网络编程中的函数实现原理
网络编程之函数实现方法
socket的创建
struct socket {
short type; /* SOCK_STREAM, ... */
socket_state state;
long flags;
struct proto_ops *ops;
// 这个字段要记一下
void *data;
struct socket *conn;
struct socket *iconn;
struct socket *next;
struct wait_queue **wait;
struct inode *inode;
struct fasync_struct *fasync_list;
};
struct socket *sock_alloc(void)
{
struct inode * inode;
struct socket * sock;
// 获取一个可用的inode节点
inode = get_empty_inode();
if (!inode)
return NULL;
// 初始化某些字段
inode->i_mode = S_IFSOCK;
inode->i_sock = 1;// socket文件
inode->i_uid = current->uid;
inode->i_gid = current->gid;
// 指向inode的socket结构体,初始化inode结构体的socket结构体
sock = &inode->u.socket_i;
sock->state = SS_UNCONNECTED;
sock->flags = 0;
sock->ops = NULL;
sock->data = NULL;
sock->conn = NULL;
sock->iconn = NULL;
sock->next = NULL;
sock->wait = &inode->i_wait;
// 互相引用
sock->inode = inode; /* "backlink": we could use pointer arithmetic instead */
sock->fasync_list = NULL;
// socket数加一
sockets_in_use++;
// 返回新的socket结构体,他挂载在inode中
return sock;
}
sock_alloc首先分配一个inode,然后对inode和sock进行初始化,inode设置为socket文件类型。
这时我们拿到了一个socket结构体,接着调用create函数
// 创建一个sock结构体,和socket结构体互相关联
static int inet_create(struct socket *sock, int protocol)
{
struct sock *sk;
struct proto *prot;
int err;
// 分配一个sock结构体
sk = (struct sock *) kmalloc(sizeof(*sk), GFP_KERNEL);//kmalloc用于向内核空间申请内存。
switch(sock->type)
{
case SOCK_STREAM:
protocol = IPPROTO_TCP;
// 函数集
prot = &tcp_prot;
break;
case SOCK_DGRAM:
protocol = IPPROTO_UDP;
prot=&udp_prot;
break;
}
// sock结构体的socket字段指向上层的socket结构体
sk->socket = sock;
// 省略一堆对sock结构体的初始化代码
}
这里可能就有点迷惑,为什么需要socket和sock两种结构体呢?这就不得不提Linux内核对于网络通信层的抽象。一般在网络编程时,创建套接字都是使用socket函数,其声明为
socket(int family, int type, int protocol)
family是协议簇,比如unix域、ipv4、ipv6,type是在第一个参数的基础上的子分类。比如ipv4下有tcp、udp、raw、packet。protocol对tcp、udp没用,对raw、packet的话是标记上层协议类型。这好比一棵树一样,从根节点开始,有很多分支。
socket结构体是對於所有协议簇的顶层抽象,在同一协议簇下也有不同的子类,如ipv4下有tcp,udp等。不同子类具体的实现方法不同,数据结构与算法也不同,所以socket结构体下有一个自定义的data字段。这个字段在ipv4下就是sock结构体,在Unix域下就是unix_proto_data结构体。
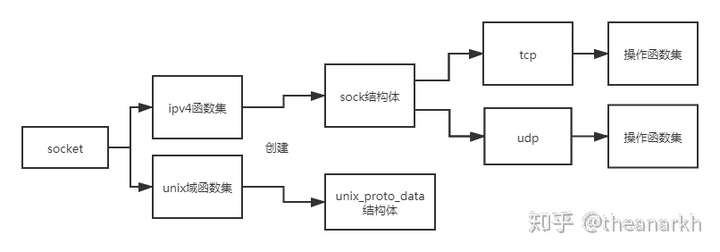
这样我们就得到了一个inode和文件描述符fd,返回fd。
所以创建socket的函数实现为
// 新建一个socket结构体,并且创建一个下层的sock结构体,互相关联
static int sock_socket(int family, int type, int protocol)
{
int i, fd;
struct socket *sock;
struct proto_ops *ops;
// 找到对应的协议族,比如unix域、ipv4
for (i = 0; i < NPROTO; ++i)
{ // 从props数组中找到family协议对应的操作函数集,props由系统初始化时sock_register进行操作。不同的协议族在底层对应不同的处理函数
if (pops[i] == NULL) continue;
if (pops[i]->family == family)
break;
}
if (i == NPROTO)
{
return -EINVAL;
}
// 函数集
ops = pops[i];
// 检查一下类型
if ((type != SOCK_STREAM && type != SOCK_DGRAM &&
type != SOCK_SEQPACKET && type != SOCK_RAW &&
type != SOCK_PACKET) || protocol < 0)
return(-EINVAL);
// 分配一个新的socket结构体
if (!(sock = sock_alloc()))
{
...
