

如何快速上手lxml
lxml是一个非常方便的解析工具,首先了解一下lxml在整个爬虫开发流程中的作用。
爬虫可简单可复杂,视爬虫对象、任务不同而不同。我们的目标是用最简单最有效的方法来快速获取想要的信息。
这里给出一个简单例子:爬取信用信息公示系统中,企业信息详情。
如下图所示:

1 实例
首先确定lxml规则
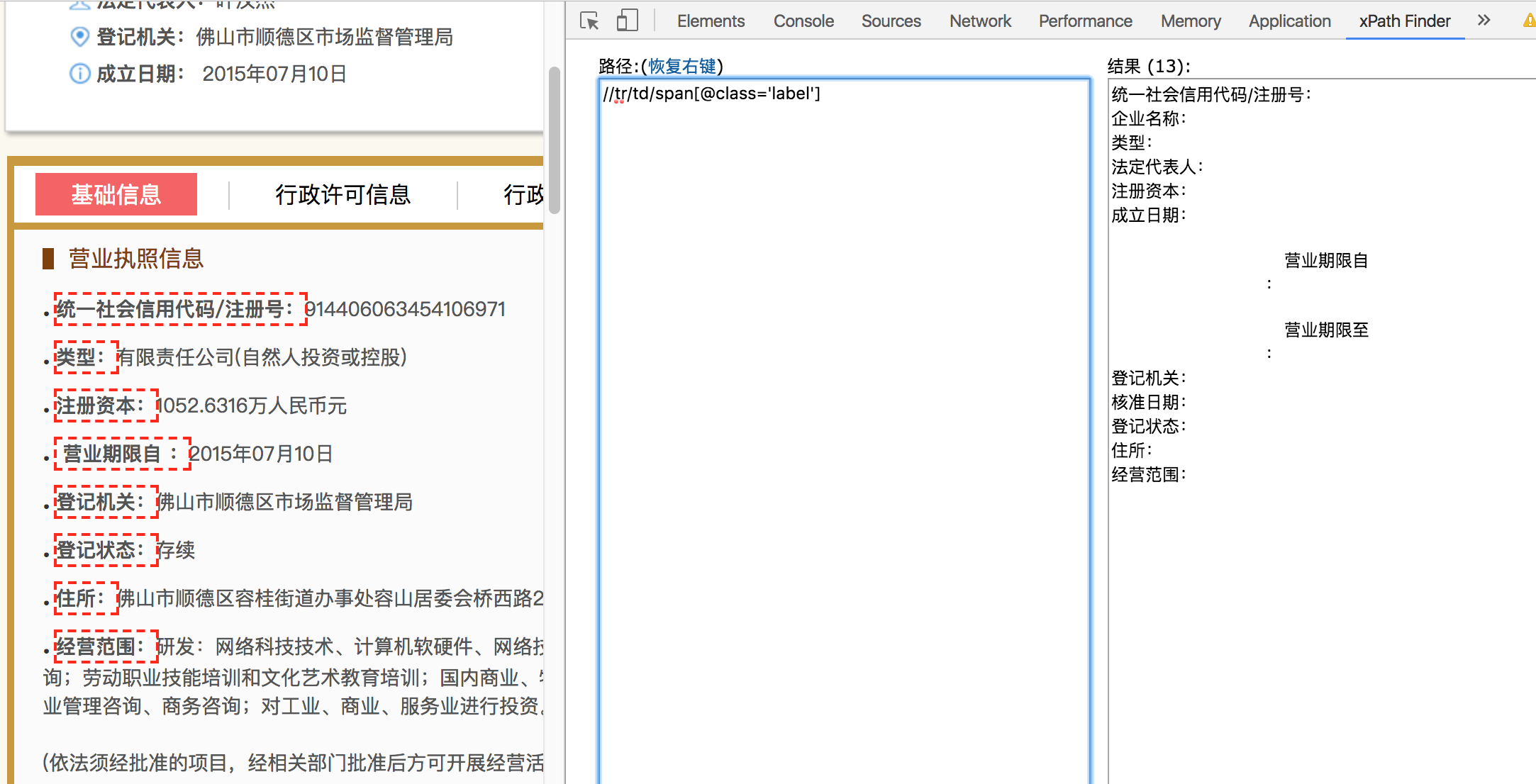
xpath finder插件会直观显示匹配结果。
然后再ipython中验证
In [1]: import requests
In [2]: from lxml import html
In [3]: resp=requests.get('http://www.sdsszt.com/GSpublicity/GSpublicityList.html?service=entInfo_QuIz54WYBCp98MAnDE+TOjSI6nj4d
...: DhPid4wNzIOjLyqVswLC8L8we/iqFGcaayM-q1d+FAeb99tNXz0PkuiXwA==&localSetting=sd&from=singlemessage')
In [4]: text=resp.content.decode('utf-8')
In [7]: root=html.fromstring(text)
In [21]: root.findall('.//tr/td/span[@class=\'label\']')[0].xpath('text()')
Out[21]: ['统一社会信用代码/注册号:']
In [22]: root.findall('.//table//tr/td/span[@class=\'label\']')[0].xpath('text()')
Out[22]: ['统一社会信用代码/注册号:']
In [23]: root.findall('.//table//tr/td/span[@class=\'content\']')[0].xpath('text()')
Out[23]: ['914406063454106971']
动手写脚本,一气呵成
# encoding: utf-8
__author__ = 'fengshenjie'
import requests
from lxml import html
import json
import csv, random
conf = {
'start_url': [
'http://www.sdsszt.com/GSpublicity/GSpublicityList.html?service=entInfo_QuIz54WYBCp98MAnDE+TOjSI6nj4dDhPid4wNzIOjLyqVswLC8L8we/iqFGcaayM-q1d+FAeb99tNXz0PkuiXwA==&localSetting=sd&from=singlemessage'
],
'raw_headers': ['''Host: www.sdsszt.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7,da;q=0.6
''']
}
def getHeader():
headerrow = random.choice(conf['raw_headers'])
res = {}
lines = headerrow.split('\n')
for line in lines:
