直播数据爬取
可以在 js 数据中找到 sign 的加密方式
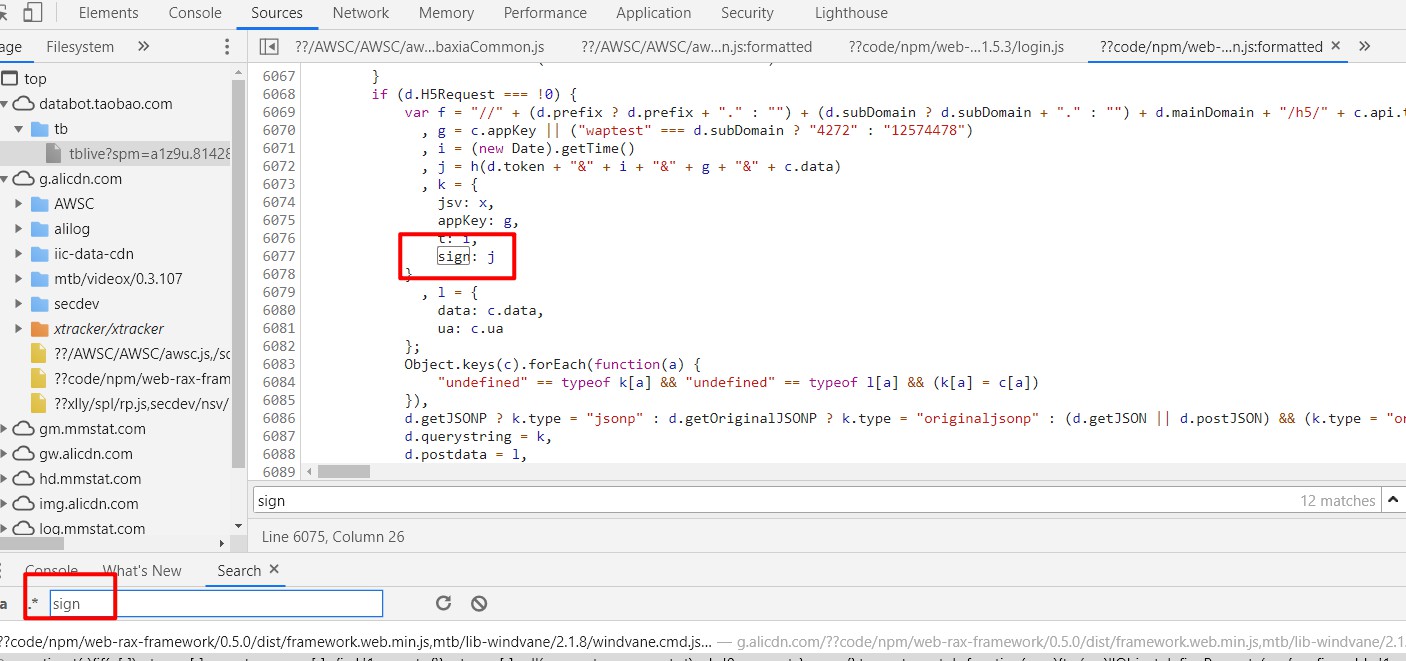
分析得知 sign 加密方式为 (d.token + "&" + 时间戳 + "&" + appkey + "&" + data)
d.token的值,发现这个值在cookie当中出现了,与时间戳结合在一起,这个token值会过期,大概是2小时
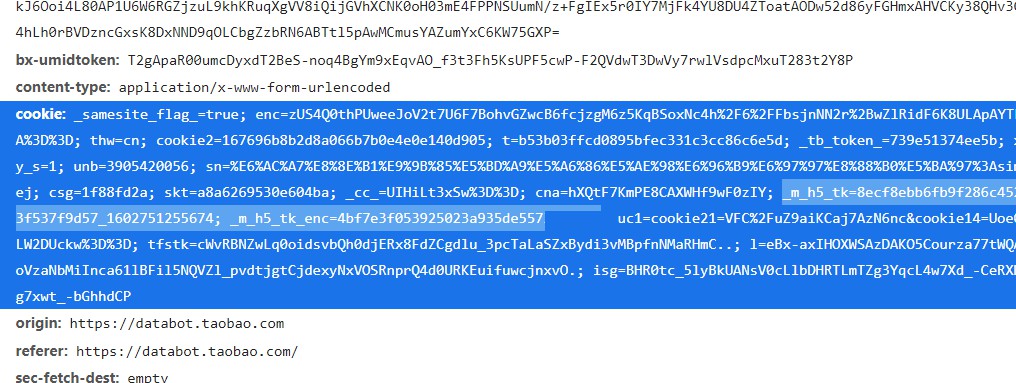
请求数据接口的时候请求头必须带cookie,且包含_m_h5_tk与_m_h5_tk_enc这两个字段,而且发现不需要登录就可以获取这个cookie,响应返回的信息当中也包括了这两个字段,这样就可以获取到token了
import requests
from urllib import parse
def _m_h5():
data = parse.unquote('%7B%22param%......innerId%22%3A%22%22%7D')
params = {
'appKey': 12574478,
'data': data
}
# 请求空获取cookies
url = 'https://acs.m.taobao.com/h5/mtop.taobao.social.feed.aggregate/1.0/'
resp = requests.get(url, params=params)
cookiejar = requests.utils.dict_from_cookiejar(resp.cookies)
m_ht_tk = cookiejar['_m_h5_tk']
m_h5_tk_enc = cookiejar['_m_h5_tk_enc']
print(m_ht_tk, m_h5_tk_enc)
return m_ht_tk, m_h5_tk_enc
_m_h5()
import requests
import time
import json
import hashlib
from urllib import parse
from openpyxl import load_workbook
from apscheduler.schedulers.blocking import BlockingScheduler
class TaobaoLiveSpider:
def __init__(self):
self.start_time = parse.quote('2020-10-15 11:00:11')
self.end_time = parse.quote('2020-11-14 11:00:11')
# 观看次数 固定格式
self.data = parse.unquote(f'%7B%22param%2_abstract_indicator%5C%22%2C%5C%22queryDetail%5C%22%3Afalse%2C%5C%22startTime%5C%22%3A%5C%22{self.start_time}%5C%22%2C%5C%22endTime%5C%22%3A%5C%22{self.end_time}%5C%22%2C%5C%22timeType%5C%22%3A2%2C%5C%22sign%5C%2AfaC%5C%22%7D%5D%5C%22%2C%5C%22extra%5C%22%3Anull%7D%22%2C%22innerId%22%3A%22%22%7D') # 每次请求需携带的 data,错误会报 非法请求参数
# 引导交易 固定格式
self.guid_deal_data = parse.unquote(f'%7B%22paracbot_slr_lime_rpt_ov_deal%5C%22%2C%5C%22queryDetail%5C%22%3Afalse%2C%5C%22startTime%5C%22%3A%5C%22{self.start_time}%5C%22%2C%5C%22endTime%5C%22%3A%5C%22{self.end_time}%5C%22%2C%5C%22timeType%5C%22%3A2%2C%5C%22sign%5C%22%3Anull%2C%5C%22limit%5C%22%3A1%2C%5C%22row%5C%22%3A%5C%22%5B%5D%5C%22%2C%5C%22measure%5C%22%3A%5C%22%5B%...22%22%7D')
# 粉丝平均在线 固定格式
self.fans_average_on_line_time_data = parse.unquote(f'%7B%22pabstract_indicator%5C%22%2C%5C%22queryDetail%5C%22%3Afalse%2C%5C%22startTime%5C%22%3A%5C%22{self.start_time}%5C%22%2C%5C%22endTime%5C%22%3A%5C%22{self.end_time}%5C%22%2C%5C%22timeType%5C%22%3A2%2C%5C%22sign%5C%25C%5C%...2%7D')
# print(self.data)
# print(self.guid_deal_data)
# print(self.fans_average_on_line_time_data)
self.now_time = str(round(time.time(), 3)).replace('.', '') # 13 当前位时间戳
self.url = 'https://h5api.m.taobao.com/h5/mtop.alibaba.iic.xinsightshop.olap.query/1.0/'
self.m_ht_tk, self.m_h5_tk_enc = '', ''
self.local_now_time = time.strftime('%Y-%m-%d %H:%M:%S')