}
// 设置类型和操作函数集
sock->type = type;
sock->ops = ops;
if ((i = sock->ops->create(sock, protocol)) < 0)
{
sock_release(sock);
return(i);
}
// 返回一个新的文件描述符
if ((fd = get_fd(SOCK_INODE(sock))) < 0)
{
sock_release(sock);
return(-EINVAL);
}
return(fd);
}
bind函数
static int sock_bind(int fd, struct sockaddr *umyaddr, int addrlen)
{
struct socket *sock;
int i;
char address[MAX_SOCK_ADDR];
int err;
// 通过文件描述符找到对应的socket
if (!(sock = sockfd_lookup(fd, NULL))) //sockfd_lookup通过fd找到file结构体,从而找到socket结构体。
return(-ENOTSOCK);
if((err=move_addr_to_kernel(umyaddr,addrlen,address))<0)
return err;
if ((i = sock->ops->bind(sock, (struct sockaddr *)address, addrlen)) < 0)
{
return(i);
}
return(0);
}
sockfd_lookup的函数定义为:
// 通过fd找到file结构体,从而找到inode节点,最后找到socket结构体
static inline struct socket *sockfd_lookup(int fd, struct file **pfile)
{
struct file *file;
struct inode *inode;
if (fd < 0 || fd >= NR_OPEN || !(file = current->files->fd[fd]))
return NULL;
inode = file->f_inode;
if (!inode || !inode->i_sock)
return NULL;
if (pfile)
*pfile = file;
return socki_lookup(inode);
}
// inode和socket互相引用
inline struct socket *socki_lookup(struct inode *inode)
{
return &inode->u.socket_i;
}
bind函数与socket函数一样,底层的具体实现取决于协议簇,假设在ipv4协议簇下,bind的函数实现为:
// 给socket绑定一个地址
static int inet_bind(struct socket *sock, struct sockaddr *uaddr,
int addr_len)
{
struct sockaddr_in *addr=(struct sockaddr_in *)uaddr;
// 拿到底层的sock结构体
struct sock *sk=(struct sock *)sock->data, *sk2;
unsigned short snum = 0 /* Stoopid compiler.. this IS ok */;
int chk_addr_ret;
// raw协议的这些数据由用户填充
if(sock->type != SOCK_RAW)
{ // 已经绑定了端口
if (sk->num != 0)
return(-EINVAL);
snum = ntohs(addr->sin_port);
// 端口无效则随机获取一个非root才能使用的端口
if (snum == 0)
{
snum = get_new_socknum(sk->prot, 0);
}
// 小于1024的端口需要超级用户权限
if (snum < PROT_SOCK && !suser())
return(-EACCES);
}
// 判断ip
chk_addr_ret = ip_chk_addr(addr->sin_addr.s_addr);
// 非法地址
if (addr->sin_addr.s_addr != 0 && chk_addr_ret != IS_MYADDR && chk_addr_ret != IS_MULTICAST)
return(-EADDRNOTAVAIL); /* Source address MUST be ours! */
// 记录ip
if (chk_addr_ret || addr->sin_addr.s_addr == 0)
sk->saddr = addr->sin_addr.s_addr;
if(sock->type != SOCK_RAW)
{
/* Make sure we are allowed to bind here. */
cli();
// 遍历哈希表,哈希表冲突解决法是链地址法,校验绑定的端口的合法性
for(sk2 = sk->prot->sock_array[snum & (SOCK_ARRAY_SIZE -1)];
sk2 != NULL; sk2 = sk2->next)
{
// 端口还没有绑定过,直接校验下一个
if (sk2->num != snum)
continue;
// 端口已经被使用,没有设置可重用标记,比如断开连接后在2msl内是否可以重用,通过setsockopt函数设置
if (!sk->reuse)
{
sti();
return(-EADDRINUSE);
}
// 端口一样,但是ip不一样,ok,下一个
if (sk2->saddr != sk->saddr)
continue; /* socket per slot ! -FB */
// 端口和ip都一样。被监听的端口不能同时被使用
if (!sk2->reuse || sk2->state==TCP_LISTEN)
