


jstack分析线程死锁
一、介绍
jstack是java虚拟机自带的一种堆栈跟踪工具。jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息,如果是在64位机器上,需要指定选项"-J-d64",Windows的jstack使用方式只支持以下的这种方式:
jstack [-l] pid
主要分为两个功能:
a. 针对活着的进程做本地的或远程的线程dump;
b. 针对core文件做线程dump。
jstack用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。 线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。 如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序的java stack和native stack的信息, 如果现在运行的java程序呈现hung的状态,jstack是非常有用的。
jstack命令主要用来查看Java线程的调用堆栈的,可以用来分析线程问题(如死锁)。
线程状态
想要通过jstack命令来分析线程的情况的话,首先要知道线程都有哪些状态,下面这些状态是我们使用jstack命令查看线程堆栈信息时可能会看到的线程的几种状态:
NEW,未启动的。不会出现在Dump中。
RUNNABLE,在虚拟机内执行的。运行中状态,可能里面还能看到locked字样,表明它获得了某把锁。
BLOCKED,受阻塞并等待监视器锁。被某个锁(synchronizers)給block住了。
WATING,无限期等待另一个线程执行特定操作。等待某个condition或monitor发生,一般停留在park(), wait(), sleep(),join() 等语句里。
TIMED_WATING,有时限的等待另一个线程的特定操作。和WAITING的区别是wait() 等语句加上了时间限制 wait(timeout)。
TERMINATED,已退出的。
Monitor
在多线程的 JAVA程序中,实现线程之间的同步,就要说说 Monitor。 Monitor是 Java中用以实现线程之间的互斥与协作的主要手段,它可以看成是对象或者 Class的锁。每一个对象都有,也仅有一个 monitor。下面这个图,描述了线程和 Monitor之间关系,以 及线程的状态转换图:
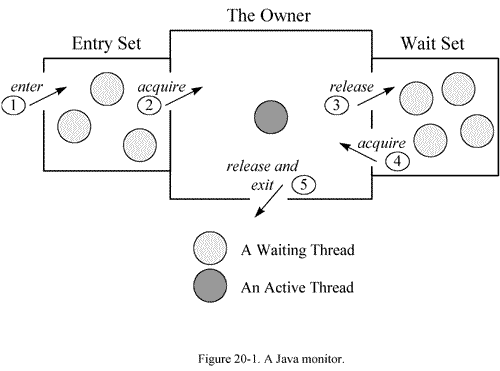
进入区(Entry Set):表示线程通过synchronized要求获取对象的锁。如果对象未被锁住,则迚入拥有者;否则则在进入区等待。一旦对象锁被其他线程释放,立即参与竞争。
拥有者(The Owner):表示某一线程成功竞争到对象锁。
等待区(Wait Set):表示线程通过对象的wait方法,释放对象的锁,并在等待区等待被唤醒。
从图中可以看出,一个 Monitor在某个时刻,只能被一个线程拥有,该线程就是 “Active Thread”,而其它线程都是 “Waiting Thread”,分别在两个队列 “ Entry Set”和 “Wait Set”里面等候。在 “Entry Set”中等待的线程状态是 “Waiting for monitor entry”,而在“Wait Set”中等待的线程状态是 “in Object.wait()”。 先看 “Entry Set”里面的线程。我们称被 synchronized保护起来的代码段为临界区。当一个线程申请进入临界区时,它就进入了 “Entry Set”队列。
调用修饰
表示线程在方法调用时,额外的重要的操作。线程Dump分析的重要信息。修饰上方的方法调用。
locked <地址> 目标:使用synchronized申请对象锁成功,监视器的拥有者。
waiting to lock <地址> 目标:使用synchronized申请对象锁未成功,在迚入区等待。
waiting on <地址> 目标:使用synchronized申请对象锁成功后,释放锁后在等待区等待。
parking to wait for <地址> 目标
locked
at oracle.jdbc.driver.PhysicalConnection.prepareStatement
- locked <0x00002aab63bf7f58> (a oracle.jdbc.driver.T4CConnection)
at oracle.jdbc.driver.PhysicalConnection.prepareStatement
- locked <0x00002aab63bf7f58> (a oracle.jdbc.driver.T4CConnection)
at com.jiuqi.dna.core.internal.db.datasource.PooledConnection.prepareStatement
通过synchronized关键字,成功获取到了对象的锁,成为监视器的拥有者,在临界区内操作。对象锁是可以线程重入的。
waiting to lock
