python基础语法02
比较完整的教程:https://www.runoob.com/python3/python3-tutorial.html
1.运算符号
(1)运算符号
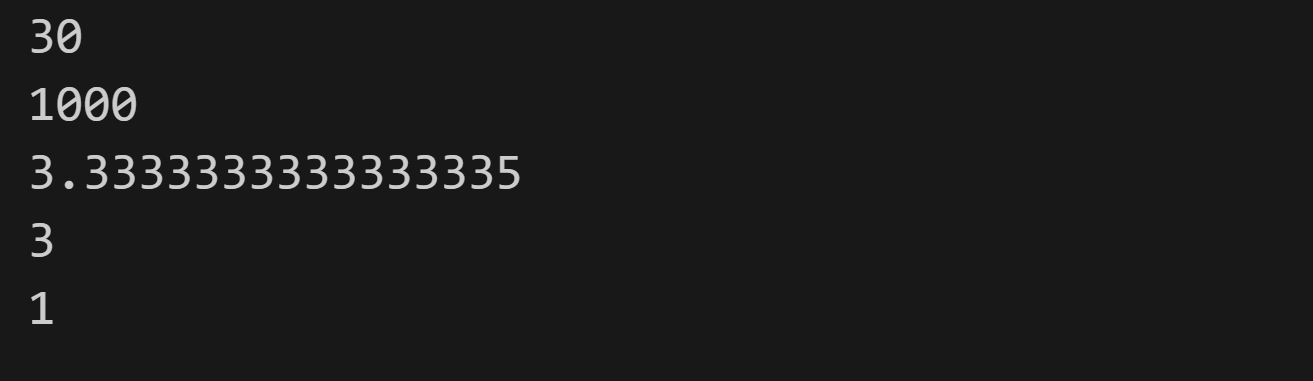
print(10*3)
print(10**3) # 10的3次方
print(10/3)
print(10//3) # 取整数部分
print(10 % 3) # 取余
(2)优先级
-
3*1**3 表达式输出结果为3 ,因为乘方拥有更高的优先级
-
优先级顺序为 NOT、AND、OR
(3)round()函数
-
round()函数的四舍五入规则是基于银行家舍入法(Bankers’ rounding),也称为偶数舍入。如果要舍弃的数字是5,而前面的数字是偶数,则舍入到最接近的偶数。如果前面的数字是奇数,则向上舍入到最接近的偶数。
-
对于负数,round()函数采用的是“远离零的方向舍入”(round away from zero)的方式
print(round(2.5)) # 2
print(round(3.5)) # 4
print(round(-2.5)) # -2
print(round(-3.5)) # -4
# 保留两位小数
print(round(1.7269, 2)) # 1.73
print(round(1.7259, 2)) # 1.73
print(round(1.7359, 2)) # 1.74
print(round(1.7249, 2)) # 1.72
print(round(1.7239, 2)) # 1.72
print(round(1.7349, 2)) # 1.73 为什么不是1.74呢
'''
答:print(round(1.7349, 2)) 的结果不是1.74,而是1.73。
这是因为Python的round函数在处理浮点数时,采用的是标准的四舍五入规则,
但在实际应用中,浮点数的精度问题会导致四舍五入的结果与预期有所差异。
具体来说,浮点数的精度问题使得1.7349在计算机内部的表示可能略小于实际值,
导致在进行四舍五入时,根据标准的四舍五入规则,应该舍去的是小数点后第三位数字3,
因此结果为1.73而不是1.74。
这种精度问题在计算机科学和数学中是一个普遍存在的问题,
因为浮点数在计算机内部的表示是近似的,而不是精确的。
尽管现代计算机和编程语言已经做了很多优化来减少这种误差,
但在某些情况下,尤其是涉及到金融计算或需要高精度的领域,
这种误差可能会成为问题。因此,对于需要高精度计算的场景,
可能需要使用特定的数据类型或库来处理浮点数,以确保计算的准确性
'''
解决办法:
使用decimal()函数,专门用于高精度的浮点运算
import decimal
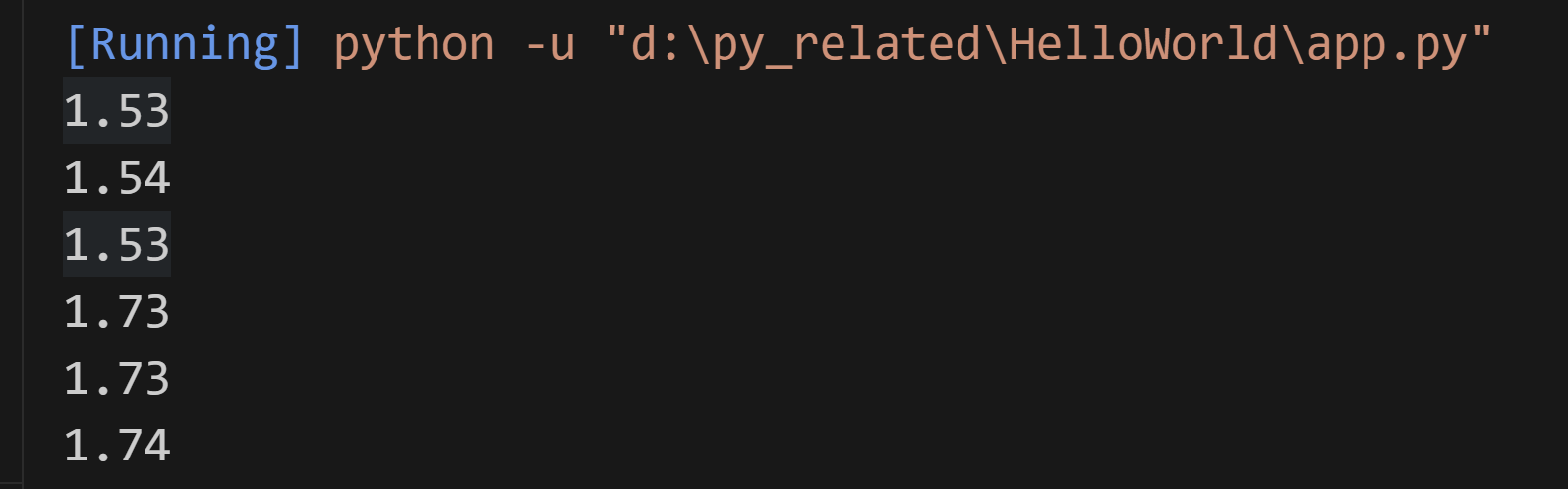
print(round(1.535, 2)) # 1.53
print(round(decimal.Decimal('1.535'), 2)) # 1.54
print(round(decimal.Decimal('1.5346'), 2)) # 1.53 ???为什么不是1.54呢?
