
java学习day25---(单例集合Set/散列表/hashSet/TreeSet)
一、单列集合
Set接口
1.没有索引 2.存取无序 3.元素不能重复
可变参数
方法要操作的数据是统一数据类型,可以使用一个特殊的参数接受这些参数,如:要求几个数的和,这时候不知道是多少个数,就很难定义方法的参数个数,这时候引入可变参数就解决了
语法:类型... 变量名 如:int... arr
可变参数就会以变量名定义一个数组来存储这些参数
public staic int getSum(int... arr){
int sum=0;
for(int i:arr){
sum+=i;
}
return sum;
}
可变参数必须作为参数列表的最后一个参数,不然编译会报错
HashSet类
hashCode()方法
继承自Object类,返回一个对象的哈希码值
没有重写的hashCode方法,返回的是对象的地址值
hashCode值不相同,两个对象就不相同
hashCode值相同,两个对象就不一定相同
Set去重第一层:
存入元素时,使用hashCode()算出列表里对象的值,和要插入对象的值对比,不相同就代表没有重复的,直接插入;相同,就使用equals()进一步对比
对象的类,没有重写hashCode方法,就不能完成去重
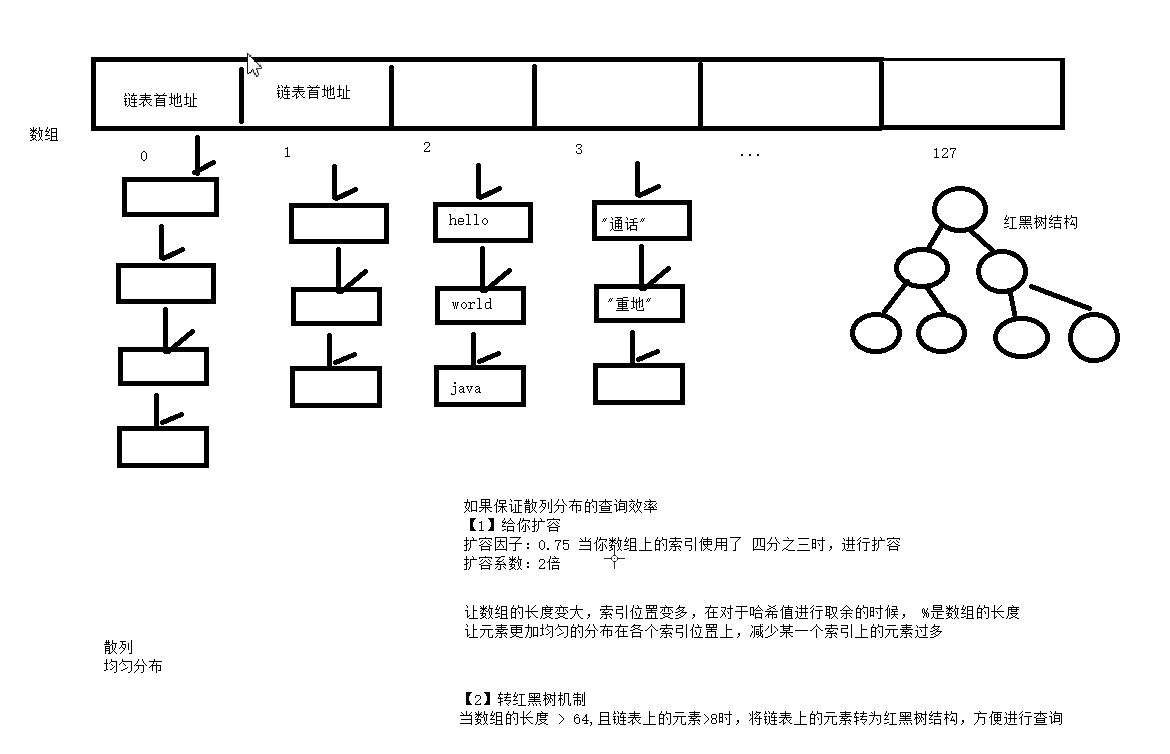
散列表(哈希表)
创建一个数组,存储的都是同类型的数组的首地址,一般初始长度8个。每个地址都使用链表的结构,存储一系列的数据。
1.每当有元素要存入时,使用这个元素的哈希值取余%这个地址数组的长度,进入对应的索引
2.取对应索引的地址值,对比这个地址值的所有元素与要存入元素的哈希值,不相同就直接存入,相同就调用equals()对比,大大减少了对比哈希值的次数
3.存入的顺序是无法保证的,取出的时候顺序与存入顺序不一样
4.当列表里的元素过多时,就会进行扩容,一般扩容数组长度的2倍,扩容后会对元素进行重新排列
5.当数组长度大于64并且元素大于8时,就会把链表结构换成红黑树结构
Set去重第二层:优化了查询时间
LinkedHashSet类
HashSet的子类,具备可迭代的顺序,但是底层依然是无序的
使用一个外部的双向链表记录存入的顺序,取出的时候就按照这个链表的顺序取出,就实现了存入取出顺序一致。但底层散列表依然是无序的
TreeSet类
可以根据集合中,元素的某个条件排序
存储结构是:红黑树
自然排序:在集合中元素的类的compareTo方法中重写排序
这个类要implements(实现) comparable类
根据返回值的的正负决定排序方式
正数就把当前的排到后面,负数就把当前的排到前面
this在前,o在后时升序
public int compareTo(类型 o){
return 0;
}
//升序this.属性-o.属性
//降序o.属性-this.属性
比较器排序:在创建集合时,提供构造函数的比较对象来排序
排序规则在别的类中,这个类实现了Compattor类的compareTo方法
TreeSet tree=new TreeSet<>(类)
自然排序和比较器排序同时存在时,比较器优先
比较器配合匿名内部类使用!
@自然排序:用Comparable类
@比较器排序:用Compartor类

 浙公网安备 33010602011771号
浙公网安备 33010602011771号