
spark学习中一些小问题---1
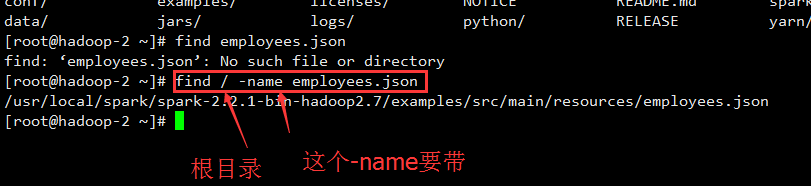
1.linux文件查找命令。这个很关键
find / -name employees.json
2.hdfs命令上传整个文件夹或文件
hadoop dfs -put /home/root/apache-hive-1.2.1-bin/lib/ /home/root/apache-hive-1.2.1-bin/
将lib整个文件夹包括文件夹下面的所有文件上传到hdfs对应的目录下。
3.Output directory hdfs://hadoop:8010/user/root/output already exists 问题解决
出现这个问题,啥也不用说,先把HDFS中的输出目录干掉: hadoop fs -ls -R:可查看目录。 //显示文件夹,文件和文件夹内的所有内容 hadoop fs -ls //显示文件和文件夹 hadoop fs -rmr output:干掉输出文件。 MapReduce执行是不允许输出目录存在的,自动创建!
4.添加文件到hadoop集群中
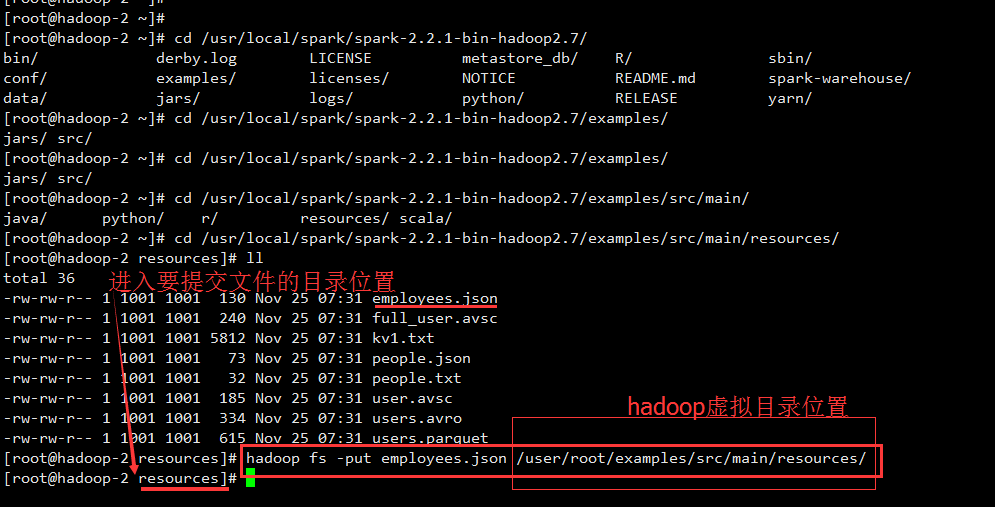
hadoop fs -put employees.json /user/root/examples/src/main/resources/
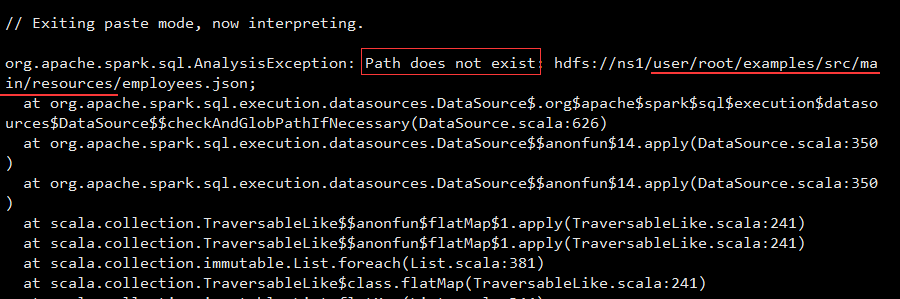
5.细节方面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号