print(round(1.7349, 2)) # 1.73
print(round(decimal.Decimal('1.7349'), 2)) # 还是1.73 为什么不是1.74呢???这里还是没搞明白
print(round(decimal.Decimal('1.735'), 2)) # 1.74
import math
print(abs(-2.9)) # 2.9 可以是整数,浮点数,复数
print(math.fabs(2.9)) # 2.9 math.fabs(x)方法也是返回x的绝对值,但是返回的是浮点型的值。
print(math.ceil(2.2)) # 3 向上取整
x = input("x:") # input函数输入的是字符串
y = int(x)+1 # 这里需要强制转换
print(y)
#精度问题
>>> print(0.1 + 0.2 == 0.3)
False
>>> print(0.1+0.2)
0.30000000000000004
#解决办法
>>> import math
>>> math.isclose(0.1 + 0.2, 0.3)
True
2.截取[]的注意点和易错点

3.自定义函数、常见函数 ord() zip()
(1)定义函数
# 没有return语句则默认是返回None
def greet(name):
print(f"Hi {name}")
greet("kakafa")
# 另一种方式
def get_greeting(name):
return f"Hello {name}"
print(get_greeting("kakafa"))
不定长参数:
-
参数列表,参数带*,表示可以接受输入多个参数,参数是以元组的形式存储的。
-
参数列表,参数带,表示可以接受输入多个字典类型的参数,以字典的形式**存储参数。
-
**参数类型排最后,*参数类型次之,单参数排最前面(def greet(name, age=30, *numbers, **person)
def sum_num(*numbers):
print(numbers)
sum_num(1, 2, 3, 4, 5) #(1, 2, 3, 4, 5)
def save_user(**person):
print(person)
save_user(id=1, name="Sam", age=10)
#{'id': 1, 'name': 'Sam', 'age': 10}
(2)常见函数
- ord()函数用于返回一个字符的Unicode码点,即该字符在Unicode编码表中的数值。unicode包括ASCII
>>> ord("a")
97
>>> ord("0")
48
- zip()函数:用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表
>>> a=[1,2,3]
>>> b=[11,22,33]
>>> zip(a,b) # 元素个数与最短的列表一致
<zip object at 0x00000217985B43C0>
>>> zipped=list(zip(a,b))
>>> print(zipped)
[(1, 11), (2, 22), (3, 33)]
>>> list(zip("abc",a,b)) #多个也可以
