用python绘图-散点图/直方图/概率密度图
项目用到的文件:
一、代码解释:
drawing01.py
import dash # Dash是用于构建分析型Web应用的Python框架,由Plotly开发
from dash import dcc
from dash import html
from dash.dependencies import Input, Output
import pandas as pd # 尤其适用于表格数据和时间序列数据的分析
import numpy as np # 支持大型、多维数组和矩阵
import myFunction
datasets = {
"DFT-P" : { "type" : "DFT", "filename" : "P" },
"DFT-H" : { "type" : "DFT", "filename" : "H" },
"DFT-S" : { "type" : "DFT", "filename" : "S" },
"DFT-G" : { "type" : "DFT", "filename" : "G" }
}
bins = np.array([-2, 0.05, 2.0, 20.0]) #[-2, 0.05)、[0.05, 2.0)和[2.0, 20.0)
df_E = pd.read_csv("data_DFT/E.csv",index_col="mp_id") # 设置 "mp_id" 列作为索引
options_list = []
all_df={}
for label, dataset in datasets.items():
if dataset["type"] == "DFT":
df_X = pd.read_csv("data_DFT/"+dataset["filename"]+".csv",index_col="mp_id")
mp_ids = np.intersect1d(df_X.index,df_E.index)# 用于计算两个数组的交集。返回两个数组中共同存在的元素,并且结果是有序的且去重(即不包含重复元素)
# 创建一个 DataFrame,并从两个不同的数据源中提取数据填充这个DataFrame
df = pd.DataFrame(mp_ids,columns=["mp_id"])
df["exp_gap"] = df_E["gap"].loc[mp_ids].values # .loc[mp_ids]:根据 mp_ids 获取对应行的 gap 值 .values:将得到的值转换为 NumPy 数组,以便直接赋值给新 DataFrame 的一列。
df["model_gap"] = df_X["gap"].loc[mp_ids].values
myFunction.abs_error(df,label)# 给数据集df增加了"error"和"abs_error"列
options_list.append({"label": label, "value": label})
all_df[label]=df
app = dash.Dash(__name__) # 创建 Dash 应用
# html 和 dcc: 用于生成 HTML 元素和 Dash 控件
# 设置应用布局
app.layout = html.Div([
