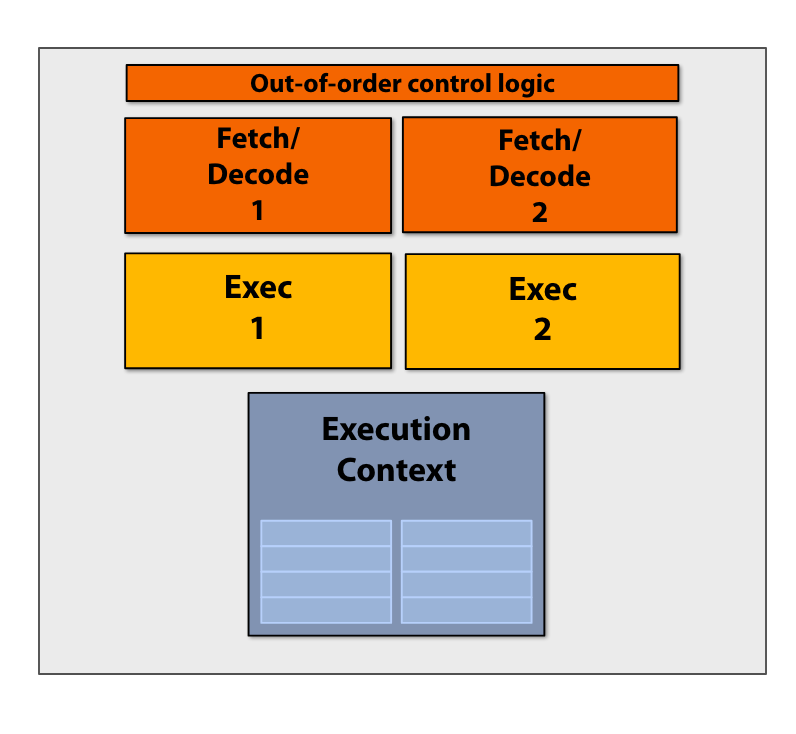
Idea #1
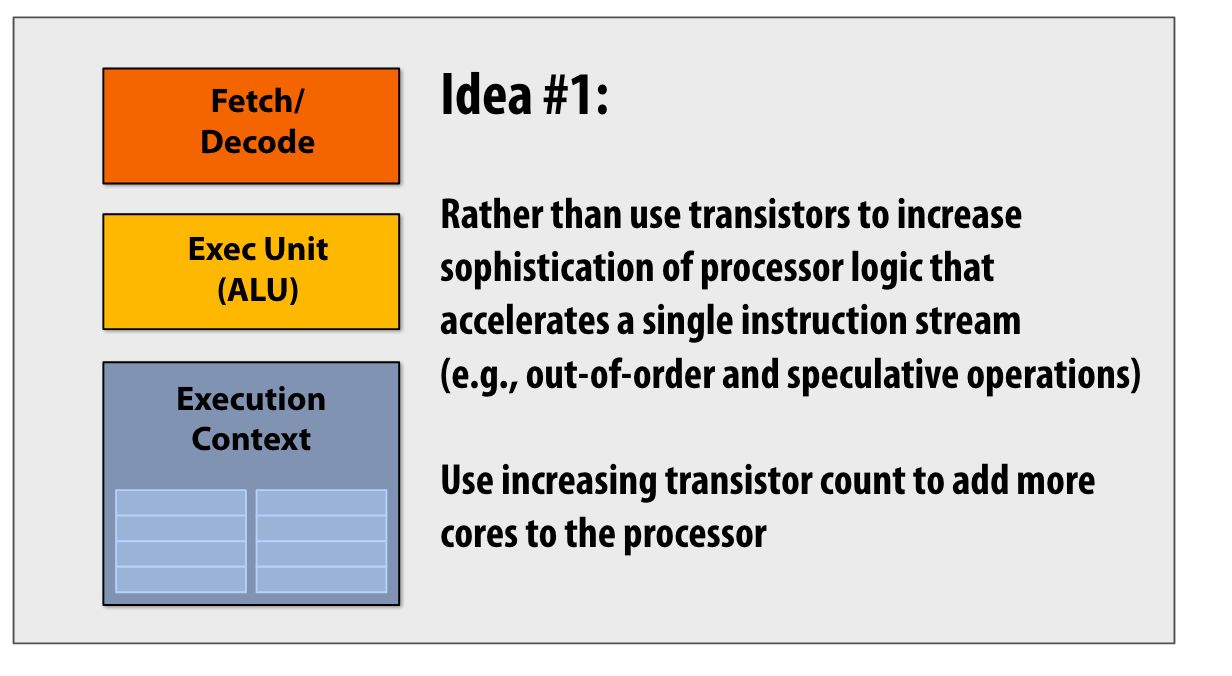
不增加每个核的transistor的数量,而是增加处理器的核数
多核并行的模式:
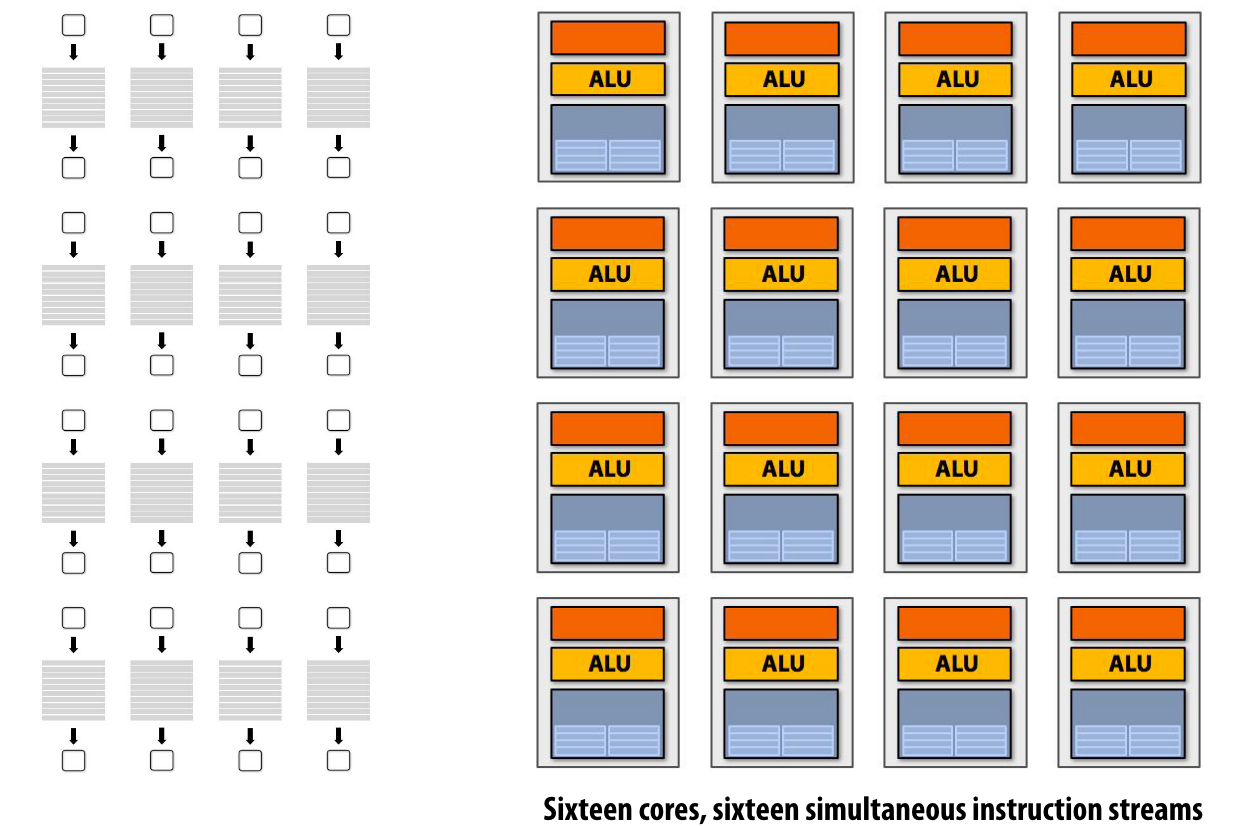
如果有16个核,就有16个同时执行的指令流