[('a', 1, 11), ('b', 2, 22), ('c', 3, 33)]
# 与 zip 相反,zip(*) 可理解为解压,返回二维矩阵式
>>> aa,bb=zip(*zip(a,b))
>>> list(aa)
[1, 2, 3]
>>> list(bb)
[11, 22, 33]
4.循环语句的else用法
当for循环在没有提前退出的情况下,即正常结束时,else块中的代码会被执行
# 这里是提前退出的情况,因此不用执行else语句
leaders = ["Elon", "Tim", "Warren", "Yang"]
for i in leaders:
if i == "Yang":
print("Yang is a leader!")
break
else:
print("Not found Yang!")
# else部分是用于在循环正常结束时执行特定的代码块
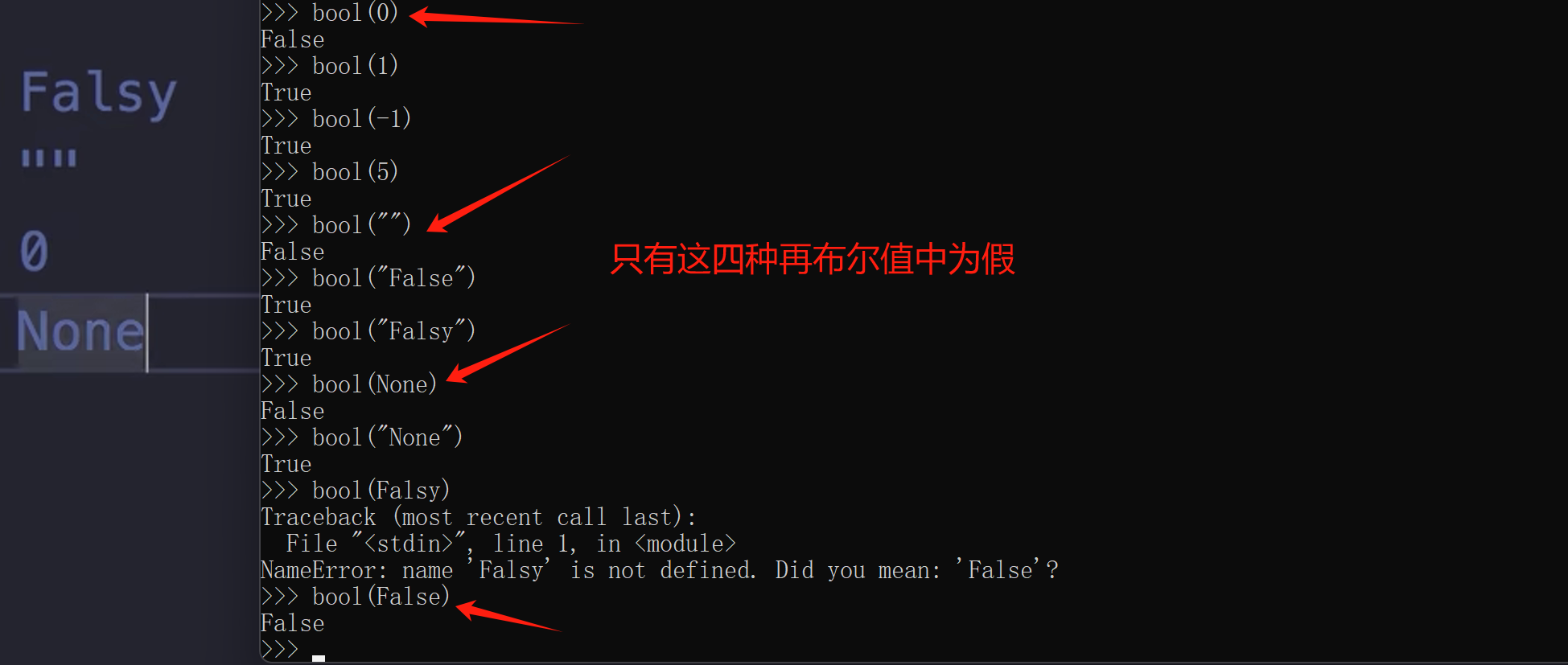
5.数据类型特点
python中除了Int(整型)Float(浮点型)Bool(布尔型)Str(字符串)
还有 None(空值) List(列表)Tuple(元组) Dict(字典)Set(集合)bytes,range等类型
>>> print(type(range(5)))
<class 'range'>
>>> print(type(5))
<class 'int'>
# bytes数据类型 表示字节序列 不可变 与“字符串”类型类似,“字节串”是把多个“字节”串在一起
>>> x=b'hello'
>>> print(type(x))
<class 'bytes'>
# 或者这样定义
>>> y=bytes([1,2,3,4,5])
>>> y
b'\x01\x02\x03\x04\x05'
>>> print(y)
b'\x01\x02\x03\x04\x05'
-
可迭代的数据类型 iterable
序列:str、bytes、tuple、list
非序列:dict、set
其它:dict_keys、dict_values、dict_items -
可变的数据类型
序列:list
非序列:dict、set -
不可变的数据类型
序列:tuple、str、bytes
非序列:int、float、complex、bool、string、None
问:如何理解不可变的数据类型?
答:以整数位例,一个整数的值一旦确定,就不能改变。如果需要表示一个不同的整数值,必须创建一个新的整数对象。
这是因为整数对象在内存中的位置(地址)不会改变,而python变量实际上是一个指针,指向地址,因此不可变。如果它的值发生变化,就需要通过创建并分配一个新的内存位置来保存新的值,因此地址会改变。
参考链接:https://blog.csdn.net/fox_kang/article/details/134574514
6.enumerate
enumerate功能:将一个可遍历的数据对象(如列表、元组、字典和字符串)组合成一个索引序列,同时列出数据下标和数据(索引 值),一般配合for循环使用。
letters = ["a", "b", "c"]
for letter in letters:
