
K-means
介绍
K-means算法是是最经典的聚类算法之一,它的优美简单、快速高效被广泛使用。它是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
图示
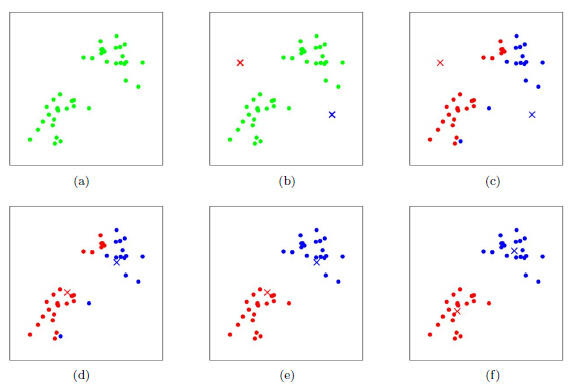
步骤
- 从N个文档随机选取K个文档作为质心
- 对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类
- 重新计算已经得到的各个类的质心
- 迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束
优点
- k-平均算法是解决聚类问题的一种经典算法,算法简单、快速。
- 对处理大数据集,该算法是相对可伸缩的和高效率的,因为它的复杂度大约是O(nkt),其中n是所有对象的数目,k是簇的数目,t是迭代的次数。通常k<<n。这个算法经常以局部最优结束。
- 算法尝试找出使平方误差函数值最小的k个划分。当簇是密集的、球状或团状的,而簇与簇之间区别明显时,它的聚类效果很好。
缺点
- K 是事先给定的,这个 K 值的选定是非常难以估计的;
- 对初值敏感,对于不同的初始值,可能会导致不同的聚类结果。一旦初始值选择的不好,可能无法得到有效的聚类结果;
- 该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。
- 不适合于发现非凸面形状的簇,或者大小差别很大的簇;
- 对于"噪声"和孤立点数据敏感,少量的该类数据能够对平均值产生极大影响。
改进
