利用selenium爬取cnvd漏洞信息
cnvd使用加速乐,正常访问会产生两次访问,第一次返回一段js代码生成cookie端添加到第二次访问的cookie才能进行成功访问。通过selenium访问一次产生的cookie,再利用session将每次会话的cookie限定,用了一天这个方法就gg了。能力有限,只能用最耗时的方法进行了。
由于是记录cookie,大概浏览器打开访问8次会被ban了,重新打开浏览器可以继续访问。
由于每个月份的日期不一致,所以selenium元素定位需要确认,修改。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# by 默不知然 2018-02-06
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from urllib import parse
from bs4 import BeautifulSoup
import re
import requests
import time
import random
import xlsxwriter
#由于根据cookie限制访问次数,8次左右后重新打开浏览器爬取数据可避免限制,不需要使用代理。
def cnvd_url(url,page_num):
'''
设置代理
proxy = random.sample(agent_lists,1)[0]
while proxy[2]!='HTTP':
proxy = random.sample(agent_lists,1)[0]
options = webdriver.ChromeOptions()
options.add_argument(('--proxy-server=http://'+proxy[0]+':'+proxy[1]))
driver = webdriver.Chrome(chrome_options=options)
'''
cnvd_url_html_list=[]
driver = webdriver.Chrome()
driver.get(url)
driver.set_window_size(200,200)
time.sleep(4)
#选择开始日期(每个月份不一致,元素位置不一致,所以需要手动修改)
driver.find_element_by_id('startDate').click()
driver.find_element_by_class_name('ui-datepicker-month').click()
driver.find_element_by_xpath('/html/body/div[11]/div/div/select[1]/option[1]').click()
driver.find_element_by_xpath('/html/body/div[11]/table/tbody/tr[1]/td[2]/a').click()
#选择结束日期(每个月份不一致,元素位置不一致,所以需要手动修改)
driver.find_element_by_id('endDate').click()
driver.find_element_by_class_name('ui-datepicker-month').click()
driver.find_element_by_xpath('/html/body/div[11]/div/div/select[1]/option[1]').click()
driver.find_element_by_xpath('/html/body/div[11]/table/tbody/tr[5]/td[4]/a').click()
#点击查询
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[1]/form/div/input[6]').click()
#第一页URL获取
html = driver.page_source
cnvd_url_html_soup = BeautifulSoup(html,'html.parser')
cnvd_url_html_div = cnvd_url_html_soup.find('div',attrs={'class':'blkContainer'})
cnvd_url_html_div_soup = BeautifulSoup(cnvd_url_html_div.encode().decode(),'html.parser')
cnvd_url_html_td_soup = cnvd_url_html_div_soup.find_all('td',attrs={'width':'45%'})
response = r'<a href="([\s+\S+]+)" title="[\s+\S+]+>'
for i in cnvd_url_html_td_soup:
url = 'http://www.cnvd.org.cn'+ re.compile(response).findall(str(i))[0]
cnvd_url_html_list.append(url)
#设置循环读取第二页之后的URL
for i in range(1,page_num):
if i%7 == 0:
vulnerability_get(cnvd_url_html_list)
cnvd_url_html_list.clear()
time.sleep(60)
else:
driver.find_element_by_class_name('nextLink').click()
html = driver.page_source
cnvd_url_html_soup = BeautifulSoup(html,'html.parser')
cnvd_url_html_div = cnvd_url_html_soup.find('div',attrs={'class':'blkContainer'})
cnvd_url_html_div_soup = BeautifulSoup(cnvd_url_html_div.encode().decode(),'html.parser')
cnvd_url_html_td_soup = cnvd_url_html_div_soup.find_all('td',attrs={'width':'45%'})
response = r'<a href="([\s+\S+]+)" title="[\s+\S+]+>'
for i in cnvd_url_html_td_soup:
url = 'http://www.cnvd.org.cn'+ re.compile(response).findall(str(i))[0]
cnvd_url_html_list.append(url)
vulnerability_get(cnvd_url_html_list)
driver.quit()
#获取代理,并写入列表agent_lists
def agent_list(url):
r = requests.get(url,headers=headers)
agent_info = BeautifulSoup(r.content,'lxml').find(id="ip_list").find_all('tr')[1:]
for i in range(len(agent_info)):
info = agent_info[i].find_all('td')
agents = []
agents.append(info[1].string)
agents.append(info[2].string)
agents.append(info[5].string)
agent_lists.append(agents)
#获取漏洞具体信息
def vulnerability_get(url):
driver = webdriver.Chrome()
for i in url:
global vulnerability_num
vulnerability_num = 0
vulnerability_list = []
driver.get(i)
driver.set_window_size(200,200)
time.sleep(2)
try:
html = driver.page_source
vulnerability_html_soup = BeautifulSoup(html,'html.parser')