self.line = 2
def get_taobao_cookie(self):
"""
cookie 字段
:return: m_ht_tk, m_h5_tk_enc
"""
# data = parse.unquote(data)
params = {
'appKey': 27522***,
'data': self.data
}
url = 'https://acs.m.taobao.com/h5/mtop.taobao.social.feed.aggregate/1.0/'
resp = requests.get(url, params=params)
cookiejar = requests.utils.dict_from_cookiejar(resp.cookies)
self.m_ht_tk = cookiejar['_m_h5_tk']
self.m_h5_tk_enc = cookiejar['_m_h5_tk_enc']
def headers(self):
self.get_taobao_cookie()
m_ht_tk, m_h5_tk_enc = self.m_ht_tk, self.m_h5_tk_enc
# print('m_ht_tk, m_h5_tk_enc', m_ht_tk, m_h5_tk_enc)
return {
'cookie': f'_samesite_flag_=true; enc=zUS4Q0thPUweeJoV2t7U6F7Boh...cookie14=Uoe0b0ORnwCV7g%3D%3D; _m_h5_tk={m_ht_tk}; _m_h5_tk_enc={m_h5_tk_enc}; l=eBQZK...M-z4WFdhUU3iV4LClmbXGZtE1Ab_kVQUg5TgQGwt5iPeN5-BXtyeA6i1..',
'origin': 'https://databot.taobao.com',
'referer': 'https://databot.taobao.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
def params(self, data):
return {
'jsv': '2.6.0',
'appKey': '27522***',
't': self.now_time,
'sign': self.sign(data),
'api': 'mtop.alibaba.iic.xinsightshop.olap.query',
'v': '1.0',
'type': 'originaljson',
'dataType': 'json',
'timeout': 20000,
'H5Request': 'true',
'data': data
}
def sign(self, data):
"""
sign 加密方式
:return: sign 字符串
"""
# m_ht_tk, _ = self.get_taobao_cookie(self.data)
m_ht_tk = self.m_ht_tk.split('_')[0]
sign = m_ht_tk + '&' + self.now_time + '&' + '27522***' + '&' + data
sign = hashlib.md5(sign.encode())
sign = sign.hexdigest()
return sign
def spider(self):
resp = requests.get(self.url, headers=self.headers(), params=self.params(self.data)).json()
print(resp)
visit = resp['data']['data']['cellset'][1]
watching_count = visit[5]['value']
click_probability = visit[7]['value']
on_line_count = visit[6]['value']
average_on_line_time = visit[2]['value']
live_room_watching_count = visit[0]['value']
fans_make_up = visit[-2]['value']
extra_add_flow = visit[1]['value']
add_fans = visit[4]['value']
goods_click = visit[3]['value']
goods_click_fans_make_up = visit[-1]['value']
resp = requests.get(self.url, headers=self.headers(), params=self.params(self.guid_deal_data)).json()
visit = resp['data']['data']['cellset'][1]
guid_deal_count = visit[0]['value']
guid_deal_percent = visit[1]['value']
guid_deal_money = visit[2]['value']
guid_deal_money_percent = visit[3]['value']
resp = requests.get(self.url, headers=self.headers(), params=self.params(self.fans_average_on_line_time_data)).json()
visit = resp['data']['data']['cellset'][1]
fans_average_on_line_time = visit[0]['value']
