常用OLAP引擎
l presto
Presto是Facebook开发的分布式大数据SQL查询引擎,专门进行快速数据分析。
特点:
- 可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
- 直接从HDFS读取数据,在使用前不需要大量的ETL操作。
查询原理:
- 完全基于内存的并行计算
- 流水线
- 本地化计算
- 动态编译执行计划
- 小心使用内存和数据结构
- 类BlinkDB的近似查询
- GC控制
架构图:
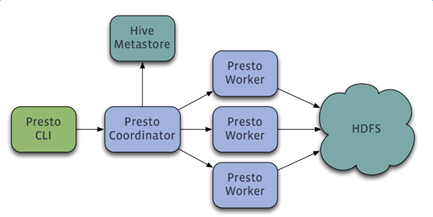
Presto实现原理和美团的使用实践 http://tech.meituan.com/presto.html
Presto官网 http://prestodb-china.com/
l druid
Druid是广告分析公司Metamarkets开发的一个用于大数据实时查询和分析的分布式实时处理系统,主要用于广告分析,互联网广告系统监控、度量和网络监控。
特点:
- 快速的交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到。
- 高可用性——Druid的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失;
- 可扩展——Druid已实现每天能够处理数十亿事件和TB级数据。
- 为分析而设计——Druid是为OLAP工作流的探索性分析而构建,它支持各种过滤、聚合和查询。
应用场景:
- 需要实时查询分析时;
- 具有大量数据时,如每天数亿事件的新增、每天数10T数据的增加;
- 需要一个高可用、高容错、高性能数据库时。
- 需要交互式聚合和快速探究大量数据时
架构图:

Druid官网 http://druid.io/druid.html
Druid:一个用于大数据实时处理的开源分布式系统 http://www.infoq.com/cn/news/2015/04/druid-data/
Druid创始人Eric Tschetter详解开源实时大数据分析系统Druid http://www.csdn.net/article/2014-10-30/2822381
l apache kylin
Apache Kylin最初由eBay开发并贡献至开源社区的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据。
特点:
- 用户为百亿以上数据集定义数据模型并构建立方体
- 亚秒级的查询速度,同时支持高并发
- 为Hadoop提供标准SQL支持大部分查询功能
- 提供与BI工具,如Tableau的整合能力
- 友好的web界面以管理,监控和使用立方体
- 项目及立方体级别的访问控制安全
架构图:
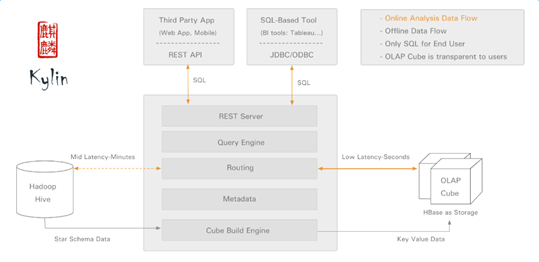
kylin官网 http://kylin.apache.org/cn/
l 系统对比
性能对比:
Presto,Kylin1.3,Kylin1.5和Druid
典型的五个查询场景:一个事实表的过滤和聚合;五张表全关联之后的查询;两个Count Dstinct指标和两个Sum指标;后面两个查询包含8~10个的维度过滤。
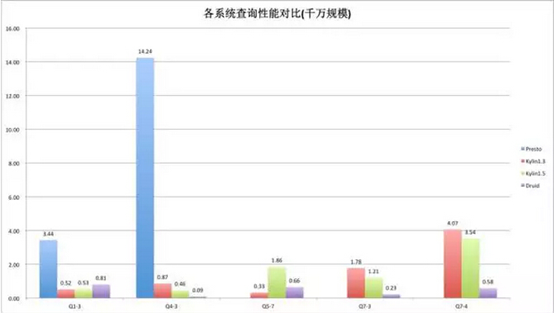
图-千万规模的级别
总结:可以看到不管Presto跟Kylin还是Druid相比差的都比较多,差一个数量级。从后面的两个查询上可以看到,在千万规模的级别,和Druid还是有比较大的差距。这主要和它们的实现模式相关,因为Druid会把所有的数据预处理完以后都加载到内存里,在做一些小数据量聚合的时候,可以达到非常快的速度;但是Kylin要到HBase上读,相对来说它的性能要差一些,但也完全能满足需求。
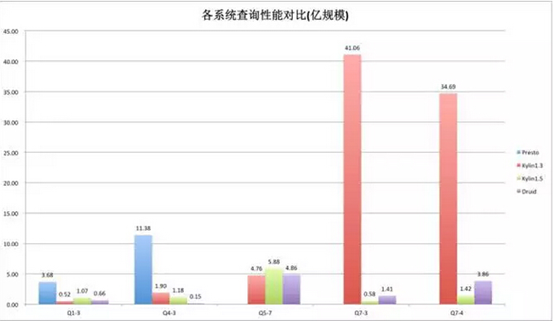
图-亿规模的级别
总结:在亿级的规模上情况又有了变化,还是看后面两个查询,Kylin1.3基本上是一个线性的增长,这个数据已经变得比较难看了,这是由于Kylin1.3在扫描HBase的时候是串行方式,但是Kylin1.5反而会有更好的表现,这是因为Kylin1.5引入了HBase并行Scan,大大降低了扫描的时间。Kylin1.5的数据会shard到不同的region上,在千万量级上数据量还比较小,没有明显的体现,但是上亿以后,随着数据量上升,region也变多了,反而能把并发度提上去。所以在这里可以看到Kylin1.5表现会更好。这里也可以看出,在数据量成数量级上升后,Kylin表现的更加稳定,在不同规模数据集上依然可以保持不错的查询性能。而Druid随着数据量的增长性能损失也成倍增长。
系统的易用性:
Druid一个集群的角色是非常多的,如果要把这个系统用起来的话,可能光搭这个环境,起这些服务都要很长的时间。这个对于我们做平台来讲,实际上是一个比较痛的事。不管是在部署,还是加监控的时候,成本都是相对比较高的。另外一个查询接口方面,我们最熟悉或者最标准,最好用的当然是标准SQL的接口。ES、Druid这些系统原来都不支持SQL,当然现在也有一些插件,但是在功能的完备性和数据的效率上都不如原生的支持。
数据成本:
在查询成本上,Presto是最好的,因为几乎不需要做什么特殊的处理,基本上Hive能读的数据Presto也都能读,所以这个成本非常低。Druid和Kylin的成本相对较高,因为都需要提前的预计算,尤其是Kylin如果维度数特别多,而且不做特别优化的话,数据存储会比较耗资源。
Kylin优势:
第一,性能非常稳定。因为Kylin依赖的所有服务,比如Hive、HBase都是非常成熟的,Kylin本身的逻辑并不复杂,所以稳定性有一个很好的保证。
第二,易用。首先是外围的服务,不管是Hive还是HBase,只要大家用Hadoop系统的话基本都有了,不需要额外工作。在部署运维和使用成本上来讲,都是比较低的。其次,有一个公共的Web页面来做模型的配置。相比之下Druid现在还是基于配置文件来做。这里就有一个问题,配置文件一般都是平台方或者管理员来管理的,没办法把这个配置系统开放出去,这样在沟通成本和响应效率上都不够理想。
第三,活跃开放的社区和热心的核心开发者团队,社区里讨论非常开放,大家可以提自己的意见及patch,修复bug以及提交新的功能等。核心团队都是中国人,这是Apache所有项目里唯一中国人为主的顶级项目,社区非常活跃和热心,有非常多的中国工程师。
Apache Kylin在美团数十亿数据OLAP场景下的实践 http://kyligence.io/2016/08/2016/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号