print(letter)
'''
a
b
c
'''
for letter in enumerate(letters):
print(letter)
'''
(0, 'a')
(1, 'b')
(2, 'c')
'''
for letter in enumerate(letters):
print(letter[0], letter[1])
'''
0 a
1 b
2 c
'''
for index, letter in enumerate(letters): #直接在for循环中就拆解这个索引序列
print(index, letter)
'''
0 a
1 b
2 c
'''
7.lambda、sort()、map()、filter()
- 不使用lambda

- 使用lambda
# 定义一个list
items = [
("product1", 10),
("product2", 9),
("product3", 8)
]
# def sort_item(item):
# return item[1]
items.sort(key=lambda item: item[1]) # lambda 参数:返回值
print(items)

sort()和sorted()区别:https://blog.csdn.net/rr8f2haQf/article/details/137654783
- 还可以用map()函数
# map函数用法
# map(function, iterable, ...) iterable: 一个或多个序列
>>> list(map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]))
[3, 7, 11, 15, 19]
# 定义一个list
items = [
("product1", 10),
("product2", 9),
("product3", 8)
]
# map函数:Python 2.x 返回列表; Python 3.x 返回迭代器。
list_t = list(map(lambda item: item[1], items))
print(list_t)
-
filter函数
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
# 定义一个list
items = [
("product1", 10),
("product2", 9),
("product3", 8)
]
hign_prize = list(filter(lambda item: item[1] > 8, items))
print(hign_prize)

- 前面的表达还可以更加简略:
prize = [item[1] for item in items]
print(prize)
# [10, 9, 8]
prize = [item for item in items if item[1] > 8]
print(prize)
#[('product1', 10), ('product2', 9)]
prize2 = [item[1] for item in items if item[1] > 8]
print(prize2)