print(watching_count, click_probability, on_line_count, average_on_line_time, fans_average_on_line_time,
live_room_watching_count, fans_make_up, extra_add_flow,
add_fans, goods_click, goods_click_fans_make_up, guid_deal_count, guid_deal_percent,
guid_deal_money, guid_deal_money_percent, self.local_now_time)
return watching_count, click_probability, on_line_count, average_on_line_time, fans_average_on_line_time,\
live_room_watching_count, fans_make_up, extra_add_flow,\
add_fans, goods_click, goods_click_fans_make_up, guid_deal_count, guid_deal_percent,\
guid_deal_money, guid_deal_money_percent, self.local_now_time
def write_excel(self):
workbook = load_workbook('data.xlsx')
wb = workbook['Sheet1']
line = wb.max_row
watching_count, click_probability, on_line_count, average_on_line_time, fans_average_on_line_time, \
live_room_watching_count, fans_make_up, extra_add_flow, \
add_fans, goods_click, goods_click_fans_make_up, guid_deal_count, guid_deal_percent, \
guid_deal_money, guid_deal_money_percent, self.local_now_time = self.spider()
line += 1
wb[f'A{line}'] = self.local_now_time
wb[f'B{line}'] = watching_count
wb[f'C{line}'] = click_probability
wb[f'D{line}'] = on_line_count
wb[f'E{line}'] = average_on_line_time
wb[f'F{line}'] = fans_average_on_line_time
wb[f'G{line}'] = live_room_watching_count
wb[f'H{line}'] = fans_make_up
wb[f'I{line}'] = extra_add_flow
wb[f'J{line}'] = add_fans
wb[f'K{line}'] = goods_click
wb[f'L{line}'] = goods_click_fans_make_up
wb[f'M{line}'] = guid_deal_count
wb[f'N{line}'] = guid_deal_percent
wb[f'O{line}'] = guid_deal_money
wb[f'P{line}'] = guid_deal_money_percent
workbook.save('data.xlsx')
def main():
run = TaobaoLiveSpider()
run.write_excel()
scheduler = BlockingScheduler()
scheduler.add_job(main, 'interval', seconds=1800, id='main')
scheduler.start()
模拟登陆
import re
import os
import json
import requests
s = requests.Session()
# cookies序列化文件
COOKIES_FILE_PATH = 'taobao_login_cookies.txt'
class UsernameLogin:
def __init__(self, loginId, umidToken, ua, password2):
"""
账号登录对象
:param loginId: 用户名
:param umidToken: 新版登录新增参数
:param ua: 淘宝的ua参数
:param password2: 加密后的密码
"""
# 检测是否需要验证码的URL
self.user_check_url = 'https://login.taobao.com/newlogin/account/check.do?appName=taobao&fromSite=0'
# 验证淘宝用户名密码URL
self.verify_uaername_password_url = "https://login.taobao.com/newlogin/login.do?appName=taobao&fromSite=0"
# 访问st码URL
self.vst_url = 'https://login.taobao.com/member/vst.htm?st={}'
# 淘宝个人 主页
# self.my_taobao_url = 'http://i.taobao.com/my_taobao.htm'
self.my_taobao_url = 'https://zhaoshang.tmall.com/channel/index.htm?'