{
sti();
return(-EADDRINUSE);
}
}
sti();
// 保证该sk不在sock_array队列里
remove_sock(sk);
// 挂载到sock_array里
put_sock(snum, sk);
// tcp头中的源端口
sk->dummy_th.source = ntohs(sk->num);
sk->daddr = 0;
sk->dummy_th.dest = 0;
}
return(0);
}
bind函数主要是对待绑定的ip和端口做一个校验,合法的时就记录在sock结构体中。并且把sock结构体挂载到一个全局的哈希表里。
cli()和sti()函数的定义请见附录A。
listen函数
static int sock_listen(int fd, int backlog)
{
struct socket *sock;
if (fd < 0 || fd >= NR_OPEN || current->files->fd[fd] == NULL)
return(-EBADF);
if (!(sock = sockfd_lookup(fd, NULL)))
return(-ENOTSOCK);
if (sock->state != SS_UNCONNECTED)
{
return(-EINVAL);
}
if (sock->ops && sock->ops->listen)
sock->ops->listen(sock, backlog);
// 设置socket的监听属性,accept函数时用到
sock->flags |= SO_ACCEPTCON;
return(0);
}
static int inet_listen(struct socket *sock, int backlog)
{
struct sock *sk = (struct sock *) sock->data;
// 如果没有绑定端口则绑定一个,并把sock加到sock_array中
if(inet_autobind(sk)!=0)
return -EAGAIN;
if ((unsigned) backlog > 128)
backlog = 128;
// tcp接收队列的长度上限,不同系统实现不一样,具体参考tcp.c的使用
sk->max_ack_backlog = backlog;
// 修改socket状态,防止多次调用listen
if (sk->state != TCP_LISTEN)
{
sk->ack_backlog = 0;
sk->state = TCP_LISTEN;
}
return(0);
}
// 绑定一个随机的端口,更新sk的源端口字段,并把sk挂载到端口对应的队列中,见bind函数的分析
static int inet_autobind(struct sock *sk)
{
/* We may need to bind the socket. */
if (sk->num == 0)
{
sk->num = get_new_socknum(sk->prot, 0);
if (sk->num == 0)
return(-EAGAIN);
put_sock(sk->num, sk);
sk->dummy_th.source = ntohs(sk->num);
}
return 0;
}
可以看出sock_listen是最顶层的函数,在sock_listen内通过调用相应协议簇的listen函数进行监听。对于ipv4协议簇,其监听函数为inet_listen,在其内部也只是设置一些监听队列的长度,以及在socket没有绑定端口时随机绑定一个端口。
accept函数
服务器在监听一个端口时,当有新的连接进入时,就新建一个socket,我们就可以通过accept函数拿到这个socket对应的描述符。
accept函数定义为:
static int sock_accept(int fd, struct sockaddr *upeer_sockaddr, int *upeer_addrlen)
{
struct file *file;
struct socket *sock, *newsock;
int i;
char address[MAX_SOCK_ADDR];
int len;
if (fd < 0 || fd >= NR_OPEN || ((file = current->files->fd[fd]) == NULL))
return(-EBADF);
// 根据文件描述符找到对应的file结构体和socket结构
if (!(sock = sockfd_lookup(fd, &file)))
return(-ENOTSOCK);
if (sock->state != SS_UNCONNECTED)
{
return(-EINVAL);
}
// socket没有调用过listen,报错,该标记位在listen中设置
if (!(sock->flags & SO_ACCEPTCON))
{
return(-EINVAL);
}
// 分配一个新的socket结构体
if (!(newsock = sock_alloc()))
{
printk("NET: sock_accept: no more sockets\n");
return(-ENOSR); /* Was: EAGAIN, but we are out of system
resources! */
}
newsock->type = sock->type;
newsock->ops = sock->ops;
// 创建一个底层的sock结构体和新的socket结构体互相关联
if ((i = sock->ops->dup(newsock, sock)) < 0)
{
sock_release(newsock);
return(i);
}
// accept返回一个新的sock和socket关联
i = newsock->ops->accept(sock, newsock, file->f_flags);
if ( i < 0)
{