html.Div([
html.H1(children="Comparing plots for all DFT methods"),
html.Div(children = [
html.Label(
["Plot mode:"], # 图的类型
style={"font-weight": "bold", "text-align": "center"}
),
html.Div(children = [
dcc.Dropdown(
id = "plot_mode",
options = [
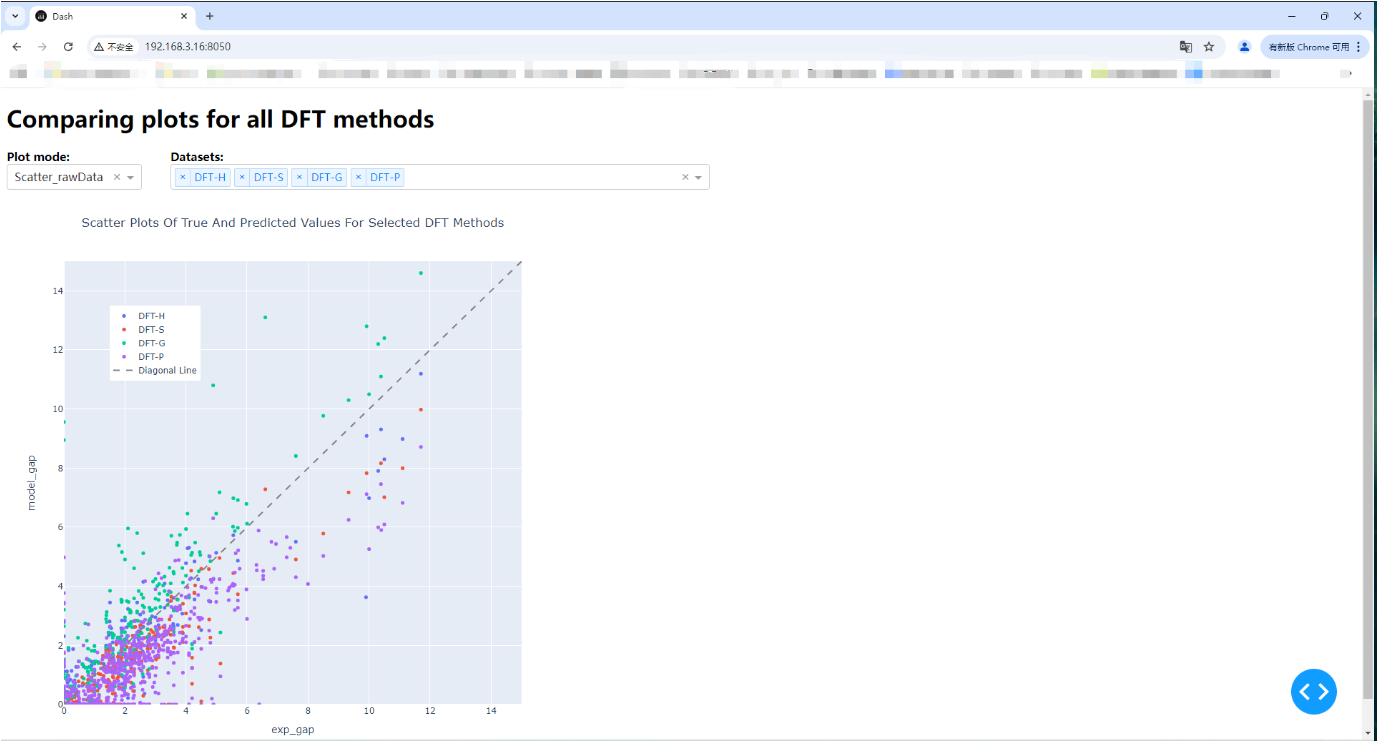
{ "label" : "Scatter_rawData", "value" : 1 }, # 散点图:模型的预测值和真实值之间的分布情况
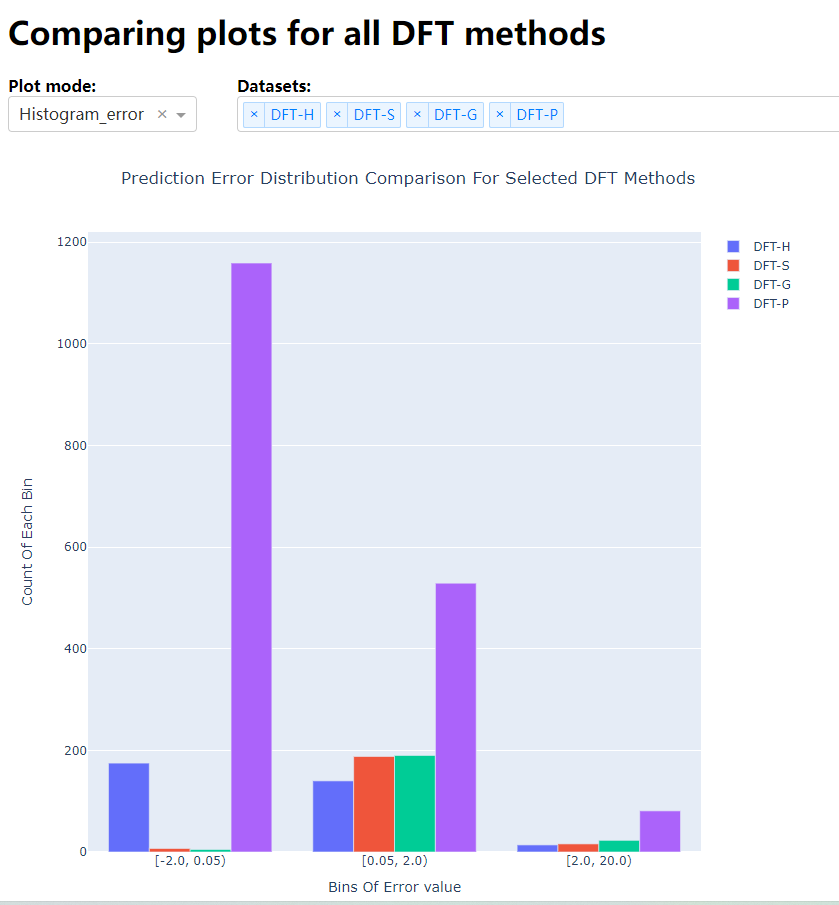
{ "label" : "Histogram_error", "value" : 2 }, # 直方图:将误差数据分组,并以直方图的形式展示。比较该模型对不同数据集的预测误差分布情况。
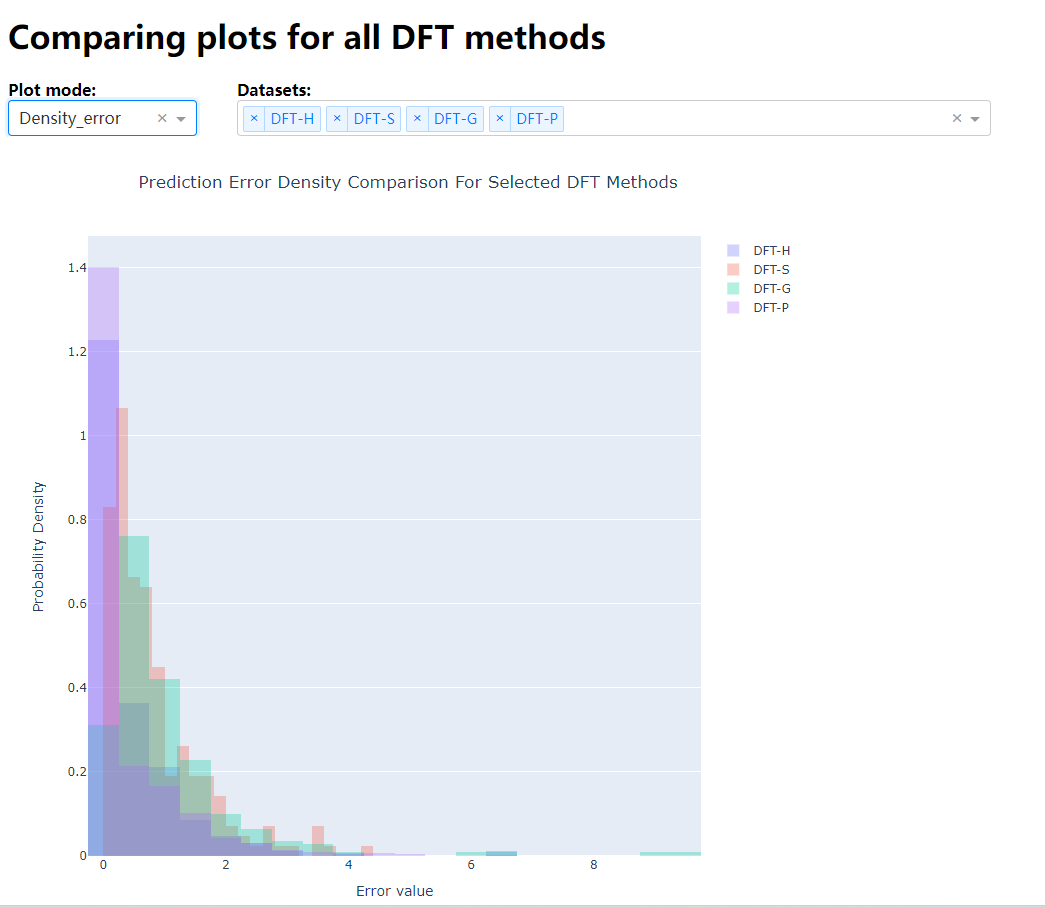
{ "label" : "Density_error", "value" : 3 } # 密度图:密度图是通过平滑直方图来估计数据的概率密度函数,并以连续曲线的形式展示数据分布的集中程度。密度图可以更直观地看出数据的峰值和分布的波动情况
],
value = 1, # 默认选择原始数据的散点图
),
]),
], style = {"width": "10%", "display": "inline-block"}),
html.Div(children = [
html.Label(
["Datasets:"], # 数据集的类型(DFT四种方法:PBE、HSE、GLLB-SC、SCAN)
style = {"font-weight": "bold", "text-align": "center"}
),
html.Div(children = [
dcc.Dropdown(
id = "selected_datasets",
options = options_list,
value = ["DFT-P"], #默认是DFT-P这个数据集
multi = True # 设置为可以多选
)
])
], style = {"width": "40%", "margin-left": "40px", "display": "inline-block"}),
# style={"display": "inline-block"}:让每个div以行内块的形式显示,使它们可以在同一行中并排显示。(div块默认是上下排列的)
]),
html.Div(children = [
html.Div([
dcc.Graph(id="fig"), # 选定的将要展示的某一类型的图
], style={"display": "inline-block"} )
])
])
# 当用户在下拉菜单中选择一个选项时,Dash 会自动调用update_graph回调函数,并将选择的值作为参数传入
@app.callback(
