


Java知识点整理(一)
ArrayList和LinkedList的区别
1、ArrayList和LinkedList可想从名字分析,它们一个是Array(动态数组)的数据结构,一个是Link(链表)的数据结构,此外,它们两个都是对List接口的实现。
前者是数组队列,相当于动态数组;后者为双向链表结构,也可当作堆栈、队列、双端队列。
2、当随机访问List时(get和set操作),ArrayList比LinkedList的效率更高,因为LinkedList是线性的数据存储方式,所以需要移动指针从前往后依次查找。
3、当对数据进行增加和删除的操作时(add和remove操作),LinkedList比ArrayList的效率更高,因为ArrayList是数组,所以在其中进行增删操作时,会对操作点之后所有数据的下标索引造成影响,需要进行数据的移动。
4、从利用效率来看,ArrayList自由性较低,因为它需要手动的设置固定大小的容量,但是它的使用比较方便,只需要创建,然后添加数据,通过调用下标进行使用;而LinkedList自由性较高,能够动态的随数据量的变化而变化,但是它不便于使用。
5、ArrayList主要控件开销在于需要在lList列表预留一定空间;而LinkList主要控件开销在于需要存储结点信息以及结点指针信息。
ArrayList越界问题
ArrayList内部add()的实现过程分两步操作,step1检查array容量,step2塞值并将size++
数组下标越界,index会和ArrayList的私有变量size做比较,那问题就是size到底是多少?添加元素成功后会执行size++,删除元素成功会执行size--。也就是说size是元素个数,并不是数组的长度。
private void rangeCheckForAdd(int index) {
if (index < 0 || index > this.size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
假设有2个线程操作同一个ArrayList,且array的容量刚好还可以存一个值。Thread1执行add()的step1完成,step2还没开始时被挂起,这时Thread1“认为”array还有位置可以塞值,然后安心地睡去了;Thread2执行add(),存入一个元素并将size++,而+1后的size已经大于array当前容量了。然后Thread1醒过来往下执行,因为它睡前已经检查过array容量了,所以就直接执行step2,直接把值存在下标为size的地方,所以就越界了。
ArrayList和HashSet的区别
Set 集合是无序不可以重复的的、List 集合是有序可以重复的
Volatile 和 Synchronize 区别
线程安全性包括两个方面,①可见性。②原子性。
volatile关键字的作用:
-
使变量在多个线程间可见(可见性),不能保证线程的安全性
-
volatile 修饰的变量会禁止指令重排序(有序性)
-
volatile轻量级,只能修饰变量。synchronized重量级,还可修饰方法
-
volatile只能保证数据的可见性,不能用来同步,因为多个线程并发访问volatile修饰的变量不会阻塞。
-
synchronized不仅保证可见性,而且还保证原子性,因为,只有获得了锁的线程才能进入临界区,从而保证临界区中的所有语句都全部执行。多个线程争抢synchronized锁对象时,会出现阻塞。
多态原理
方法表是实现动态调用的核心。方法表存放在方法区中的类型信息中。为了优化对象调用方法的速度,方法区的类型信息会增加一个指针,该指针指向一个记录该类方法的方法表,方法表中的每一个项都是对应方法的指针。
invokevitual
- 查看基类的方法表,得到调用方法方法在该方法表的偏移量(假设为15),这样就得到该方法的直接引用。
- 根据this指针得到具体的子类对象,根据对象得到该对象对应的方法表,根据偏移量15查看有无重写(override)该方法,如果重写,则可以直接调用;如果没有重写,则需要拿到按照继承关系从下往上的基类的方法表,同样按照这个偏移量15查看有无该方法。
invokeinterface
因为 Java 类是可以同时实现多个接口的,而当用接口引用调用某个方法的时候,情况就有所不同了。Java 对于接口方法的调用是采用搜索方法表的方式。
-
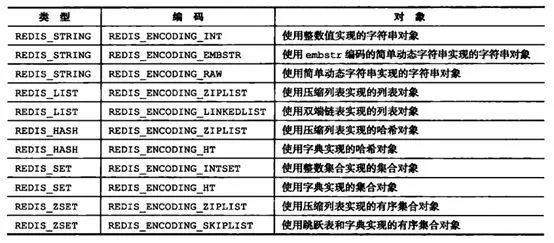
列表
列表的内部编码可以是压缩列表(ziplist)或双端链表(linkedlist)。
双端链表:由一个list结构和多个listNode结构组成;典型结构如下图所示:
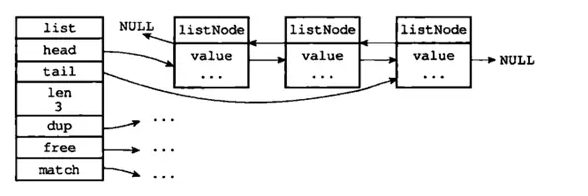
通过图中可以看出,双端链表同时保存了表头指针和表尾指针,并且每个节点都有指向前和指向后的指针;链表中保存了列表的长度;dup、free和match为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。而链表中每个节点指向的是type为字符串的redisObject。