sock_release(newsock);
return(i);
}
// 返回一个新的文件描述符
if ((fd = get_fd(SOCK_INODE(newsock))) < 0)
{
sock_release(newsock);
return(-EINVAL);
}
// 是否需要获取socket对应的地址
if (upeer_sockaddr)
{
newsock->ops->getname(newsock, (struct sockaddr *)address, &len, 1);
move_addr_to_user(address,len, upeer_sockaddr, upeer_addrlen);
}
return(fd);
}
这个sock_accept函数又是最顶层的实现,重点在于第39行相应协议簇的accept函数的实现。
在ipv4下,accept函数的实现为:
static int inet_accept(struct socket *sock, struct socket *newsock, int flags)
{
struct sock *sk1, *sk2;
int err;
sk1 = (struct sock *) sock->data;
// 返回一个新的sock结构体
sk2 = sk1->sk_prot->accept(sk1,flags);
// 互相关联
newsock->data = (void *)sk2;
sk2->socket = newsock;
newsock->conn = NULL;
// 设置sock为已经建立连接状态
newsock->state = SS_CONNECTED;
return(0);
}
可以看到,在这里的第7行,又嵌套了一个底层的accept函数。sk1->sk_prot是属于proto结构体类型的。一起看一下tcp层的accept函数
static struct sock *tcp_accept(struct sock *sk, int flags)
{
struct sock *newsk;
struct sk_buff *skb;
// 是一个listen的套接字
if (sk->state != TCP_LISTEN)
{
sk->err = EINVAL;
return(NULL);
}
cli();
// 从sock的receive_queue队列摘取已建立连接的节点,
while((skb = tcp_dequeue_established(sk)) == NULL)
{
// 没有已经建立连接的节点,但是设置了非阻塞模式,直接返回
if (flags & O_NONBLOCK)
{
sti();
release_sock(sk);
sk->err = EAGAIN;
return(NULL);
}
release_sock(sk);
//阻塞进程,如果后续建立了连接,则进程被唤醒的时候,就会跳出while循环
interruptible_sleep_on(sk->sleep);
}
sti();
// 拿到一个新的sock结构,由建立连接的时候创建的
newsk = skb->sk;
// 返回新的sock结构体
return(newsk);
}
这个函数的主要逻辑就是从监听型的socket的已完成的三次握手的队列中摘下一个节点,这个节点是一个sk_buff结构体,sk_buff是一个网络结构包的数据结构。
TCP/IP三次握手的实现
connect函数
客户端发起连接的过程在网络编程中非常简单,无非就是创建一个socket,然后调用connect函数去建立连接。操作系统在connect函数中做了很多。
顶层connect函数的定义为:
static int sock_connect(int fd, struct sockaddr *uservaddr, int addrlen)
{
struct socket *sock;
struct file *file;
int i;
char address[MAX_SOCK_ADDR];
int err;
if (fd < 0 || fd >= NR_OPEN || (file=current->files->fd[fd]) == NULL)
return(-EBADF);
if (!(sock = sockfd_lookup(fd, &file)))
return(-ENOTSOCK);
i = sock->ops->connect(sock, (struct sockaddr *)address, addrlen, file->f_flags);
if (i < 0)
{
return(i);
}
return(0);
}
同样的套路,根据套接字描述符找到相应的socket结构体,然后统一地调用sock->op的connect函数,这个函数同样在不同的协议簇中有不同的实现。
在sock->op->connect函数内,进行一系列判断后,继续调用传输层的connect函数。如果是tcp层,则发送一个sync包,然后把socket状态修改为连接中。
tcp层的connect函数定义为:
static int tcp_connect(struct sock *sk, struct sockaddr_in *usin, int addr_len)
{
struct sk_buff *buff;
struct device *dev=NULL;
unsigned char *ptr;
int tmp;
int atype;
struct tcphdr *t1;
struct rtable *rt;
if (usin->sin_family && usin->sin_family != AF_INET)
return(-EAFNOSUPPORT);
// 不传ip则取本机ip
if(usin->sin_addr.s_addr==INADDR_ANY)
usin->sin_addr.s_addr=ip_my_addr();
// 禁止广播和多播