Idea #2
fetch/Decode的成本要比ALU贵,因此可以一个核塞多个ALU,从而分摊managing 指令流的成本
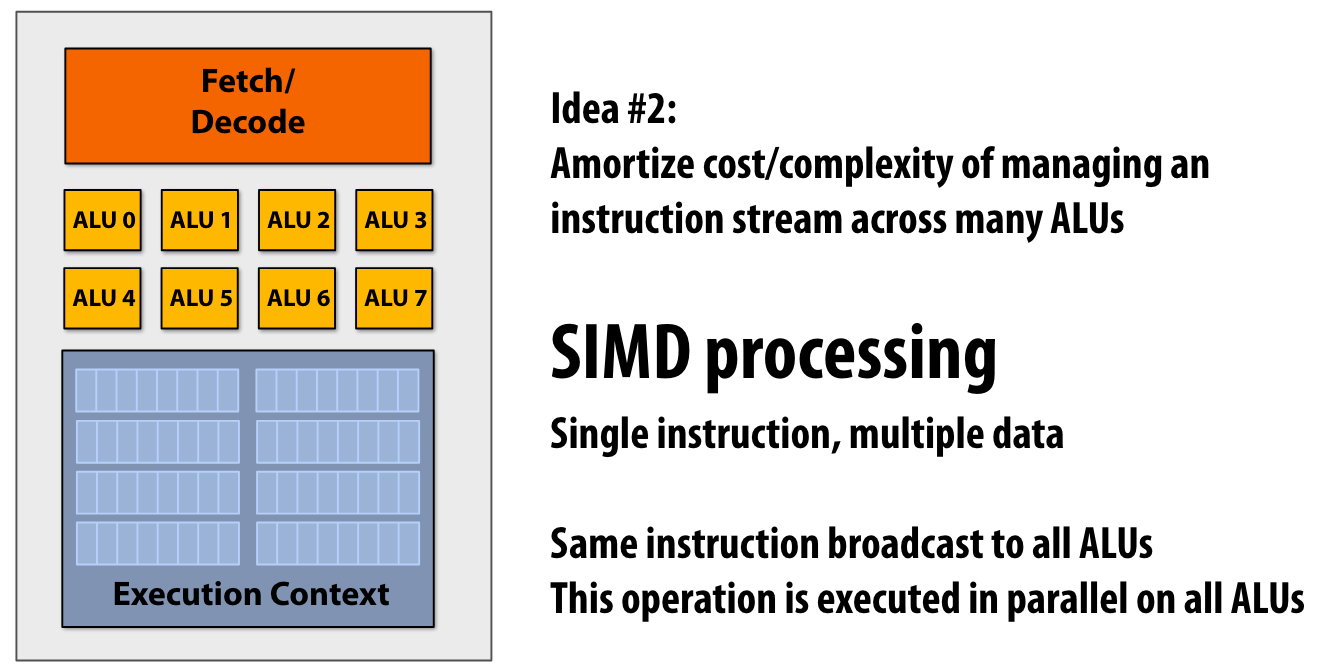
SIMD single multiple data,simd里面wide指8bits、1Byte
condition