# [10, 9]
8.array
(1)array
-
array是一种用于存储和操作多个相同类型元素的容器。
-
与list相比,array在存储和操作大量数值型数据时更为高效。array在内存中以连续的方式存储数据,占用的内存空间更小。
from array import array
# typecode是数组元素的类型码,i代表有符号整型
numbers = array('i', [1, 2, 3])
print(numbers)
for x in numbers:
print(x)

- 增加元素:使用append()方法向array中添加一个元素,或使用extend()方法向array中添加多个元素。
- 删除元素:使用remove()方法可以删除第一个匹配的元素。
- 修改元素:通过索引直接修改array中指定位置的元素。
- 查找元素:使用index()方法可以得到指定元素的索引,使用count()方法可以计算指定元素在array中的个数。
9.推导式、生成器(Generator)区别
list推导式
new_list = [x*x for x in range(31) if x%3==0]
print(new_list) # 输出 [0, 9, 36, 81, 144, 225, 324, 441, 576, 729, 900]
#嵌套
list1 = [[1,2,3],[4,5,6],[7,8,9]]
new_list = [x for y in list1 for x in y if x%2==0]
print(new_list) # 输出 [2, 4, 6, 8]
dict推导式
new_dict = {x:x*x for x in range(11) if x%2==0}
print(new_dict) # 输出 {0: 0, 2: 4, 4: 16, 6: 36, 8: 64, 10: 100}
set推导式
new_set = {x for x in 'abcdsfabdcad' if x not in 'abc'}
print(new_set) # 输出 {'f', 'd', 's'}
元组推导式和生成器
# 不使用tuple()转换,输出的是生成器对象
new_tuple = (x for x in range(31) if x % 2 == 0)
print(new_tuple)
# 输出 <generator object <genexpr> at 0x000001A8738FACF0>
# 使用tuple()转换为元组
new_tuple = (x for x in range(31) if x % 2 == 0)
print(tuple(new_tuple))
# 输出 (0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30)
问1:什么是生成器?
答1:
-
生成器(Generator)是一个特殊的迭代器(Iterator),它能够用一种懒加载(Lazy Evaluation)的方式按需一次性生成一个元素,而不是在内存中创建并存储整个序列。
-
生成器是一种特殊的数据结构,一种特殊的数据类型,用于生成一系列的值。
问2:推导式和生成器的区别?