vulnerability_html_div = vulnerability_html_soup.find('div',attrs={'class':'blkContainerSblk'})
vulnerability_div_soup = BeautifulSoup(vulnerability_html_div.encode().decode(),'html.parser')
vulnerability_name = vulnerability_div_soup.h1.string
except:
vulnerability_name = 1
if vulnerability_name == 1:
driver.quit()
driver = webdriver.Chrome()
driver.get(i)
driver.set_window_size(200,200)
time.sleep(2.5)
html = driver.page_source
vulnerability_html_soup = BeautifulSoup(html,'html.parser')
vulnerability_html_div = vulnerability_html_soup.find('div',attrs={'class':'blkContainerSblk'})
vulnerability_div_soup = BeautifulSoup(vulnerability_html_div.encode().decode(),'html.parser')
vulnerability_html_tr = vulnerability_div_soup.find_all('tr')
#漏洞名称
vulnerability_name = vulnerability_div_soup.h1.string
vulnerability_list.append(vulnerability_name)
#CNVD编号
response = r'<td>([\s+\S+]+)</td>'
vulnerability_cnvd = re.compile(response).findall(str(vulnerability_html_tr[0]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_cnvd)
#公开时间
response = r'<td>([\s+\S+]+)</td>'
vulnerability_strdate = re.compile(response).findall(str(vulnerability_html_tr[1]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_strdate)
#危害等级
try:
response = r'</span>([\S+\s+]+)\('
vulnerability_rank = re.compile(response).findall(str(vulnerability_html_tr[2]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_rank)
except:
vulnerability_rank = ''
vulnerability_list.append(vulnerability_rank)
#影响产品
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_range = re.compile(response).findall(str(vulnerability_html_tr[3]).replace('\n','').replace('\t','').replace('<br/>',';'))[0]
vulnerability_list.append(vulnerability_range)
except:
vulnerability_range = ''
vulnerability_list.append(vulnerability_range)
#判断是否存在 BUGTRAQ ID、其他 ID 的多余选项。
response = r'<td class="alignRight">([\s+\S+]+)</td><td>'
vulnerability_id_info = re.compile(response).findall(str(vulnerability_html_tr[4]).replace('\n','').replace('\t',''))[0]
if vulnerability_id_info == 'BUGTRAQ ID':
#判断是否存在“其他 ID”
response = r'<td class="alignRight">([\s+\S+]+)</td><td>'
vulnerability_id_info_n = re.compile(response).findall(str(vulnerability_html_tr[5]).replace('\n','').replace('\t',''))[0]
if vulnerability_id_info_n == '其他 ID':
#CVE编号
response = r'target="_blank">([\s+\S+]+)</a>'
vulnerability_cve = re.compile(response).findall(str(vulnerability_html_tr[6]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_cve)
#漏洞描述
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_description = re.compile(response).findall(str(vulnerability_html_tr[7]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_description)
except:
vulnerability_description = ''
vulnerability_list.append(vulnerability_description)
#参考链接
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_link = re.compile(response).findall(str(vulnerability_html_tr[8]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_link)
except:
vulnerability_link = ''
vulnerability_list.append(vulnerability_link)
#解决方案
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_solve = re.compile(response).findall(str(vulnerability_html_tr[9]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_solve)
except:
vulnerability_solve = ''
vulnerability_list.append(vulnerability_solve)
#补丁
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_path = re.compile(response).findall(str(vulnerability_html_tr[10]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_path)
except:
vulnerability_path = ''
vulnerability_list.append(vulnerability_path)
vulnerability_total_list.append(vulnerability_list)
vulnerability_num+=1
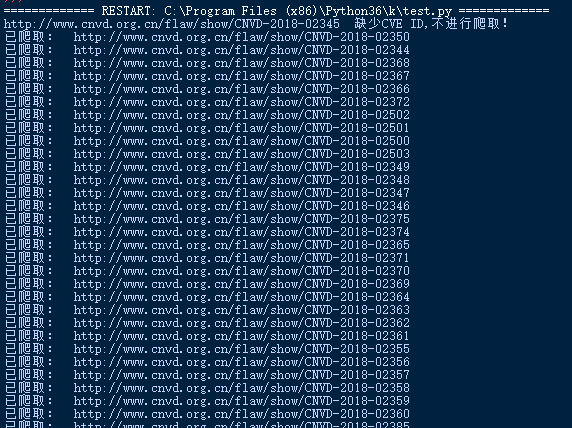
print ('已爬取: ',i)
elif vulnerability_id_info_n == '漏洞描述':
print (i,' 缺少CVE ID,不进行爬取!')
