


python读写csv文件的方法(还没试,先记录一下)
该csv模块定义了以下功能:
csv.reader(csvfile,dialect ='excel',** fmtparams )
返回一个reader对象,它将迭代给定csvfile中的行。 csvfile可以是任何支持迭代器协议的对象,并在每次__next__()调用其方法时返回一个字符串- 文件对象和列表对象都是合适的。如果csvfile是一个文件对象,则应该打开它newline=''。[1]可以给出 可选的 方言参数,该参数用于定义特定于CSV方言的一组参数。它可以是类的子类的实例,也可以是函数Dialect返回的字符串之一 list_dialects()。其他可选的fmtparams可以给出关键字参数来覆盖当前方言中的各个格式参数。有关方言和格式参数的完整详细信息,请参阅“ 方言和格式参数”一节。
从csv文件读取的每一行都作为字符串列表返回。除非QUOTE_NONNUMERIC指定了format选项(在这种情况下,未加引号的字段将转换为浮点数),否则不会执行自动数据类型转换。
一个简短的用法示例:
>>>
>>> import csv
>>> with open('eggs.csv', newline='') as csvfile:
... spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|')
... for row in spamreader:
... print(', '.join(row))
Spam, Spam, Spam, Spam, Spam, Baked Beans
Spam, Lovely Spam, Wonderful Spam
csv.writer(csvfile,dialect ='excel',** fmtparams )
返回一个编写器对象,负责将用户的数据转换为给定的类文件对象上的分隔字符串。csvfile可以是带有write()方法的任何对象 。如果csvfile是文件对象,则应使用newline='' [1]打开它 。 可以给出可选的方言参数,该参数用于定义特定于CSV方言的一组参数。它可以是类的子类的实例,也可以是 函数Dialect返回的字符串之一list_dialects()。可以给出其他可选的fmtparams关键字参数来覆盖当前方言中的各个格式参数。有关方言和格式参数的完整详细信息,请参阅部分方言和格式参数。为了使与实现DB API的模块接口尽可能简单,将值None写为空字符串。虽然这不是可逆转换,但它可以更容易地将SQL NULL数据值转储到CSV文件,而无需预处理从cursor.fetch*调用返回的数据。所有其他非字符串数据str()在写入之前都会进行字符串化。
一个简短的用法示例:
import csv
with open('eggs.csv', 'w', newline='') as csvfile:
spamwriter = csv.writer(csvfile, delimiter=' ',
quotechar='|', quoting=csv.QUOTE_MINIMAL)
spamwriter.writerow(['Spam'] * 5 + ['Baked Beans'])
spamwriter.writerow(['Spam', 'Lovely Spam', 'Wonderful Spam'])
csv.register_dialect(name [,dialect [,** fmtparams ] ] )
将方言与名称联系起来。 name必须是一个字符串。方言可以通过传递子类Dialect,或通过fmtparams关键字参数或两者来指定,并使用关键字参数覆盖方言的参数。有关方言和格式参数的完整详细信息,请参阅“ 方言和格式参数”一节。
csv.unregister_dialect(name)
从方言注册表中删除与名称关联的方言。Error如果name不是已注册的方言名称,则引发An 。
csv.get_dialect(name)
返回与姓名相关的方言。Error如果name不是已注册的方言名称,则引发 An 。此函数返回不可变的 Dialect。
csv.list_dialects()
返回所有已注册方言的名称。
csv.field_size_limit([ new_limit ] )
返回解析器允许的当前最大字段大小。如果给出new_limit,则这将成为新限制。
该csv模块定义了以下类:
class csv.DictReader(f,fieldnames = None,restkey = None,restval = None,dialect ='excel',* args,** kwds )
创建一个像常规阅读器一样操作的对象,但将每行中的信息映射到OrderedDict 其键由可选的fieldnames参数给出。
的字段名的参数是一个序列。如果省略fieldnames,则文件f的第一行中的值将用作字段名。无论字段名如何确定,有序字典都保留其原始顺序。
如果一行包含的字段多于字段名,则将剩余数据放入一个列表中,并使用restkey指定的字段名(默认为None)进行存储。如果非空行的字段数少于字段名,则缺少的值将填入None。
所有其他可选或关键字参数都传递给基础 reader实例。
在版本3.6中更改:返回的行现在是类型OrderedDict。
一个简短的用法示例:
>>>
>>> import csv
>>> with open('names.csv', newline='') as csvfile:
... reader = csv.DictReader(csvfile)
... for row in reader:
... print(row['first_name'], row['last_name'])
...