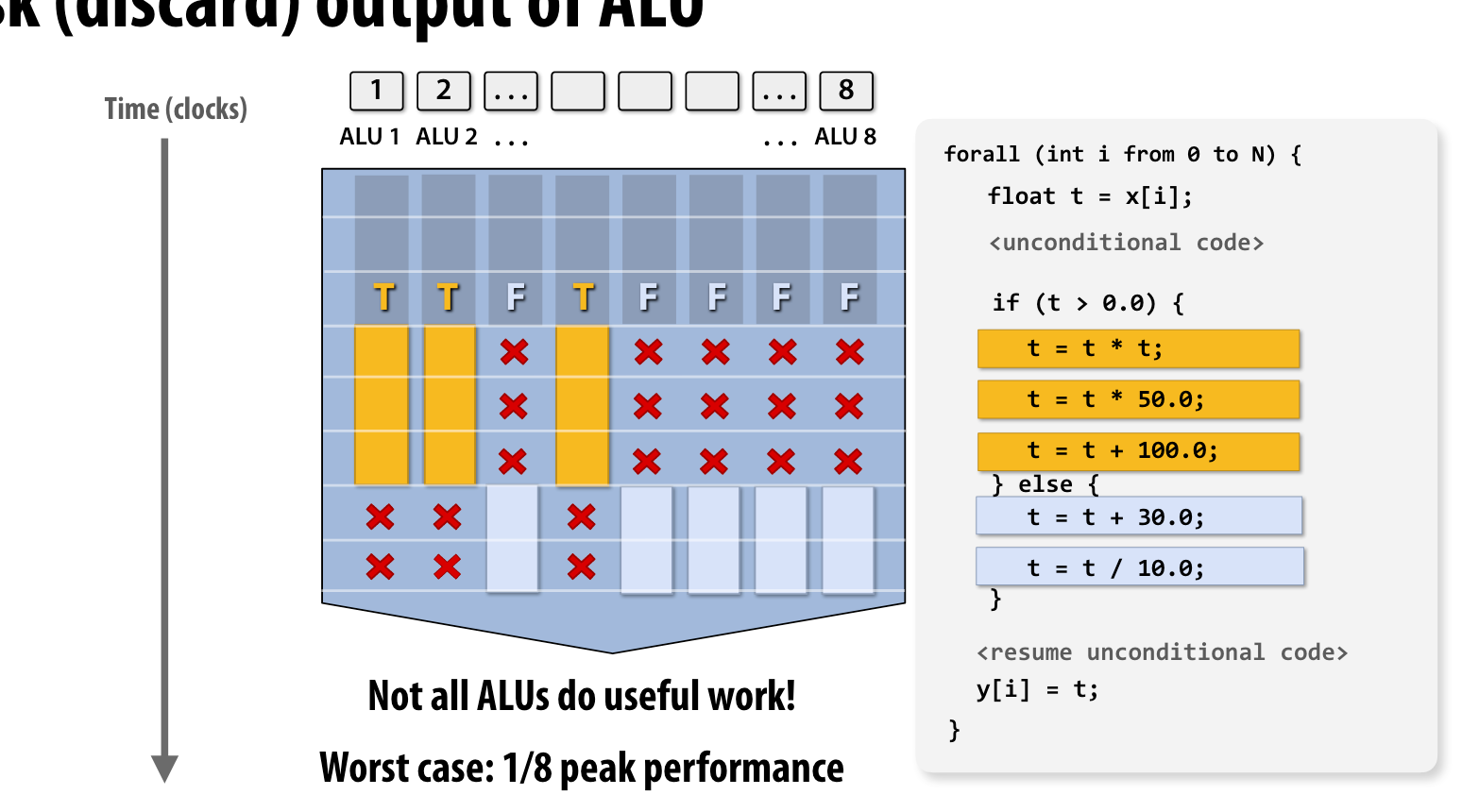
如果出现了if condition之类的情况,可能最糟糕的情况只会获得1/8的peak performance
explicit simd CPU
在编译阶段,编译器将simd指令编译在二进制文件中
- 程序code中写明simd指令
- 使用一些声明simd的semantic,(ispc的forall等
- 一些auto-vectorizing的编译器