压缩列表:压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块(而不是像双端链表一样每个节点是指针)组成的顺序型数据结构;具体结构相对比较复杂,略。与双端链表相比,压缩列表可以节省内存空间,但是进行修改或增删操作时,复杂度较高;因此当节点数量较少时,可以使用压缩列表;但是节点数量多时,还是使用双端链表划算。
压缩列表不仅用于实现列表,也用于实现哈希、有序列表;使用非常广泛。只有同时满足下面两个条件时,才会使用压缩列表:
- 列表中元素数量小于512个
- 列表中所有字符串对象都不足64字节。
如果有一个条件不满足,则使用双端列表;且编码只可能由压缩列表转化为双端链表,反方向则不可能。
-
有序集合
有序集合与集合一样,元素都不能重复;但与集合不同的是,有序集合中的元素是有顺序的。与列表使用索引下标作为排序依据不同,有序集合为每个元素设置一个分数(score)作为排序依据。
有序集合的内部编码可以是压缩列表(ziplist)或跳跃表(skiplist)。
跳跃表是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。除了跳跃表,实现有序数据结构的另一种典型实现是平衡树;大多数情况下,跳跃表的效率可以和平衡树媲美,且跳跃表实现比平衡树简单很多,因此redis中选用跳跃表代替平衡树。跳跃表支持平均O(logN)、最坏O(N)的复杂点进行节点查找,并支持顺序操作。Redis的跳跃表实现由zskiplist和zskiplistNode两个结构组成:前者用于保存跳跃表信息(如头结点、尾节点、长度等),后者用于表示跳跃表节点。具体结构相对比较复杂,略。
只有同时满足下面两个条件时,才会使用压缩列表:
- 有序集合中元素数量小于128个;
- 有序集合中所有成员长度都不足64字节。
如果有一个条件不满足,则使用跳跃表;且编码只可能由压缩列表转化为跳跃表,反方向则不可能。
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
多线程单例
- Double Check Locking
- 枚举实现单例
锁池和等待池
- 锁池:假设线程A已经拥有了某个对象(注意:不是类)的锁,而其它的线程想要调用这个对象的某个synchronized方法(或者synchronized块),由于这些线程在进入对象的synchronized方法之前必须先获得该对象的锁的拥有权,但是该对象的锁目前正被线程A拥有,所以这些线程就进入了该对象的锁池中。
- 等待池:假设一个线程A调用了某个对象的wait()方法,线程A就会释放该对象的锁后,进入到了该对象的等待池中
notify和notifyAll的区别
- 如果线程调用了对象的 wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。
- 当有线程调用了对象的 notifyAll()方法(唤醒所有 wait 线程)或 notify()方法(只随机唤醒一个 wait 线程),被唤醒的的线程便会进入该对象的锁池中,锁池中的线程会去竞争该对象锁。也就是说,调用了notify后只要一个线程会由等待池进入锁池,而notifyAll会将该对象等待池内的所有线程移动到锁池中,等待锁竞争
- 优先级高的线程竞争到对象锁的概率大,假若某线程没有竞争到该对象锁,它还会留在锁池中,唯有线程再次调用 wait()方法,它才会重新回到等待池中。而竞争到对象锁的线程则继续往下执行,直到执行完了 synchronized 代码块,它会释放掉该对象锁,这时锁池中的线程会继续竞争该对象锁。
乐观锁悲观锁应用场景
悲观锁:比较适合写入操作比较频繁的场景,如果出现大量的读取操作,每次读取的时候都会进行加锁,这样会增加大量的锁的开销,降低了系统的吞吐量。
乐观锁:比较适合读取操作比较频繁的场景,如果出现大量的写入操作,数据发生冲突的可能性就会增大,为了保证数据的一致性,应用层需要不断的重新获取数据,这样会增加大量的查询操作,降低了系统的吞吐量。
总结:两种所各有优缺点,读取频繁使用乐观锁,写入频繁使用悲观锁。
排序算法复杂度
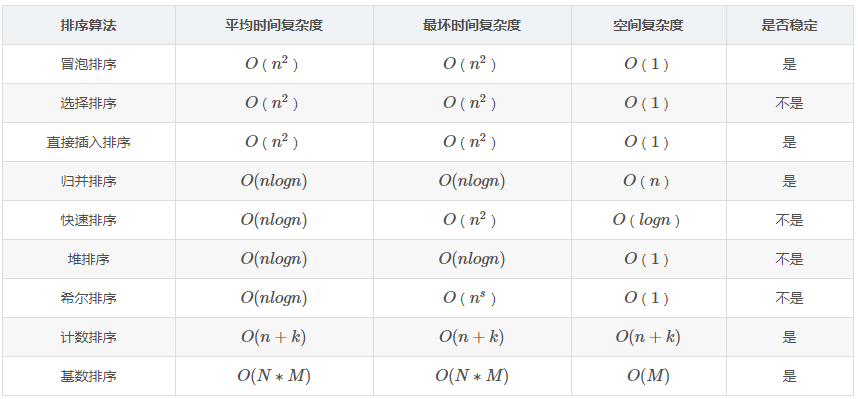
注:
- 归并排序可以通过手摇算法将空间复杂度降到O(1),但是时间复杂度会提高。
- 基数排序时间复杂度为O(N*M),其中N为数据个数,M为数据位数。
辅助记忆
- 时间复杂度记忆
冒泡、选择、直接插入排序需要两个for循环,每次只关注一个元素,平均时间复杂度为O(n2)(一遍找元素O(n)O(n),一遍找位置O(n)O(n))
快速、归并、希尔、堆基于二分思想,log以2为底,平均时间复杂度为O(nlogn)(一遍找元素O(n),一遍找位置O(logn))
- 稳定性记忆-“快希选堆”(快牺牲稳定性)
排序算法的稳定性:排序前后相同元素的相对位置不变,则称排序算法是稳定的;否则排序算法是不稳定的。

