python 08-机器学习入门-Anaconda安装
一、机器学习中常用的包
-
NumPy:用于数值计算的包,提供了多维数组对象和一系列数学函数
-
Matplotlib:用于绘制图表的库,可以创建各种静态、动态和交互式的图表
-
Pandas: 提供了高性能、易于使用的数据结构和数据分析工具
-
Scikit-learn: 是Python重要的机器学习库。其包括分类、回归、降维和聚类四大机器学习算法,还包括了特征提取、数据处理和模型评估三大模块
二、Anaconda安装
(1)为什么选择Anaconda?
-
Anaconda是一个开源的Python发行版本,其最大的特点在于集成了大量的科学计算包及其依赖项,总计超过180个,涵盖了数据分析、机器学习、深度学习、数据可视化等多个领域,为科研人员提供了强大的支持。此外,Anaconda还包含了一个名为conda的包管理器,使得用户可以轻松地安装、更新和管理这些包。Anaconda还可以创建和管理多个独立的Python环境,使得在不同项目中使用不同版本的Python和库变得简单。
-
Miniconda是Anaconda的一个轻量级版本,只包含conda和Python本身,但同样可以通过conda安装和管理其他包。
-
PyCharm是一款由JetBrains开发的Python集成开发环境(IDE),提供了代码编辑、调试、项目管理、版本控制等多种功能,是一个功能强大的工具,特别适合专业开发人员使用。PyCharm适合那些需要强大IDE支持的专业开发者,它提供了丰富的功能,包括代码自动完成、调试器、单元测试工具等,使得代码开发高效和便捷。
-
Anaconda自带python解释器,而PyCharm不含python解释器,需要另外下载安装。
(2)安装
官网下载地址:https://www.anaconda.com/download/success


-
Add Anaconda to my PATH environment variable:
意思是将Anaconda添加到系统的环境变量中,这样你就可以在任何目录下使用Anaconda提供的命令,比如conda、jupyter等 -
Register Anaconda as my default Python:
意思是将Anaconda的Python设置为系统默认的Python解释器 -
clean the package cache upon completion:
在Anaconda安装过程中,可以选择在安装完成后清除包缓存。其作用是在安装过程结束后删除下载的临时包文件,以释放磁盘空间。

因为我之前已经下载过python解释器,并且配置过环境变量,因此想要把Anaconda的Python设置为默认的解释器,就需要手动的把原来的环境变量配置改成Anaconda的Python的地址,如下
原来:

修改后(记得保存):

三、Anaconda具体使用
(1)Jupyter Notebook
安装完后运行命令jupyter notebook
Jupyter Notebook提供了丰富的命令和操作,以便用户可以更加高效地创建、编辑和运行代码。
.ipynb文件不仅包括了代码,也包括了代码结构以及输出,而.py文件只有源代码

接着自动弹出这样一个网页:


创建一个文件夹用于编写python代码:

改名字为HelloWorld:

可以在里面编写代码:

(2)导入数据集合dataset
Kaggle:是一个国际知名的数据科学竞赛平台,现为Google Cloud的一部分。该平台主要为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的环境
注册一个kaggle账号,出现验证码加载不出来的提示,解决办法参考:https://blog.csdn.net/qq_41835735/article/details/131413062?spm=1001.2014.3001.5502
接着找到一个数据集并下载:


解压后将数据文件和HelloWorld文件放在一起:

接着导入pandas包,用其中的方法来读取这个数据集文件:

(3)pandas的一些用法
- 数据集.shape:
对于 DataFrame,shape 属性会返回一个元组,其中第一个元素是行数,第二个元素是列数。
对于 Series,shape 属性会返回一个元组,其中只有一个元素,即序列的长度。

- 数据集.describe() :
用于生成 DataFrame 或 Series 的描述性统计摘要。这个方法默认会计算数值型列的一些常用统计量,包括计数(非空值数量)、平均值、标准差、最小值、四分位数(25%、50%、75%)和最大值。
如果 DataFrame 中包含非数值型数据,这些列将被默认忽略,但可以通过设置include参数来包含它们,或者使用exclude参数来排除某些类型的列。

