MongoDB 基础知识
2.1 文档是MongoDB的核心概念。文档就是键值对的一个有序集{'msg':'hello','foo':3}。类似于python中的有序字典。
需要注意的是:
#1、文档中的键/值对是有序的。
#2、文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
#3、MongoDB区分类型和大小写。
#4、MongoDB的文档不能有重复的键。
#5、文档中的值可以是多种不同的数据类型,也可以是一个完整的内嵌文档。文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
#1、键不能含有\0 (空字符)。这个字符用来表示键的结尾。
#2、.和$有特别的意义,只有在特定环境下才能使用。
#3、以下划线"_"开头的键是保留的(不是严格要求的)。
2.2 集合就是一组文档。如果将MongoDB中的一个文档比喻为关系型数据的一行,那么一个集合就是相当于一张表
#1、集合存在于数据库中,通常情况下为了方便管理,不同格式和类型的数据应该插入到不同的集合,但其实集合没有固定的结构,这意味着我们完全可以把不同格式和类型的数据统统插入一个集合中。
#2、组织子集合的方式就是使用“.”,分隔不同命名空间的子集合。
比如一个具有博客功能的应用可能包含两个集合,分别是blog.posts和blog.authors,这是为了使组织结构更清晰,这里的blog集合(这个集合甚至不需要存在)跟它的两个子集合没有任何关系。
在MongoDB中,使用子集合来组织数据非常高效,值得推荐
#3、当第一个文档插入时,集合就会被创建。合法的集合名:
集合名不能是空字符串""。
集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
集合名不能以"system."开头,这是为系统集合保留的前缀。
用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
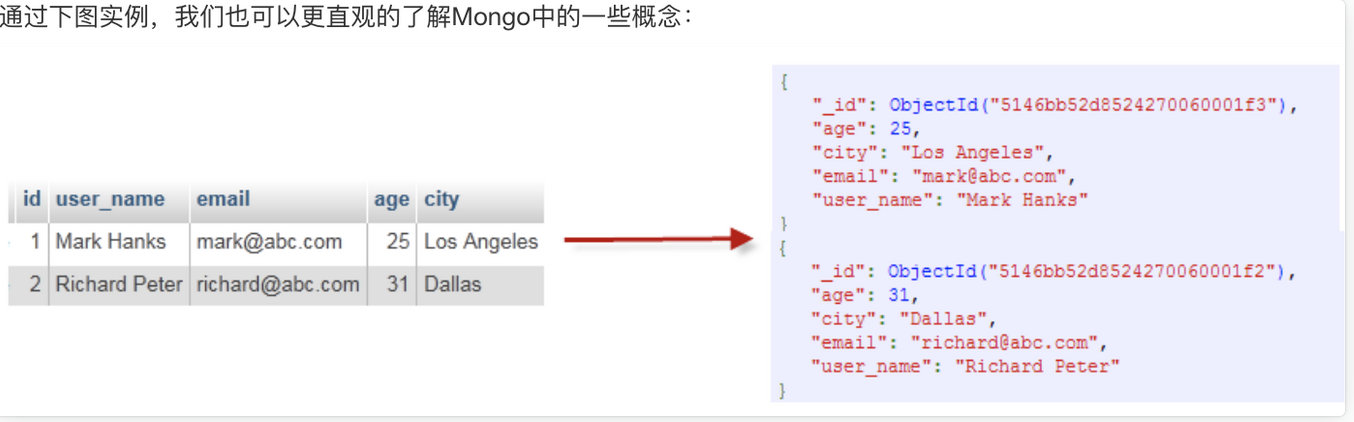
2.3 数据库:在MongoDB中,多个文档组成集合,多个集合可以组成数据库
数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串:
#1、不能是空字符串("")。
#2、不得含有' '(空格)、.、$、/、\和\0 (空字符)。
#3、应全部小写。
#4、最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
#1、admin: 从身份认证的角度讲,这是“root”数据库,如果将一个用户添加到admin数据库,这个用户将自动获得所有数据库的权限。再者,一些特定的服务器端命令也只能从admin数据库运行,如列出所有数据库或关闭服务器
#2、local: 这个数据库永远都不可以复制,且一台服务器上的所有本地集合都可以存储在这个数据库中
#3、config: MongoDB用于分片设置时,分片信息会存储在config数据库中
2.4 强调:把数据库名添加到集合名前,得到集合的完全限定名,即命名空间
例如:
如果要使用cms数据库中的blog.posts集合,这个集合的命名空间就是
cmd.blog.posts。命名空间的长度不得超过121个字节,且在实际使用中应该小于100个字节
指定范围时间
db.things.find({"createTime":{"$gt":"2015-5-21 0:0:0"}}) // 大于某个时间
db.things.find({"createTime":{"$lt":"2014-5-21 0:0:0"}}) // 小于某个时间
db.things.find({"$and":[{"createTime":{"$gt":"2015-5-21 0:0:0"}},{"createTime":{"$lt":"2015-5-22 0:0:0"}}]}) // 某个时间段
db.getCollection('auction_case').find({data_source: '阿里法拍', "$and":[{"detail_time":{"$gt":"2021-09-30 00:00:00"}},{"detail_time":{"$lt":"2021-10-03 00:00:00"}}]}) // 某个时间段
# 切片取值
datas = dbs[index_: index_+100000].clone()
# 多线程取值需要列表推导式一下
datas = [data for data in datas]
df = pd.DataFrame(datas)
df = df.rename(columns={
"name": "名称",
"age": "年龄"
})
columns = ["名称", "年龄"]
# 指定顺序
df = df[columns]
excel_number = index_/10000
df.to_excel(f'info.xlsx', index=False)
多线程读取的正确方式
def save_excel(self, dbs, index_):
datas = dbs[index_: index_+10000].clone()
datas = [data for data in datas]
df = pd.DataFrame(datas)
df = df.rename(columns={
"name": "名称",
"age": "年龄"
})
columns = ["名称", "年龄"]
# 指定顺序
df = df[columns]
excel_number = index_/10000
df.to_excel(f'crawl datas/{excel_number}.xlsx', index=False)
print(666)
def export_room_number(self):
"""
多线程导出数据
"""
dbs = self.m.search('room_number_detail', types=2, count=20000)
dbs_counts = dbs.count()
# for index_ in range(0, 2310000, 10000):
# t = Thread(target=self.save_excel, args=(dbs, index_,))
# t.start()
with ThreadPoolExecutor(max_workers=6) as pool:
for index_ in range(0, 2310000, 10000):
pool.submit(self.save_excel, dbs, index_)
MongoDB中查找字段内容长度
# 查询 name 内容长度大于30的数量 re方式查找
db.getCollection('dbs').find({"name": {"$regex": /^.{30,}$/}}).count()
Python中使用
{"name": {"$regex": r'^.{30,}$'}} 不带 /
查询包含某个字符的字段的数据
# 这种方法更快
db.getCollection('auction_case').find({title: {$regex:/份额/}})
# pymongo 内使用
{'name': {'$regex':'天王盖地虎'}, 'age': 66}
db.getCollection('auction_case').find({title: '/^.*份额.*$/'})
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号