# 淘宝用户名
self.loginId = loginId
# 淘宝用户名
self.umidToken = umidToken
# 淘宝关键参数,包含用户浏览器等一些信息,很多地方会使用,从浏览器或抓包工具中复制,可重复使用
self.ua = ua
# 加密后的密码,从浏览器或抓包工具中复制,可重复使用
self.password2 = password2
# 请求超时时间
self.timeout = 3
def _user_check(self):
"""
检测账号是否需要验证码
:return:
"""
data = {
'loginId': self.loginId,
'ua': self.ua,
}
try:
response = s.post(self.user_check_url, data=data, timeout=self.timeout)
response.raise_for_status()
except Exception as e:
print(f'检测是否需要验证码请求失败,原因:{e}')
raise e
check_resp_data = response.json()['content']['data']
needcode = False
# 判断是否需要滑块验证,一般短时间密码错误多次可能出现
if 'isCheckCodeShowed' in check_resp_data:
needcode = True
print('是否需要滑块验证:{}'.format(needcode))
return needcode
def _get_umidToken(self):
"""
获取umidToken参数
:return:
"""
response = s.get('https://login.taobao.com/member/login.jhtml')
st_match = re.search(r'"umidToken":"(.*?)"', response.text)
print(st_match.group(1))
return st_match.group(1)
@property
def verify_login_password(self):
"""
验证用户名密码,并获取st码申请URL
:return: 验证成功返回st码申请地址
"""
headers = {
'Referer': 'https://login.taobao.com/member/login.jhtml',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
'origin': 'https://login.taobao.com'
}
# 登录toabao.com提交的数据,如果登录失败,可以从浏览器复制你的form data
data = {
'loginId': self.loginId,
'password2': self.password2,
'keepLogin': 'false',
'ua': self.ua,
'umidGetStatusVal': '255',
'screenPixel': '1920x1080',
'navlanguage': 'zh-CN',
'navUserAgent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
'navPlatform': 'Win32',
'appName': 'taobao',
'appEntrance': 'taobao_pc',
'_csrf_token': 'kmnF0VwnseLLEq0kw7qLI',
'umidToken': '899a8d2fdf9d6a93a5d7472bcb8db95227a9e034',
'hsiz': '167696b8b2d8a066b7b0e4e0e140d905',
'bizParams': '',
'style': 'default',
'appkey': '00000000',
'from': 'tbTop',
'isMobile': 'false',
'lang': 'zh_CN',
'returnUrl': 'https://www.taobao.com/',
'fromSite': '0'
}
try:
response = s.post(self.verify_uaername_password_url, headers=headers, data=data,
timeout=self.timeout)
response.raise_for_status()
# 从返回的页面中提取申请st码地址
except Exception as e:
print('验证用户名和密码请求失败,原因:')
raise e
# 提取申请st码url
print(response.json())
apply_st_url_match = response.json()['content']['data']['asyncUrls'][0]
# 存在则返回
if apply_st_url_match:
print('验证用户名密码成功,st码申请地址:{}'.format(apply_st_url_match))
return apply_st_url_match
else:
raise RuntimeError('用户名密码验证失败!response:{}'.format(response.text))
def _apply_st(self):
"""
申请st码
:return: st码
"""
apply_st_url = self.verify_login_password
try:
response = s.get(apply_st_url)
response.raise_for_status()
except Exception as e:
print('申请st码请求失败,原因:')
raise e
st_match = re.search(r'"data":{"st":"(.*?)"}', response.text)
if st_match:
print('获取st码成功,st码:{}'.format(st_match.group(1)))
return st_match.group(1)
else:
raise RuntimeError('获取st码失败!response:{}'.format(response.text))
def login(self):
"""
使用st码登录
:return:
"""
# 加载cookies文件
if self._load_cookies():
return True
# 判断是否需要滑块验证
self._user_check()
st = self._apply_st()
headers = {
'Host': 'login.taobao.com',
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
try:
response = s.get(self.vst_url.format(st), headers=headers)
response.raise_for_status()
except Exception as e:
print('st码登录请求,原因:')
raise e
# 登录成功,提取跳转淘宝用户主页url
my_taobao_match = re.search(r'top.location.href = "(.*?)"', response.text)
if my_taobao_match:
print('登录淘宝成功,跳转链接:{}'.format(my_taobao_match.group(1)))
self.my_taobao_url = my_taobao_match.group(1)
self._serialization_cookies()
return True
else:
raise RuntimeError('登录失败!response:{}'.format(response.text))
def _load_cookies(self):
# 1、判断cookies序列化文件是否存在
if not os.path.exists(COOKIES_FILE_PATH):
return False
# 2、加载cookies
s.cookies = self._deserialization_cookies()
# 3、判断cookies是否过期
try:
self.get_taobao_nick_name()
except Exception as e:
os.remove(COOKIES_FILE_PATH)
print('cookies过期,删除cookies文件!')