答2:
-
运行机制:
列表推导式会立即生成一个完整的列表。这意味着,当你使用列表推导式时,它会一次性生成所有满足条件的元素,并将它们存储在一个列表中。例如,list1 = [x for x in range(10)] 会生成一个包含0到9的列表[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]。
生成器表达式则是惰性计算的,它不会一次性生成所有值,而是在需要时才生成值。生成器表达式使用圆括号而不是方括号,例如,(x for x in range(10)) 生成一个生成器对象,这个对象可以按需产生值,而不是一次性生成一个列表。
-
内存使用:
列表推导式会占用大量内存,因为它需要一次性存储所有生成的元素。这对于处理大数据集可能会成为问题,因为内存可能会被耗尽。
生成器表达式则更加内存友好,因为它按需生成值,并在生成值后立即释放内存,从而减少了内存的使用。这对于处理大数据集或无限序列特别有用。
-
应用场景:
列表推导式适用于当你需要立即获取一个完整的列表,并对该列表进行进一步的操作或遍历时。
生成器表达式则更适合于处理大数据集、惰性计算场景、优化迭代器、以及实现协程和异步编程模型等,其中内存使用和效率是关键考虑因素。综上所述,如果你需要一个完整的列表并进行一次性处理,列表推导式是更好的选择。如果你需要处理大数据集、优化内存使用或实现惰性计算,那么生成器表达式更合适。
10.解包unpacking
# unpacking
numbers = [1, 2, 3]
print(numbers)
print(1, 2, 3)
# unpacking
print(*numbers)
# 输出
# [1, 2, 3]
# 1 2 3
# 1 2 3

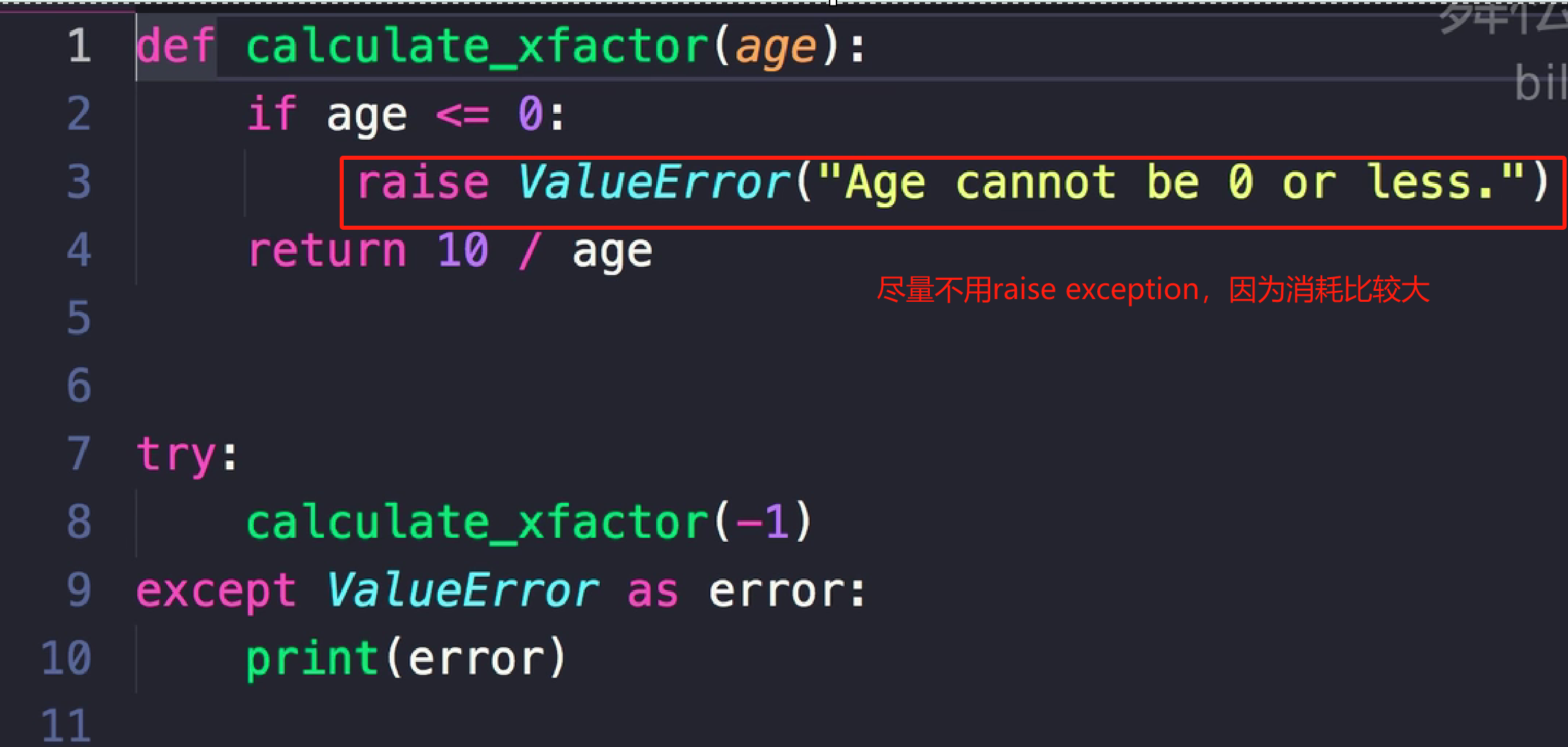
11.异常exception
例子:
age = int(input("age:"))



try:
age = int(input("age:"))
xfactor=10/age
except ValueError: #两种异常
print("You didn't enter a value age.")