at com.jiuqi.dna.core.impl.CacheHolder.isVisibleIn(CacheHolder.java:165)
- waiting to lock <0x0000000097ba9aa8> (a CacheHolder)
at com.jiuqi.dna.core.impl.CacheGroup$Index.findHolder
at com.jiuqi.dna.core.impl.ContextImpl.find
at com.jiuqi.dna.bap.basedata.common.util.BaseDataCenter.findInfo
通过synchronized关键字,没有获取到了对象的锁,线程在监视器的进入区等待。在调用栈顶出现,线程状态为Blocked。
waiting on
at java.lang.Object.wait(Native Method)
- waiting on <0x00000000da2defb0> (a WorkingThread)
at com.jiuqi.dna.core.impl.WorkingManager.getWorkToDo
- locked <0x00000000da2defb0> (a WorkingThread)
at com.jiuqi.dna.core.impl.WorkingThread.run
通过synchronized关键字,成功获取到了对象的锁后,调用了wait方法,进入对象的等待区等待。在调用栈顶出现,线程状态为WAITING或TIMED_WATING。
parking to wait for
park是基本的线程阻塞原语,不通过监视器在对象上阻塞。随concurrent包会出现的新的机制,synchronized体系不同。
线程动作
线程状态产生的原因
runnable:状态一般为RUNNABLE。
in Object.wait():等待区等待,状态为WAITING或TIMED_WAITING。
waiting for monitor entry:进入区等待,状态为BLOCKED。
waiting on condition:等待区等待、被park。
sleeping:休眠的线程,调用了Thread.sleep()。
Wait on condition 该状态出现在线程等待某个条件的发生。具体是什么原因,可以结合 stacktrace来分析。 最常见的情况就是线程处于sleep状态,等待被唤醒。 常见的情况还有等待网络IO:在java引入nio之前,对于每个网络连接,都有一个对应的线程来处理网络的读写操作,即使没有可读写的数据,线程仍然阻塞在读写操作上,这样有可能造成资源浪费,而且给操作系统的线程调度也带来压力。在 NewIO里采用了新的机制,编写的服务器程序的性能和可扩展性都得到提高。 正等待网络读写,这可能是一个网络瓶颈的征兆。因为网络阻塞导致线程无法执行。一种情况是网络非常忙,几 乎消耗了所有的带宽,仍然有大量数据等待网络读 写;另一种情况也可能是网络空闲,但由于路由等问题,导致包无法正常的到达。所以要结合系统的一些性能观察工具来综合分析,比如 netstat统计单位时间的发送包的数目,如果很明显超过了所在网络带宽的限制 ; 观察 cpu的利用率,如果系统态的 CPU时间,相对于用户态的 CPU时间比例较高;如果程序运行在 Solaris 10平台上,可以用 dtrace工具看系统调用的情况,如果观察到 read/write的系统调用的次数或者运行时间遥遥领先;这些都指向由于网络带宽所限导致的网络瓶颈。
二、命令格式
jstack [ option ] pid
jstack [ option ] executable core
jstack [ option ] [server-id@]remote-hostname-or-IP
常用参数说明
1)options:
executable Java executable from which the core dump was produced.(可能是产生core dump的java可执行程序)
core 将被打印信息的core dump文件
remote-hostname-or-IP 远程debug服务的主机名或ip
server-id 唯一id,假如一台主机上多个远程debug服务
2)基本参数:
-F当’jstack [-l] pid’没有相应的时候强制打印栈信息,如果直接jstack无响应时,用于强制jstack),一般情况不需要使用
-l长列表. 打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表,会使得JVM停顿得长久得多(可能会差很多倍,比如普通的jstack可能几毫秒和一次GC没区别,加了-l 就是近一秒的时间),-l 建议不要用。一般情况不需要使用
-m打印java和native c/c++框架的所有栈信息.可以打印JVM的堆栈,显示上Native的栈帧,一般应用排查不需要使用
-h | -help打印帮助信息
pid 需要被打印配置信息的java进程id,可以用jps查询.