return False
print('加载淘宝cookies登录成功!!!')
return True
def _serialization_cookies(self):
"""
序列化cookies
:return:
"""
cookies_dict = requests.utils.dict_from_cookiejar(s.cookies)
print(cookies_dict)
with open(COOKIES_FILE_PATH, 'w+', encoding='utf-8') as file:
json.dump(cookies_dict, file)
print('保存cookies文件成功!')
def _deserialization_cookies(self):
"""
反序列化cookies
:return:
"""
with open(COOKIES_FILE_PATH, 'r+', encoding='utf-8') as file:
cookies_dict = json.load(file)
cookies = requests.utils.cookiejar_from_dict(cookies_dict)
return cookies
def get_taobao_nick_name(self):
"""
获取淘宝昵称
:return: 淘宝昵称
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
params = {
'spm': '687.8433302/new.sidebar.1.296f226aVUQtum',
'spm': 'a217wi.openworkbeanchtmall_web'
}
try:
response = s.get(self.my_taobao_url, headers=headers)
# print(response.text)
response.raise_for_status()
except Exception as e:
print('获取淘宝主页请求失败!原因:')
raise e
# 提取淘宝昵称
# nick_name_match = re.search(r'<input id="mtb-nickname" type="hidden" value="(.*?)"/>', response.text)
nick_name_match = re.findall("erNick = '(.*?)'", response.text)[0]
if nick_name_match:
print(f'登录淘宝成功,你的用户名是:{nick_name_match}')
return nick_name_match
else:
raise RuntimeError('获取淘宝昵称失败!response:{}'.format(response.text))
def get_live(self):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'referer': 'https://liveplatform.taobao.com/live/liveList.htm?'
}
url = 'https://liveplatform.taobao.com/live/action.do?currentPage=1&pagesize=20&api=get_live_list'
response = s.get(url, headers=headers).text
print(response)
if __name__ == '__main__':
# 说明:loginId、umidToken、ua、password2这4个参数都是从浏览器登录页面复制过来的。
# 如何复制4个参数:
# # 1、浏览器打开:https://login.taobao.com/member/login.jhtml
# # 2、F12打开调试窗口,左边有个Preserve log,勾选上,这样页面跳转请求记录不会丢失
# # 3、输入用户名密码登录,然后找到请求:newlogin/login.do 这个是登录请求
# # 4、复制上面的4个参数到下面,基本就可以运行了
# # 5、如果运行报错可以微信私聊猪哥,没加猪哥微信的可以关注猪哥微信公众号[裸睡的猪],回复:加群
# 淘宝用户名:手机 用户名 都可以
loginId = 'username'
# 改版后增加的参数,后面考虑解密这个参数
umidToken = 'ae2d51d',
# 淘宝重要参数,从浏览器或抓包工具中复制,可重复使用
ua = '137#Qtc9hE9o9IpDz/4p38vMDW2hkgwdkrNMhdtCDn7DaPtK8zuCzjGfX9gy1gOwsfS1'
# 加密后的密码,从浏览器或抓包工具中复制,可重复使用
password2 = 'c3107629fbd23e5b0b6c4696e146d7207299d6d80fb8b00154a143736cb'
ul = UsernameLogin(loginId, umidToken, ua, password2)
ul.login()
ul.get_taobao_nick_name()
ul.get_live()
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号