(4)jupyter notebook快捷键
选中某一个编辑框,按escape键,就会从edit模式转换到comand模式


不同模式下的快捷键不同
查看快捷键:

比较常用的Jupyter Notebook shortcuts for Windows
- Command Mode Shortcuts (press Esc to enter)
Enter: Switch to Edit mode.
A: Insert a new cell above.
B: Insert a new cell below.
双击D: Delete the selected cell.
Z: Undo the last cell deletion.
Y: Change the cell type to Code.
M: Change the cell type to Markdown.
Ctrl + Shift + H: Show keyboard shortcuts.
- Edit Mode Shortcuts (press Enter to enter)
Ctrl + Enter: Run the current cell.
Shift + Enter: Run the current cell and move to the next cell.
Alt + Enter: Run the current cell and insert a new cell below.
Ctrl + Z: Undo the last action.
Ctrl + Y: Redo the last undone action.
Tab: Code completion or indent.代码补全或缩进
Shift + Tab: Tooltip for the object under the cursor.显示当前光标所在位置对象的工具提示,这通常用于快速查看对象的
类型、方法、属性等信息
- 其他
Ctrl + S: Save the notebook.
Ctrl + Shift + -: Split the current cell into two at the cursor position.
四、一个机器学习的例子
主题:通过已有的用户常听的歌的数据,猜测用户推荐ta可能会购买的音乐
步骤:
1.Import The Data
mosh老师提供的数据music.csv:(只是一个假设,不代表真实情况)


2. Clean the Data
3. Split the Data into Training/Test Sets
前两列是输入,genre时输出,需要我们预测的对象,所以拆分原表,得到一个只有输入信息的表x和输出信息的表y:


4. Create a Model
5. Train the Model
6. Make Predictions
接下来利用机器学习的算法建一个模型,这里需要用到决策树的方法。

7. Evaluate and lmprove

再运行一次,精确度变成了0.5:

实际上精确度不一定有这么大,因为数据过小,还会有可能更低。
每一次需要用到这个预测功能时,都得重新训练模型,做重复性的工作。因此可以进行模型的持久化,将训练好的模型存起来,要用的时候再调出即可:
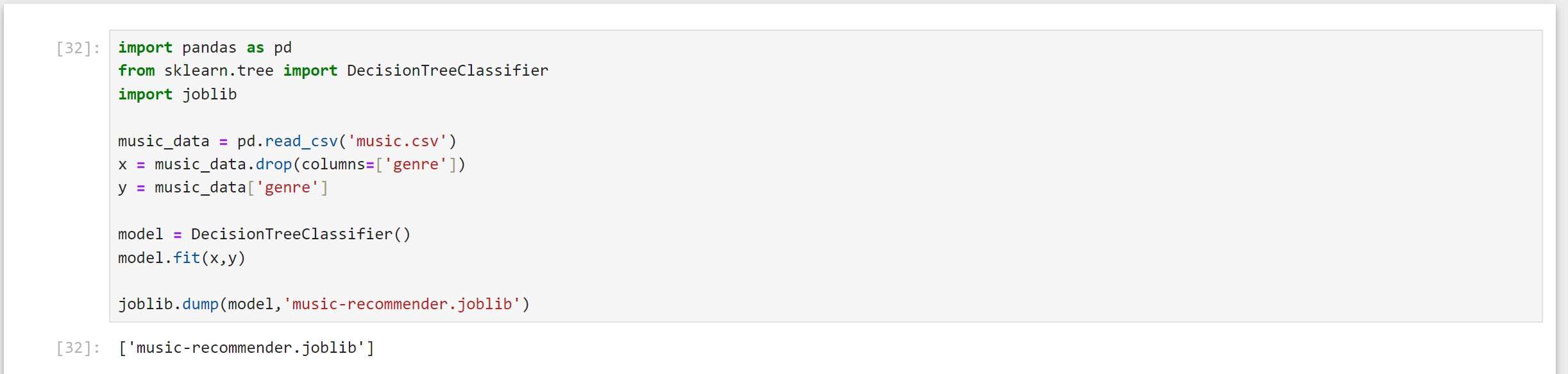
下次使用时调用即可:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)