Output( component_id = "fig", component_property = "figure"), # 更新 ID 为 fig 的图表的 figure 属性
Input("plot_mode", "value"), # 监视 ID 为 plot_mode 的组件的值变化
Input("selected_datasets", "value")) # 监视 ID 为 selected_datasets 的组件的值变化
# 这个函数定义了,但没有任何地方调用它。因此,除非在其他地方(例如回调或事件处理器)显式调用它,否则它不会运行。
# 这个函数用于更新图形,当用户选择的plot_mode和数据集改变后,会相应改变显示的图的类型的数据集
def update_graph(plot_mode, selected_datasets):
selected_df= {}
for label in selected_datasets:
selected_df[label]=all_df[label]
# s_dist_data.append([res[dataset].s_df[i]["abs_error"].values for i in range(3)])
if plot_mode == 1:# 原始数据散点图
fig = myFunction.exp_mod_scatter_plotly(selected_df)
elif plot_mode == 2:# error值的分布其情况 直方图
fig = myFunction.Histogram_error_plotly(selected_df,bins)
else:# error值的分布情况密度图
fig = myFunction.Density_error(selected_df)
return fig
# 在 Python 文件中,if __name__ == "__main__": 语句用于检查该文件是否作为主程序直接运行。
# 如果是,那么该文件包含的代码块会被执行。
if __name__ == "__main__":
app.run_server(host='0.0.0.0', port=8050,debug=True)
myFunction.py
import numpy as np # 支持大型、多维数组和矩阵
# graph_objects相比express提供了更细粒度的控制,适合需要对图形进行复杂自定义的用户
import plotly.graph_objects as go
class abs_error(object):
def __init__(self, df, label):
self.df = df
self.label = label
self.df["error"] = self.df["model_gap"] - self.df["exp_gap"]
self.df["abs_error"] = abs(self.df["error"])
# 用plotly.graph_objects绘制散点图
def exp_mod_scatter_plotly(selected_df):
fig=go.Figure()
for label,df in selected_df.items():
