构造 DataFrame
在pandas中,表格数据基本都是以DataFrame保存的,所以一般需要先将普通数据转换为DataFrame格式再进行操作,有5种常用方法
1、由 Series 数据转换
这种方式指定每一列为一个Series数据并给出列名,要求必须指定列名不然会报错,不要求每一个Series数据长度相同,默认以最长的为行高,空白部分自动补齐,行下标(index)如果不指定则会默认为[0,1,2…]
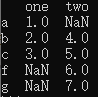
d = {'one':pd.Series([1,2,3],index=['a','b','c']),
'two':pd.Series([4,5,6,7],index=['b','c','f','g'])}
df = pd.DataFrame(d)
# pd.DataFrame({'列名': pd.Series(['列表'])})
2、由字典转换
这种方式将字典转换为DataFrame,每一个字典字段指定一列,要求每列长度必须相同且必须指定列名
h = {'一':[1,2,3,4],
'二':[6,7,8,9]}
df = pd.DataFrame(h,index=['one','second','third','fourth'])

3、由列表转换
从列表转化为DataFrame,列表每一个子元素为一行,默认列名为[0,1,2…],元素长度可以不同,默认填充至最长行
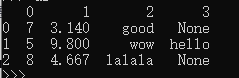
data = []
data.append((7,3.14,'good'))
data.append((5,9.8,'wow','hello'))
data.append((8,4.667,'lalala'))
df = pd.DataFrame(data)
4、由字典列表转换
从字典列表转换,与从列表转换类似,但通过字典指定列名,列表每一个子元素为一行,长度可以不同
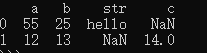
data = []
data.append({'a':55,'b':25,'str':'hello'})
data.append({'a':12,'b':13,'c':14})
df = pd.DataFrame(data)
5、由元组字典转换
虽然不怎么常用,但是也给出方法,由于比较复杂所以讲解一下,这种方法相当于在表中建立子表,字典中每一个字段为一列,比如('A','b'):{('one','1'):1,('one','2'):2}定义了一列,行高为2,列索引为’A’的子下标’b’,行索引为’one’的子下标’1’与子下标’2’
data = {('A','b'):{('one','1'):1,('one','2'):2},
('A','a'): {('one','2'):3,('one','1'):4},
('A','c'): {('one','2'):5,('one','1'):6},
('B','a'): {('one','3'):7,('one','2'):8},
('B','b'): {('one','1'):9,('one','2'):10}
}
df = pd.DataFrame(data)
以DataFrame形式写入表格
df.to_excel('test.xlsx')
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号