Seq2seq 算法
编码器解码器架构
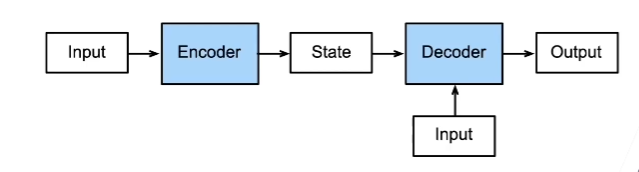
编码器-解码器架构就是构造一个编码器,通过编码器来获得解码器的初始state。这个在架构在很多情况下都可以使用,比如在Seq2Seq算法里。比如在机器翻译领域,通过编码器把要翻译的句子编码为一个初始状态,然后用解码器对这个状态进行解码,解码得到需要的翻译句子。
class EncodeDecode(nn.Module):
def __init__(self, Encode, Decode):
super(EncodeDecode, self).__init__()
self.encoder = Encode
self.decoder = Decode
def forward(self, EncodeX, DecodeX, *args):
enco_outputs = self.encoder(EncodeX)
deco_state = self.decoder.init_state(enco_outputs, *args)
return self.decoder(DecodeX, deco_state)
编码器-解码器架构说白了就是两段RNN + Linear
我主要跟着做了Seq2seq 算法的实现。
编码器
class Encode(nn.Module):
def __init__(self, vocab_size, embedding_size, hidim, num_layer, dropout=0) -> None:
super(Encode, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.GRU = nn.GRU(embedding_size, hidim, num_layer, dropout=dropout)
def forward(self, X, *args):
'''X 的shape应该是(batchsize,时间步)'''
embedding = self.embedding(X) # 会多出一个维度(时间步, batchsize, embedding_size)
X = embedding.permute(1, 0, 2) #交换维度
h, state = self.GRU(X) # 不考虑传入初始state
return h, state
这里需要注意的embedding,现在都2021年了不要再玩word2vec那一套的,用torch自带的embedding不好吗?
解码器
class Decode(nn.Module):
def __init__(self, vocab_size, embedding_size, hidim, num_layer, dropout) -> None:
super(Decode, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.GRU = nn.GRU(embedding_size+hidim, hidim, num_layer, dropout=dropout)
self.Linear = nn.Linear(hidim, vocab_size)
def init_state(self, enco_ouputs, *args):
return enco_ouputs[1] # 这就是encode输出的state,不过是因为enco_outputs 是一个元组
def forward(self, X, state):
'''X shape (batchsize, step)'''
X = self.embedding(X).permute(1, 0, 2)
context = state[-1].repeat(X.shape[0], 1, 1)
X_context = torch.cat((X, context), 2)
output, state = self.GRU(X_context, state)
output = self.Linear(output)
return output.permute(1, 0, 2), state
解码器使用编码器输出的state作为初始的state,但是这里还做了一个操作,那就是把编码器输出的state的最后一层的那个state(鬼知道我在说什么,因为解码器是两层GRU架构,输出的state的shape是(2, batchsize, hidim) ) 就是只用最后一层的state,然后把它拼接到解码器输入的X的每一个词上,所以这就是self.GRU = nn.GRU(embedding_size+hidim, hidim, num_layer, dropout=dropout) 中embedding_size+hidim 的原因。
掩码交叉熵
掩码函数
def sequence_mask(X, valid_len,value=0):
'''using to get mask crossentropyLoss'''
'''x tensor shape (batchsize, step, vocab_size)'''
max_len = X.size(1)
mask = torch.arange(max_len, device=X.device).reshape(1, -1) < valid_len.reshape(-1, 1)
X[~mask] = value
return X
这里的mask用到了广播机制,因为mask是二维的,所以它作用于X的前两个维度。
掩码交叉熵
class Mask_CrossEntropyLoss(nn.CrossEntropyLoss):
def forward(self, pred, labels, valid_len):
'''X shape (batchsize, step, vocabsize)'''
self.reduction = 'none'
unweighted_loss = super(Mask_CrossEntropyLoss, self).forward(pred.permute(0, 2, 1), labels) #(batchsize, step)
weights = torch.ones_like(labels)
weights = sequence_mask(weights, valid_len)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss # (batchsize)
这里的 unweighted_loss 的shape是 (batchsize, steps),然后把后面pading给用掩码变为0.
训练
def train_seq2seq(net, data_iter, num_epochs, lr, num_layer, tgt_vocab, device):
net.to(device)
loss = Mask_CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
net.train()
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) #损失和预测的总共词数
for batch in data_iter:
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0], device=device).reshape(-1, 1)
dec_input = torch.concat((bos, Y[:, :-1]), dim=1) # 这里取了Y[:, :-1]是为了保证长度一致。
y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(y_hat, Y, Y_valid_len)
optimizer.zero_grad()
l.sum().backward()
nn.utils.clip_grad.clip_grad_norm_(net.parameters(), 1)
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), sum(Y_valid_len))
if (epoch + 1)% 50 == 0 or epoch == 0:
print("epoch {}: loss {}".format(epoch + 1, metric[0]/metric[1]))
print("loss {}, {} tokens/sec".format(metric[0]/metric[1], metric[1]/timer.stop()))
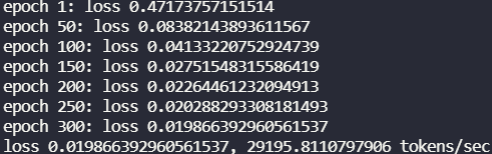
基本逻辑就是用encode输出state,然后用decode进行预测,在计算交叉熵。训练是时候Decoder是有句子的,也就是label。但是真的进行翻译的时候,decoder是没有句子的,只有起始词<bos>。训练结果:
预测
预测部分,把我整晕了,真的莫名奇妙出现bug。。。直接用书本代码:
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""序列到序列模型的预测"""
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = np.array([len(src_tokens)], ctx=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# 添加批量轴
enc_X = np.expand_dims(np.array(src_tokens, ctx=device), axis=0)
enc_outputs = net.encoder(enc_X, enc_valid_len)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# 添加批量轴
dec_X = np.expand_dims(np.array([tgt_vocab['<bos>']], ctx=device), axis=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(axis=2)
pred = dec_X.squeeze(axis=0).astype('int32').item()
# 保存注意力权重(稍后讨论)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
翻译准确度用BLEU分数来衡量:
def bleu(pred_seq, label_seq, k): #@save
"""计算 BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[''.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[''.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[''.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
翻译:
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device)
print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')
最后真的搞,我直接人晕了。。。
下次有机会再好好看看seq2seq 吧,不过还是那句话,2021年谁还用seq2seq啊。。。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 智能桌面机器人:用.NET IoT库控制舵机并多方法播放表情
· Linux glibc自带哈希表的用例及性能测试
· 深入理解 Mybatis 分库分表执行原理
· 如何打造一个高并发系统?
· .NET Core GC压缩(compact_phase)底层原理浅谈
· 手把手教你在本地部署DeepSeek R1,搭建web-ui ,建议收藏!
· 新年开篇:在本地部署DeepSeek大模型实现联网增强的AI应用
· Janus Pro:DeepSeek 开源革新,多模态 AI 的未来
· 互联网不景气了那就玩玩嵌入式吧,用纯.NET开发并制作一个智能桌面机器人(三):用.NET IoT库
· 【非技术】说说2024年我都干了些啥