except ZeroDivisionError:
print("Age cannot be 0.")
else:
print("No exception were thrown.")
#异常后执行语句相同,则可以合并
try:
age = int(input("age:"))
xfactor=10/age
except (ValueError,ZeroDivisionError):
print("You didn't enter a value age.")
else:
print("No exception were thrown.")
try:
file=open("app.py") #文件使用完需要关闭
age = int(input("age:"))
except ValueError:
print("You didn't enter a value age.")
else:
print("No exception were thrown.")
finally:
file.close() #无论有无异常 都会执行这个
#还可以这么写
#with语句创建了一个上下文环境,open('app.py', 'r')表达式执行后的文件对象被赋值给变量file。
# 当with代码块执行完毕时,文件自动关闭
try:
with open('app.py', 'r') as file:
content = file.read()
print(f"文件内容:{content}")
#这里还可以写其他语句,不过不属于with代码块中,注意缩进位置
except ValueError:
print("You didn't enter a value age.")
else:
print("No exception were thrown.")
12.魔术方法、类的私有属性、修饰器
(1)魔术方法
-
魔法方法(Magic Method)是python内置方法,格式为:(双下划线)方法名(双下划线)
-
不需要主动调用,存在的目的是为了给python的解释器进行调用,几乎每个魔法方法都有一个对应的内置函数,或者运算符,当我们对这个对象使用这些函数或者运算符时就会自动调用该类中的对应魔法方法(需要提前在该类中实现魔法方法的重载才能调用,否则会报错 eg:TypeError:'>'not supported between instance of '类名' and '类名',因此需要提前在类中实现__gt__()即为greater than的魔法方法)(并不是实现每一个魔法函数才能使用,eg:当我们实现了greater than则less than就不用显式的写出来,python会自动找出lt应该怎么做)
-
Python中的魔法方法类似于Java中的重载?但是也不太一样,Python中的魔法方法可以理解为:对类中的内置方法的重载。(重载(Overloading)和重写(Overriding),重载:方法名相同,参数个数或类型不同,重写是继承里的概念);但是与java不同的是,这些方法不是通过类定义来直接控制的,而是通过Python解释器的特殊处理来实现其功能。
(2)私有属性
-
Python中的“私有”属性并不是真正的私有,而是一种命名上的约定,它依赖于Python的名称改写机制(name mangling)来实现一定程度的封装,只是一种提醒防止意外访问,实际上如果非要访问还是可以访问的。
-
在Python中,通常约定两个下划线开头的属性是私有的,类外部可以通过
_类名__私有属性(方法)名访问私有属性(方法) -
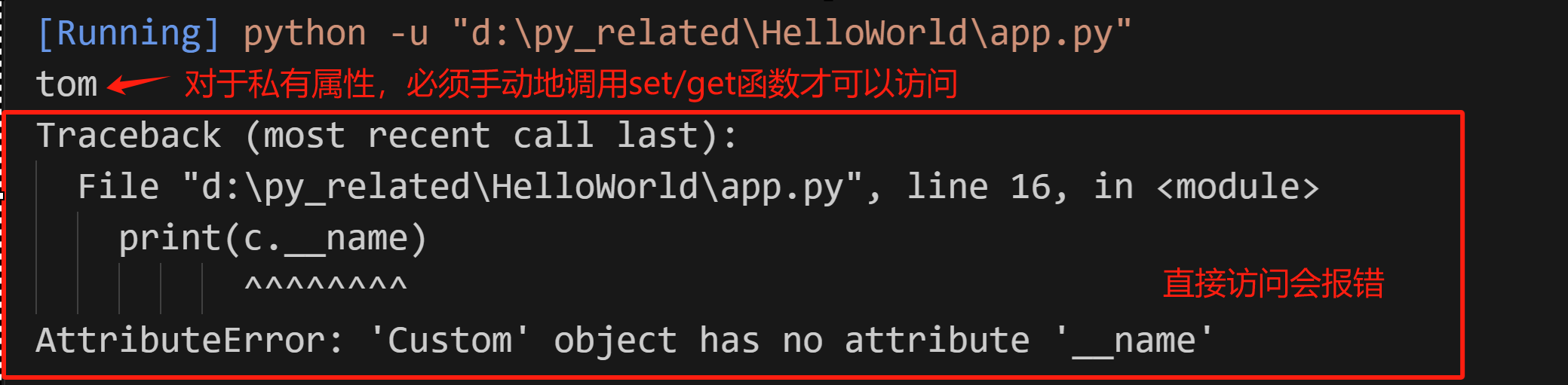
私有属性不能直接从类的外部访问它们。如果尝试这样做,Python会抛出一个AttributeError。类似于java类中的私有属性,可以自己编写set/get方法来访问和修改
class Custom(object):
def __init__(self, name):
self.__name = name
def get_name(self):
return self.__name
def set_name(self, value):
self.__name = value