implicit simd GPU
编译器只能生成标量处理程序,但是硬件可以在simd alus上执行,也就是硬件层面决定
访问内存
stalls
如果当前指令流的当前指令没有完成,处理器就不能继续执行当前指令流的下一条指令,这就是stalls

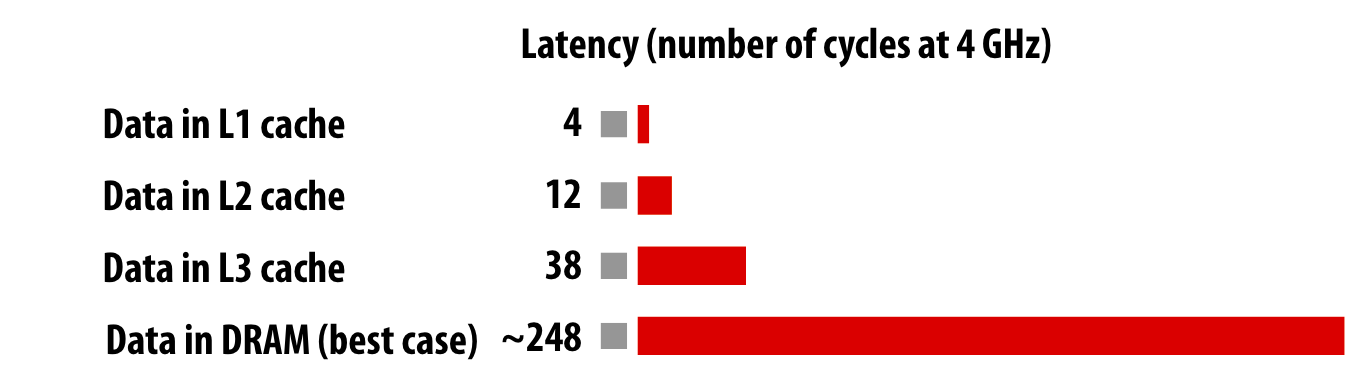