x = [i for i in df["exp_gap"]]
y = [j for j in df["model_gap"]]
# 当 mode='markers' 时,每个数据点将以独立的标记进行绘制,而不是连接成线条
scatter = go.Scatter(x=x, y=y, mode='markers', name=label,marker=dict(size=5))
fig.add_trace(scatter)
#加对角线
diagonal_line = go.Scatter(x=[0,15],
y=[0,15],
name='Diagonal Line',
mode='lines',
line=dict(dash='dash', color='grey'))
fig.add_trace(diagonal_line)
#加标题和坐标轴含义
fig.update_layout(title=dict(
text='Scatter Plots Of True And Predicted Values For Selected DFT Methods', # 标题文本
x=0.5, # 标题相对于图表水平居中对齐
y=0.95 # 标题在图表上方
),
xaxis_title='exp_gap',
yaxis_title='model_gap',
legend=dict( # 也就是把图例放到图里面
x=0.1, # 将图例水平位置设置为图表宽度0.1倍
y=0.9 # 将图例垂直位置设置为图表高度的0.9倍
),
xaxis_range=[0, 15],# 这两句是把坐标轴的大小范围调整成一样
yaxis_range=[0, 15],
width=800, # 设置宽度为800像素,注意:散点图的画布大小不包含图表标题和横纵坐标标题
height=800 )# 设置高度为800像素
return fig
#将selected_df中的每一个数据集进行分组处理,返回一个新的数据集的集合
def bins_process(selected_df,bins):
counts={}
for label, df in selected_df.items():
# 返回一个与selected_df大小相同的数组,其中每个元素都是对应于selected_df中的值所属的区间的索引(从 1 开始)。如果某个值小于所有的 bins,则返回 0;如果大于所有的 bins,则返回 len(bins)即为边界值的个数,这里是4
digitized = np.digitize(df["abs_error"], bins)# 计算每个残差属于哪个区间(默认是左闭右开区间)
# 统计每个区间的数量,counts为一个数组,count[i] 表示输入数组中值为 i 的元素的数量,这里只有三个数据
count_bins = np.bincount(digitized)[1:] # 忽略第一个区间(digitized 为0的部分)
counts[label]=count_bins
return counts
# 直方图:将误差数据分组,并以直方图的形式展示。比较该模型对不同数据集的预测误差分布情况。
def Histogram_error_plotly(selected_df,bins):