try:
k, v = line.split(':')
res[k] = v
except Exception as e:
print(e, line)
return res
def downloader(url):
resp = requests.get(url)
return resp.content.decode('utf-8')
def parser(text):
assert isinstance(text, str)
root = html.fromstring(text)
res = []
labels = root.findall('.//tr/td/span[@class=\'label\']')
contents = root.findall('.//tr/td/span[@class=\'content\']')
assert len(labels) == len(contents)
for i in range(len(labels)):
label = labels[i].xpath('text()')
content = contents[i].xpath('text()')
res.append({
'label': label[0].replace('\r\n', '').strip(),
'content': content[0].strip()
})
# print(json.dumps(res, ensure_ascii=False))
outputer(res)
def outputer(res, fname='./shunde.csv'):
assert isinstance(res, list)
for d in res:
print(d['label'], d['content'])
lines = [(d['label'], d['content']) for d in res]
with open(fname, 'w', encoding='utf-8-sig') as f:
w = csv.writer(f)
w.writerows(lines)
def main():
for url in conf['start_url']:
print('->', url)
parser(downloader(url))
if __name__ == '__main__':
main()
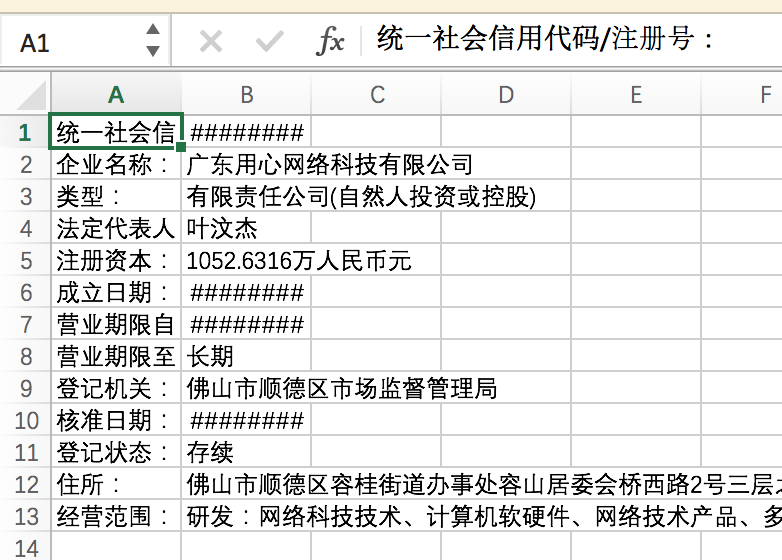
这是我们最后输出的文件:
2 XPath语法
可以看出,要使用lxml,首先要熟悉xpath语法。
基本语法如下
表达式 描述
nodename 选取此节点的所有子节点。
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
路径表达式 结果
/bookstore/* 选取 bookstore 元素的所有子元素。
//* 选取文档中的所有元素。
//title[@*] 选取所有带有属性的 title 元素。
xml.etree.ElementTree模块的相同功能 给出了使用lxml解析xml的示例,
In [1]: from lxml import etree
In [2]: tree=etree.parse('country_data.xml')
In [3]: root=tree.getroot()
# Top-level elements,得到顶级元素
In [4]: root.findall('.')