访问内存的延迟,通常为100左右cpu时钟周期
Cache
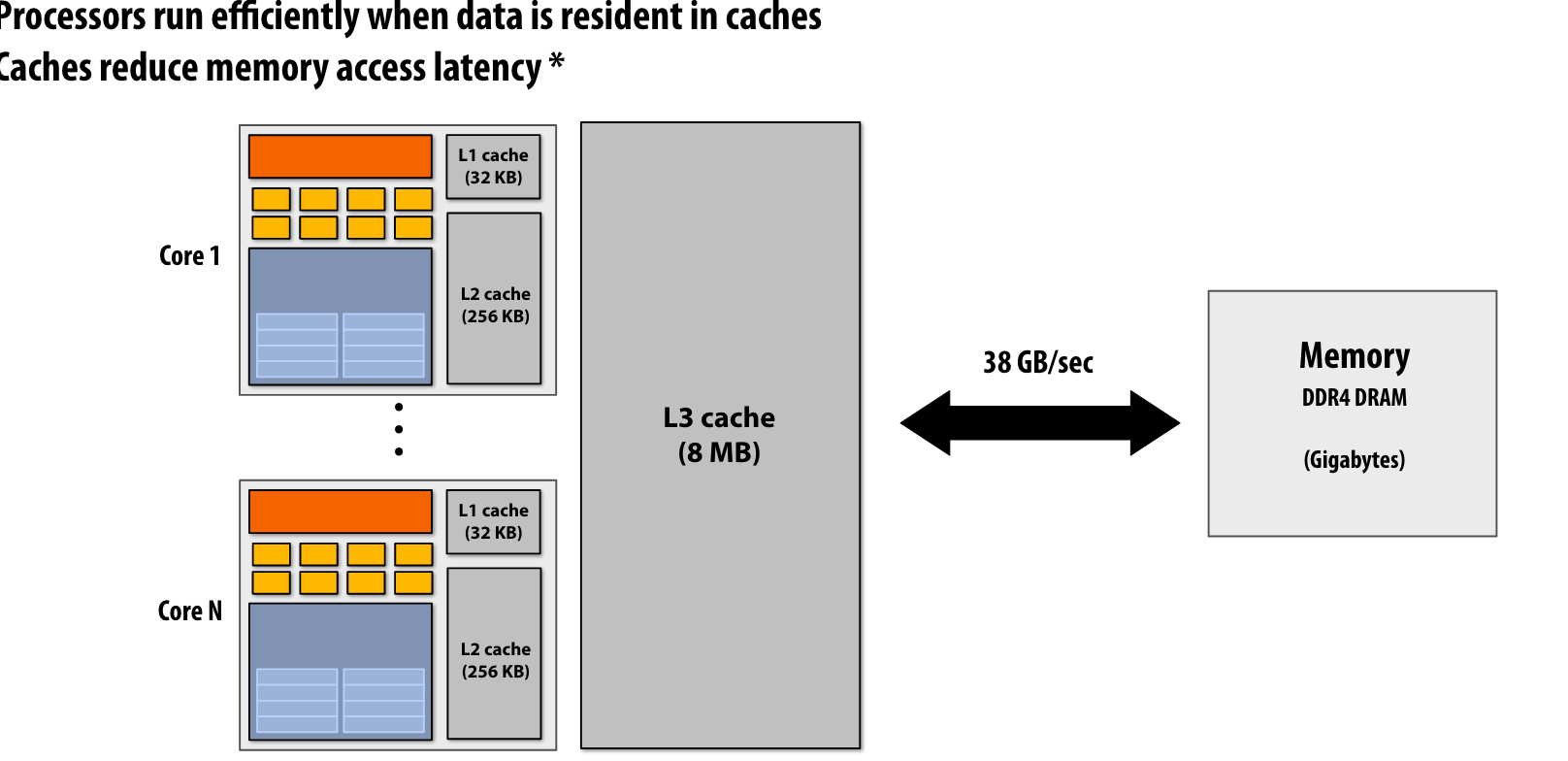
Cache可以提供更低的延迟和更高的数据带宽
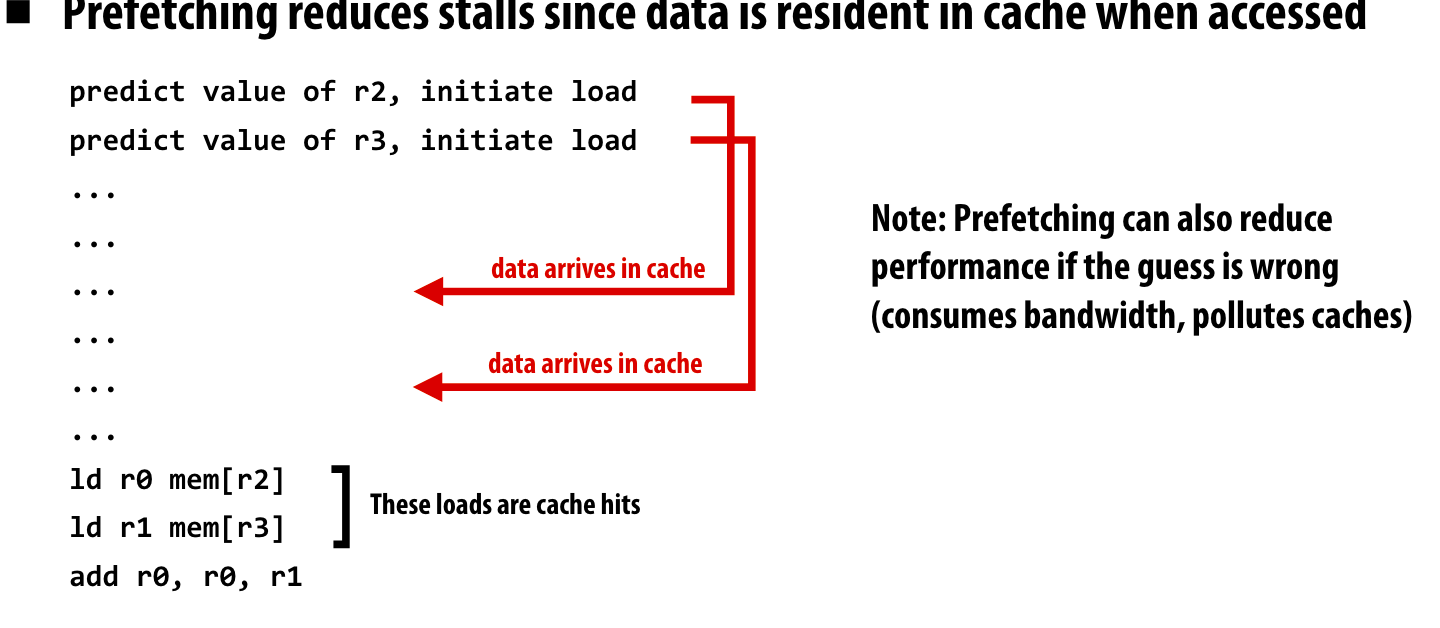
prefetch
在执行程序之前,先预先将数据提前fetch到Cache中,如果fetch错了,这可能降低执行效率
Idea #3