counts=bins_process(selected_df,bins)
fig=go.Figure()
for label,count_bins in counts.items():
fig.add_trace(go.Bar(
x=[f'[{bins[i]}, {bins[i + 1]})' for i in range(len(bins) - 1)], #默认是左闭右开区间
y=count_bins,
name=label,
#marker=dict(color='blue')
))
fig.update_layout(
title=dict(
text='Prediction Error Distribution Comparison For Selected DFT Methods', # 标题文本
x=0.5, # 标题相对于图表水平居中对齐
y=0.95 # 标题在图表上方
),
xaxis_title='Bins Of Error value',
yaxis_title='Count Of Each Bin',
barmode='group', # 分组模式
showlegend=True # 这个参数控制是否在图表中显示图例(legend)
)
return fig
# 密度图:密度图是通过平滑直方图来估计数据的概率密度函数,并以连续曲线的形式展示数据分布的集中程度。密度图可以更直观地看出数据的峰值和分布的波动情况
def Density_error(selected_df):
fig = go.Figure()
for label, df in selected_df.items():
fig.add_trace(go.Histogram(
x=df["abs_error"],
# 一般情况下密度图不用设置y,因为y轴上的值将自动转换为该区间内的概率密度
histnorm='probability density', # 设置为概率密度图。整个图形下方的面积总和最终会等于 1
name=label,
opacity=0.3, # 指定图形元素为 60% 不透明
nbinsx=30 # 可以调整这个值来改变条形的数量,这一参数指定了 x 轴要被划分为多少个区间(即条形的数量),nbinsx=30 表示将残差数据的范围均匀划分为 30 个区间。
))
fig.update_layout(
title=dict(
text='Prediction Error Density Comparison For Selected DFT Methods', # 标题文本
x=0.5, # 标题相对于图表水平居中对齐
y=0.95 # 标题在图表上方
),
xaxis_title='Error value',
yaxis_title='Probability Density',# 概率密度并不是一个直接的概率值,而是一种描述数据分布的方式。“密度”就是在某个特定区间内的数据集中程度
barmode='overlay', # 重叠显示,barmode='overlay' 表示将不同数据集的条形图重叠显示
showlegend=True
)
return fig
二、网页展示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号