Out[4]: [<Element data at 0x4685d48>]
# All 'neighbor' grand-children of 'country' children of the top-level
# elements
In [9]: root.findall('./country/neighbor')
Out[9]:
[<Element neighbor at 0x468cfc8>,
<Element neighbor at 0x481a1c8>,
<Element neighbor at 0x4786e48>,
<Element neighbor at 0x468c448>,
<Element neighbor at 0x481a108>]
# Nodes with name='Singapore' that have a 'year' child
In [10]: root.findall('.//year/..')
Out[10]:
[<Element country at 0x481aac8>,
<Element country at 0x468c1c8>,
<Element country at 0x481a708>]
In [12]: root.findall(".//year/..[@name='Singapore']")
Out[12]: [<Element country at 0x468c1c8>]
# 'year' nodes that are children of nodes with name='Singapore'
root.findall(".//*[@name='Singapore']/year")
# All 'neighbor' nodes that are the second child of their parent
root.findall(".//neighbor[2]")
find默认得到第一个,findall找所有
In [14]: root.find('country')
Out[14]: <Element country at 0x481aac8>
In [15]: root.findall('country')
Out[15]:
[<Element country at 0x481aac8>,
<Element country at 0x468c1c8>,
<Element country at 0x481a708>]
获取指定neighbor元素的name属性
In [18]: root.xpath('country/neighbor')[0].xpath('@name')
Out[18]: ['Austria']
In [19]: root.xpath('country/neighbor')
Out[19]:
[<Element neighbor at 0x468cfc8>,
<Element neighbor at 0x481a1c8>,
<Element neighbor at 0x4786e48>,
<Element neighbor at 0x468c448>,
<Element neighbor at 0x481a108>]
获取指定year元素的text
In [23]: root.xpath('country/year')[0].xpath('text()')
Out[23]: ['2008']
除了常规的xml,lxml的解析器也支持html,甚至破碎的html(http://lxml.de/parsing.html)
>>> broken_html = "<html><head><title>test<body><h1>page title</h3>"
>>> parser = etree.HTMLParser()
>>> tree = etree.parse(StringIO(broken_html), parser)
>>> result = etree.tostring(tree.getroot(),
... pretty_print=True, method="html")
>>> print(result)
<html>
<head>
<title>test</title>
</head>
<body>
<h1>page title</h1>
</body>
</html>
或者直接使用etree.HTML()
>>> html = etree.HTML(broken_html)
>>> result = etree.tostring(html, pretty_print=True, method="html")
>>> print(result)
<html>
<head>
<title>test</title>
</head>
<body>
<h1>page title</h1>
</body>
</html>
3 进阶
3.1 contains函数
要抓取的网页情况千变万化,有时候一个div的class可能有多个,contains是模糊匹配,对于动态生成界面的元素id非常有用。
对应的@class=xx用于精确匹配
In: print tr.xpath('.//div[contains(@class,"btn2")]/span')
Out: [<Element span at 0x7e3ab88>]
In: print tr.xpath('.//div[@class="btn2 btn2_center"]/span')
Out: [<Element span at 0x7e3ab88>]
有时碰到很奇怪的问题就多尝试,换个方法可能就行了
In [16]: body=root.findall('body')[0]
In [23]: body.findall('./div[@id="uniq22"]') # 无法通过id识别这个div
Out[23]: []
In [31]: body.xpath('.//*[contains(@class,"page-content")]') # contains语法得到这个div
Out[31]: [<Element div at 0x474ca48>]
References
作者:kakashis
联系方式:fengshenjiev[AT]gmail.com
本文版权归作者所有,欢迎转载,演绎或用于商业目的,但是必须说明本文出处(包含链接)。
