Node爬虫之——使用async.mapLimit控制请求并发
一般我们在写爬虫的时候,很多网站会因为你并发请求数太多当做是在恶意请求,封掉你的IP,为了防止这种情况的发生,我们一般会在代码里控制并发请求数,Node里面一般借助async模块来实现。
1. async.mapLimit方法
mapLimit(arr, limit, iterator, callback)
arr中一般是多个请求的url,limit为并发限制次数,mapLimit方法将arr中的每一项依次拿给iterator去执行,执行结果传给最后的callback;
2. async.mapLimit方法应用
下面是之前写过的一个简单的爬虫示例,将爬取到的新闻标题和路径保存在一个Excel表格中,限制并发数为3,代码如下
webSpider.js:
//request调用url主函数 (mapLimit iterator)
function main(option, callback) {
n++;
timeline[option] = new Date().getTime();
console.log('现在的并发数是', n, ',正在抓取的是', option);
request(option, function(err, res, body) {
if(!err && res.statusCode == 200){
var $ = cheerio.load(body);
$('#post_list .post_item').each(function(index, element) {
// console.log(element);
var item = [$(element).find('.post_item_body h3 a').text(),$(element).find('.post_item_body h3 a').attr('href')];
dataArr[0].data.push(item);
});
console.log('抓取', option, '结束,耗时:', new Date().getTime()-timeline[option], '毫秒');
n--;
callback(null, 'done!');
}else{
console.log(err);
n--;
callback(err, null);
}
});
}
//限制请求并发数为3
async.mapLimit(options, 3, main.bind(this), function(err, result){
if(err) {
console.log(err);
} else {
fs.writeFile('data/cnbNews.xlsx', xlsx.build(dataArr), 'utf-8', function(err){
if(err){
console.log('write file error!');
}else{
console.log('write file success!');
}
});
}
});
这里迭代器里面第二个参数callback(即请求每一条url完成之后的回调方法)是关键,没有异常的情况下所有options中的url都请求完成之后会回调mapLimit方法的回调方法进行后续操作(如这里的生成文件),如果单条url请求异常,回调方法中会接收到err并报出错误,不能执行后续生成文件的操作。
async.mapLimit(options, 3, function(option, callback) {
request(option, main);
callback(null);
}, function(err, result) {
if(err) {
console.log(err);
} else {
console.log('done!');
}
});
如上,网上有些资料中是在迭代器中request方法执行完成之后调用callback,因为request方法异步接收请求数据,这种写法会使async.mapLimit方法limit参数无效,导致无法达到限制请求并发数的目的,这里需要注意下。
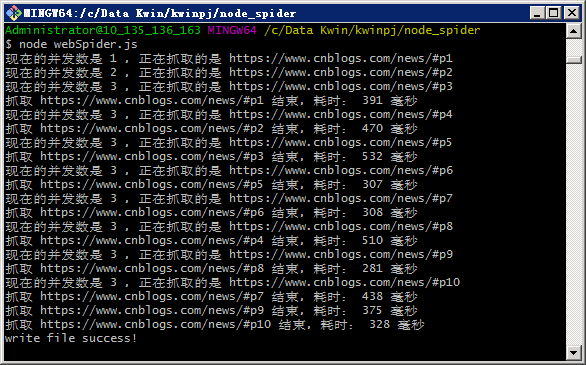
执行webSpider.js,
node webSpider.js
3. 总结
执行结果可以看到并发数依次增加,增加到3时不再继续增加,等待前面一条请求执行完成后才会请求下一条,这样的话,如果我们需要爬取1000条数据,就可以并发10条请求,慢慢爬完这1000个链接,这样就不用担心因并发太多被封IP这种情况发生了。完整代码已上传GitHub,有兴趣去试试吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号