Eric Idle
John Cleese
>>> print(row)
OrderedDict([('first_name', 'John'), ('last_name', 'Cleese')])
class csv.DictWriter(f,fieldnames,restval ='',extrasaction ='raise',dialect ='excel',* args,** kwds )
创建一个像常规编写器一样操作的对象,但将字典映射到输出行。的字段名的参数是一个sequence标识,其中在传递给字典值的顺序按键的writerow()方法被写入到文件 ˚F。如果字典缺少字段名中的键,则可选的restval参数指定要写入的值。如果传递给方法的字典包含在字段名中找不到的键 ,则可选的extrasaction参数指示要采取的操作。如果设置为, 则引发默认值a 。如果设置为writerow()'raise'ValueError'ignore',字典中的额外值将被忽略。任何其他可选或关键字参数都将传递给基础 writer实例。
请注意,与DictReader类不同,类的fieldnames参数DictWriter不是可选的。
一个简短的用法示例:
import csv
with open('names.csv', 'w', newline='') as csvfile:
fieldnames = ['first_name', 'last_name']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'first_name': 'Baked', 'last_name': 'Beans'})
writer.writerow({'first_name': 'Lovely', 'last_name': 'Spam'})
writer.writerow({'first_name': 'Wonderful', 'last_name': 'Spam'})
类csv.Dialect
的Dialect类是依赖于主要用于它的属性,这是用来定义一个特定的参数的容器类reader或writer实例。
类csv.excel
在excel类定义的Excel生成CSV文件的通常的性质。它以方言名称注册'excel'。
类csv.excel_tab
所述excel_tab类定义Excel生成的制表符分隔的文件的通常的性质。它以方言名称注册'excel-tab'。
类csv.unix_dialect
的unix_dialect类定义在UNIX系统上,即,使用生成的CSV文件的通常性质'\n'如线路终端机和引用的所有字段。它以方言名称注册'unix'。
版本3.2中的新功能。
类csv.Sniffer
本Sniffer类用来推断一个CSV文件的格式。
本Sniffer类提供了两个方法:
sniff(样本,分隔符=无)
分析给定的样本并返回Dialect反映找到的参数的子类。如果给出了可选的delimiters参数,则将其解释为包含可能的有效分隔符的字符串。
has_header(样本)
分析示例文本(假定为CSV格式), True如果第一行看起来是一系列列标题,则返回。
使用示例Sniffer:
with open('example.csv', newline='') as csvfile:
dialect = csv.Sniffer().sniff(csvfile.read(1024))
csvfile.seek(0)
reader = csv.reader(csvfile, dialect)
# ... process CSV file contents here ...
该csv模块定义以下常量:
csv.QUOTE_ALL
指示writer对象引用所有字段。
csv.QUOTE_MINIMAL
指示writer对象只引用那些包含特殊字符,如字段分隔符,quotechar或任何字符lineterminator。
csv.QUOTE_NONNUMERIC
指示writer对象引用所有非数字字段。
指示读者将所有非引用字段转换为float类型。
csv.QUOTE_NONE
指示writer对象永远不引用字段。当输出数据中出现当前 分隔符时,它前面是当前的escapechar 字符。如果未设置escapechar,则Error在遇到需要转义的任何字符时,编写器将引发。
指示reader不对引号字符执行特殊处理。
该csv模块定义了以下异常:
异常csv.Error
检测到错误时由任何功能引发。
参考: https://blog.csdn.net/qq_35892623/article/details/81267182
https://www.cnblogs.com/Keys819/p/9326575.html
1.Python处理csv文件之csv.writer()

import csv
def csv_write(path,data):
with open(path,'w',encoding='utf-8',newline='') as f:
writer = csv.writer(f,dialect='excel')
for row in data:
writer.writerow(row)
return True
调用上面的函数
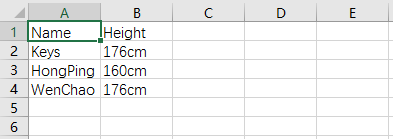
data = [
['Name','Height'],
['Keys','176cm'],
['HongPing','160cm'],
['WenChao','176cm']
]
csv_write('test.csv',data)
运行结果
2.Python处理csv文件之csv.reader()
def csv_read(path):
data = []
with open(path,'r',encoding='utf-8') as f:
reader = csv.reader(f,dialect='excel')
for row in reader:
data.append(row)
return data
调用上面的函数
data = csv_read('test.csv')
print(data)
运行结果
[['Name', 'Height'], ['Keys', '176cm'], ['HongPing', '160cm'], ['WenChao', '176cm']]
3.Python处理csv文件之csv.DictWriter()
def csv_dict_write(path,head,data):
with open(path,'w',encoding='utf-8',newline='') as f:
writer = csv.DictWriter(f,head)
writer.writeheader()
writer.writerows(data)
return True
调用上面的函数
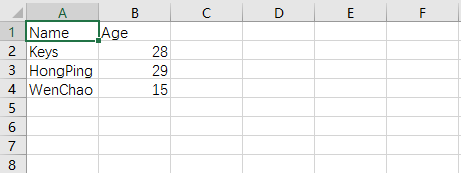
head = ['Name','Age']
data = [
{'Name':'Keys', 'Age':28},
{'Name':'HongPing', 'Age':29},
{'Name':'WenChao', 'Age':15}
]
csv_dict_write('test2.csv',head,data)
运行结果
4.Python处理csv文件之csv.DictReader()
def csv_dict_read(path):
with open(path,'r',encoding='utf-8') as f:
reader = csv.DictReader(f,dialect='excel')
for row in reader:
print(row['Name'])
调用上面的函数
csv_dict_read('test2.csv')
运行结果
Keys HongPing WenChao