if ((atype=ip_chk_addr(usin->sin_addr.s_addr)) == IS_BROADCAST || atype==IS_MULTICAST)
return -ENETUNREACH;
sk->inuse = 1;
// 连接的远端地址
sk->daddr = usin->sin_addr.s_addr;
// 第一个字节的序列号
sk->write_seq = tcp_init_seq();
sk->window_seq = sk->write_seq;
sk->rcv_ack_seq = sk->write_seq -1;
sk->err = 0;
// 远端端口
sk->dummy_th.dest = usin->sin_port;
release_sock(sk);
// 分配一个skb
buff = sk->prot->wmalloc(sk,MAX_SYN_SIZE,0, GFP_KERNEL);
sk->inuse = 1;
// tcp头和选项,告诉对方自己的接收窗口大小1
buff->len = 24;
buff->sk = sk;
buff->free = 0;
buff->localroute = sk->localroute;
t1 = (struct tcphdr *) buff->data;
// 查找路由
rt=ip_rt_route(sk->daddr, NULL, NULL);
// 构建ip和mac头
tmp = sk->prot->build_header(buff, sk->saddr, sk->daddr, &dev,
IPPROTO_TCP, NULL, MAX_SYN_SIZE,sk->ip_tos,sk->ip_ttl);
buff->len += tmp;
t1 = (struct tcphdr *)((char *)t1 +tmp);
memcpy(t1,(void *)&(sk->dummy_th), sizeof(*t1));
// 序列号为初始化的序列号
t1->seq = ntohl(sk->write_seq++);
// 下一个数据包中第一个字节的序列号
sk->sent_seq = sk->write_seq;
buff->h.seq = sk->write_seq;
t1->ack = 0;
t1->window = 2;
t1->res1=0;
t1->res2=0;
t1->rst = 0;
t1->urg = 0;
t1->psh = 0;
// 是一个syn包
t1->syn = 1;
t1->urg_ptr = 0;
// TCP头包括24个字节,因为还有4个字节的选项
t1->doff = 6;
// 执行tcp头后面的第一个字节
ptr = (unsigned char *)(t1+1);
// 选项的类型是2,通知对方TCP报文中数据部分的最大值
ptr[0] = 2;
// 选项内容长度是4个字节
ptr[1] = 4;
// 组成MSS
ptr[2] = (sk->mtu) >> 8;
ptr[3] = (sk->mtu) & 0xff;
// tcp头的校验和
tcp_send_check(t1, sk->saddr, sk->daddr,sizeof(struct tcphdr) + 4, sk);
// 设置套接字为syn_send状态
tcp_set_state(sk,TCP_SYN_SENT);
// 设置数据包往返时间需要的时间
sk->rto = TCP_TIMEOUT_INIT;
// 设置超时回调
sk->retransmit_timer.function=&retransmit_timer;
sk->retransmit_timer.data = (unsigned long)sk;
// 设置超时时间
reset_xmit_timer(sk, TIME_WRITE, sk->rto);
// 设置syn包的重试次数
sk->retransmits = TCP_SYN_RETRIES;
// 发送
sk->prot->queue_xmit(sk, dev, buff, 0);
reset_xmit_timer(sk, TIME_WRITE, sk->rto);
release_sock(sk);
return(0);
}
其核心代码就是构建一个tcp包并发送出去。这是第一次握手的代码
第二次握手的代码为:
// 发送了syn包
if(sk->state==TCP_SYN_SENT)
{
// 发送了syn包,收到ack包说明可能是建立连接的ack包
if(th->ack)
{
// 尝试连接但是对端回复了重置包
if(th->rst)
return tcp_std_reset(sk,skb);
// 建立连接的回包
syn_ok=1;
// 期待收到对端下一个的序列号
sk->acked_seq=th->seq+1;
sk->fin_seq=th->seq;
// 发送第三次握手的ack包,进入连接建立状态
tcp_send_ack(sk->sent_seq,sk->acked_seq,sk,th,sk->daddr);
tcp_set_state(sk, TCP_ESTABLISHED);
// 解析tcp选项
tcp_options(sk,th);
// 记录对端地址
sk->dummy_th.dest=th->source;
// 可以读取但是还没读取的序列号
sk->copied_seq = sk->acked_seq;
// 唤醒阻塞在connect函数的进程
if(!sk->dead)
{
sk->state_change(sk);
sock_wake_async(sk->socket, 0);
}
}
}
推荐大家关注知乎专栏
Appendix A
cli和sti函数
这两个函数属于Linux的内核函数。
cli()和sti()类似于汇编指令中的CLI和STL,当某个任务不想在执行的过程中被打断,则可以在任务的开始处执行cli(),在任务的结束处执行sti(),恢复中断的执行。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)