c = Custom('tom')
print(c.__name) #报错

class Custom(object):
def __init__(self, name):
self.__name = name
def get_name(self):
return self.__name
def set_name(self, value):
self.__name = value
c = Custom('tom')
print(c.get_name())

-
在python中还用property函数来私有化属性。property()函数是一个强大的内置函数,用于创建可管理的属性。property函数并不直接实现私有属性,而是通过getter和setter方法对属性进行封装,从而实现类似私有属性的效果
-
(仍然需要在属性前加上两个下划线才能定义属性为私有)property函数用法的不同点在于:使用了property()之后,就不用手动调用get/set函数了,只要直接访问property对象就可以自动帮我们调用get/set函数(这个property对象相当于一个中介,代理我们访问私有属性的作用)
使用property函数前:
class Custom(object):
def __init__(self, value_init):
self.__name = value_init # 仍然需要在属性前加上两个下划线才能定义属性为私有
def get_name(self):
return self.__name
def set_name(self, value):
self.__name = value
c = Custom('tom')
print(c.get_name()) # 必须使用get函数才可以访问
print(c.__name) # 无法直接访问或修改__name属性本身
使用property函数后:
class Custom(object):
def __init__(self, value_init):
self.__name = value_init #仍然需要在属性前加上两个下划线才能定义属性为私有
def get_name(self):
return self.__name
def set_name(self, value):
self.__name = value
name_p = property(get_name, set_name)
c = Custom('tom')
print(c.name_p) #不用写c.get_name()
c.name_p = "carol" #不用写c.set_name("carol")也可以直接通过name_p对象直接赋值了
print(c.name_p) #直接通过name_p对象访问私有属性(原理是name_p对象帮我们调用了get/set函数)

(3)修饰器
- 修饰器可以简化代码,类似java里的注解
例如:上述的property函数可以这样写:
class Custom(object):
def __init__(self, value_init):
self.__name = value_init
@property
def name_p(self):
return self.__name
@name_p.setter
def name_p(self, value): #如果setter的这个函数没有定义,那么__name属性iu是个只读属性
self.__name = value
# name_p = property(get_name, set_name)
c = Custom('tom')
print(c.name_p)
参考链接:
https://www.runoob.com/python/python-built-in-functions.html
https://blog.csdn.net/sinat_41752325/article/details/126424392
https://blog.csdn.net/qq_62789540/article/details/127416850

 浙公网安备 33010602011771号
浙公网安备 33010602011771号