通过多线程来掩盖stalls,注意,这里的多线程是一个核上多个context意义上的多线程
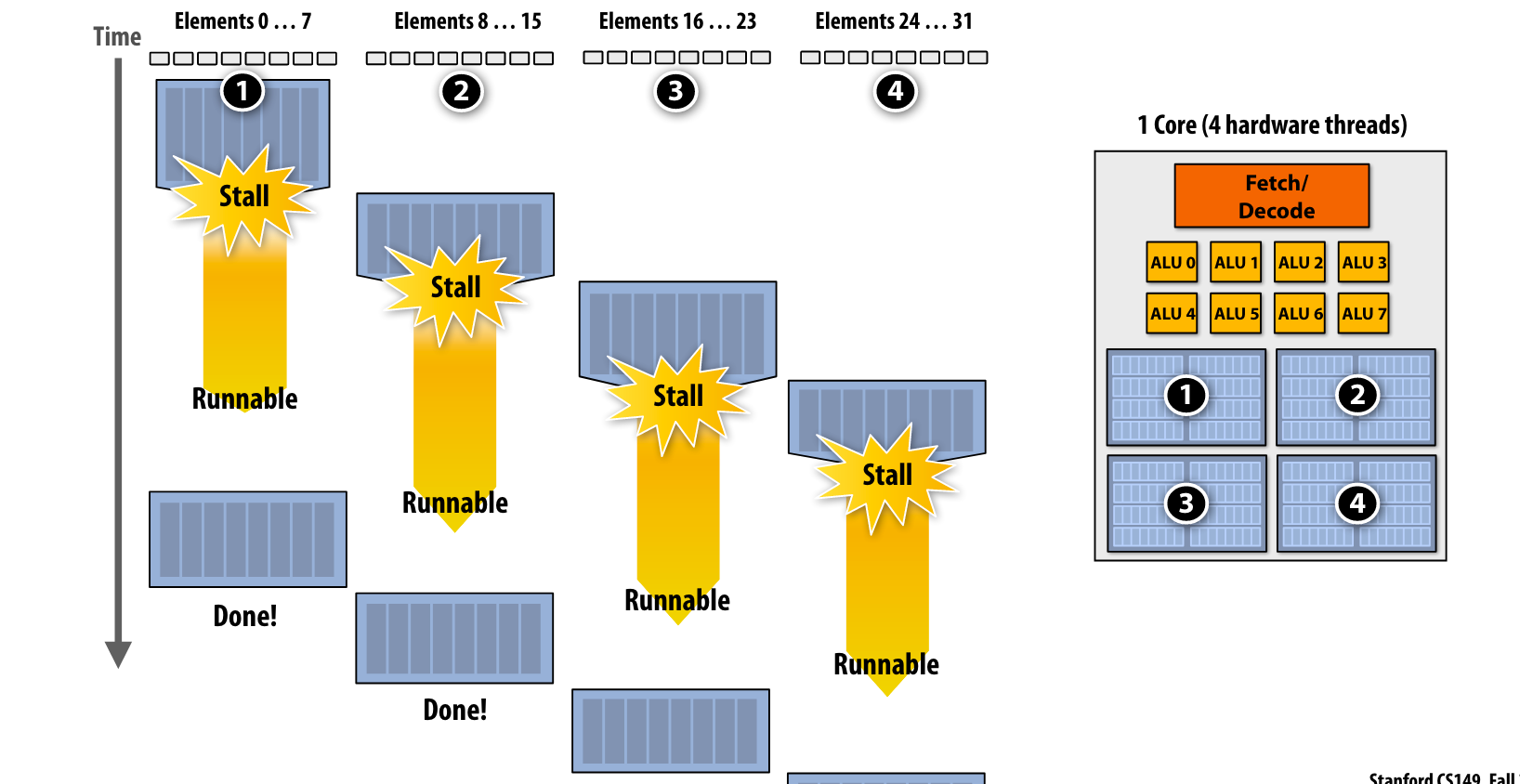

多线程是面向吞吐量的系统的选择,虽然一个线程的执行时间可能变长,但是系统总的吞吐量提高了
延迟和带宽
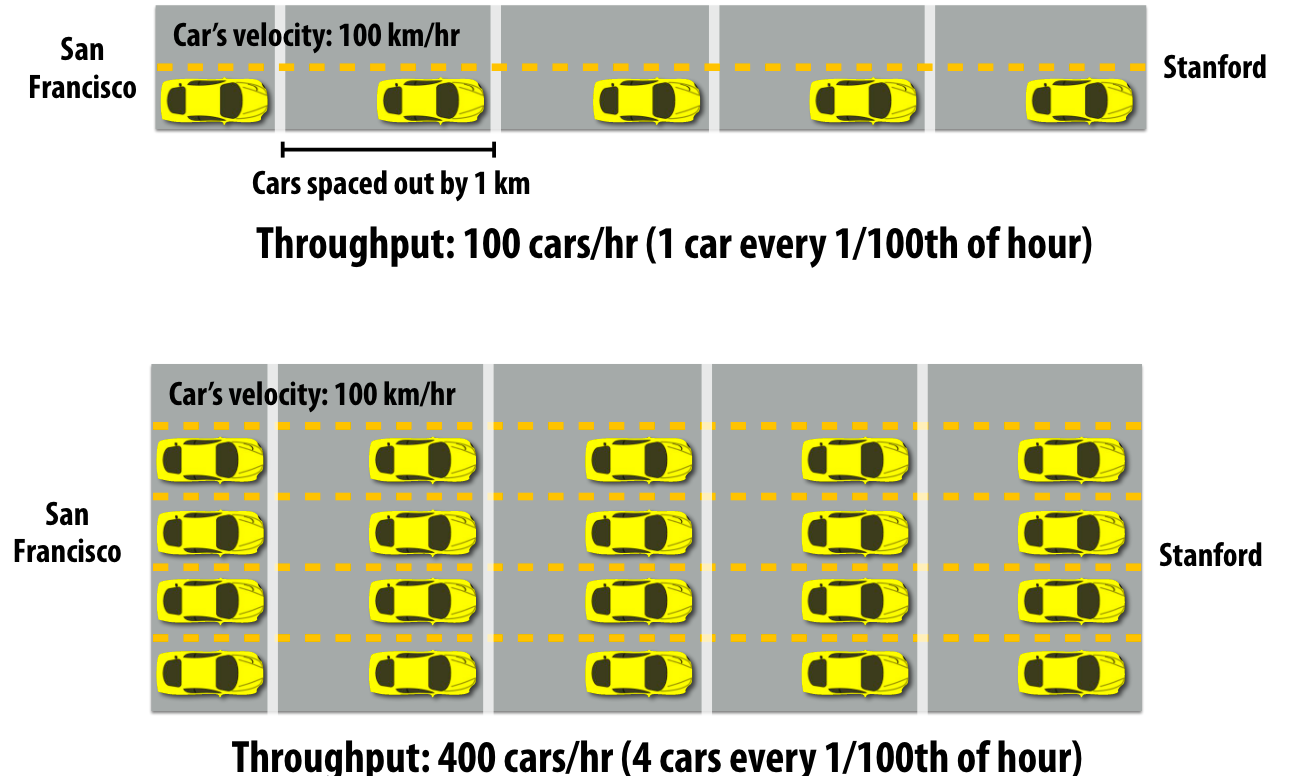