else:
#CVE编号
response = r'target="_blank">([\s+\S+]+)</a>'
vulnerability_cve = re.compile(response).findall(str(vulnerability_html_tr[5]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_cve)
#漏洞描述
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_description = re.compile(response).findall(str(vulnerability_html_tr[6]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_description)
except:
vulnerability_description = ''
vulnerability_list.append(vulnerability_description)
#参考链接
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_link = re.compile(response).findall(str(vulnerability_html_tr[7]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_link)
except:
vulnerability_link = ''
vulnerability_list.append(vulnerability_link)
#解决方案
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_solve = re.compile(response).findall(str(vulnerability_html_tr[8]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_solve)
except:
vulnerability_solve = ''
vulnerability_list.append(vulnerability_solve)
#补丁
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_path = re.compile(response).findall(str(vulnerability_html_tr[9]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_path)
except:
vulnerability_path = ''
vulnerability_list.append(vulnerability_path)
vulnerability_total_list.append(vulnerability_list)
vulnerability_num+=1
print ('已爬取: ',i)
elif vulnerability_id_info == 'CVE ID':
#CVE编号
response = r'target="_blank">([\s+\S+]+)</a>'
vulnerability_cve = re.compile(response).findall(str(vulnerability_html_tr[4]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_cve)
#漏洞描述
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_description = re.compile(response).findall(str(vulnerability_html_tr[5]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_description)
except:
vulnerability_description = ''
vulnerability_list.append(vulnerability_description)
#参考链接
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_link = re.compile(response).findall(str(vulnerability_html_tr[6]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_link)
except:
vulnerability_link = ''
vulnerability_list.append(vulnerability_link)
#解决方案
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_solve = re.compile(response).findall(str(vulnerability_html_tr[7]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_solve)
except:
vulnerability_solve = ''
vulnerability_list.append(vulnerability_solve)
#补丁
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_path = re.compile(response).findall(str(vulnerability_html_tr[8]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_path)
except:
vulnerability_path = ''
vulnerability_list.append(vulnerability_path)
vulnerability_total_list.append(vulnerability_list)
vulnerability_num+=1
print ('已爬取: ',i)
elif vulnerability_id_info == '其他 ID':
#CVE编号
response = r'target="_blank">([\s+\S+]+)</a>'
vulnerability_cve = re.compile(response).findall(str(vulnerability_html_tr[5]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_cve)
#漏洞描述
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_description = re.compile(response).findall(str(vulnerability_html_tr[6]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_description)
except:
vulnerability_description = ''
vulnerability_list.append(vulnerability_description)
#参考链接
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_link = re.compile(response).findall(str(vulnerability_html_tr[7]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_link)
except:
vulnerability_link = ''
vulnerability_list.append(vulnerability_link)
#解决方案
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_solve = re.compile(response).findall(str(vulnerability_html_tr[8]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_solve)
except:
vulnerability_solve = ''
vulnerability_list.append(vulnerability_solve)
#补丁
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_path = re.compile(response).findall(str(vulnerability_html_tr[9]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_path)
except:
vulnerability_path = ''
vulnerability_list.append(vulnerability_path)
vulnerability_total_list.append(vulnerability_list)
vulnerability_num+=1
print ('已爬取: ',i)
else:
print (i,' 缺少CVE ID,不进行爬取!')
