Scrapy 架构
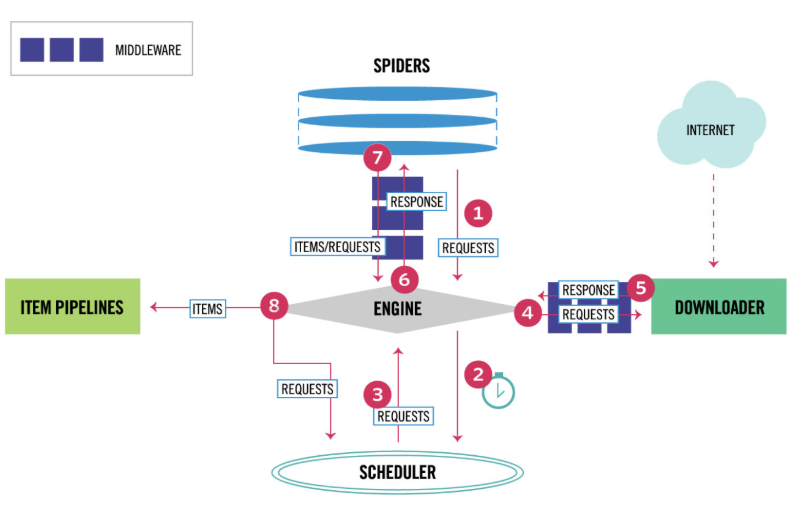
- 引擎(EGINE)(大总管)
引擎负责 控制系统 所有 组件之间的数据流,并在某些动作发生时触发事件
- 调度器(SCHEDULER)
一个 URL 优先级队列,存放引擎发送过来的 requests 请求,由它来决定下一个要抓取的网址是什么,同时去除重复的网址
- 下载器(DOWLOADER)
用于下载网页内容,并将网页内容返回给 EGINE,下载器是建立在 twisted 这个高效的异步模型上的
- 爬虫(SPIDERS)
SPIDERS 是开发人员自定义的类,用来解析 responses,并且提取 items,或者发送新的请求
- 项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
- 下载中间件(Downloader Middlewares)
可以自定义的下载扩展,比如设置代理,加头,加cookie,集成selenium
- 爬虫中间件(Spider Middleware)
可以自定义 requests 请求和 responses 过滤
Scrapy 的三个内置对象
- request请求对象:由url method post_data headers等构成
- response响应对象:由url body status headers等构成
- item数据对象:本质是个字典
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号