延迟:一辆车从san 到Stanford路上画的时间
带宽:一个小时内(或者其他时间单位),能有多少车辆从san到Stanford。
延迟高带宽不一定低,同样延迟低不一定带宽高。如果是内存带宽,就是能够同时从内存传输多少数据的能力,而延迟则是从内存传输数据到处理器的时间。
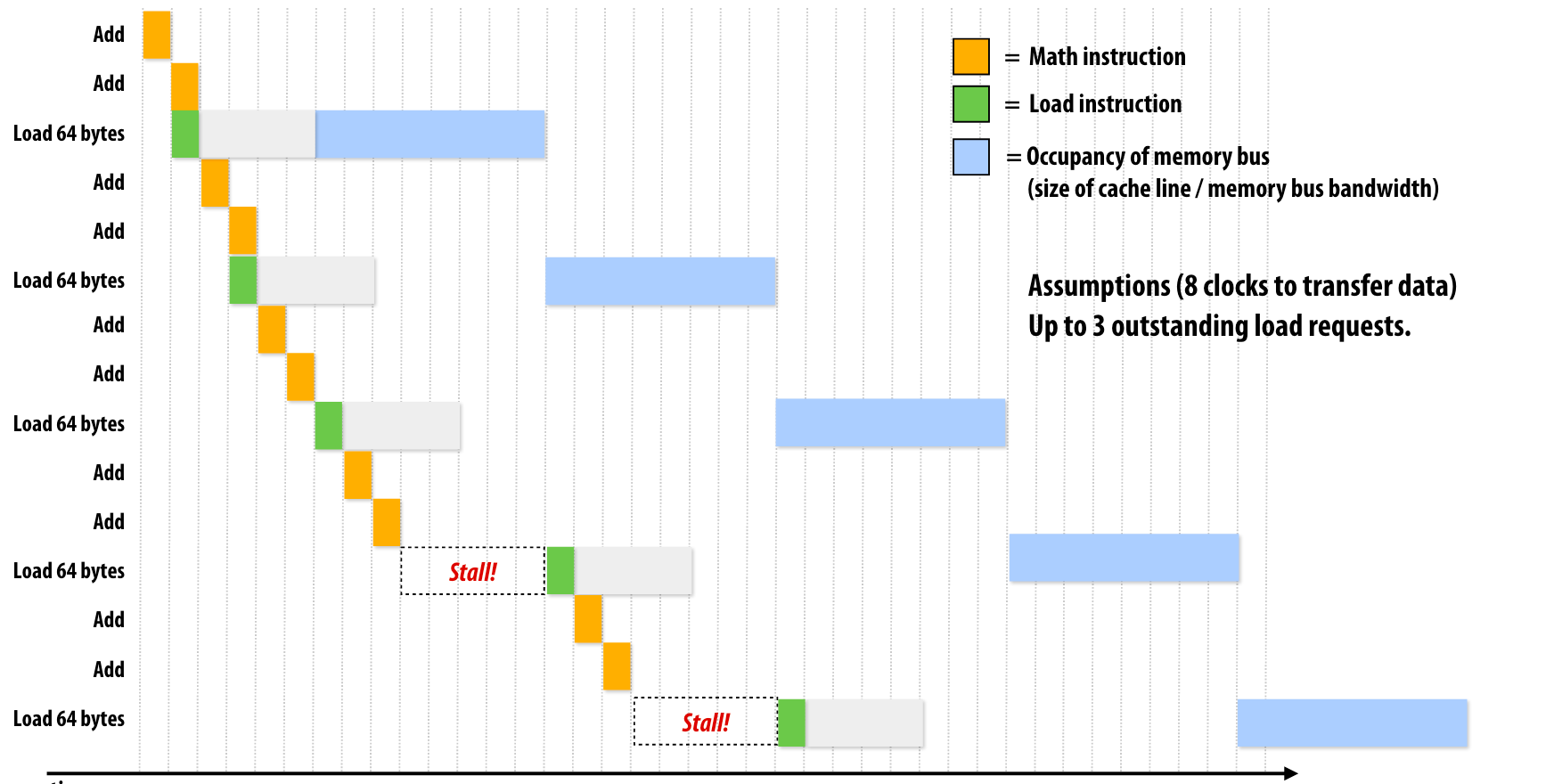