#访问次数过多重置浏览器
else:
vulnerability_html_tr = vulnerability_div_soup.find_all('tr')
#漏洞名称
vulnerability_name = vulnerability_div_soup.h1.string
vulnerability_list.append(vulnerability_name)
#CNVD编号
response = r'<td>([\s+\S+]+)</td>'
vulnerability_cnvd = re.compile(response).findall(str(vulnerability_html_tr[0]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_cnvd)
#公开时间
response = r'<td>([\s+\S+]+)</td>'
vulnerability_strdate = re.compile(response).findall(str(vulnerability_html_tr[1]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_strdate)
#危害等级
try:
response = r'</span>([\S+\s+]+)\('
vulnerability_rank = re.compile(response).findall(str(vulnerability_html_tr[2]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_rank)
except:
vulnerability_rank = ''
vulnerability_list.append(vulnerability_rank)
#影响产品
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_range = re.compile(response).findall(str(vulnerability_html_tr[3]).replace('\n','').replace('\t','').replace('<br/>',';'))[0]
vulnerability_list.append(vulnerability_range)
except:
vulnerability_range = ''
vulnerability_list.append(vulnerability_range)
#判断是否存在 BUGTRAQ ID、其他 ID 的多余选项。
response = r'<td class="alignRight">([\s+\S+]+)</td><td>'
vulnerability_id_info = re.compile(response).findall(str(vulnerability_html_tr[4]).replace('\n','').replace('\t',''))[0]
if vulnerability_id_info == 'BUGTRAQ ID':
#判断是否存在“其他 ID”
response = r'<td class="alignRight">([\s+\S+]+)</td><td>'
vulnerability_id_info_n = re.compile(response).findall(str(vulnerability_html_tr[5]).replace('\n','').replace('\t',''))[0]
if vulnerability_id_info_n == '其他 ID':
#CVE编号
response = r'target="_blank">([\s+\S+]+)</a>'
vulnerability_cve = re.compile(response).findall(str(vulnerability_html_tr[6]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_cve)
#漏洞描述
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_description = re.compile(response).findall(str(vulnerability_html_tr[7]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_description)
except:
vulnerability_description = ''
vulnerability_list.append(vulnerability_description)
#参考链接
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_link = re.compile(response).findall(str(vulnerability_html_tr[8]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_link)
except:
vulnerability_link = ''
vulnerability_list.append(vulnerability_link)
#解决方案
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_solve = re.compile(response).findall(str(vulnerability_html_tr[9]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_solve)
except:
vulnerability_solve = ''
vulnerability_list.append(vulnerability_solve)
#补丁
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_path = re.compile(response).findall(str(vulnerability_html_tr[10]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_path)
except:
vulnerability_path = ''
vulnerability_list.append(vulnerability_path)
vulnerability_total_list.append(vulnerability_list)
vulnerability_num+=1
print ('已爬取: ',i)
elif vulnerability_id_info_n == '漏洞描述':
print (i,' 缺少CVE ID,不进行爬取!')
else:
#CVE编号
response = r'target="_blank">([\s+\S+]+)</a>'
vulnerability_cve = re.compile(response).findall(str(vulnerability_html_tr[5]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_cve)
#漏洞描述
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_description = re.compile(response).findall(str(vulnerability_html_tr[6]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_description)
except:
vulnerability_description = ''
vulnerability_list.append(vulnerability_description)
#参考链接
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_link = re.compile(response).findall(str(vulnerability_html_tr[7]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_link)
except:
vulnerability_link = ''
vulnerability_list.append(vulnerability_link)
#解决方案
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_solve = re.compile(response).findall(str(vulnerability_html_tr[8]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_solve)
except:
vulnerability_solve = ''
vulnerability_list.append(vulnerability_solve)
#补丁
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_path = re.compile(response).findall(str(vulnerability_html_tr[9]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_path)
except:
vulnerability_path = ''
vulnerability_list.append(vulnerability_path)
vulnerability_total_list.append(vulnerability_list)
vulnerability_num+=1
print ('已爬取: ',i)
elif vulnerability_id_info == 'CVE ID':
#CVE编号
response = r'target="_blank">([\s+\S+]+)</a>'
vulnerability_cve = re.compile(response).findall(str(vulnerability_html_tr[4]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_cve)
#漏洞描述
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_description = re.compile(response).findall(str(vulnerability_html_tr[5]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_description)
except:
vulnerability_description = ''
vulnerability_list.append(vulnerability_description)
#参考链接
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_link = re.compile(response).findall(str(vulnerability_html_tr[6]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_link)
except:
vulnerability_link = ''
vulnerability_list.append(vulnerability_link)
#解决方案
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_solve = re.compile(response).findall(str(vulnerability_html_tr[7]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_solve)
except:
vulnerability_solve = ''
vulnerability_list.append(vulnerability_solve)
#补丁
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_path = re.compile(response).findall(str(vulnerability_html_tr[8]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_path)
except:
vulnerability_path = ''
vulnerability_list.append(vulnerability_path)
vulnerability_total_list.append(vulnerability_list)
vulnerability_num+=1
print ('已爬取: ',i)
elif vulnerability_id_info == '其他 ID':
#CVE编号
response = r'target="_blank">([\s+\S+]+)</a>'
vulnerability_cve = re.compile(response).findall(str(vulnerability_html_tr[5]).replace('\n','').replace('\t',''))[0]
vulnerability_list.append(vulnerability_cve)
#漏洞描述
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_description = re.compile(response).findall(str(vulnerability_html_tr[6]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_description)
except:
vulnerability_description = ''
vulnerability_list.append(vulnerability_description)
#参考链接
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_link = re.compile(response).findall(str(vulnerability_html_tr[7]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_link)
except:
vulnerability_link = ''
vulnerability_list.append(vulnerability_link)
#解决方案
try:
response = r'<td>([\s+\S+]+)</td>'
vulnerability_solve = re.compile(response).findall(str(vulnerability_html_tr[8]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_solve)
except:
vulnerability_solve = ''
vulnerability_list.append(vulnerability_solve)
#补丁
try:
response = r'<a[\s+\S+]+>([\s+\S+]+)</a>'
vulnerability_path = re.compile(response).findall(str(vulnerability_html_tr[9]).replace('\n','').replace('\t','').replace('<br/>',''))[0]
vulnerability_list.append(vulnerability_path)
except:
vulnerability_path = ''
vulnerability_list.append(vulnerability_path)
vulnerability_total_list.append(vulnerability_list)
vulnerability_num+=1
print ('已爬取: ',i)
else:
print (i,' 缺少CVE ID,不进行爬取!')