线程dump的分析工具:
- IBM Thread and Monitor Dump Analyze for Java 一个小巧的Jar包,能方便的按状态,线程名称,线程停留的函数排序,快速浏览。
- http://spotify.github.io/threaddump-analyzer Spotify提供的Web版在线分析工具,可以将锁或条件相关联的线程聚合到一起。
其他
虚拟机执行Full GC时,会阻塞所有的用户线程。因此,即时获取到同步锁的线程也有可能被阻塞。 在查看线程Dump时,首先查看内存使用情况。
频繁GC问题或内存溢出问题
一、使用jps查看线程ID
二、使用jstat -gc 3331 250 20 查看gc情况,一般比较关注PERM区的情况,查看GC的增长情况。
三、使用jstat -gccause:额外输出上次GC原因
四、使用jmap -dump:format=b,file=heapDump 3331生成堆转储文件
五、使用jhat或者可视化工具(Eclipse Memory Analyzer 、IBM HeapAnalyzer)分析堆情况。
六、结合代码解决内存溢出或泄露问题。
死锁问题
一、使用jps查看线程ID
二、使用jstack 3331:查看线程情况
写个简单的死锁demo:

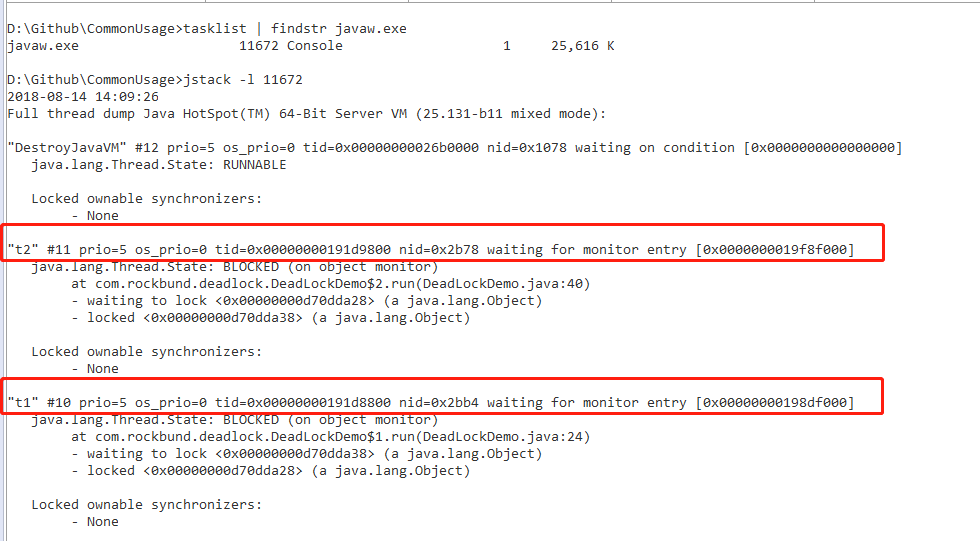
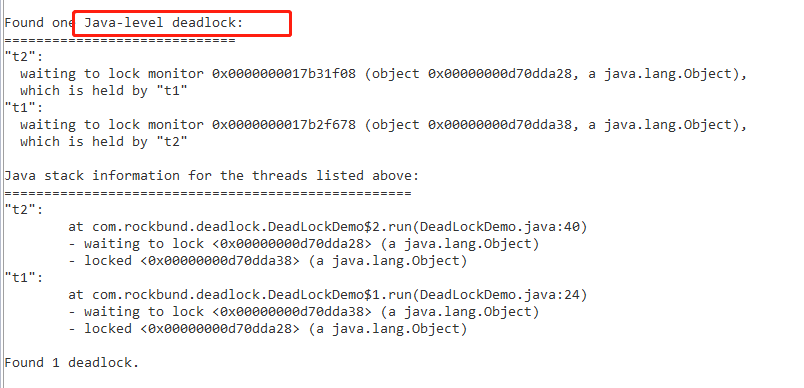
对于jstack做的ThreadDump的栈,可以反映如下信息:
- 如果某个相同的call stack经常出现, 我们有80%的以上的理由确定这个代码存在性能问题(读网络的部分除外);
- 如果相同的call stack出现在同一个线程上(tid)上, 我们很很大理由相信, 这段代码可能存在较多的循环或者死循环;
- 如果某call stack经常出现, 并且里面带有lock,请检查一下这个lock的产生的原因, 可能是全局lock造成了性能问题;
- 在一个不大压力的群集里(w<2), 我们是很少拿到带有业务代码的stack的, 并且一般在一个完整stack中, 最多只有1-2业务代码的stack,
- 如果经常出现, 一定要检查代码, 是否出现性能问题。
- 如果你怀疑有dead lock问题, 那么请把所有的lock id找出来,看看是不是出现重复的lock id。

