梯度下降法
根据维基百科[1]的定义,梯度下降(Gradient Descendent, GD) 法是一阶迭代式优化算法(First-Order Iterative Optimization Algorithm)。
我们首先举一个机器学习的问题:某地的房价与房地面积和卧室的数量之间成如下表的关系:
房子面积(平方英尺) | 卧室数 | 价格(千美元) |
2104 | 3 | 400 |
1600 | 3 | 330 |
2400 | 3 | 369 |
1416 | 2 | 232 |
3000 | 4 | 540 |
根据这个已知数据,我们要通过分析上面的数据学习出一个模型(即价格和房子面积+卧室数之间的关系),用于预测其它情况(比如面积2000,卧室数5)的房价。这个问题我们可以看作是一个概率里的回归问题,属于个机器学习的问题。

Fig.1:一维输入数据拟合示例

Fig.2: 表中数据plot后一个视角

Fig.3: 表中数据plot后另一个视角
对于一维的输入数据,如Fig.1所示,我们需要的拟合函数实际上表现为一条直线。而对于二维的输入数据,我们需要得到的拟合函数实际上是一个平面。但从Fig.2和Fig.3能看出,直接plot出的数据并不是一个平面(Fig.3中能看出有点接近平面),也可以说输入的三个向量数据构造成了一个接近平面(线性)的函数。我们的目的实际上是要从数据中进行优化,得到一个平面。
由于我们已经有了已知的数据,我们实际上是要从已知数据对未知数据的值进行预测,因此属于有监督学习范畴。
问题先放一下,我们现在来看看一些机器学习中的一些概念:
表示"输入"变量('input' variables),也称为特征(features)
***我们不使用特征值这样的说法,为了避免和eigenvalue(中文翻译为特征值)这个概念混淆。***
表示"输出"变量('output' variables),也称为目标值(target)
一对成为一个训练样本(training example),用作训练的数据集就是一组个训练样本 ,被称为训练集(training set)
***为避免混淆,本文开始启用代表样本数量,代表维度。***
表示输入变量的取值空间,表示输出变量的取值空间。那么就是训练得到的映射函数,对于每个取值空间的取值,都能给出取值空间上的一个预测值。函数这里实际做出了假设(hypothesis),即假设函数能够对做出有效映射。

Fig.4: 机器学习基本框架
对于这个问题,当预测值为连续值时,则有监督学习问题是回归(regression)问题;预测值为离散值时,则为分类(Classification)问题。
回归及问题:
对于线性回归问题,先简单将表示为的线性函数。我们用,.. 去描述特征里面的分量,比如=房子面积,=卧室数量,等等,我们可以做出一个估计函数:
其中,称为参数(parameters) ,也叫做权重(weights),参数决定了到的射映空间。
在这儿的意思是调整feature中每个分量的影响力,就是到底是房子面积更重要还是卧室数量更重要。用来表示截距项(intercept term),我们就可以用向量的方式来表示了:
注意这里的代表特征的维度数量,上例中房子面积和卧室数各为一个维度。我们还应该再注意一点,的取值范围从0开始,如果我们将此公式做出转换,利用上面的例子中二维输入数据,我们实际得到: ,如果令
有了训练集,如何通过学习得到参数?
常用的一种方法,让预测值尽量接近真实值,定义成本函数(cost function):
这个错误估计函数是去对的估计值与真实值差的平方和作为错误估计函数,前面乘上的是为了在求导的时候,这个系数就不见了。
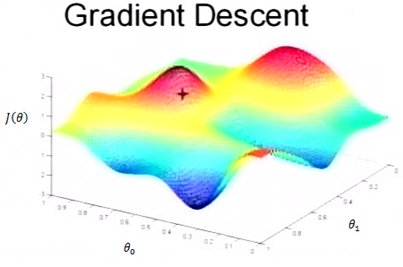
Fig.5是一个表示参数与成本函数的关系图,红色的部分是表示有着比较高的取值,我们需要的是,能够让的值尽量的低。也就是深蓝色的部分。,表示向量的两个维度。
在上面提到梯度下降法的第一步是给给一个初值,假设随机给的初值是在图上的十字点。然后我们将按照梯度下降的方向进行调整,就会使得往更低的方向进行变化,如图所示,算法的结束将是在下降到无法继续下降为止。

当然,可能梯度下降的最终点并非是全局最小点,可能是一个局部最小点,可能是下面的情况:

上面这张图就是描述的一个局部最小点,这是我们重新选择了一个初始点得到的,看来我们这个算法将会在很大的程度上被初始点的选择影响而陷入局部最小点
注意,更新是对所有的值,即各个维度同时进行。被称作学习率(learning rate),也是梯度下降的长度,若取值较小,则收敛的时间较长;相反,若取值较大,则可能错过最优值。
假设我们只有一个训练样本(注意,这里代表输入特征,是个向量,在我们例子中有房子面积和卧室数两个维度;代表输出,一般是个数值),此时,求偏导项得到:
下面是更新的过程,也就是会向着梯度最小的方向进行减少。表示更新之前的值,后面的部分表示按梯度方向减少的量,学习率表示每次按照梯度减少的方向变化多少。按照以下式子更新的值:
倒三角形表示梯度,按这种方式来表示,就不见了,看看用好向量和矩阵,真的会大大的简化数学的描述啊。
- https://spin.atomicobject.com/2014/06/24/gradient-descent-linear-regression/