driver.quit()
#漏洞信息写入excel
def vulnerability_excel(excel):
workbook = xlsxwriter.Workbook('spider_cnvd.xlsx')
worksheet = workbook.add_worksheet()
row = 0
col = 0
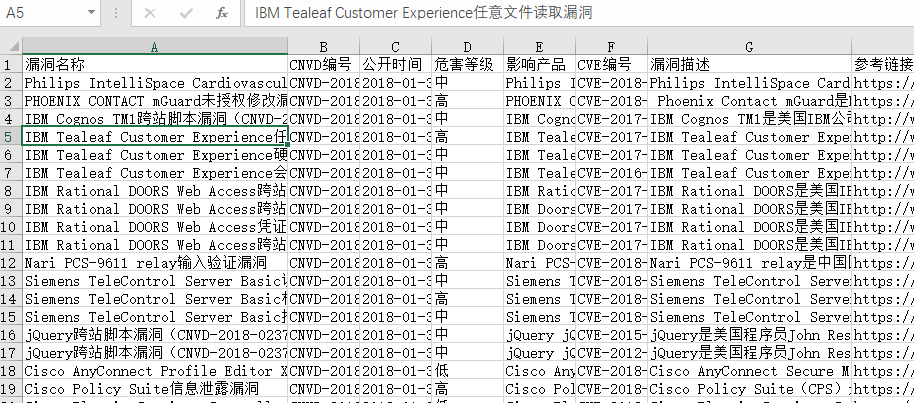
worksheet.write(row,0,'漏洞名称')
worksheet.write(row,1,'CNVD编号')
worksheet.write(row,2,'公开时间')
worksheet.write(row,3,'危害等级')
worksheet.write(row,4,'影响产品')
worksheet.write(row,5,'CVE编号')
worksheet.write(row,6,'漏洞描述')
worksheet.write(row,7,'参考链接')
worksheet.write(row,8,'解决方案')
worksheet.write(row,9,'补丁')
row = 1
n = 0
while n < len(excel):
worksheet.write(row,col,excel[n][0])
worksheet.write(row,col+1,excel[n][1])
worksheet.write(row,col+2,excel[n][2])
worksheet.write(row,col+3,excel[n][3])
worksheet.write(row,col+4,excel[n][4])
worksheet.write(row,col+5,excel[n][5])
worksheet.write(row,col+6,excel[n][6])
worksheet.write(row,col+7,excel[n][7])
worksheet.write(row,col+8,excel[n][8])
worksheet.write(row,col+9,excel[n][9])
row += 1
n += 1
workbook.close()
global headers
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36',
}
global agent_lists
agent_lists = []
global vulnerability_total_list
vulnerability_total_list = []
def main():
for i in range(1,2):
url='http://www.xicidaili.com/nn/'+str(i)
agent_list(url)
url = 'http://www.cnvd.org.cn/flaw/list.htm?flag=true'
page_num = 69
cnvd_url(url,page_num)
#aaa=['http://www.cnvd.org.cn/flaw/show/CNVD-2018-02345','http://www.cnvd.org.cn/flaw/show/CNVD-2018-02350','http://www.cnvd.org.cn/flaw/show/CNVD-2018-02200']
#vulnerability_get(aaa)
vulnerability_excel(vulnerability_total_list)
print('已爬取漏洞数量: ',vulnerability_num)
if __name__ == '__main__':
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号