如果内存带宽很低就会出现这种情况,内存的总线被占用,其他load操作只能等待,但是如果内存带宽提高,那么相当于内存总线还能同时传输更多数据,这时候就可以允许多个load操作同时执行。
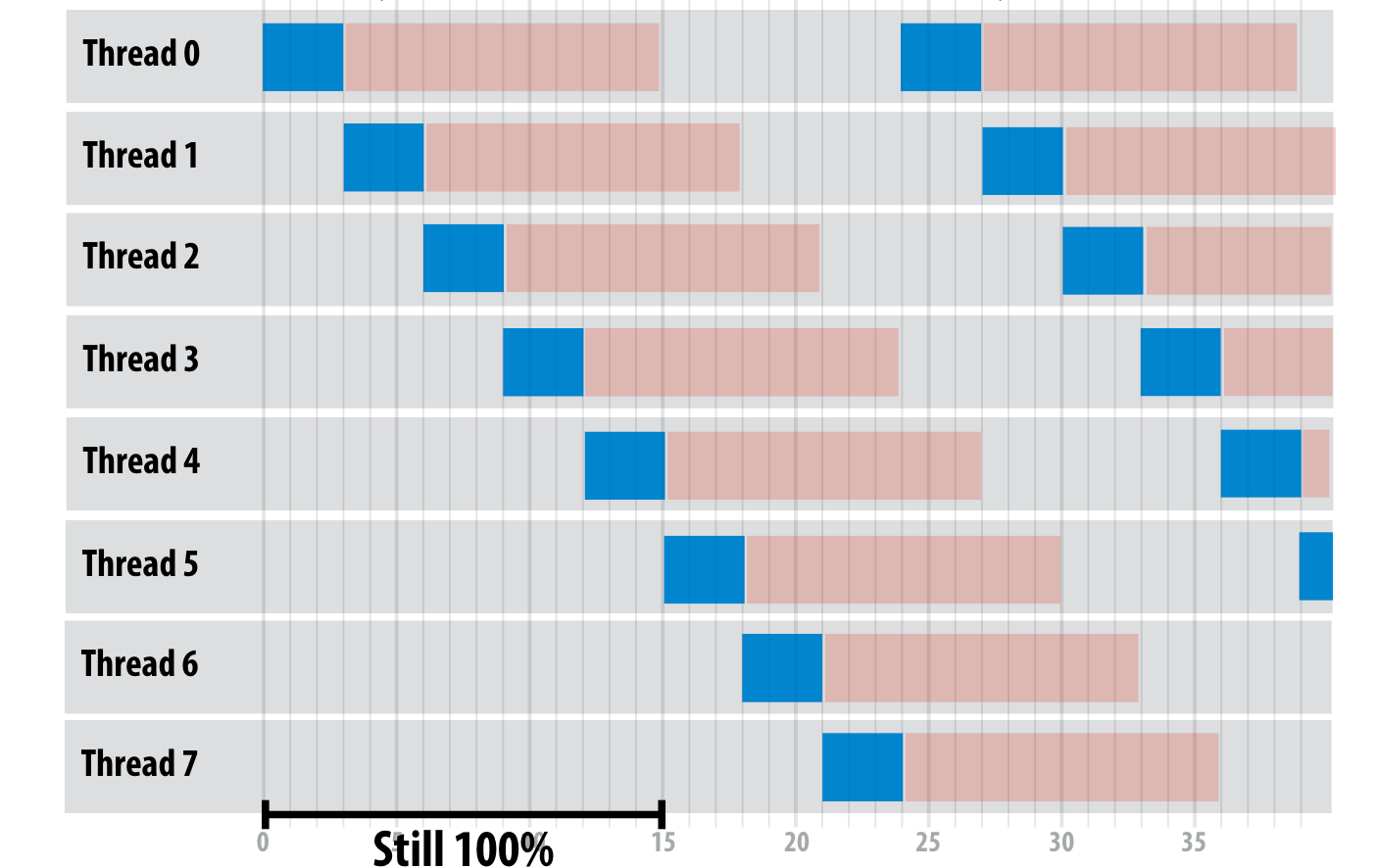
我们就可以达到这样的理想100%利用率:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通