

测试拆分比较大SQL Server数据库
有2个办法拆分比较大的数据库。
1.重建聚集索引
2.收缩数据库
一、准备测试数据
1 1 create table blocktable(blockno int,binno int,rack int,chipcount int,machineno varchar(10)) 2 2 go 3 3 4 4 insert into blocktable(blockno,binno,rack,chipcount,machineno) 5 5 select cast((rand(checksum(newid()))*130) as int),cast((rand(checksum(newid()))*10) as int), 6 6 cast((rand(checksum(newid()))*130) as int),0,'001' 7 7 from master..spt_values 8 8 where [type] = 'p' and number <= 10000000000 9 9 10 10 select * 11 11 from blocktable 12 12 13 13 insert into blocktable select * from blocktable 14 14 15 15 drop table blocktable 16 16 17 17 select @@servername
拆分前:
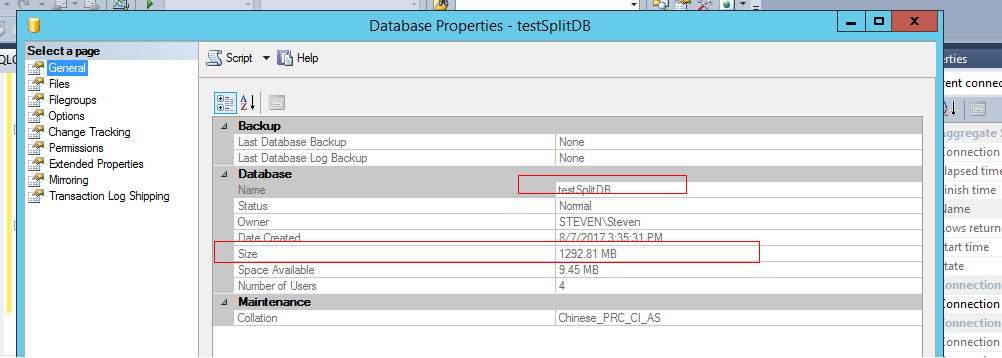
添加3个数据文件

此时主数据文件大小不变,ndf文件大小为初始大小100M, 说明数据还没有移动到ndf文件中.
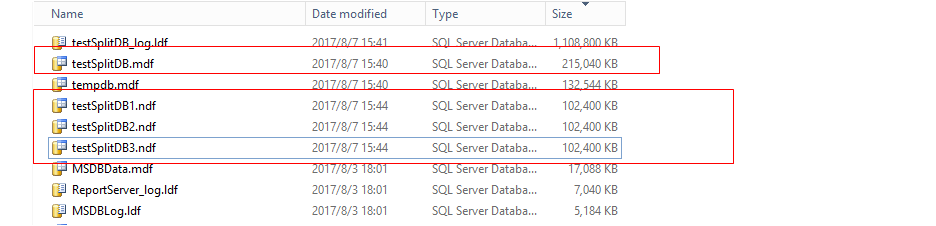
收缩数据库
1 USE [testSplitDB] 2 GO 3 DBCC SHRINKDATABASE(N'testSplitDB' ) 4 GO
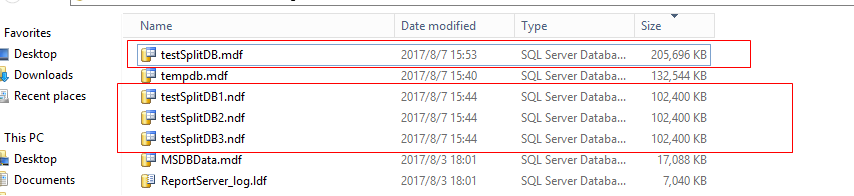
这个命令没起作用
下面测试清空rimary DB file
清空primary DB file遇到错误,原因未知.
下面测试重建聚集索引.
重建狙击索引有效
下面再测试一遍
测试数据库大小

加入3个ndf文件

测试收缩数据库
---没有效果
使用下面的选项移动成功, 并且ndf文件是轮流写,所以ndf文件大小相近. 但是花费时间比较长. 如果操作的是mdf文件, 最后可能报错,提示不能移动所有object, 这个错误可以忽略. 完成后再释放mdf文件的空间就可以了.

收缩完成后结果:
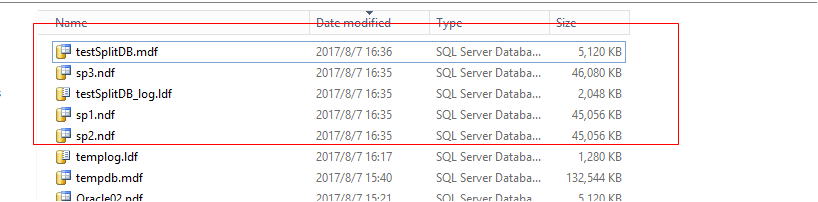
当再次写入数据时,所有文件会被轮流写入
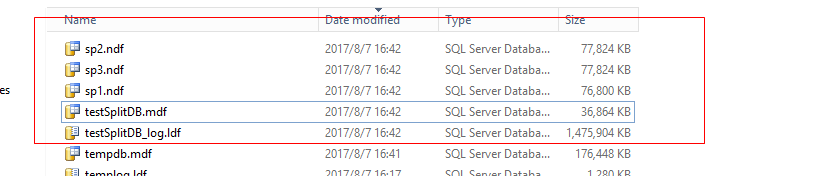
• 第三次测试
再次确认普通收缩数据库不行,必须选择清空数据库文件才可以移动数据到ndf文件.
再次确认新建聚集索引有效,收缩的时候选择重新组织页.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号